

Предлагаю ознакомиться с расшифровкой доклада конца 2019 года Александра Валялкина "Go optimizations in VictoriaMetrics"
— быстрая и масштабируемая СУБД для хранения и обработки данных в форме временного ряда (запись образует время и набор соответствующих этому времени значений, например, полученных через периодический опрос состояния датчиков или сбор метрик).

Вот ссылка на видео этого доклада —

Расскажу немного о себе. Я – Александр Валялкин. Вот . Я увлекаюсь Go и оптимизацией производительности. Написал много всяких полезных и не очень библиотек. Они начинаются либо с fast, либо с quick префикса.
В данный момент я работаю над VictoriaMetrics. Что это такое и что я там делаю? Об этом я расскажу в этой презентации.

План доклада такой:
- Вначале я вам расскажу, что такое VictoriaMetrics.
- Потом расскажу, что такое временные ряды.
- Потом расскажу, как работает база данных временных рядов.
- Далее расскажу про архитектуру базы данных: из чего она состоит.
- И потом перейдем к оптимизациям, которые есть в VictoriaMetrics. Это оптимизация инвертированного индекса и оптимизация для bitset-реализации на Go.

Что такое VictoriaMetrics кто-нибудь в аудитории знает? Ничего себе, уже много людей знают. Это хорошая новость. Для тех, кто не знает – это база данных для временных рядов. Она основана на архитектуре ClickHouse, на некоторых деталях реализации ClickHouse. Например, на таких, как: MergeTree, параллельное вычисление на всех доступных ядрах процессора и оптимизация производительности с помощью работы над блоками данных, которые помещаются в кэш процессора.
VictoriaMetrics предоставляет лучшее сжатие данных по сравнению с другими базами данных для временных рядов.
Она масштабируется вертикально — т. е. вы можете добавлять большее количество процессоров, большее количество оперативной памяти на одном компе. VictoriaMetrics будет успешно утилизировать эти доступные ресурсы и будет повышать линейную производительность.
Также VictoriaMetrics масштабируется горизонтально — т. е. вы можете добавлять дополнительные ноды в кластер VictoriaMetrics, и ее производительность будет расти почти линейно.
Как вы догадались, VictoriaMetrics быстрая база данных, потому что других я не могу писать. И она написана на Go, поэтому я про нее рассказываю на этом митапе.

Кто знает, что такое временной ряд? Тоже много людей знает. Временно ряд — это серия пар (timestamp, значение), где эти пары отсортированы по времени. Значение представляет из себя число с плавающей точкой – float64.
Каждый временной ряд уникально идентифицирован ключом. Из чего состоит этот ключ? Он состоит из непустого набора пар ключ-значения.
Вот пример временного ряда. Ключом этого ряда является список пар: __name__="cpu_usage" – это название метрики, instance="my-server" — это компьютер, на котором эта метрика собрана, datacenter="us-east" — это датацентр, где стоит этот компьютер.
У нас получилось имя временного ряда, состоящее из трех пар ключ-значения. Этому ключу соответствует список пар (timestamp, value). t1, t3, t3, ..., tN — это timestamps, 10, 20, 12, ..., 15 — сответствующие значения. Это cpu-usage в данный момент времени для данного ряда.

Где могут быть использованы временные ряды? У кого-нибудь есть идеи?
- В DevOps можно измерять показания загрузки CPU, RAM, сети, rps, количество ошибок и т. д.
- IoT – можем мерить температуру давление, geo coordinates и еще что-нибудь.
- Также финансы – можем мониторить цены на всякие акции и валюты.
- Кроме этого, временные ряды могут использоваться в мониторинге производственных процессов на заводах. У нас есть пользователи, которые используют VictoriaMetrics для мониторинга ветровых турбин, для роботов.
- Также временные ряды полезны для сбора информации с датчиков различных устройств. Например, для двигателя; для измерения давления в шинах; для измерения скорости, расстояния; для измерения расхода бензина и т. д.
- Также временные ряды могут использоваться для мониторинга самолетов. В каждом самолете есть черный ящик, который собирает временные ряды по разным параметрам здоровья самолета. Временные ряды также используются в аэрокосмической промышленности.
- Healthcare – это давление крови, пульс и т.д.
Может быть, еще есть применения, про которые я забыл, но, надеюсь, что вы поняли, что временные ряды активно используются в современном мире. И объем их использования с каждым годом растет.

Для чего нужна база данных для временных рядов? Почему нельзя использовать обычную реляционную базу для хранения временных рядов?
Потому что во временных рядах обычно большой объем информации, который сложно сохранять и обрабатывать в обычных базах данных. Поэтому появились специализированные БД для временных рядов. Эти базы эффективно сохраняют точки (timestamp, value) с заданным ключом. Они предоставляют API для чтения сохраненных данных по ключу, по одной паре ключ-значение, либо по нескольким таким парам, либо по regexp. Например, вы хотите найти загрузку процессора всех ваших сервисов в датацентре в Америке, то нужно использовать вот такой псевдозапрос.
Обычно базы данных для временных рядов представляют специализированные языки запросов, потому что SQL для временных рядов не очень хорошо подходит. Хотя есть базы данных, которые SQL поддерживают, но он не очень хорошо подходит. Более хорошо подходят такие языки запросов, как , , , . Я надеюсь, что кто-то слышал хотя бы одном из этих языков. О PromQL, наверное, слышали многие. Это язык запросов Prometheus.
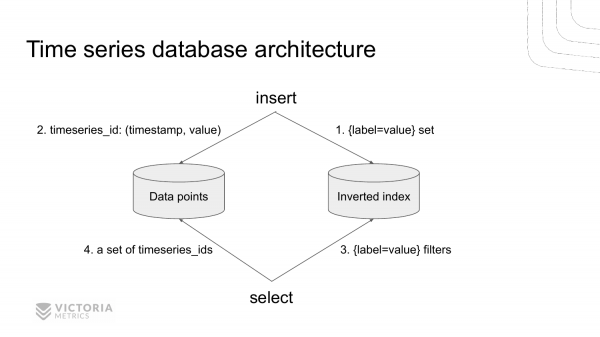
Вот как выглядит архитектура современной базы данных для временных рядов на примере VictoriaMetrics.
Она состоит из двух частей. Это хранилище для инвертированного индекса и хранилище для значений временных рядов. Эти хранилища разделены.
Когда приходит новая запись в базу данных, то мы сначала обращаемся в инвертированный индекс, чтобы найти идентификатор временного ряда по заданному набору label=value для данной метрики. Находим этот идентификатор и сохраняем значение в хранилище данных.
Когда приходит какой-то запрос на выборку данных из TSDB, мы в первую очередь лезем в инвертированный индекс. Достаем все timeseries_ids записи, которые соответствуют данному набору label=value. И затем достаем все необходимые данные из хранилища данных, индексированного по timeseries_ids.

Рассмотрим пример, как база данных для временных рядов обрабатывает входящий select-запрос.
- В первую очередь она достает все
timeseries_idsиз инвертированного индекса, которые содержат заданные парыlabel=value, либо удовлетворяют заданному регулярному выражению. - Потом она достает все data points из храналища данных на заданном интервале времени для найденных
timeseries_ids. - После этого база данных производит какие-то вычисления над этими data points, согласно запросу пользователя. И после этого возвращает ответ.
В данной презентации я вам расскажу про первую часть. Это поиск timeseries_ids по инвертированному индексу. Про вторую часть и третью часть вы можете потом посмотреть , либо подождать, пока я подготовлю другие доклады 🙂

Приступим к инвертированному индексу. Многим может показаться, что это просто. Кто знает, что такое инвертированный индекс и как он работает? О, уже не так много людей. Давайте попытаемся понять, что это такое.
На самом деле все просто. Это просто словарь, который отображает ключ на значение. Что такое ключ? Эта пара label=value, где label и value — это строки. А значения – это набор timeseries_ids, в который входит заданная пара label=value.
Инвертированный индекс позволяет быстро находить все timeseries_ids, у которых есть заданные label=value.
А также он позволяет быстро находить timeseries_ids временных рядов для нескольких пар label=value, либо для пар label=regexp. Как это происходит? С помощью нахождения пересечения множества timeseries_ids для каждой пары label=value.

Рассмотрим различные реализации инвертированного индекса. Начнем с самой простой наивной реализации. Она выглядит вот так.
Функция getMetricIDs получает список строк. Каждая строка содержит label=value. Эта функция возвращает список metricIDs.
Как это работает? Вот у нас есть глобальная переменная, которая называется invertedIndex. Это обычный словарь (map), который отображет строку на slice int-ов. Строка содержит label=value.
Реализация функции: достаем metricIDs для первого label=value, затем проходимся по всем остальным label=value, достаем metricIDs для них. И вызываем функцию intersectInts, про которую будет рассказано далее. И эта функция возвращает пересечение этих списков.

Как вы видите, реализация инвертированного индекса не очень сложная. Но это наивная реализация. Какие у нее есть недостатки? Главный недостаток наивной реализации в том, что такой инвертированный индекс у нас хранится в оперативной памяти. После перезапуска приложения мы теряем этот индекс. Нет сохранения этого индекса на диск. Для базы данных такой инвертированный индекс вряд ли подойдет.
Второй недостаток тоже связан с памятью. Инвертированный индекс должен помещаться в оперативную память. Если он превысит размер оперативной памяти, то очевидно, что мы получим – out of memory error. И программа не будет работать.

Данную проблему можно решить с помощью готовых решений таких, как , либо .
Если вкратце, то нам нужна база данных, которая позволяет сделать быстро три операции.
- Первая операция – это запись
ключ-значениев эту базу. Это она делает очень быстро, гдеключ-значение– это произвольные строки. - Вторая операция – это быстрый поиск значения по заданному ключу.
- И третья операция – это быстрый поиск всех значений по заданному префиксу.
LevelDB и RocksDB – эти базы разработаны в Google и Facebook. Сначала появилась LevelDB. Потом ребята из Facebook взяли LevelDB и начали ее улучшать, сделал RocksDB. Сейчас на RocksDB внутри Facebook работают почти все внутренние базы данных, в том числе они перевели на RocksDB и MySQL. Они назвали его .
Инвертированный индекс можно реализовать с помощью LevelDB. Как это сделать? Мы сохраняем в качестве ключа label=value. А в качестве значения – идентификатор временного ряда, где присутствует пара label=value.
Если у нас есть много временных рядов c данной парой label=value, то будет много строчек в этой базе данных с одинаковыми ключом и разными timeseries_ids. Чтобы получить список всех timeseries_ids, которые начинаются с данной label=prefix, мы делаем range scan, под который оптимизирована данная база данных. Т. е. выбираем все строчки, которые начинаются с label=prefix и получаем необходимые timeseries_ids.

Вот примерная реализация, как она выглядела бы на Go. У нас есть инвертированный индекс. Это LevelDB.
Функция такая же, как для наивной реализации. Она почти строчка в строчку повторяет наивную реализацию. Единственный момент, что вместо обращения к map мы обращаемся к инвертированному индексу. Достаем все значения для первой label=value. Потом проходимся по всем оставшимся парам label=value и достаем соответствующие наборы metricIDs для них. Затем находим пересечение.
Вроде бы все хорошо, но в этом решении есть недостатки. VictoriaMetrics вначале реализовывала инвертированный индекс на основе LevelDB. Но в итоге пришлось отказаться от него.
Почему? Потому что LevelDB медленней, чем наивная реализация. В наивной реализации по заданному ключу мы сразу достаем весь slice metricIDs. Эта очень быстрая операция — весь slice готов для использования.
В LevelDB же при каждом вызове функции GetValues нужно пройтись по всем строчкам, которые начинаются с label=value. И для каждой строчки достать значение timeseries_ids. Из таких timeseries_ids собрать slice этих timeseries_ids. Очевидно, что это намного медленней, чем просто обращение к обычному map’у по ключу.
Второй недостаток в том, что LevelDB написан на C. Обращение к C-функциям из Go не очень быстрое. Оно занимает сотни наносекунд. Это не очень быстро, потому что по сравнению с обычным вызовом функции, написанной на go, которая занимает 1-5 наносекунд, разница в производительности получается в десятки раз. Для VictoriaMetrics – это было фатальным недостатком 🙂

Поэтому я написал собственную реализацию инвертированного индекса. И назвал ее .
Mergeset основан на структуре данных MergeTree. Эта структура данных позаимствована из ClickHouse. Очевидно, что mergeset должен быть оптимизирован для быстрого поиска timeseries_ids по заданному ключу. Mergeset написан полностью на Go. Вы можете посмотреть . Реализация mergeset лежит в папочке . Вы можете попытаться разобраться, что там происходит.
API mergeset очень похож на LevelDB и RocksDB. Т. е. он позволяет быстро сохранить туда новые записи и быстро выбрать записи по заданному префиксу.

Про недостатки mergeset мы поговорим попозже. Сейчас поговорим о том, какие возникли проблемы с VictoriaMetrics в production при реализации инвертированного индекса.
Почему они возникли?
Первая причина – это high churn rate. В переводе на русский – это частая смена временных рядов. Это когда временной ряд заканчивается и начинается новый ряд, либо начинаются много новых временных рядов. И это происходит часто.
Вторая причина – это большое количество временных рядов. Вначале, когда мониторинг набирал популярность, количество временных рядов было маленьким. Например, на каждый компьютер нужно мониторить загрузку процессора, памяти, сети и диска. 4 временных ряда на каждый компьютер. У вас, допустим, 100 компьютеров и 400 временных рядов. Это очень мало.
С течением времени люди придумали, что можно измерять более детализированную информацию. Например, измерять загрузку не всего процессора, а в отдельности каждого процессорного ядра. Если у вас есть 40 процессорных ядер, то, соответственно, у вас появляется в 40 раз больше временных рядов для измерения загрузки процессора.
Но это еще не все. У каждого процессорного ядра может быть несколько состояний таких, как idle, когда он простаивает. А также работа в user space, работа в kernel space и другие состояния. И каждое такое состояние тоже можно измерять, как отдельный временной ряд. Это дополнительно увеличивает количество рядов в 7-8 раз.
У нас из одной метрики получилось 40 х 8 = 320 метрик только на один компьютер. Умножаем на 100, получаем 32 000 вместо 400.
Потом появился Kubernetes. И все еще ухудшил, потому что в Kubernetes может хоститься много разных сервисов. Каждый сервис в Kubernetes состоит из многих подов. И все это нужно мониторить. Кроме этого у нас есть постоянный deployment новых версий ваших сервисов. Для каждой новой версии нужно создавать новые временные ряды. В итоге количество временных рядов растет экспоненциально и мы сталкиваемся с проблемой большого количества временных рядов, которая называется high-cardinality. VictoriaMetrics с ней успешно справляется по сравнению с другими базами данных для временных рядов.

Рассмотрим подробнее high churn rate. Из-за чего появляется high churn rate на production? Потому что некоторые значения лейблов и тегов постоянно меняются.
Например, возьмем Kubernetes, в котором есть понятие deployment, т. е. когда выкатывается новая версия вашего приложения. Разработчики Kubernetes почему-то решили добавить id’шку deployment’а в label.
К чему это привело? К тому, что при каждом новом deployment’е у нас все старые временные ряды прерываются, а вместо них начинаются новые временные ряды с новым значением лейбла deployment_id. Таких рядов может быть сотни тысяч и даже миллионы.
Важная особенность всего этого в том, что общее количество временных рядов растет, но количество временных рядов, которые в данный момент активны, на которые приходят данные, остается постоянным. Такое состояние называется – high churn rate.
Основная проблема high churn rate в том, чтобы обеспечить постоянную скорость поиска всех временных рядов по заданному набору лейблов за какой-то интервал времени. Обычно это интервал времени за последний час или за последний день.
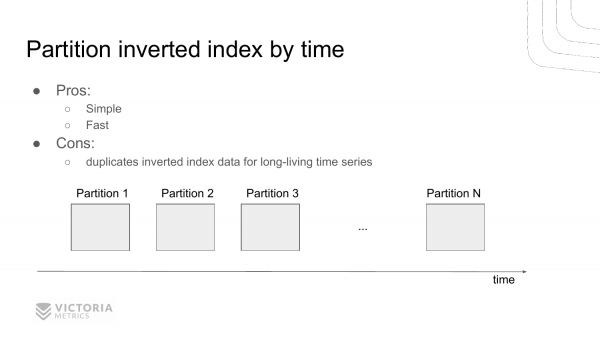
Как эту проблему решить? Вот первый вариант. Это разделять инвертированный индекс на независимые части по времени. Т. е. проходит какой-то интервал времени, заканчиваем работать с инвертированным индексом текущим. И создаем новый инвертированный индекс. Проходит еще один интервал времени, создаем еще один и еще один.
И при выборке из этих инвертированных индексов мы находим набор инвертированных индексов, которые попадают в заданный интервал. И, соответственно, выбираем оттуда id временных рядов.
Это позволяет сэкономить ресурсы, потому что нам не нужно просматривать части, которые не попадают в заданный интервал. Т. е. обычно, если мы выбираем данные за последний час, то за предыдущие временные интервалы мы пропускаем запросы.

Есть еще один вариант решения этой проблемы. Это хранить для каждого дня отдельный список id временных рядов, которые встретились за этот день.
Преимущество этого решения по сравнению с предыдущим решением в том, что мы не дублируем информацию об временных рядах, которые не исчезают с течением времени. Они постоянно находятся и не меняются.
Недостаток в том, что такое решение сложнее в реализации и сложнее в дебаге. И VictoriaMetrics выбрала это решение. Так сложилось исторически. Такое решение тоже показывает себя неплохо, по сравнению с предыдущим. Потому что это решение не было реализовано из-за того, что приходится дублировать данные в каждом partition для временных рядов, которые не изменяются, т. е. которые не исчезают с течением времени. VictoriaMetrics была в первую очередь оптимизирована по потреблению дискового пространства, и предыдущая реализация ухудшала потребление дискового пространства. А вот эта реализация лучше подходит для минимизации потребления дискового пространства, поэтому она была выбрана.
Пришлось с ней бороться. Борьба заключалась в том, что в данной реализации нужно все равно выбирать намного большее количество timeseries_ids для данных, чем, когда инвертированный индекс разделен по времени.

Как мы решили эту проблему? Мы ее решили оригинальным образом – путем сохранения нескольких идентификаторов временных рядов в каждой записи инвертированного индекса вместо одного идентификатора. Т. е. у нас есть ключ label=value, который встречается в каждом временном ряду. И теперь мы сохраняем несколько timeseries_ids в одной записи.
Вот пример. Раньше у нас было N записей, а теперь у нас есть одна запись, префикс у которой такой же, как и у всех остальных. У предыдущей записи значение содержит все id временных рядов.
Это позволило увеличить скорость сканирования такого инвертированного индекса до 10 раз. И позволило уменьшить потребление памяти для кэша, потому что теперь мы храним строку label=value только один раз в кэше вместе N раз. И эта строка может быть большой, если у вас в тегах и labels хранятся длинные строчки, которые любит туда пихать Kubernetes.
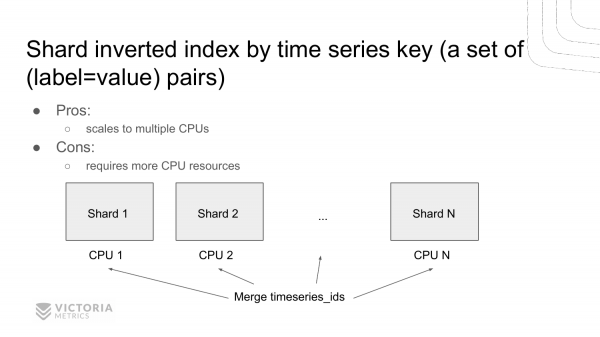
Еще один вариант ускорения поиска по инвертированному индексу – это шардирование. Создание нескольких инвертированных индексов вместо одного и шардирование данных между ними по ключу. Это набор key=value пар. Т. е. у нас получается несколько независимых инвертированных индексов, которые мы можем опрашивать параллельно на нескольких процессорах. Предыдущие реализации позволяли работать только в однопроцессорном режиме, т. е. сканировать данные только на одном ядре. Данное решение позволяет сканировать данные сразу на нескольких ядрах, как это любит делать ClickHouse. Это мы планируем реализовать.

А теперь вернемся к нашим баранам – к функции пересечения timeseries_ids. Рассмотрим, какие могут быть реализации. Эта функция позволяет находить timeseries_ids для заданного набора label=value.

Первый вариант – это наивная реализация. Два вложенных цикла. Вот мы получаем на входе функции intersectInts два slices — a и b. На выходе она должна вернуть нам пересечение этих slices.
Наивная реализация выглядит так. Мы проходимся по всем значениям из slice a, внутри этого цикла проходимся по всем значениям slice b. И сравниваем их. Если они совпадают, значит, мы нашли пересечение. И сохраняем его в result.

Какие есть недостатки? Квадратичная сложность — это главный ее недостаток. Например, если у вас размеры slice a и b по одному миллиону, то эта функция никогда вам не вернет ответ. Потому что ей нужно будет сделать один триллион итераций, что очень много даже для современных компьютеров.

Вторая реализация основана на map. Мы создаем map. Помещаем в эту map все значения из slice a. Затем пробегаемся отдельным циклом по slice b. И проверяем – есть ли это значение из slice b в map. Если оно есть, то добавляем его в результат.

Какие преимущества? Преимущество в том, что тут только линейная сложность. Т. е. функция намного быстрее выполнится для больших размеров slices. Для миллионного размера slice эта функция выполнится за 2 миллиона итераций, в отличии от триллиона итераций, как в предыдущей функции.
А недостаток в том, что эта функция требует больше памяти для того, чтобы создать эту map.
Второй недостаток – это большой overhead на хеширование. Этот недостаток не очень очевидный. И для нас он тоже был не очень очевидным, поэтому вначале в VictoriaMetrics реализация intersection была через map. Но потом профилирование показало, что основное процессорное время тратится на запись в map и на проверку наличия значения в этой map.
Почему в этих местах тратится процессорное время? Потому что в данных строчках Go производит операцию хеширования. Т. е. он вычисляет hash от ключа, чтобы обратиться потом по заданному индексу в HashMap. Операция по вычислению hash’а выполняется за десятки наносекунд. Это медленно для VictoriaMetrics.

Я решил реализовать bitset, оптимизированный специально для этого случая. Вот как теперь выглядит пересечение двух slices. Тут создаем bitset. Добавляем в него элементы из первого slice. Потом проверяем наличие этих элементов во втором slice. И добавляем их в результат. Т. е. почти не отличается от предыдущего примера. Единственное, что мы здесь заменили обращение к map кастомными функциями add и has.

С первого взгляда кажется, что это должно работать медленней, если раньше там использовалась стандартная map, а тут еще какие-то функции вызываются, но профилирование показывает, что эта штука работает в 10 раз быстрее, чем стандартная map для случая с VictoriaMetrics.
Кроме этого, она использует гораздо меньше памяти по сравнению с реализацией на map. Потому что мы храним здесь биты вместо восьмибайтовых значений.
Недостаток у такой реализации в том, что она не такая очевидная, не тривиальная.
Еще один недостаток, который многие могут не замечать – это то, что данная реализация может плохо работать в некоторых случаях. Т. е. она оптимизирована для конкретного случая, для данного случая пересечения ids временных рядов VictoriaMetrics. Это не значит, что она подойдет для всех случаев. Если ее неправильно использовать, то получим не прирост производительности, а out of memory error и замедление производительности.

Рассмотрим реализацию данной структуры. Если хотите посмотреть, то она находится в исходниках VictoriaMetrics, в папке . Она оптимизирована именно для случая VictoriaMetrics, где timeseries_id представляет из себя 64-битное значение, где первые 32 бита в основным постоянные и меняются только последние 32 бита.
Эта структура данных не хранится на диске, она работает только в памяти.

Вот ее API. Он не очень сложный. API подогнан именно под конкретный пример использования VictoriaMetrics. Т. е. тут нет лишних функций. Здесь функции, которые явно используются VictoriaMetrics.
Есть функции add, которая добавляет новые значения. Есть функция has, которая проверяет новые значения. И есть функция del, которая удаляет значения. Есть вспомогательная функция len, которая возвращает размер множества. Функция clone клонирует множество. И функция appendto преобразует этот сет в slice timeseries_ids.

Вот как выглядит реализация этой структуры данных. В set есть два элемента:
ItemsCount– это вспомогательное поле, чтобы быстро вернуть количество элементов в set. Можно было бы обойтись без этого вспомогательного поля, но его пришлось добавить сюда, потому что VictoriaMetrics часто опрашивает в своих алгоритмах длину bitset.Второе поле – это
buckets. Это slice из структурыbucket32. В каждой структуре хранитсяhiполе. Это верхние 32 бита. И два slice —b16hisиbucketsизbucket16структур.
Тут хранятся верхние 16 бит второй части 64-битной структуры. А здесь хранятся bitsets для младших 16 бит каждого байта.
Bucket64 состоит из массива uint64. Длина вычисляется с помощью этих констант. В одном bucket16 максимум может хранится 2^16=65536 бит. Если это поделить на 8, то это 8 килобайт. Если поделить еще раз на 8, то это 1000 uint64 значении. Т. е. Bucket16 – это у нас 8-килобайтная структура.

Рассмотрим, как реализован один из методов этой структуры добавления нового значения.
Все начинается с uint64 значения. Вычисляем верхние 32 бита, вычисляем нижние 32 бита. Проходимся по всем buckets. Сравниваем верхние 32 бита в каждом bucket с добавляемым значением. И если они совпадают, то вызываем функцию add в структуре b32 buckets. И добавляем туда нижние 32 бита. И если это вернуло true, то это значит, что мы добавили такое значение туда и у нас такого значения не было. Если он возвращает false, то такое значение уже было. Затем увеличиваем количество элементов в структуре.
Если мы не нашли нужный bucket с нужным hi-значением, то мы вызываем функцию addAlloc, которая выделает новый bucket, добавляя его в bucket-структуру.

Это реализация функции b32.add. Она похожа на предыдущую реализацию. Мы вычисляем старшие 16 бит, младшие 16 бит.
Потом мы проходимся по всем верхним 16 битам. Находим совпадения. И при совпадении вызываем метод add, который рассмотрим на следующей странице для bucket16.

И вот самый нижний уровень, который должен быть максимально оптимизирован. Мы вычисляем для uint64 id значение в slice bit, а также bitmask. Это маска для данного 64-битного значения, по которой можно проверить наличие этого бита, либо установить его. Мы проверяем наличие этого бита, установленного и устанавливаем его, и возвращаем наличие. Вот такая реализация у нас, которая позволила ускорить операцию пересечения ids временных рядов в 10 раз по сравнению с обычными maps.

В VictoriaMetrics помимо этой оптимизации есть много других оптимизаций. Большинство из этих оптимизаций добавлены не просто так, а после профилирования кода в production.
Это главное правило оптимизации – не добавлять оптимизацию, предполагая, что здесь будет узкое место, потому что может оказаться, что там не будет узкого места. Оптимизация обычно ухудшает качество кода. Поэтому стоит оптимизировать только после профилирования и желательно в production, чтобы это были реальные данные. Кому интересно, можете посмотреть исходники VictoriaMetrics и изучить другие оптимизации, которые там есть.

У меня вопрос про bitset. Очень похоже на реализацию C++ vector bool, оптимизированный bitset. Вы оттуда взяли реализацию?
Нет, не оттуда. При реализации этого bitset я ориентировался на знания структуры этих ids timeseries, которые используютя в VictoriaMetrics. А структура у них такая, что верхние 32 бита в основном постоянны. Нижние 32 бита могут меняться. Чем ниже бит, тем чаще он может меняться. Поэтому эта реализация именно оптимизирована под данную структуру данных. C++ реализация, насколько я знаю, оптимизирована под общий случай. Если делать оптимизацию под общий случай, то это значит, что она будет не самой оптимальной под конкретный случай.
Советую вам еще посмотреть доклад Алексея Миловида. Он где-то с месяц назад рассказывал про оптимизации в ClickHouse под конкретные специализации. Он как раз рассказывает, что в общем случае C++ реализация или какая-нибудь другая реализация заточены под хорошую работу в среднем по больнице. Она может работать хуже, чем специализированная реализация под конкретные знания, как у нас, когда мы знаем, что верхние 32 бита в основном постоянны.
У меня второй вопрос. В чем кардинальное отличие от InfluxDB?
Кардинальных отличий много. Если по производительности и по потреблению памяти, то InfluxDB в тестах показывает в 10 раз больше потребления памяти для high cardinality временных рядов, когда их у вас много, например, миллионы. Например, VictoriaMetrics потребляет 1 GB на миллион активных рядов, а InfluxDB при этом потребляет 10 Gb. И это большая разница.
Второе кардинальное отличие в том, что в InfluxDB странные языки запросов – Flux и InfluxQL. Они не очень удобны для работы с временными рядами по сравнению с , который поддерживается в VictoriaMetrics. PromQL – это язык запросов из Prometheus.
И еще одно отличие – это то, что у InfluxDB немного странноватая модель данных, где в каждой строчке может храниться несколько fields с разным набором тегов. Эти строчки делятся еще на всякие таблицы. Вот эти дополнительные усложнения усложняют последующую работу с этой базой. Ее сложно поддерживать и понимать.
В VictoriaMetrics все гораздо проще. Там каждый временной ряд представляет из себя ключ-значение. Значение – это набор точек – (timestamp, value), а ключ – это набор label=value. Нет никакого разделения на fields и measurements. Это позволяет вам выбирать любые данные, а затем их комбинировать, складывать, вычитать, умножать, делить в отличие от InfluxDB, где вычисления между разными рядами до сих пор не реализованы, насколько я знаю. Если даже реализованы, то сложно, надо писать кучу кода.
У меня есть уточняющий вопрос. Я правильно понял, что была какая-то проблема, про которую вы рассказывали, что этот инвертированный индекс не вмещается в память, поэтому там партицирование идет?
Вначале я показал наивную реализацию инвертированного индекса на стандартной Go’шной map’е. Такая реализация не подходит для баз данных, потому что этот инвертированный индекс не сохраняется на диске, а база данных должна сохранять на диск, чтобы при рестарте эти данные оставались доступными. В данной реализации при рестарте приложения у вас инвертированный индекс пропадет. И вы потеряете доступ ко всем данным, потому что не сможете найти их.
Здравствуйте! Спасибо за доклад! Меня зовут Павел. Я из компании Wildberries. У меня несколько вопросов к вам. Вопрос первый. Как вам кажется, если бы вы выбрали другой принцип при построении архитектуры своего приложения и партиционировали данные по времени, то, возможно, у вас получилось бы делать пересечение данных при поиске, основываясь только на том, что в одной партиции находится данные за один промежуток времени, т. е. за один интервал времени и вам бы не пришлось заботиться о том, что у вас куски по-разному разбросаны? Вопрос номер 2 — раз вы реализуете подобный алгоритм с bitset и всем остальным, то, возможно, вы пробовали использовать инструкции процессора? Может быть, вы пробовали такие оптимизации?
На второй сразу отвечу. Мы до этого еще не дошли. Но если надо будет, дойдем. А первый, какой был вопрос?
Вы обсуждали два сценария. И сказали, что выбрали второй с более сложной имплементацией. И не предпочли первый, где данные партиционированы по времени.
Да. В первом случае суммарный объем индекса был бы больше, потому что мы в каждой партиции должны были бы хранить дубли данных для тех временных рядов, которые продолжаются сквозь эти все партиции. И если у вас churn rate у временных рядов небольшой, т. е. постоянно одни и те же ряды используются, то в первом случае мы бы намного сильнее проиграли в объеме занимаемого дискового пространства по сравнению со вторым случаем.
А так – да, партиционирование по времени – хороший вариант. Его Prometheus использует. Но в Prometheus есть другой недостаток. При слиянии этих кусков данных, ему требуется держать в памяти мета-информацию по всем label и timeseries. Поэтому, если куски данных большие, которые он сливает, то потребление памяти очень сильно растет при слиянии, в отличии от VictoriaMetrics. При слиянии VictoriaMetrics вообще не потребляет память, там какие-то пара килобайт потребляются, независимо от размеров объединяемых кусков данных.
Алгоритм, который у вас используется, он использует память. В ней отмечаются timeseries-метки, на которых есть значения. И таким образом вы проверяете парное наличие в одном массиве данных и в другом. И понимаете – произошел intersect или нет. Обычно в базах данных реализуют курсоры, итераторы, хранящие текущее свое состоящее и бегущее по отсортированным данным за счет вы имеете простую сложность у данных операций.
Почему мы не используем курсоры для пересечения данных?
Да.
У нас в LevelDB или в mergeset хранятся как раз отсортированные строчки. Мы можем курсором пройтись и найти пересечение. А почему не используем? Потому что – это медленно. Потому что курсоры подразумевают под собой, что на каждую строчку нужно вызвать функцию. Вызов функции – это 5 наносекунд. И если у вас 100 000 000 строчек, то получается, что мы тратим полсекунды только на вызов функции.
Такое есть, да. И последний у меня вопрос. Вопрос, может быть, немного странно прозвучит. Почему в момент поступления данных нельзя считать все необходимые агрегаты и в необходимом виде их сохранять? Зачем сохранять огромные объемы в какие-то системы типа VictoriaMetrics, ClickHouse и т. д., чтобы потом очень много времени тратить на них?
Приведу пример, чтобы было понятней. Допустим, как работает маленький игрушечный спидометр? Он записывает расстояние, которое вы проехали, все время его добавляя в одну величину, во вторую – время. И делит. И получает среднюю скорость. Можно делать примерно тоже самое. Складывать налету все необходимые факты.
Хорошо, понял вопрос. Ваш пример имеет место для жизни. Если вы знаете, какие вам нужны агрегаты, то это самая лучшая реализация. Но проблема в том, что люди сохраняют эти метрики, какие-то данные в ClickHouse и они не знают еще, как они в будущем будут их агрегировать, фильтровать, поэтому приходится сохранять все сырые данные. Но если вы знаете, что вам нужно подсчитать что-то среднее, то почему бы не подсчитать его, вместо того, чтобы сохранять там кучу сырых значений? Но это только в том случае, если вы точно знаете, что вам нужно.
Кстати, базы для хранения временных рядов поддерживают подсчет агрегатов. Например, Prometheus поддерживает . Т. е. это можно сделать, если вы знаете, какие вам понадобятся агрегаты. В VictoriaMetrics этого пока нет, но перед ней обычно ставится Prometheus, в котором можно это сделать в recoding rules.
Например, на предыдущей работе нужно было подсчитывать количество событий в скользящем окне за последний час. Проблема в том, что пришлось делать кастомную реализацию на Go, т. е. сервис для подсчета этой штуки. Этот сервис был в итоге нетривиальным, потому что это сложно считать. Реализация может быть простой, если вам нужно считать какие-то агрегаты на фиксированных интервалах времени. Если же вы хотите считать события в скользящем окне, то это не так просто, как кажется. Я думаю, это не реализовано до сих пор в ClickHouse или в timeseries-базах, потому что сложно в реализации.
И еще один вопрос. Мы сейчас говорили об усреднении, и я вспомнил, что когда-то была такая штука как Graphite с бэкендом Carbon. И он умел старые данные прореживать, т. е. оставлять одну точку в минуту, одну точку в час и т. д. В принципе, это достаточно удобно, если нам нужны сырые данные, условно говоря, за месяц, а все остальное можно проредить. Но Prometheus, VictoriaMetrics эту функциональность не поддерживают. Планируется ли поддерживать? Если нет, то почему?
Спасибо за вопрос. Наши пользователи его периодически задают. Спрашивают, когда мы добавим поддержку прореживания (downsampling). Тут несколько проблем. Во-первых, каждый пользователь понимает под downsampling что-нибудь свое: кто-то хочет получить любую произвольную точку на заданном интервале, кто-то хочет максимальные, минимальные, средние значения. Если в вашу базу пишут данные многие системы, то нельзя их грести под одну гребенку. Может оказаться, что для каждой системы нужно использовать разное прореживание. И это сложно в реализации.
И второе – это то, что VictoriaMetrics, как и ClickHouse, оптимизирована под работу над большим объемом сырых данных, поэтому она может перелопатить миллиард строчек меньше, чем за секунду, если у вас есть много ядер в вашей системе. Сканирование точек временного ряда в VictoriaMetrics – 50 000 000 точек в секунду на одно ядро. И эта производительность масштабируется на имеющиеся ядра. Т. е. если у вас 20 ядер, например, то получится сканирование миллиарда точек в секунду. И это свойство VictoriaMetrics и ClickHouse снижает потребность в downsamling.
Еще одно свойство в том, что VictoriaMetrics эффективно сжимает эти данные. Сжатие в среднем на production от 0,4 до 0,8 байт на точку. Каждая точка – это timestamp + значение. И она сжимается меньше, чем в один байт в среднем.
Сергей. У меня есть вопрос. Какой минимальный квант времени записи?
Одна миллисекунда. Недавно у нас был разговор с другими разработчиками баз данных для временных рядов. У них минимальный квант времени – это одна секунда. И в Graphite, например, тоже одна секунда. В OpenTSDB тоже одна секунда. В InfluxDB – наносекундная точность. В VictoriaMetrics – одна миллисекунда, потому что в Prometheus одна миллисекунда. И VictoriaMetrics разрабатывалась как remote storage для Prometheus первоначально. Но сейчас она может сохранять данные и из других систем.
Человек, с которым я разговаривал, говорит, что у них секундная точность — им этого достаточно, потому что это зависит от типа данных, которые сохраняются в базу временных рядов. Если это DevOps-данные или данные с инфраструктуры, где вы собираете их с интервалом в 30 секунд, в минуту, то там секундной точности достаточно, меньше уже не надо. А если вы собираете эти данные high frequency trading systems, то там нужна наносекундная точность.
Миллисекундная точность в VictoriaMetrics подходит и для DevOps-кейса, и может подойти для большинства кейсов, которые я упомянул в начале доклада. Единственное, для чего она может не подойти – это high frequency trading systems.
Спасибо! И еще вопрос. Какая совместимость в PromQL?
Полная обратная совместимость. VictoriaMetrics поддерживает полностью PromQL. Кроме этого она добавляет еще дополнительную расширенную функциональность на PromQL, которая называется . По поводу этой расширенной функциональности есть доклад на YouTube. Я рассказывал на Monitoring Meetup весной в Питере.
Telegram канал .
Только зарегистрированные пользователи могут участвовать в опросе. , пожалуйста.
Что вам мешает перейти на VictoriaMetrics как долгосрочное хранилище для Prometheus? (Пишите в комментариях, я добавлю в опрос))
71,4%Не использую Prometheus5
28,6%Не знал про VictoriaMetrics2
Проголосовали 7 пользователей. Воздержались 12 пользователей.
Источник: habr.com
