

В этом году главная европейская конференция по Kubernetes — KubeCon + CloudNativeCon Europe 2020 — была виртуальной. Впрочем, такая смена формата не помешала нам выступить с давно запланированным докладом «Go? Bash! Meet the Shell-operator», посвящённым нашему Open Source-проекту .
В этой статье, написанной по мотивам выступления, представлен подход к упрощению процесса создания операторов для Kubernetes и показано, как с минимальными усилиями при помощи shell-operator’а можно сделать свой собственный.

Представляем (~23 минуты на английском, заметно информативнее статьи) и основную выжимку из него в текстовом виде. Поехали!
Мы во «Фланте» постоянно все оптимизируем и автоматизируем. Сегодня речь пойдет об еще одной увлекательной концепции. Встречайте: cloud-native shell-скриптинг!
Впрочем, давайте начнем с контекста, в котором все это происходит, — с Kubernetes.
Kubernetes API и контроллеры
API в Kubernetes можно представить в виде некоего файлового сервера с директориями под каждый тип объектов. Объекты (ресурсы) на этом сервере представлены YAML-файлами. Кроме того, у сервера имеется базовый API, позволяющий делать три вещи:
- получать ресурс по его kind’у и имени;
- менять ресурс (при этом сервер хранит только «правильные» объекты — все некорректно сформированные или предназначенные для других директорий отбрасываются);
- следить за ресурсом (в этом случае пользователь сразу получает его текущую/обновленную версию).
Таким образом, Kubernetes выступает этаким файловым сервером (для YAML-манифестов) с тремя базовыми методами (да, вообще-то есть и другие, но мы их пока опустим).

Проблема в том, что сервер умеет только хранить информацию. Чтобы заставить ее работать, необходим controller — второе по важности и фундаментальности понятие в мире Kubernetes.
Различают два основных типа контроллеров. Первый берет информацию из Kubernetes, обрабатывает ее в соответствии со вложенной логикой и возвращает в K8s. Второй — берет информацию из Kubernetes, но, в отличие от первого типа, меняет состояние неких внешних ресурсов.
Давайте рассмотрим подробнее процесс создания Deployment’а в Kubernetes:
- Deployment Controller (входящий в
kube-controller-manager) получает информацию о Deployment’е и создает ReplicaSet. - ReplicaSet на основе этой информации создает две реплики (два pod’а), но эти pod’ы еще не запланированы.
- Планировщик планирует pod’ы и добавляет в их YAML’ы информацию об узлах.
- Kubelet’ы вносят изменения во внешний ресурс (скажем, Docker).
Затем вся эта последовательность повторяется в обратном порядке: kubelet проверяет контейнеры, вычисляет статус pod’а и отсылает его обратно. Контроллер ReplicaSet получает статус и обновляет состояние набора реплик. То же самое происходит с Deployment Controller’ом, и пользователь, наконец, получает обновленный (текущий) статус.
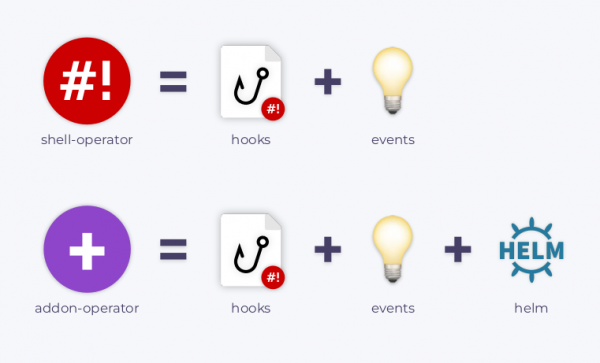
Shell-operator
Получается, что в основе Kubernetes лежит совместная работа различных контроллеров (операторы Kubernetes тоже контроллеры). Возникает вопрос, как создать свой оператор с минимальными усилиями? И тут на помощь приходит разработанный нами . Он позволяет системным администраторам создавать собственные операторы, используя привычные методы.
Простой пример: копирование секретов
Давайте рассмотрим простой пример.
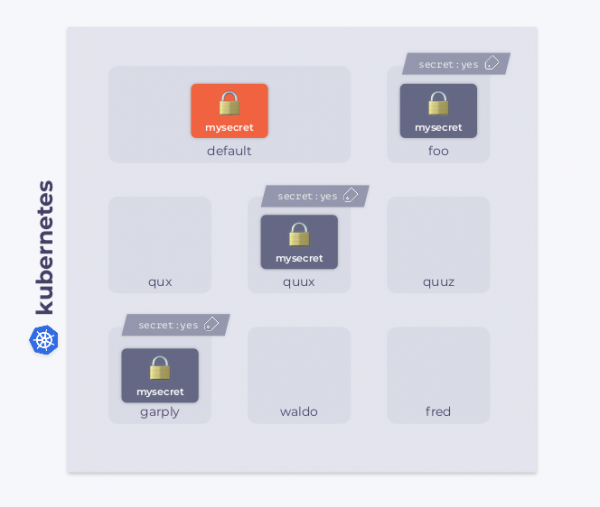
Предположим, у нас имеется кластер Kubernetes. В нем есть пространство имен default с некоторым Secret’ом mysecret. Кроме этого, в кластере есть и другие пространства имен. К некоторым из них прикреплен определенный лейбл. Наша цель — скопировать Secret в пространства имен с лейблом.
Задача осложняется тем, что в кластере могут появляться новые пространства имен, и у некоторых из них может быть данный лейбл. С другой стороны, при удалении лейбла Secret также должен удаляться. В дополнение ко всему, сам Secret тоже может меняться: в этом случае новый Secret должен быть скопирован во все пространства имен с лейблами. Если Secret случайно удаляется в каком-либо пространстве имен, наш оператор должен его сразу восстановить.
Теперь, когда задача сформулирована, пора приступить к ее реализации с помощью shell-operator. Но сначала стоит сказать несколько слов о самом shell-operator’s.
Принципы работы shell-operator
Как и другие рабочие нагрузки в Kubernetes, shell-operator функционирует в своем pod’е. В этом pod’е в каталоге /hooks хранятся исполняемые файлы. Это могут быть скрипты на Bash, Python, Ruby и т.д. Такие исполняемые файлы мы называем хуками (hooks).
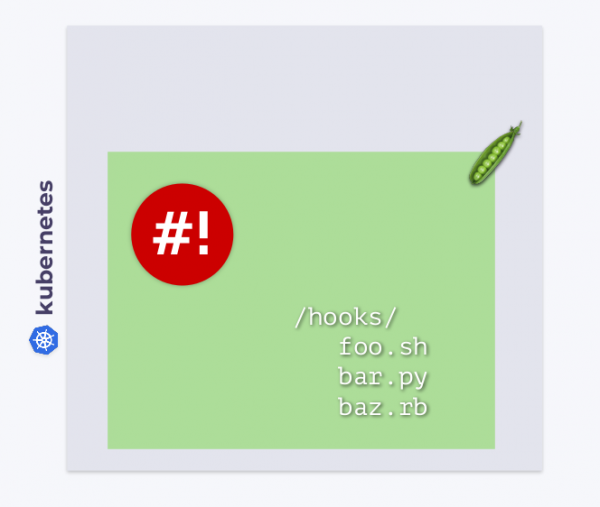
Shell-operator подписывается на события Kubernetes и запускает эти хуки в ответ на те из событий, что нам нужны.
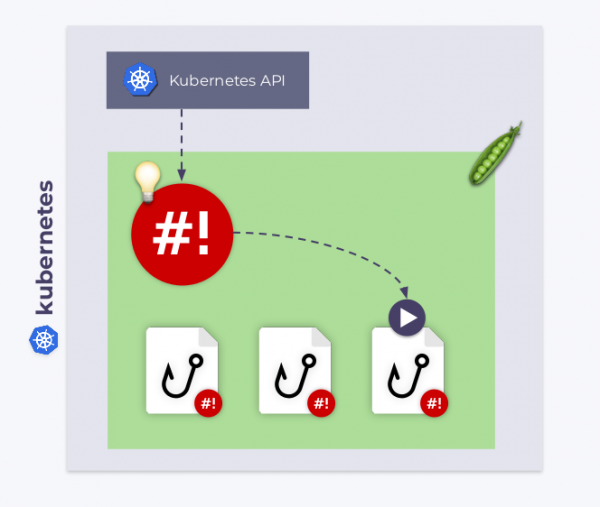
Каким образом shell-operator узнает, какой хук и когда запускать? Дело в том, что у каждого хука есть две стадии. Во время старта shell-operator запускает все хуки с аргументом --config — это стадия конфигурирования. А уже после неё хуки запускаются нормальным образом — в ответ на события, к которым они привязаны. В последнем случае хук получает контекст привязки (binding context) — данные в формате JSON, подробнее о которых мы поговорим ниже.
Делаем оператор на Bash
Теперь мы готовы к реализации. Для этого нам потребуется написать две функции (кстати, рекомендуем библиотеку , которая сильно упрощает написание хуков на Bash):
- первая нужна для стадии конфигурирования — она выводит контекст привязки;
- вторая содержит основную логику хука.
#!/bin/bash
source /shell_lib.sh
function __config__() {
cat << EOF
configVersion: v1
# BINDING CONFIGURATION
EOF
}
function __main__() {
# THE LOGIC
}
hook::run "$@"
Следующий шаг — определиться с тем, какие объекты нам нужны. В нашем случае требуется отслеживать:
- секрет-источник на предмет наличия изменений;
- все namespace’ы в кластере, чтобы знать, к каким из них прикреплен лейбл;
- секреты-цели, чтобы убедиться, что все они синхронизированы с секретом-источником.
Подписываемся на секрет-источник
Binding configuration для него достаточно проста. Мы указываем, что нас интересует Secret с названием mysecret в пространстве имен default:
function __config__() {
cat << EOF
configVersion: v1
kubernetes:
- name: src_secret
apiVersion: v1
kind: Secret
nameSelector:
matchNames:
- mysecret
namespace:
nameSelector:
matchNames: ["default"]
group: main
EOF
В результате хук будет запускаться при изменении секрета-источника (src_secret) и получать следующий binding context:
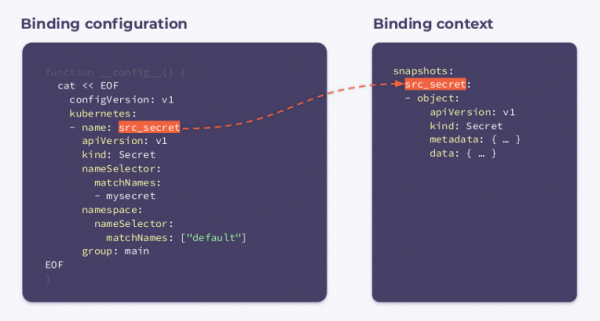
Как видите, в нем содержится имя и объект целиком.
Следим за пространствами имен
Теперь нужно подписаться на namespaces. Для этого укажем следующую binding configuration:
- name: namespaces
group: main
apiVersion: v1
kind: Namespace
jqFilter: |
{
namespace: .metadata.name,
hasLabel: (
.metadata.labels // {} |
contains({"secret": "yes"})
)
}
group: main
keepFullObjectsInMemory: false
Как видите, в конфигурации появилось новое поле с именем jqFilter. Как намекает его название, jqFilter отфильтровывает всю лишнюю информацию и создает новый объект JSON с полями, которые представляют для нас интерес. Хук с подобной конфигурацией получит следующий binding context:
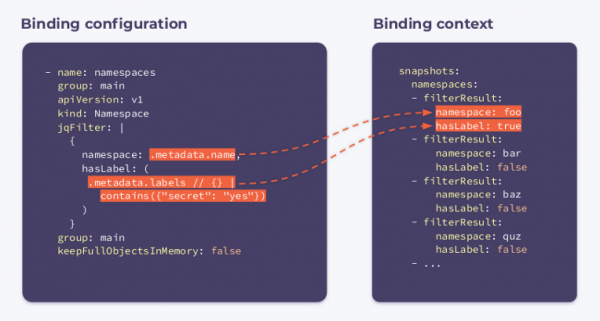
Он содержит в себе массив filterResults для каждого пространства имен в кластере. Булева переменная hasLabel показывает, прикреплен ли лейбл к данному пространству имен. Селектор keepFullObjectsInMemory: false говорит о том, что нет необходимости держать полные объекты в памяти.
Отслеживаем секреты-цели
Мы подписываемся на все Secret’ы, у которых задана аннотация managed-secret: "yes" (это наши целевые dst_secrets):
- name: dst_secrets
apiVersion: v1
kind: Secret
labelSelector:
matchLabels:
managed-secret: "yes"
jqFilter: |
{
"namespace":
.metadata.namespace,
"resourceVersion":
.metadata.annotations.resourceVersion
}
group: main
keepFullObjectsInMemory: false
В этом случае jqFilter отфильтровывает всю информацию за исключением пространства имен и параметра resourceVersion. Последний параметр был передан аннотации при создании секрета: он позволяет сравнивать версии секретов и поддерживать их в актуальном состоянии.
Хук, настроенный подобным образом, при выполнении получит три контекста привязки, описанные выше. Их можно представить как своего рода снимок (snapshot) кластера.

На основе всей этой информации можно разработать базовый алгоритм. Он перебирает все пространства имен и:
- если
hasLabelимеет значениеtrueдля текущего пространства имен:- сравнивает глобальный секрет с локальным:
- если они одинаковы — ничего не делает;
- если они отличаются — выполняет
kubectl replaceилиcreate;
- сравнивает глобальный секрет с локальным:
- если
hasLabelимеет значениеfalseдля текущего пространства имен:- убеждается, что Secret отсутствует в данном пространстве имен:
- если локальный Secret присутствует — удаляет его с помощью
kubectl delete; - если локальный Secret не обнаружен — ничего не делает.
- если локальный Secret присутствует — удаляет его с помощью
- убеждается, что Secret отсутствует в данном пространстве имен:

вы можете скачать в нашем .
Вот так мы смогли создать простой контроллер Kubernetes, использовав 35 строк YAML-конфигов и примерно такое же количество кода на Bash! Задача shell-operator состоит в том, чтобы связать их вместе.
Впрочем, копирование секретов — это не единственная область применения утилиты. Вот еще несколько примеров, которые покажут, на что он способен.
Пример 1: внесение изменений в ConfigMap
Давайте рассмотрим Deployment, состоящий из трех pod’ов. Pod’ы используют ConfigMap для хранения некоторой конфигурации. Во время запуска pod’ов ConfigMap находился в некотором состоянии (назовем его v.1). Соответственно, все pod’ы используют именно эту версию ConfigMap.
Теперь предположим, что ConfigMap изменился (v.2). Однако pod’ы будут использовать прежнюю версию ConfigMap (v.1):
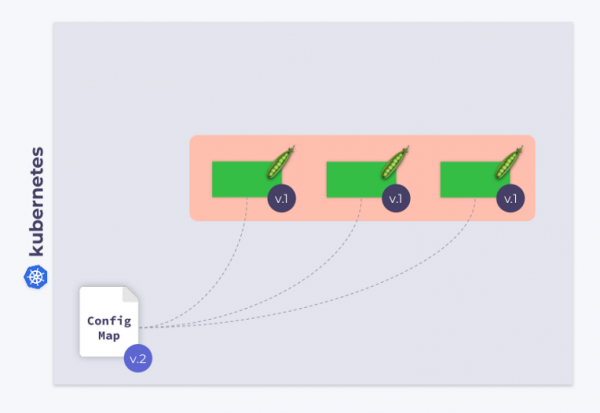
Как сделать так, чтобы они перешли на новый ConfigMap (v.2)? Ответ прост: воспользоваться template’ом. Давайте добавим аннотацию с контрольной суммой в раздел template конфигурации Deployment’а:

В результате во всех pod’ах будет прописана эта контрольная сумма, и она будет такой же, как у Deployment’a. Теперь нужно просто обновлять аннотацию при изменении ConfigMap. И shell-operator как нельзя кстати в этом случае. Все что нужно — это запрограммировать хук, который подпишется на ConfigMap и обновит контрольную сумму.
Если пользователь внесет изменения в ConfigMap, shell-operator их заметит и пересчитает контрольную сумму. После чего в игру вступит магия Kubernetes: оркестратор убьет pod, создаст новый, дождется, когда тот станет Ready, и перейдет к следующему. В результате Deployment синхронизируется и перейдет на новую версию ConfigMap.
Пример 2: работа с Custom Resource Definitions
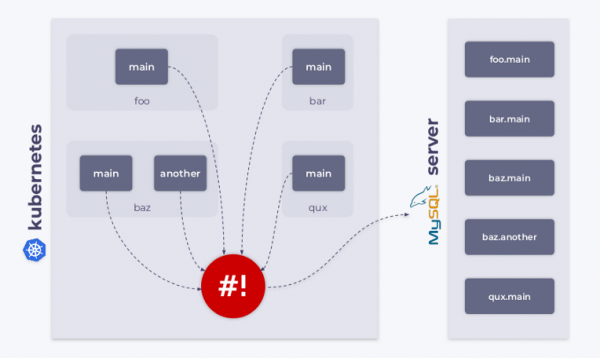
Как известно, Kubernetes позволяет создавать кастомные типы (kinds) объектов. Например, можно создать kind MysqlDatabase. Допустим, у этого типа имеются два metadata-параметра: name и namespace.
apiVersion: example.com/v1alpha1
kind: MysqlDatabase
metadata:
name: foo
namespace: bar
У нас есть кластер Kubernetes с различными пространствами имен, в которых мы можем создавать базы данных MySQL. В этом случае shell-operator можно использовать для отслеживания ресурсов MysqlDatabase, их подключения к MySQL-серверу и синхронизации желаемого и наблюдаемого состояний кластера.
Пример 3: мониторинг кластерной сети
Как известно, использование ping’а является простейшим способом мониторинга сети. В этом примере мы покажем, как реализовать подобный мониторинг с помощью shell-operator.
Прежде всего, потребуется подписаться на узлы. Shell-operator’у нужны имя и IP-адрес каждого узла. С их помощью он будет пинговать эти узлы.
configVersion: v1
kubernetes:
- name: nodes
apiVersion: v1
kind: Node
jqFilter: |
{
name: .metadata.name,
ip: (
.status.addresses[] |
select(.type == "InternalIP") |
.address
)
}
group: main
keepFullObjectsInMemory: false
executeHookOnEvent: []
schedule:
- name: every_minute
group: main
crontab: "* * * * *"
Параметр executeHookOnEvent: [] предотвращает запуск хука в ответ на любое событие (то есть в ответ на изменение, добавление, удаление узлов). Однако он будет запускаться (и обновлять список узлов) по расписанию — каждую минуту, как предписывает поле schedule.
Теперь возникает вопрос, как именно мы узнаем о проблемах вроде потери пакетов? Давайте взглянем на код:
function __main__() {
for i in $(seq 0 "$(context::jq -r '(.snapshots.nodes | length) - 1')"); do
node_name="$(context::jq -r '.snapshots.nodes['"$i"'].filterResult.name')"
node_ip="$(context::jq -r '.snapshots.nodes['"$i"'].filterResult.ip')"
packets_lost=0
if ! ping -c 1 "$node_ip" -t 1 ; then
packets_lost=1
fi
cat >> "$METRICS_PATH" <<END
{
"name": "node_packets_lost",
"add": $packets_lost,
"labels": {
"node": "$node_name"
}
}
END
done
}
Мы перебираем список узлов, получаем их имена и IP-адреса, пингуем и отправляем результаты в Prometheus. Shell-operator умеет экспортировать метрики в Prometheus, сохраняя их в файл, расположенный согласно пути, указанному в переменной окружения $METRICS_PATH.
можно сделать оператора для простого мониторинга сети в кластере.
Механизм очередей
Эта статья была бы неполной без описания еще одного важного механизма, встроенного в shell-operator. Представьте, что он выполняет некий хук в ответ на событие в кластере.
- Что произойдет, если в это же время в кластере случится еще одно событие?
- Запустит ли shell-operator еще один экземпляр хука?
- А что, если в кластере сразу произойдут, скажем, пять событий?
- Будет ли shell-operator обрабатывать их параллельно?
- А как насчет потребляемых ресурсов, таких как память и CPU?
К счастью, в shell-operator имеется встроенный механизм очередей. Все события помещаются в очередь и обрабатываются последовательно.
Проиллюстрируем это на примерах. Предположим, что у нас есть два хука. Первое событие достается первому хуку. После того, как его обработка завершена, очередь продвигается вперед. Следующие три события перенаправляются во второй хук — они извлекаются из очереди и поступают в него «пачкой». То есть хук получает массив событий — или, точнее, массив контекстов привязки.
Также эти события можно объединить в одно большое. За это отвечает параметр group в конфигурации привязки.

Можно создавать любое количество очередей/хуков и их всевозможных комбинаций. Например, одна очередь может работать с двумя хуками, или наоборот.
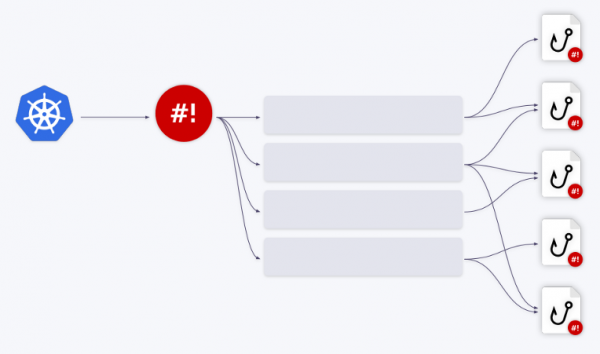
Все, что нужно сделать, — соответствующим образом настроить поле queue в конфигурации привязки. Если не указано имя очереди, хук запускается в очереди по умолчанию (default). Подобный механизм очередей позволяет полностью решить все проблемы управления ресурсами при работе с хуками.
Заключение
Мы рассказали, что такое shell-operator, показали, как с его помощью можно быстро и без особых усилий создавать операторы Kubernetes, и привели несколько примеров его использования.
Подробная информация о shell-operator, а также краткое руководство по его использованию доступны в соответствующем . Не стесняйтесь обращаться к нам с вопросами: обсудить их можно в специальной (на русском) или в (на английском).
А если понравилось — мы всегда рады новым issues/PR/звездам на GitHub, где, к слову, можно найти и другие . Среди них стоит особо выделить , который приходится старшим братом для shell-operator. Эта утилита использует чарты Helm для установки дополнений, умеет доставлять обновления и следить за различными параметрами/значениями чартов, контролирует процесс инсталляции чартов, а также может модифицировать их в ответ на события в кластере.
Видео и слайды
Видео с выступления (~23 минуты):

Презентация доклада:
P.S.
Читайте также в нашем блоге:
- «»;
- «»;
- «»;
- «.
Источник: habr.com
