


Попалась мне задача следующего вида. Необходимо реализовать контейнер хранения данных обеспечивающий следующий функционал:
- вставить новый элемент
- удалить элемент по порядковому номеру
- получить элемент по порядковому номеру
- данные хранятся в сортированном виде
Данные постоянно добавляются и удаляются, структура должна обеспечивать быструю скорость работы. Сначала пытался реализовать такую вещь используя стандартные контейнеры из std. Этот путь не увенчался успехом и пришло понимание, что нужно реализовывать что-то самому. Единственное что пришло на ум, это использовать бинарное дерево поиска. Поскольку оно отвечает требованию быстрой вставки, удалению и хранению данных в сортированном виде. Осталось только придумать как проиндексировать все элементы и пересчитывать индексы когда дерево меняется.
struct node_s {
data_t data;
uint64_t weight; // вес узла
node_t *left;
node_t *right;
node_t *parent;
};В статье будет больше картинок и теории чем кода. Код можно будет посмотреть по ссылке внизу.
Вес
Для этого дерево подверглось небольшой модифицикации, добавилась дополнительная информация о весе узла. Вес узла это кол-во потомков данного узла + 1 (вес единичного элемента).
Функция получения веса узла:
uint64_t bntree::get_child_weight(node_t *node) {
if (node) {
return node->weight;
}
return 0;
}У листа соответственно вес равен 0.
Далее перейдем к наглядному представлению примера такого дерева. Черным цветом в нем будет показан ключ узла (значение показано не будет, т.к. в этом нет надобности), красным — вес узла, зеленым — индекс узла.
Когда дерево у нас пусто, то его вес равен 0. Добавим в него корневой элемент:
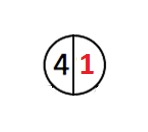
Вес дерева становится 1, вес корневого элемента 1. Вес корневого элемента является весом дерева.
Добавим еще несколько элементов:
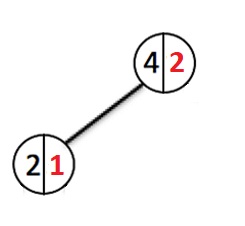
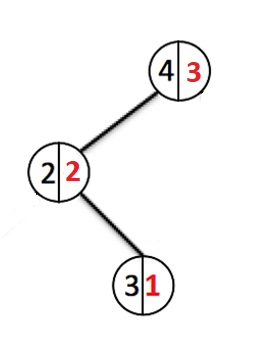
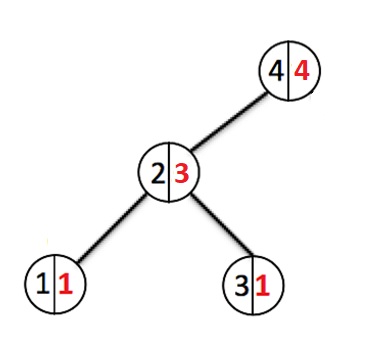
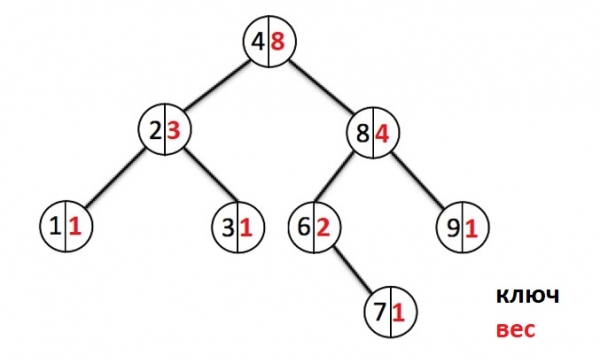
Каждый раз когда идет добавление нового элемента, мы спускаемся по узлам в низ и увеличиваем счетчик веса каждого пройденного узла. При создании нового узла ему выставляется вес 1. Если узел с таким ключом уже существует, то перезапишем значение и пойдем назад до корня вверх отменяя изменения весов у всех узлов которые мы прошли.
Если идет удаление узла, то мы спускается вниз и декрементируем веса пройденных узлов.
Индексы
Теперь перейдем к тому как проиндексировать узлы. Узлы явно не хранят свой индекс, он вычисляется на основе веса узлов. Если бы они хранили свой индекс, то требовалось бы O(n) времени, что бы обновить индексы всех узлов после каждого изменения дерева.
Перейдем к наглядному представлению. Наше дерево пусто, добавим в него 1-ый узел:
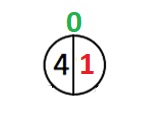
Первый узел имеет индекс 0, а теперь возможны 2-а случая. В первом индекс корневого элемента изменится, во втором не изменится.
У корня левое поддерево весит 1.
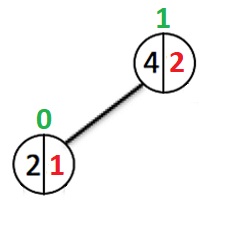
Второй случай:
Индекс корня не изменился, поскольку вес его левого поддерева остался 0.
Как считается индекс узла, это вес его левого поддерева + число переданное от родителя. Что это за число?, Это счетчик индексов, изначально он равен 0, т.к. у корня нет родителя. Дальше все зависит от того куда мы спускаемся к левому ребенку или правому. Если к левому, то к счетчику ни чего не прибавляется. Если к правому то прибавляем индекс текущего узла.
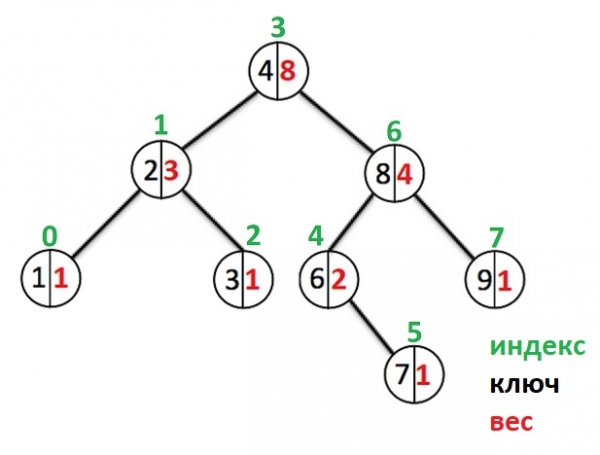
К примеру как вычисляется индекс элемента с ключом 8 (правый ребенок корня). Это «Индекс корня» + «вес левого поддерева узла с ключом 8» + «1» == 3 + 2 + 1 == 6
Индексом элемента с ключом 6 будет «Индекс корня» + 1 == 3 + 1 == 4
Соответственно что бы получить, удалить элемент по индексу требуется время O(log n), поскольку что бы получить нужный элемент мы должны сначала его найти (спуститься от корня до этого элемента).
Глубина
На основе веса так же можно вычислить и глубину дерева. Необходимую для балансировки.
Для этого вес текущего узла надо округлить до первого числа в степени 2 которое больше или ровно данному весу и взять от него двоичный логарифм. Таким образом мы получим глубину дерева, при условии что оно сбалансировано. Дерево балансируется после вставки нового элемента. Теорию про то как балансировать деревья приводить не буду. В исходных кодах представлена функция балансировки.
Код приведения веса к глубине.
/*
* Возвращает первое число в степени 2, которое больше или ровно x
*/
uint64_t bntree::cpl2(uint64_t x) {
x = x - 1;
x = x | (x >> 1);
x = x | (x >> 2);
x = x | (x >> 4);
x = x | (x >> 8);
x = x | (x >> 16);
x = x | (x >> 32);
return x + 1;
}
/*
* Двоичный логарифм от числа
*/
long bntree::ilog2(long d) {
int result;
std::frexp(d, &result);
return result - 1;
}
/*
* Вес к глубине
*/
uint64_t bntree::weight_to_depth(node_t *p) {
if (p == NULL) {
return 0;
}
if (p->weight == 1) {
return 1;
} else if (p->weight == 2) {
return 2;
}
return this->ilog2(this->cpl2(p->weight));
}Итоги
- вставка нового элемента происходит за O(log n)
- удаление элемента по порядковому номеру происходит за O(log n)
- получение элемента по порядковому номеру происходит за O(log n)
Скоростью O(log n) платим за то, что все данные хранятся в сортированном виде.
Где может пригодиться такая структура — не знаю. Просто задачка, что бы еще раз разобраться как работают деревья. Спасибо за внимание.
Ссылки
В проекте содержатся тестовые данные для проверки скорости работы. Дерево заполняется 1000000 элементов. И происходит последовательное удаление, вставка и получение элементов 1000000 раз. То есть 3000000 операций. Результат оказался вполне неплохим ~ 8 секунд.
Источник: habr.com
