

Как и в , появилась проблема с распределённой службой, назовём эту службу Элвин. На этот раз я не сам обнаружил проблему, мне сообщили ребята с клиентской части.
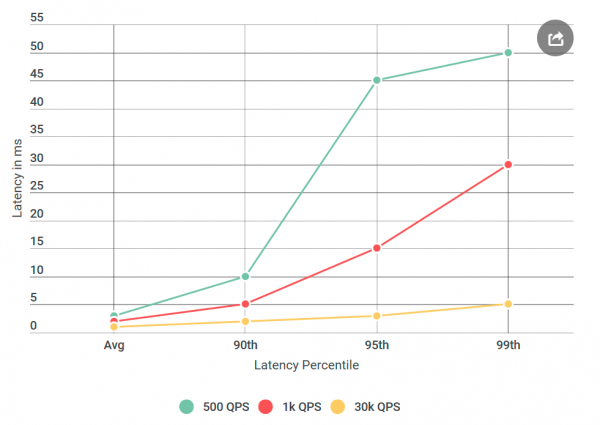
Однажды я проснулся от недовольного письма из-за больших задержек у Элвина, которого мы планировали запустить в ближайшее время. В частности, клиент столкнулся с задержкой 99-го процентиля в районе 50 мс, намного выше нашего бюджета задержки. Это было удивительно, так как я тщательно тестировал сервис, особенно на задержки, ведь это предмет частых жалоб.
Прежде чем отдать Элвина в тестирование, я провёл много экспериментов с 40 тыс. запросов в секунду (QPS), все показали задержку менее 10 мс. Я готов был заявить, что не согласен с их результатами. Но ещё раз взглянув на письмо, я обратил внимание на что-то новое: я точно не тестировал условия, которые они упомянули, их QPS был намного ниже, чем мой. Я тестировал на 40k QPS, а они только на 1k. Я запустил ещё один эксперимент, на этот раз с более низким QPS, просто чтобы ублажить их.
Поскольку я пишу об этом в блоге — вероятно, вы уже поняли: их цифры оказались правильными. Я проверял своего виртуального клиента снова и снова, всё с тем же результатом: низкое количество запросов не только увеличивает задержку, но увеличивает количество запросов с задержкой более 10 мс. Другими словами, если на 40k QPS около 50 запросов в секунду превышали 50 мс, то на 1k QPS каждую секунду было 100 запросов выше 50 мс. Парадокс!
Сужаем круг поиска
Столкнувшись с проблемой задержки в распределённой системе со многими компонентами первым делом нужно составить короткий список подозреваемых. Копнём немного глубже в архитектуру Элвина:
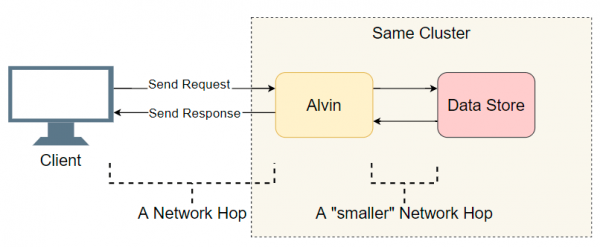
Хорошей отправной точкой является список выполненных переходов ввода-вывода (сетевые вызовы/поиск по диску и т. д.). Попытаемся выяснить, где задержка. Помимо очевидного ввода-вывода с клиентом, Элвин делает дополнительный шаг: он обращается к хранилищу данных. Однако это хранилище работает в одном кластере с Элвином, поэтому там задержка должна быть меньше, чем с клиентом. Итак, список подозреваемых:
- Сетевой вызов от клиента к Элвину.
- Сетевой вызов от Элвина к хранилищу данных.
- Поиск на диске в хранилище данных.
- Сетевой вызов из хранилища данных к Элвину.
- Сетевой вызов от Элвина к клиенту.
Попробуем вычеркнуть некоторые пункты.
Хранилище данных ни при чём
Первым делом я преобразовал Элвина в сервер ping-ping, который не обрабатывает запросы. Получив запрос, он возвращает пустой ответ. Если задержка уменьшается, то ошибка в реализации Элвина или хранилища данных — ничего такого неслыханного. В первом эксперименте получаем такой график:
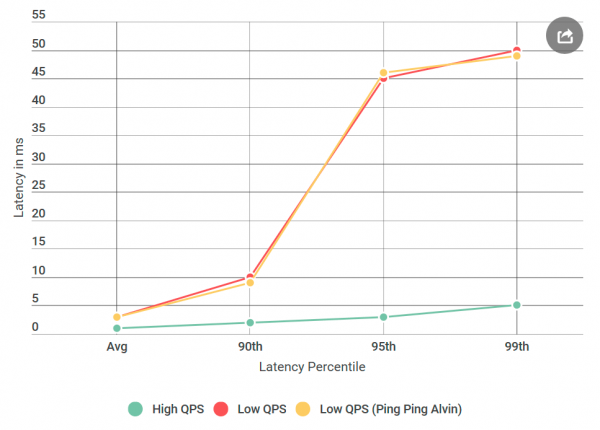
Как видим, при использовании сервера ping-ping не наблюдается никаких улучшений. Это означает, что хранилище данных не увеличивает задержку, а список подозреваемых сокращается вдвое:
- Сетевой вызов от клиента к Элвину.
- Сетевой вызов от Элвина к клиенту.
Здорово! Список быстро сокращается. Я думал, что почти выяснил причину.
gRPC
Сейчас самое время представить вам нового игрока: . Это библиотека с открытым исходным кодом от Google для внутрипроцессной связи . Хотя gRPC хорошо оптимизирован и широко используется, я первый раз использовал его в системе такого масштаба, и я ожидал, что моя реализация будет неоптимальной — мягко говоря.
Наличие gRPC в стеке породило новый вопрос: может, это моя реализация или сам gRPC вызывает проблему задержки? Добавляем в список нового подозреваемого:
- Клиент вызывает библиотеку
gRPC - Библиотека
gRPCна клиенте выполняет сетевой вызов библиотекиgRPCна сервере - Библиотека
gRPCобращается к Элвину (операции нет в случае сервера ping-pong)
Чтобы вы понимали, как выглядит код, моя реализация клиента/Элвина не сильно отличается от клиент-серверных .
Примечание: приведённый выше список немного упрощён, так как
gRPCдаёт возможность использования собственной (шаблонной?) потоковой модели, в которой переплетаются стек выполненияgRPCи реализация пользователя. Ради простоты будем придерживаться этой модели.
Профилирование всё исправит
Вычеркнув хранилища данных, я подумал, что почти закончил: «Теперь легко! Применим профиль и узнаем, где возникает задержка». Я , потому что CPU очень быстры и чаще всего не являются узким местом. Большинство задержек происходит, когда процессор должен остановить обработку, чтобы сделать что-то ещё. Точное профилирование CPU сделано именно для этого: оно точно записывает все и даёт понять, где возникают задержки.
Я взял четыре профиля: под высоким QPS (маленькая задержка) и с ping-pong сервером на низком QPS (большая задержка), как на стороне клиента, так и на стороне сервера. И просто на всякий случай также взял образец профиля процессора. При сравнении профилей я обычно ищу аномальный стек вызовов. Например, на плохой стороне с высокой задержкой происходит гораздо больше переключений контекста (в 10 и больше раз). Но в моём случае количество переключений контекста практически совпадало. К моему ужасу, там не оказалось ничего существенного.
Дополнительная отладка
Я был в отчаянии. Я не знал, какие ещё инструменты можно использовать, а мой следующий план состоял по сути в повторении экспериментов с разными вариациями, а не чётком диагностировании проблемы.
Что, если
С самого начала меня беспокоила конкретное время задержки 50 мс. Это очень большое время. Я решил, что буду вырезать куски из кода, пока не смогу выяснить точно, какая часть вызывает эту ошибку. Затем последовал эксперимент, который сработал.
Как обычно, задним умом кажется, что всё было очевидно. Я поместил клиента на одну машину с Элвином — и отправил запрос в localhost. И увеличение задержки исчезло!
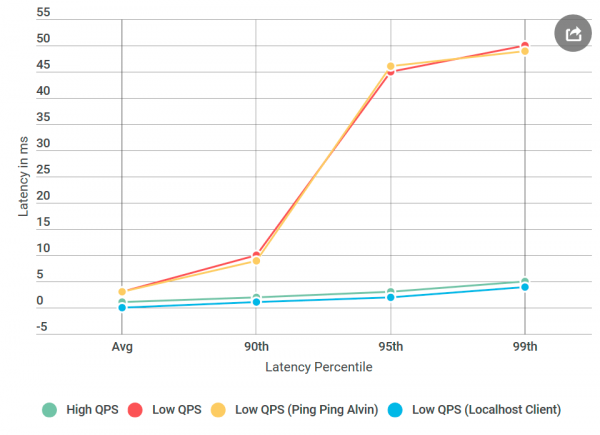
Что-то было не так с сетью.
Осваиваем навыки сетевого инженера
Должен признаться: мои знания сетевых технологий ужасны, особенно с учётом того, что я с ними работаю ежедневно. Но сеть была главным подозреваемым, и мне нужно было научиться, как её отлаживать.
К счастью, интернет любит тех, кто хочет учиться. Сочетание ping и tracert казалось достаточно хорошим началом для отладки проблем сетевого транспорта.
Во-первых, я запустил на TCP-порт Элвина. Я использовал параметры по умолчанию — ничего особенного. Из более тысячи пингов ни один не превысил 10 мс, за исключением первого для разогрева. Это противоречит наблюдаемому увеличению задержки 50 мс в 99-м процентиле: там на каждые 100 запросов мы должны были увидеть около одного запроса с задержкой 50 мс.
Затем я попробовал : может, проблема на одном из узлов по маршруту между Элвином и клиентом. Но и трейсер вернулся с пустыми руками.
Таким образом, причиной задержки был не мой код, не реализация gRPC и не сеть. Я уже начал волноваться, что никогда этого не пойму.
Теперь, на какой ОС мы находимся
gRPC широко используется в Linux, но для Windows это экзотика. Я решил провести эксперимент, который сработал: я создал виртуальную машину Linux, скомпилировал Элвина для Linux и развернул её.
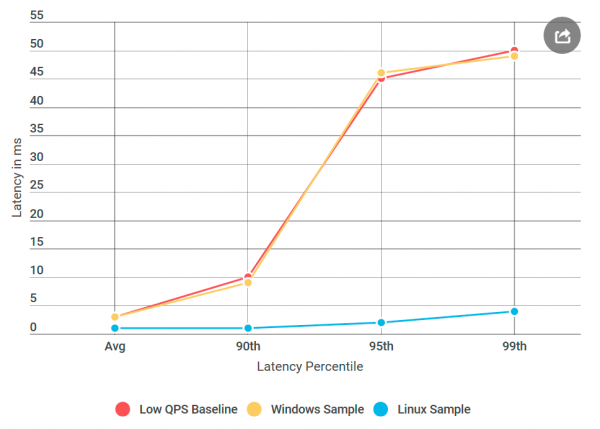
И вот что получилось: в ping-pong сервере Linux не было таких задержек, как у аналогичного узла Windows, хотя источник данных не отличался. Оказывается, проблема в реализации gRPC для Windows.
Алгоритм Нейгла
Всё это время я думал, что мне не хватает флага gRPC. Теперь я понял, что на самом деле это в gRPC не хватает флага Windows. Я нашёл внутреннюю библиотеку RPC, в которой был уверен, что она хорошо работает для всех установленных флагов . Затем добавил все эти флаги в gRPC и развернул Элвина на Windows, в исправленном сервере ping-pong под Windows!
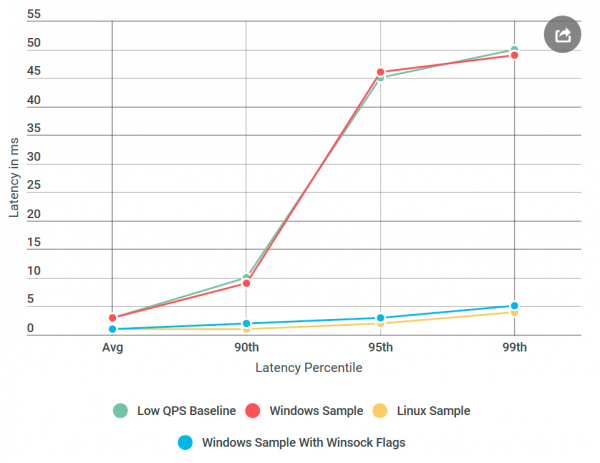
Почти готово: я начал удалять добавленные флаги по одному, пока не вернулась регрессия, так что я смог точно определить её причину. Это был печально известный , переключатель алгоритма Нейгла.
пытается уменьшить количество пакетов, отправленных по сети, путём задержки передачи сообщений до тех пор, пока размер пакета не превысит определённое количество байт. Хотя это может быть приятно для среднего пользователя, но разрушительно для серверов реального времени, поскольку ОС будет задерживать некоторые сообщения, вызывая задержки на низком QPS. У gRPC был установлен этот флаг в реализации Linux для сокетов TCP, но не для Windows. Я это .
Заключение
Большую задержку на низком QPS вызвала оптимизация ОС. Оглядываясь назад, профилирование не обнаружило задержку, потому что проводилось в режиме ядра, а не в . Не знаю, можно ли наблюдать алгоритм Нейгла через захваты ETW, но это было бы интересно.
Что касается эксперимента localhost, он, вероятно, не касался фактического сетевого кода, и алгоритм Нейгла не запустился, поэтому проблемы с задержкой исчезли, когда клиент обратился к Элвину через localhost.
В следующий раз, когда увидите увеличение задержки при уменьшении количества запросов в секунду, алгоритм Нейгла должен быть в вашем списке подозреваемых!
Источник: habr.com
