

Привет, Хабр!
А вы любите летать на самолетах? Я обожаю, но на самоизоляции полюбил еще и анализировать данные об авиабилетах одного известного ресурса — Aviasales.
Сегодня мы разберем работу Amazon Kinesis, построим стримминговую систему с реал-тайм аналитикой, поставим NoSQL базу данных Amazon DynamoDB в качестве основного хранилища данных и настроим оповещение через SMS по интересным билетам.
Все подробности под катом! Поехали!

Введение
Для примера нам потребуется доступ к . Доступ к нему предоставляется бесплатно и без ограничений, необходимо лишь зарегистрироваться в разделе «Разработчикам», чтобы получить свой API токен для доступа к данным.
Основная цель данной статьи — дать общее понимание использования потоковой передачи информации в AWS, мы выносим за скобки, что данные, возвращаемые используемым API не являются строго актуальными и передаются из кэша, который формируется на основании поисков пользователей сайтов Aviasales.ru и Jetradar.com за последние 48 часов.
Полученные через API данные об авиабилетах Kinesis-agent, установленный на машине-продюсере, будет автоматом парсить и передавать в нужный поток через Kinesis Data Analytics. Необработанная версия этого потока будет писаться напрямую в хранилище. Развернутое в DynamoDB хранилище «сырых» данных позволит проводить более глубокий анализ билетов через BI инструменты, например, AWS Quick Sight.
Мы рассмотрим два варианта деплоя всей инфраструктуры:
- Ручной — через AWS Management Console;
- Инфраструктура из кода Terraform — для ленивых автоматизаторов;
Архитектура разрабатываемой системы
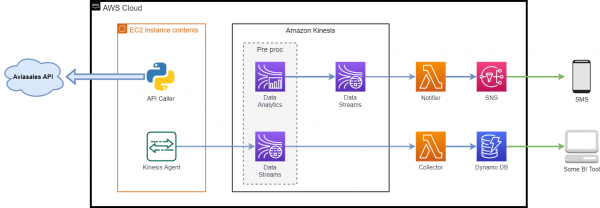
Используемые компоненты:
- — данные, возвращаемые этим API, будут использоваться для всей последующей работы;
- — обычная виртуальная машина в облаке, на которой будет генериться входной поток данных:
- — это Java-приложение, устанавливаемое локально на машину, которое предоставляет простой способ сбора и отправки данных в Kinesis (Kinesis Data Streams или Kinesis Firehose). Агент постоянно отслеживает набор файлов в указанных директориях и отправляет новые данные в Kinesis;
- — Python-скрипт, делающий запросы к API и складывающий ответ в папку, которую мониторит Kinesis Agent;
- — сервис потоковой передачи данных в режиме реального времени с широкими возможностями масштабирования;
- — бессерверный сервис, упрощающий анализ потоковых данных в режиме реального времени. Amazon Kinesis Data Analytics настраивает ресурсы для работы приложений и автоматически масштабируется для обработки любых объемов входящих данных;
- — сервис, позволяющий запускать код без резервирования и настройки серверов. Все вычислительные мощности автоматически масштабируются под каждый вызов;
- — база данных пар «ключ‑значение» и документов, которая обеспечивает задержку менее 10 миллисекунд при работе в любом масштабе. При использовании DynamoDB не требуется распределять какие-либо серверы, устанавливать на них исправления или управлять ими. DynamoDB автоматически масштабирует таблицы, корректируя объем доступных ресурсов и сохраняя высокую производительность. Никакие действия по администрированию системы не требуются;
- — полностью управляемый сервис отправки сообщений по модели «издатель — подписчик» (Pub/Sub), с помощью которого можно изолировать микросервисы, распределенные системы и бессерверные приложения. SNS можно использовать для рассылки информации конечным пользователям с помощью мобильных push-уведомлений, SMS-сообщений и электронных писем.
Начальная подготовка
Для эмуляции потока данных я решил использовать информацию об авиабилетах, возвращаемую API Aviasales. В довольно обширный список разных методов, возьмем один из них — «Календарь цен на месяц», который возвращает цены за каждый день месяца, сгруппированные по количеству пересадок. Если не передавать в запросе месяц поиска, то будет возвращена информация за месяц, следующий за текущим.
Итак, регистрируемся, получаем свой токен.
Пример запроса ниже:
http://api.travelpayouts.com/v2/prices/month-matrix?currency=rub&origin=LED&destination=HKT&show_to_affiliates=true&token=TOKEN_APIВышеописанный способ получения данных от API с указанием токена в запросе будет работать, но мне больше нравится передавать токен доступа через заголовок, поэтому в скрипте api_caller.py будем пользоваться именно этим способом.
Пример ответа:
{{
"success":true,
"data":[{
"show_to_affiliates":true,
"trip_class":0,
"origin":"LED",
"destination":"HKT",
"depart_date":"2015-10-01",
"return_date":"",
"number_of_changes":1,
"value":29127,
"found_at":"2015-09-24T00:06:12+04:00",
"distance":8015,
"actual":true
}]
}
В примере ответа API выше показан билет из Санкт-Петербурга в Пхук… Эх, да что мечтать…
Так как я из Казани, а Пхукет сейчас «нам только снится», поищем билеты из Санкт-Петербурга в Казань.
Предполагается, что у вас уже есть аккаунт в AWS. Сразу хочу обратить особое внимание, что Kinesis и отправка уведомлений через SMS не входят в годовой . Но даже несмотря на это, заложив в уме пару долларов, вполне можно построить предложенную систему и поиграть с ней. И, конечно же, не стоит забывать удалять все ресурсы после того, как они стали не нужны.
К счастью, DynamoDb и лямбда-функции будут для нас условно бесплатными, если уложиться в месячные бесплатные лимиты. Например, для DynamoDB: 25 Гб хранилища, 25 WCU/RCU и 100 млн. запросов. И миллион вызовов лямбда функций в месяц.
Ручной деплой системы
Настройка Kinesis Data Streams
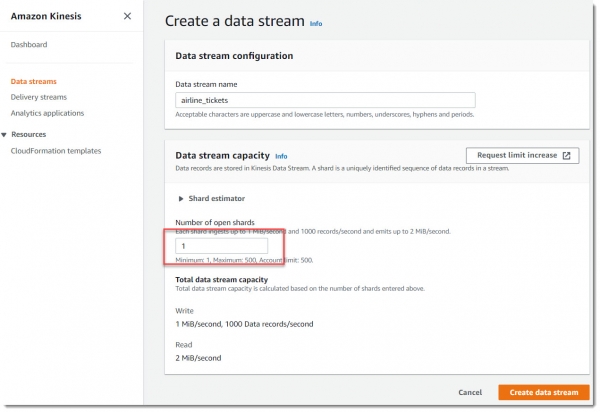
Перейдем в сервис Kinesis Data Streams и создаем два новых потока по одному шарду на каждый.
Что такое шард?
Шард — это основная единица передачи данных потока Amazon Kinesis. Один сегмент обеспечивает передачу входных данных со скоростью 1 МБ/с и передачу выходных данных со скоростью 2 МБ/с. Один сегмент поддерживает до 1000 записей PUT в секунду. При создании потока данных требуется указать нужное количество сегментов. Например, можно создать поток данных с двумя сегментами. Этот поток данных обеспечит передачу входных данных со скоростью 2 МБ/с и передачу выходных данных со скоростью 4 МБ/с с поддержкой до 2000 записей PUT в секунду.
Чем больше шардов в вашем потоке — тем больше его пропускная способность. В принципе, так и масштабируются потоки — путем добавления шардов. Но чем больше у вас шардов, тем выше и цена. Каждый шард стоит 1,5 цента в час и дополнительно 1.4 цента за каждые миллион операций добавления в поток (PUT payload units).
Создадим новый поток с именем airline_tickets, ему вполне достаточно будет 1 шарда:
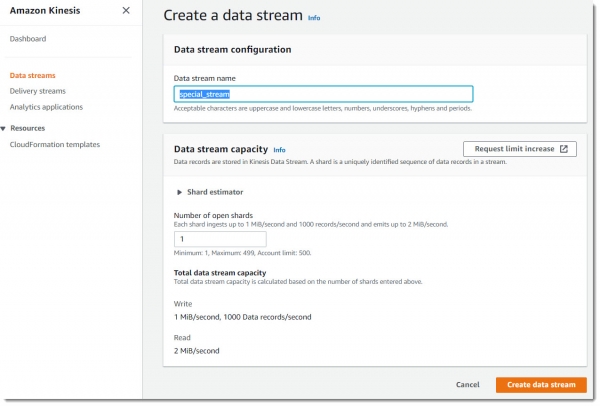
Теперь создадим еще один поток с именем special_stream:
Настройка продюсера
В качестве продюсера данных для разбора задачи достаточно использовать обычный EC2 инстанс. Это не должна быть мощная дорогая виртуальная машина, вполне подойдет спотовый t2.micro.
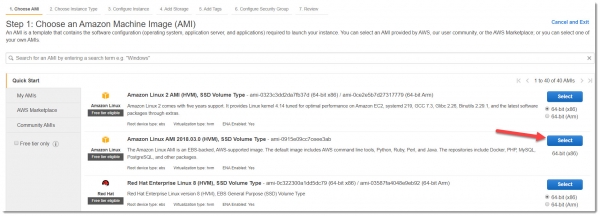
Важное замечание: для примера следует использовать image — Amazon Linux AMI 2018.03.0, с ним меньше настроек для быстрого запуска Kinesis Agent.
Переходим в сервис EC2, создаем новую виртуальную машину, выбираем нужный AMI с типом t2.micro, который входит во Free Tier:
Для того, чтобы вновь созданная виртуальная машина смогла взаимодействовать с сервисом Kinesis, необходимо дать ей на это права. Лучший способ это сделать – назначить IAM Role. Поэтому, на экране Step 3: Configure Instance Details следует выбрать Create new IAM Role:
Создание IAM роли для EC2
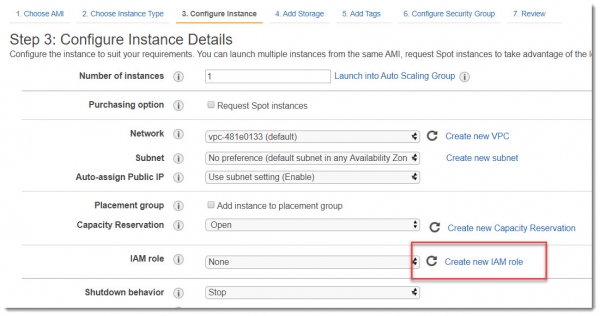
В открывшемся окне, выбираем, что новую роль создаем для EC2 и переходим в раздел Permissions:
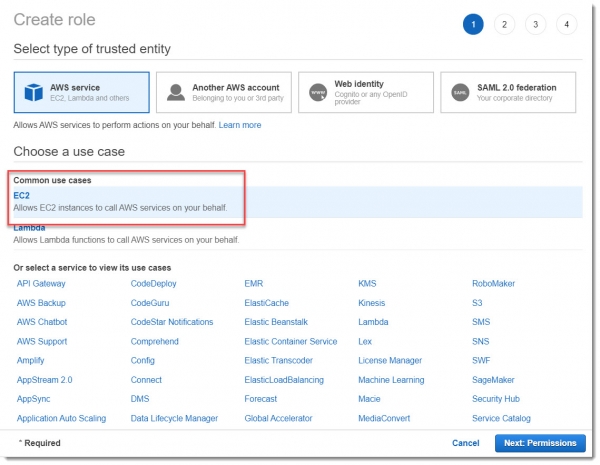
На учебном примере можно не вдаваться во все тонкости гранулярной настройки прав на ресурсы, поэтому выберем преднастроенные Амазоном полиси: AmazonKinesisFullAccess и CloudWatchFullAccess.
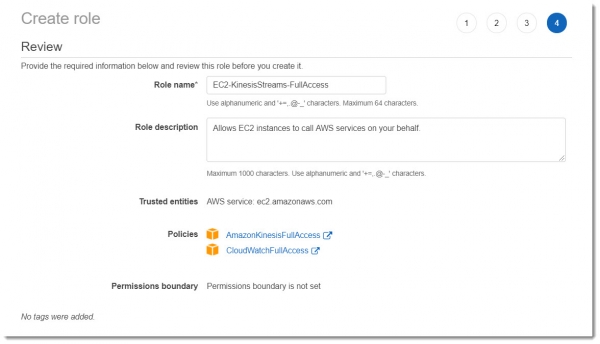
Дадим какое-нибудь осмысленное имя для этой роли, например: EC2-KinesisStreams-FullAccess. В результате, должно получиться то же самое, что указано на картинке ниже:
После создания этой новой роли, не забываем прицепить ее к создаваемому инстансу виртуальной машины:
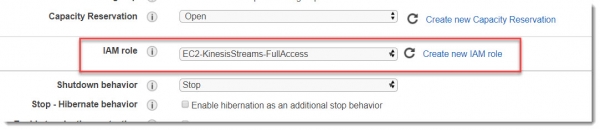
Больше на этом экране ничего не меняем и переходим к следующим окнам.
Параметры жесткого диска можно оставить по умолчанию, тэги тоже (хотя, хорошей практикой является теги использовать, хотя бы давать имя инстансу и указывать энвайронмент).
Теперь мы на закладке Step 6: Configure Security Group, где необходимо создать новый или указать имеющийся у вас Sеcurity group, позволяющий делать коннект через ssh (порт 22) на инстанс. Выберите там Source —> My IP и можете запускать инстанс.
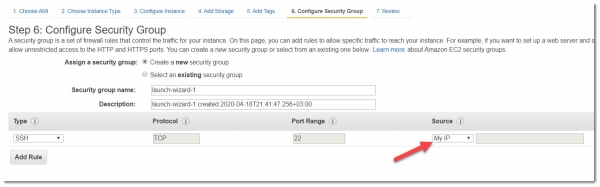
Как только он перейдет в статус running, можно пробовать законнектиться на него через ssh.
Чтобы получить возможность работы с Kinesis Agent, после успешного коннекта к машине, необходимо ввести следующие команды в терминале:
sudo yum -y update
sudo yum install -y python36 python36-pip
sudo /usr/bin/pip-3.6 install --upgrade pip
sudo yum install -y aws-kinesis-agent
Создадим папку для сохранения ответов API:
sudo mkdir /var/log/airline_ticketsПеред запуском агента, необходимо настроить его конфиг:
sudo vim /etc/aws-kinesis/agent.jsonСодержание файла agent.json должно иметь следующий вид:
{
"cloudwatch.emitMetrics": true,
"kinesis.endpoint": "",
"firehose.endpoint": "",
"flows": [
{
"filePattern": "/var/log/airline_tickets/*log",
"kinesisStream": "airline_tickets",
"partitionKeyOption": "RANDOM",
"dataProcessingOptions": [
{
"optionName": "CSVTOJSON",
"customFieldNames": ["cost","trip_class","show_to_affiliates",
"return_date","origin","number_of_changes","gate","found_at",
"duration","distance","destination","depart_date","actual","record_id"]
}
]
}
]
}
Как видно из файла конфигурации, агент будет мониторить в директории /var/log/airline_tickets/ файлы с расширением .log, парсить их и передавать в поток airline_tickets.
Перезапускаем сервис и убеждаемся, что он запустился и работает:
sudo service aws-kinesis-agent restartТеперь скачаем Python-скрипт, который будет запрашивать данные у API:
REPO_PATH=https://raw.githubusercontent.com/igorgorbenko/aviasales_kinesis/master/producer
wget $REPO_PATH/api_caller.py -P /home/ec2-user/
wget $REPO_PATH/requirements.txt -P /home/ec2-user/
sudo chmod a+x /home/ec2-user/api_caller.py
sudo /usr/local/bin/pip3 install -r /home/ec2-user/requirements.txt
Скрипт api_caller.py запрашивает данные у Aviasales и сохраняет полученный ответ в директории, которую сканирует Kinesis agent. Реализация этого скрипта достаточно стандартна, есть класс TicketsApi, он позволяет асинхронно дергать API. В этот класс передаем заголовок с токеном и параметры запроса:
class TicketsApi:
"""Api caller class."""
def __init__(self, headers):
"""Init method."""
self.base_url = BASE_URL
self.headers = headers
async def get_data(self, data):
"""Get the data from API query."""
response_json = {}
async with ClientSession(headers=self.headers) as session:
try:
response = await session.get(self.base_url, data=data)
response.raise_for_status()
LOGGER.info('Response status %s: %s',
self.base_url, response.status)
response_json = await response.json()
except HTTPError as http_err:
LOGGER.error('Oops! HTTP error occurred: %s', str(http_err))
except Exception as err:
LOGGER.error('Oops! An error ocurred: %s', str(err))
return response_json
def prepare_request(api_token):
"""Return the headers and query fot the API request."""
headers = {'X-Access-Token': api_token,
'Accept-Encoding': 'gzip'}
data = FormData()
data.add_field('currency', CURRENCY)
data.add_field('origin', ORIGIN)
data.add_field('destination', DESTINATION)
data.add_field('show_to_affiliates', SHOW_TO_AFFILIATES)
data.add_field('trip_duration', TRIP_DURATION)
return headers, data
async def main():
"""Get run the code."""
if len(sys.argv) != 2:
print('Usage: api_caller.py <your_api_token>')
sys.exit(1)
return
api_token = sys.argv[1]
headers, data = prepare_request(api_token)
api = TicketsApi(headers)
response = await api.get_data(data)
if response.get('success', None):
LOGGER.info('API has returned %s items', len(response['data']))
try:
count_rows = log_maker(response)
LOGGER.info('%s rows have been saved into %s',
count_rows,
TARGET_FILE)
except Exception as e:
LOGGER.error('Oops! Request result was not saved to file. %s',
str(e))
else:
LOGGER.error('Oops! API request was unsuccessful %s!', response)
Для тестирования правильности настроек и работоспособности агента сделаем тестовый запуск скрипта api_caller.py:
sudo ./api_caller.py TOKEN 
И смотрим результат работы в логах Агента и на закладке Monitoring в потоке данных airline_tickets:
tail -f /var/log/aws-kinesis-agent/aws-kinesis-agent.log 
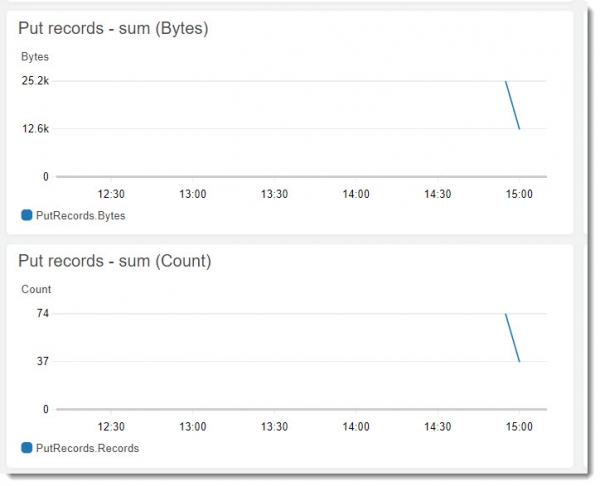
Как видно, все работает и Kinesis Agent успешно отправляет данные в поток. Теперь настроим consumer.
Настройка Kinesis Data Analytics
Перейдем к центральному компоненту всей системы — создадим новое приложение в Kinesis Data Analytics с именем kinesis_analytics_airlines_app:
Kinesis Data Analytics позволяет выполнять аналитику данных в реальном времени из Kinesis Streams с помощью языка SQL. Это полностью автомасштабируемый сервис (в отличие от Kinesis Streams), который:
- позволяет создавать новые потоки (Output Stream) на основе запросов к исходным данным;
- предоставляет поток с ошибками, которые возникли во время работы приложений (Error Stream);
- умеет автоматически определять схему входных данных (ее можно вручную переопределить при необходимости).
Это недешевый сервис — 0.11 USD за час работы, поэтому пользоваться им следует аккуратно и удалять при завершении работы.
Подключим приложение к источнику данных:
Выбираем поток, к которому собираемcя подключиться (airline_tickets):
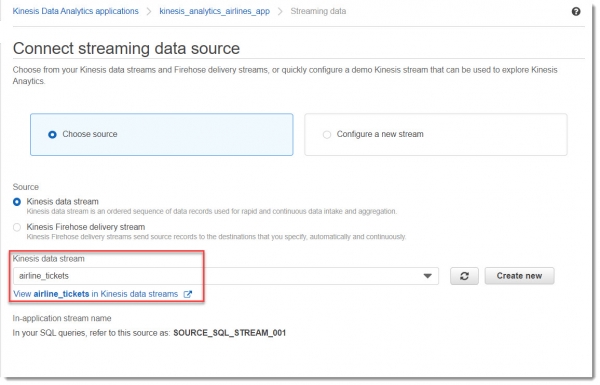
Далее, необходимо приаттачить новую IAM Роль для того, чтобы приложение могло читать из потока и писать в поток. Для этого достаточно ничего не менять в блоке Access permissions:
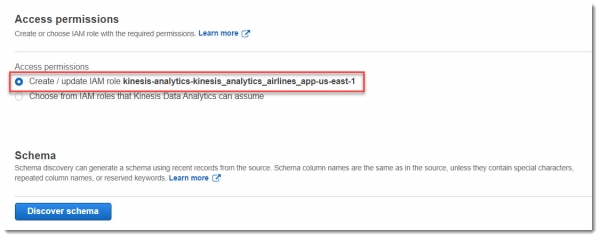
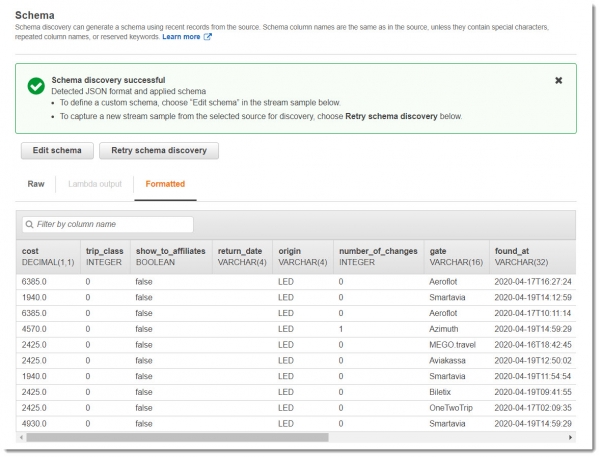
Теперь запросим обнаружение схемы данных в потоке, для этого нажимаем на кнопку «Discover schema». В результате обновится (создастся новая) роль IAM и будет запущено обнаружение схемы из данных, которые уже прилетели в поток:
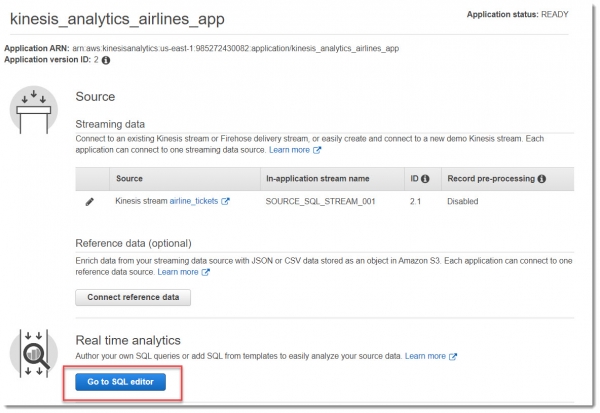
Теперь необходимо перейти в редактор SQL. При нажатии на эту кнопку, выйдет окно с вопросом о запуске приложения — выбираем что хотим запустить:
В окно редактора SQL вставим такой простой запрос и нажимаем Save and Run SQL:
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ("cost" DOUBLE, "gate" VARCHAR(16));
CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM"
SELECT STREAM "cost", "gate"
FROM "SOURCE_SQL_STREAM_001"
WHERE "cost" < 5000
and "gate" = 'Aeroflot';
В реляционных базах данных вы работаете с таблицами, используя операторы INSERT для добавления записей и оператор SELECT для запроса данных. В Amazon Kinesis Data Analytics вы работаете с потоками (STREAM) и «насосами» (PUMP) — непрерывными запросами вставки, которые вставляют данные из одного потока в приложении в другой поток.
В представленном выше SQL запросе происходит поиск билетов Аэрофлота по стоимости ниже пяти тысяч рублей. Все записи, попадающие под эти условия, будут помещены в поток DESTINATION_SQL_STREAM.
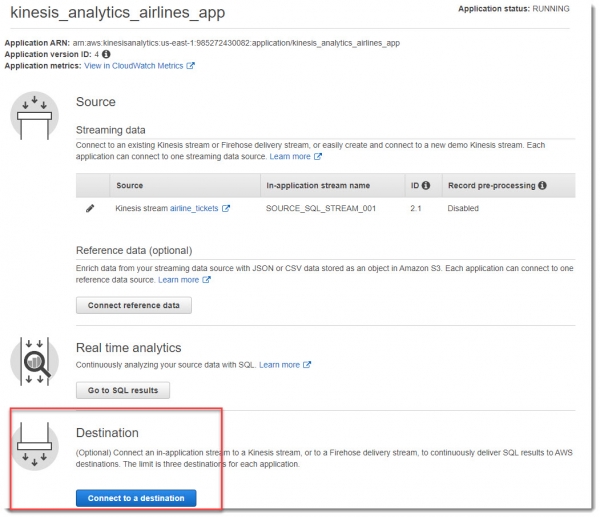
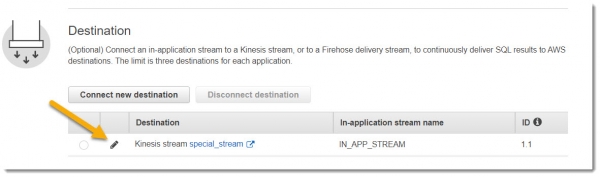
В блоке Destination выбираем поток special_stream, а в раскрывающемся списке In-application stream name DESTINATION_SQL_STREAM:
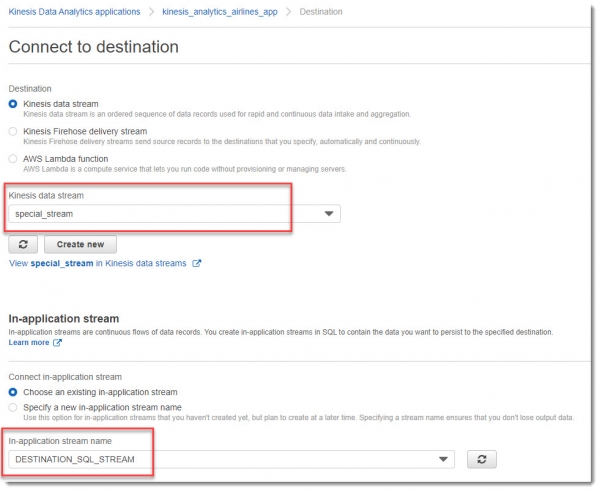
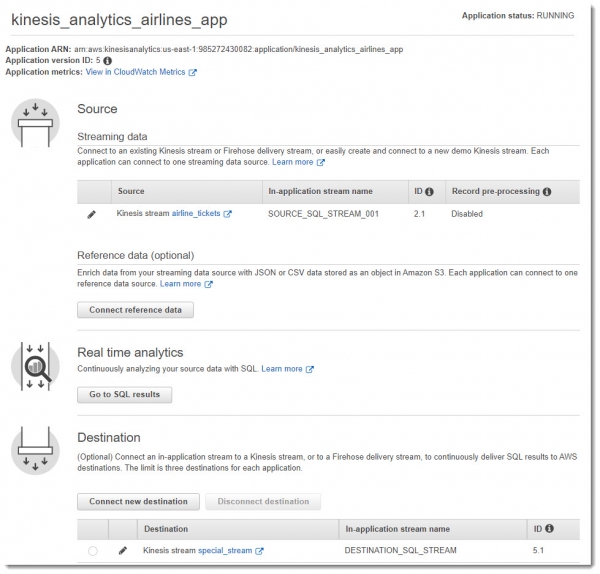
В результате всех манипуляций должно получиться нечто похожее на картинку ниже:
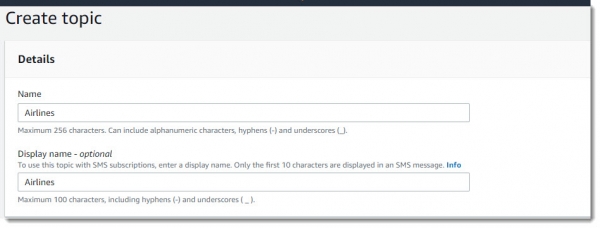
Создание и подписка на топик SNS
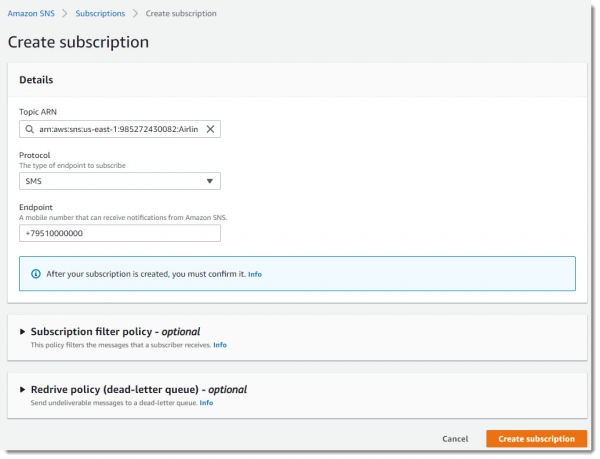
Переходим в сервис Simple Notification Service и создаем там новый топик c именем Airlines:
Оформляем подписку на этот топик, в ней указываем номер мобильного телефона, на который будут приходить СМС-уведомления:
Создание таблицы в DynamoDB
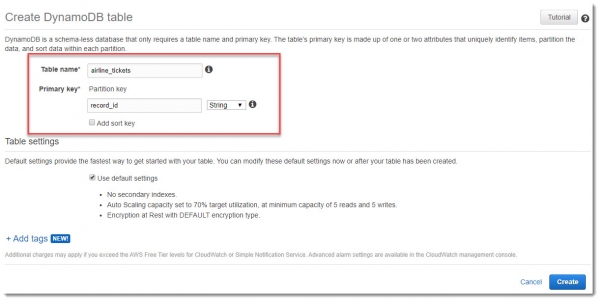
Для хранения необработанных данных их потока airline_tickets, создадим таблицу в DynamoDB с таким же именем. В качестве первичного ключа будем использовать record_id:
Создание лямбда-функции collector
Создадим лямбда-функцию под названием Collector, задачей которой будет опрос потока airline_tickets и, в случае нахождения там новых записей, вставка этих записей в таблицу DynamoDB. Очевидно, что помимо прав по умолчанию, эта лямбда должна иметь доступ к чтению потока данных Kinesis и записи в DynamoDB.
Создание IAM роли для лямбда-функции collector
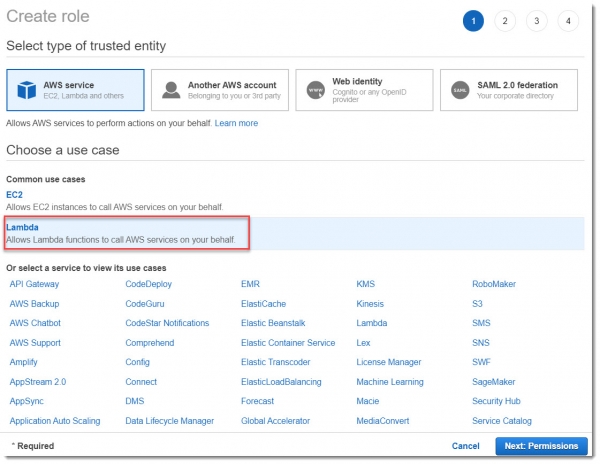
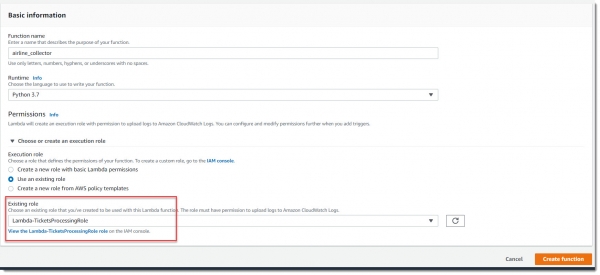
Для начала создадим новую IAM роль для лямбды с именем Lambda-TicketsProcessingRole:
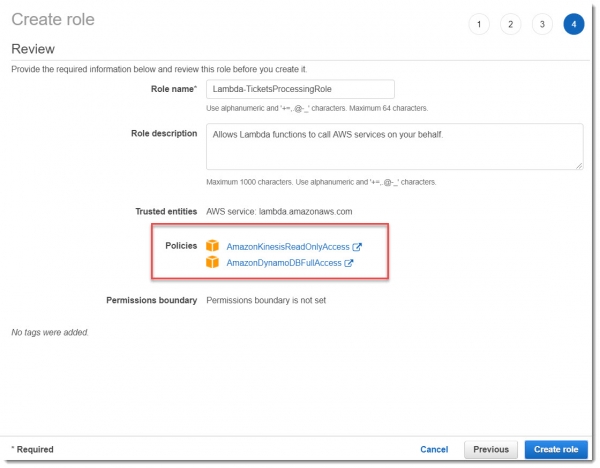
Для тестового примера вполне подойдут преднастроенные полиси AmazonKinesisReadOnlyAccess и AmazonDynamoDBFullAccess, как показано на картинке ниже:
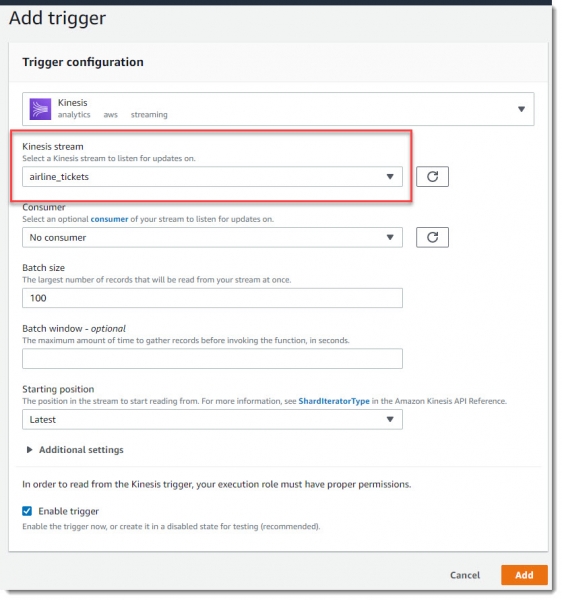
Данная лямбда должна запускаться по триггеру от Kinesis при попадании новых записей в поток airline_stream, поэтому надо добавить новый триггер:
Осталось вставить код и сохранить лямбду.
"""Parsing the stream and inserting into the DynamoDB table."""
import base64
import json
import boto3
from decimal import Decimal
DYNAMO_DB = boto3.resource('dynamodb')
TABLE_NAME = 'airline_tickets'
class TicketsParser:
"""Parsing info from the Stream."""
def __init__(self, table_name, records):
"""Init method."""
self.table = DYNAMO_DB.Table(table_name)
self.json_data = TicketsParser.get_json_data(records)
@staticmethod
def get_json_data(records):
"""Return deserialized data from the stream."""
decoded_record_data = ([base64.b64decode(record['kinesis']['data'])
for record in records])
json_data = ([json.loads(decoded_record)
for decoded_record in decoded_record_data])
return json_data
@staticmethod
def get_item_from_json(json_item):
"""Pre-process the json data."""
new_item = {
'record_id': json_item.get('record_id'),
'cost': Decimal(json_item.get('cost')),
'trip_class': json_item.get('trip_class'),
'show_to_affiliates': json_item.get('show_to_affiliates'),
'origin': json_item.get('origin'),
'number_of_changes': int(json_item.get('number_of_changes')),
'gate': json_item.get('gate'),
'found_at': json_item.get('found_at'),
'duration': int(json_item.get('duration')),
'distance': int(json_item.get('distance')),
'destination': json_item.get('destination'),
'depart_date': json_item.get('depart_date'),
'actual': json_item.get('actual')
}
return new_item
def run(self):
"""Batch insert into the table."""
with self.table.batch_writer() as batch_writer:
for item in self.json_data:
dynamodb_item = TicketsParser.get_item_from_json(item)
batch_writer.put_item(dynamodb_item)
print('Has been added ', len(self.json_data), 'items')
def lambda_handler(event, context):
"""Parse the stream and insert into the DynamoDB table."""
print('Got event:', event)
parser = TicketsParser(TABLE_NAME, event['Records'])
parser.run()
Создание лямбда-функции notifier
Вторая лямбда-функция, которая будет мониторить второй поток (special_stream) и отправлять уведомление в SNS, создается аналогично. Следовательно, эта лямбда должна иметь доступ на чтение из Kinesis и отправку сообщений в заданный SNS-топик, который далее сервисом SNS будет отправлен всем подписчикам этого топика (email, SMS и т.д).
Создание IAM роли
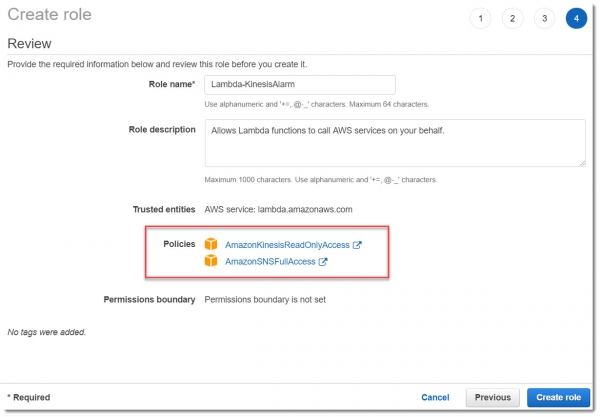
Сначала создаем IAM роль Lambda-KinesisAlarm для этой лямбды, а потом назначаем эту роль для создаваемой лямбды alarm_notifier:
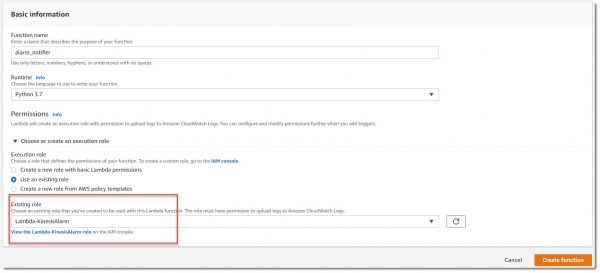
Эта лямбда должна работать по триггеру на попадание новых записей в поток special_stream, поэтому необходимо настроить триггер аналогично тому, как мы это делали для лямбды Collector.
Для удобства настройки этой лямбды, введем новую переменную окружения — TOPIC_ARN, куда помещаем ANR (Amazon Recourse Names) топика Airlines:
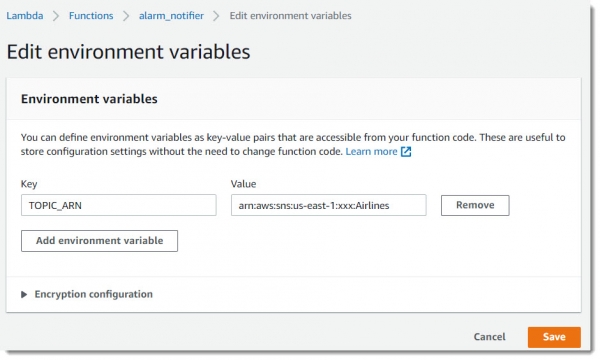
И вставляем код лямбды, он совсем несложный:
import boto3
import base64
import os
SNS_CLIENT = boto3.client('sns')
TOPIC_ARN = os.environ['TOPIC_ARN']
def lambda_handler(event, context):
try:
SNS_CLIENT.publish(TopicArn=TOPIC_ARN,
Message='Hi! I have found an interesting stuff!',
Subject='Airline tickets alarm')
print('Alarm message has been successfully delivered')
except Exception as err:
print('Delivery failure', str(err))
Кажется, на этом ручная настройка системы завершена. Остается только протестировать и убедиться в том, что мы настроили все правильно.
Деплой из кода Terraform
Необходимая подготовка
— очень удобный open-source инструмент для развертывания инфраструктуры из кода. У него свой синтаксис, который легко освоить и множество примеров, как и что развернуть. В редакторе Atom или Visual Studio Code много удобных плагинов, позволяющих облегчить работу с Terraform.
Дистрибутив скачать можно . Подробный разбор всех возможностей Terraform выходит за рамки данной статьи, поэтому ограничимся основными моментами.
Как запустить
Полный код проекта лежит . Клонируем к себе репозиторий. Перед запуском необходимо убедиться, что у вас установлен и настроен AWS CLI, т.к. Terraform будет искать учетные данные в файле ~/.aws/credentials.
Хорошей практикой является перед деплоем всей инфраструктуры, запускать команду plan, чтобы посмотреть, что Terraform нам сейчас насоздает в облаке:
terraform.exe planБудет предложено ввести номер телефона для отправки на него уведомлений. На этом этапе его вводить необязательно.
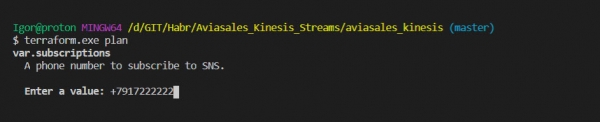
Проанализировав план работы программы, можем запускать создание ресурсов:
terraform.exe applyПосле отправки этой команды опять появится запрос на введение номера телефона, набираем «yes», когда будет показан вопрос о реальном выполнении действий. Это позволит поднять всю инфраструктуру, провести всю необходимую настройку EC2, развернуть лямбда-функции и т.д.
После того, как все ресурсы будут успешно созданы через код Terraform, необходимо зайти в детали приложения Kinesis Analytics (к сожалению, я не нашел как это сделать сразу из кода).
Запускаем приложение:
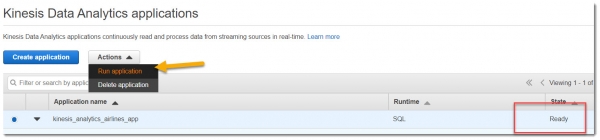
После этого необходимо явно задать in-application stream name, выбрав из раскрывающегося списка:
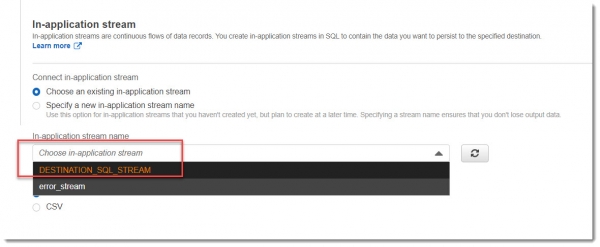
Теперь все готово к работе.
Тестирование работы приложения
Вне зависимости, как вы деплоили систему, вручную или через код Terraform, работать она будет одинаково.
Заходим по SSH на виртуальную машину EC2, где установлен Kinesis Agent и запускаем скрипт api_caller.py
sudo ./api_caller.py TOKENОсталось дождаться SMS на ваш номер:

SMS — сообщение приходит на телефон практически через 1 минуту:

Осталось посмотреть, сохранились ли записи в базе данных DynamoDB для последующего, более детального анализа. Таблица airline_tickets содержит примерно такие данные:
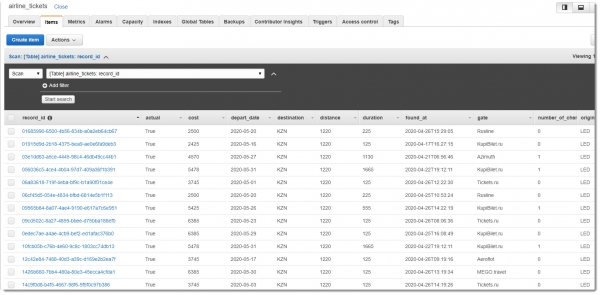
Заключение
В ходе проделанной работы была построена система онлайн-обработки данных на базе Amazon Kinesis. Были рассмотрены варианты использования Kinesis Agent в связке с Kinesis Data Streams и реал-тайм аналитикой Kinesis Analytics при помощи SQL команд, а также взаимодействие Amazon Kinesis с другими сервисами AWS.
Вышеописанную систему мы развернули двумя способами: достаточно долгим ручным и быстрым из кода Terraform.
Весь исходный код проекта доступен , предлагаю с ним ознакомиться.
С удовольствием готов обсудить статью, жду Ваших комментариев. Надеюсь на конструктивную критику.
Желаю успехов!
Источник: habr.com
