

Масштаб сети Amazon Web Services — это 69 зон по всему миру в 22 регионах: США, Европа, Азия, Африка и Австралия. В каждой зоне находится до 8 ЦОД — Центров Обработки Данных. В каждом ЦОД тысячи или сотни тысяч серверов. Сеть построена так, что все маловероятные сценарии перебоев в работе принимаются в расчет. Например, все регионы изолированы друг от друга, а зоны доступности разнесены на расстояния в несколько километров. Даже если перерубить кабель, то система перейдет на резервные каналы, а потери информации составят единицы пакетов данных. О том, на каких еще принципах построена сеть и как она устроена, расскажет Василий Пантюхин.
Василий Пантюхин начинал Unix-админом в .ru-компаниях, 6 лет занимался большими железками Sun Microsystem, 11 лет проповедовал дата-центричность мира в EMC. Естественным путем эволюционировал в приватные облака, потом подался в публичные. Сейчас, как архитектор Amazon Web Services, техническими советами помогает жить и развиваться в облаке AWS.
В предыдущей части трилогии об устройстве AWS Василий углубился в устройство физических серверов и масштабирование базы данных. Nitro-карты, кастомный гипервизор на базе KVM, база данных Amazon Aurora — обо всем этом в материале «». Прочитайте, чтобы погрузиться в контекст, или посмотрите выступления.
В этой части речь пойдет о масштабировании сети — одной из сложнейших систем в AWS. Эволюция от плоской сети к Virtual Private Cloud и ее устройство, внутренние сервисы Blackfoot и HyperPlane, проблема шумного соседа, а в конце — масштабы сети, backbone и физические кабели. Обо всем этом под катом.
Дисклеймер: всё, что ниже — личное мнение Василия, и оно может не совпадать с позицией Amazon Web Services.
Масштабирование сети
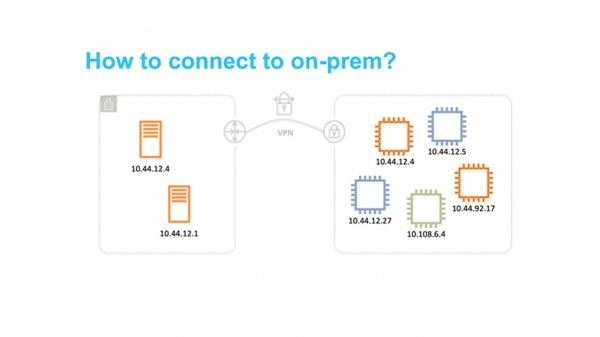
Облако AWS запустили в 2006 году. Его сеть была достаточно примитивной — с плоской структурой. Диапазон приватных адресов был общим для всех тенантов облака. При запуске новой виртуальной машины вы случайно получали доступный IP-адрес из этого диапазона.

Такой подход был прост в реализации, но принципиально ограничивал использование облака. В частности, было достаточно сложно разрабатывать гибридные решения, в которых объединялись частные сети на земле и в AWS. Самая распространенная проблема была в пересечении диапазонов IP-адресов.
Virtual Private Cloud
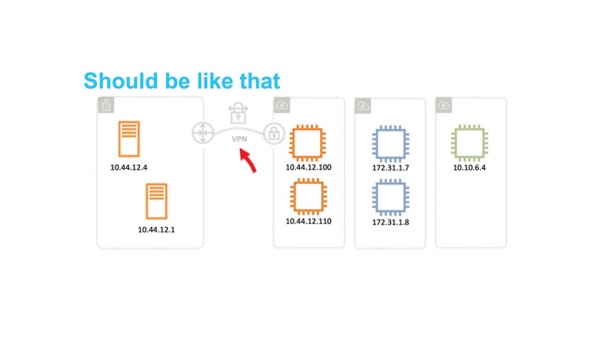
Облако оказалось востребовано. Пришла пора задуматься о масштабируемости и возможности его использования десятками миллионов тенантов. Плоская сеть стала главным препятствием. Поэтому мы задумались как изолировать пользователей друг от друга на сетевом уровне так, чтобы они могли самостоятельно выбирать диапазоны IP.
Что первым приходит в голову, когда вы задумываетесь о сетевой изоляции? Конечно VLAN и VRF — Virtual Routing and Forwarding.
К сожалению, это не сработало. VLAN ID — это всего 12 бит, что дает нам всего лишь 4096 изолированных сегментов. Даже в самых больших коммутаторах можно использовать максимум 1-2 тыс VRF. Совместное использование VRF и VLAN дает нам всего несколько миллионов подсетей. Этого точно недостаточно для десятков миллионов тенантов, у каждого из которых должна быть возможность использовать несколько подсетей.
Еще мы просто не можем себе позволить купить требуемое количество больших коробок, например, у Cisco или Juniper. Есть две причины: это бешено дорого, и мы не хотим попадать в зависимость от их политики разработки и патчинга.
Вывод один – варить свое собственное решение.
В 2009 году мы анонсировали VPC — Virtual Private Cloud. Название прижилось и теперь многие облачные провайдеры тоже его используют.
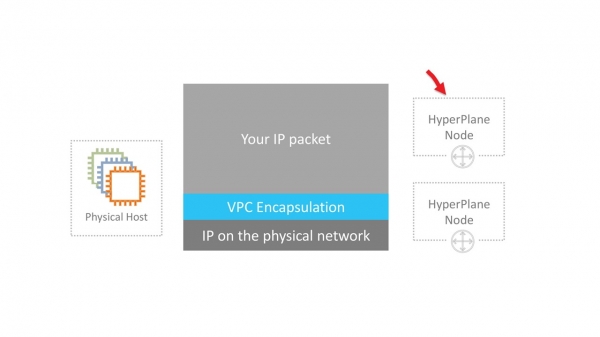
VPC – это виртуальная сеть SDN (Software Defined Network). Мы решили не изобретать специальных протоколов на уровнях L2 и L3. Сеть работает на стандартном Ethernet и IP. Для передачи по сети трафик виртуальных машин инкапсулируется в обертку нашего собственного протокола. В нем указывается ID, который принадлежит VPC тенанта.
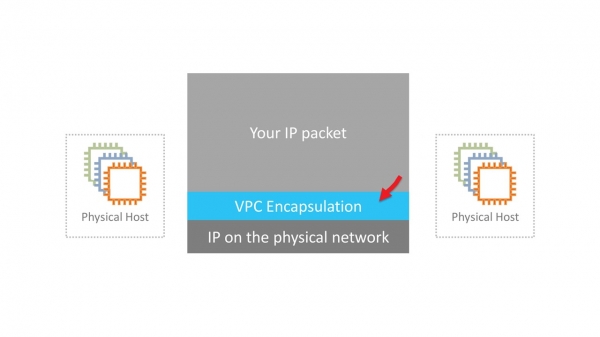
Звучит просто. Однако нужно решить несколько серьезных технических задач. Например, где и как хранить данные о маппировании виртуальных MAC/IP-адресов, VPC ID и соответствующих физических MAC/IP. В масштабах AWS это огромная таблица, которая должна работать с минимальными задержками при обращении. За это отвечает сервис маппирования, который размазан тонким слоем по всей сети.
В машинах новых поколений инкапсуляция производится картами Nitro на железном уровне. В старых инстансах инкапсуляция и декапсуляция программные.
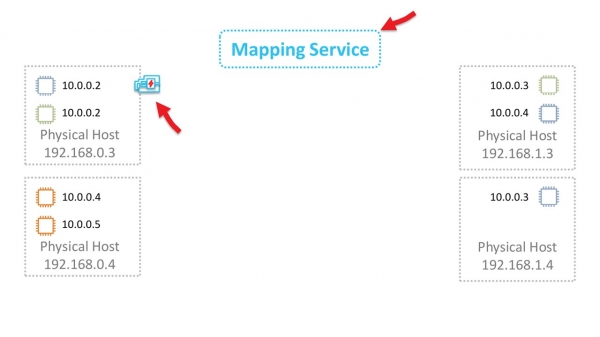
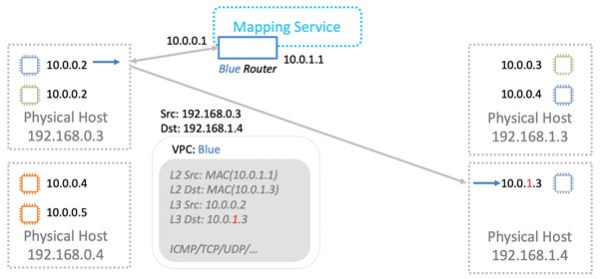
Разберемся как это работает в общих чертах. Начнем с уровня L2. Предположим, что у нас есть виртуалка с IP 10.0.0.2 на физическом сервере 192.168.0.3. Она посылает данные виртуальной машине 10.0.0.3, которая живет на 192.168.1.4. Формируется ARP-запрос, который попадает на сетевую Nitro-карту. Для простоты считаем, что обе виртуалки живут в одном «синем» VPC.

Карта заменяет адрес источника на свой собственный и пересылает ARP-фрейм сервису маппирования.
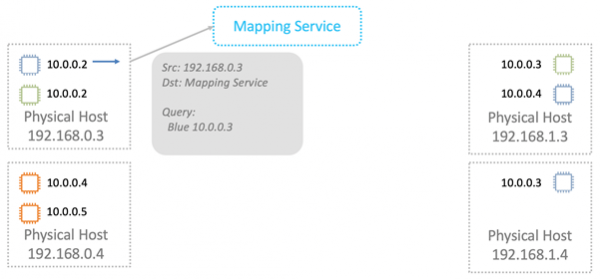
Сервис маппирования возвращает информацию, которая необходима для передачи по физической сети L2.
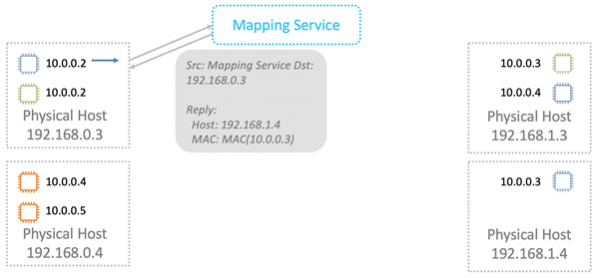
Nitro-карта в ARP-ответе заменяет MAC в физической сети на адрес в VPC.
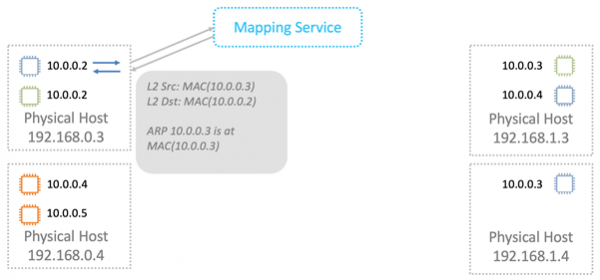
При передаче данных мы заворачиваем логические MAC и IP в VPC-обертку. Все это передаем по физической сети с помощью соответствующих IP Nitro-карт источника и назначения.
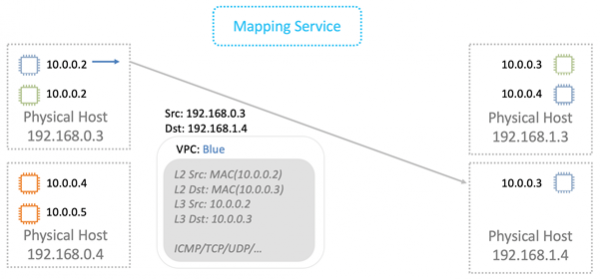
Физическая машина, которой предназначен пакет, производит проверку. Это нужно, чтобы предотвратить возможность подмены адресов. Машина посылает специальный запрос сервису маппирования и спрашивает: «С физической машины 192.168.0.3 я получила пакет, который предназначен для 10.0.0.3 в «голубом» VPC. Он легитимный?»
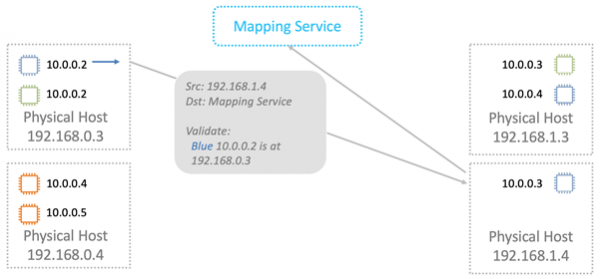
Сервис маппирования сверяется со своей таблицей размещения ресурсов и разрешает, либо запрещает прохождения пакета. Во всех новых инстансах дополнительная валидация прошита в Nitro-картах. Ее невозможно обойти даже теоретически. Поэтому spoofing на ресурсы в другом VPC не сработает.
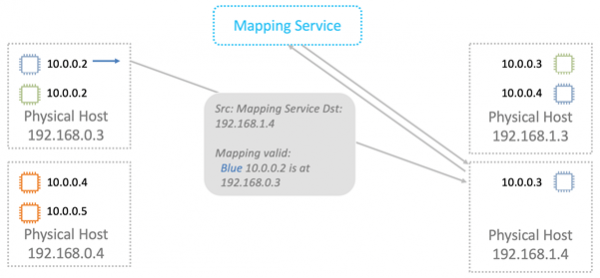
Дальше данные отправляются виртуальной машине для которой они предназначены.
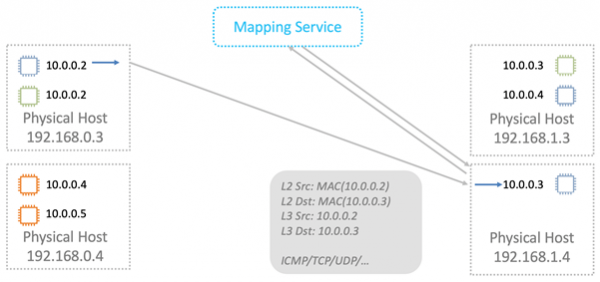
Сервис маппирования работает еще и как логический маршрутизатор для передачи данных между виртуалками в разных подсетях. Там концептуально все просто, не буду детально разбирать.
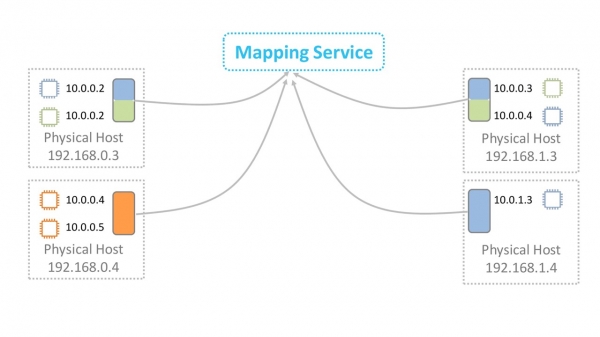
Получается, что при передаче каждого пакета серверы обращаются к сервису маппирования. Как бороться с неизбежными задержками? Кэшированием, конечно же.
Вся прелесть в том, что не нужно кэшировать всю огромную таблицу. На физическом сервере живут виртуалки из относительно небольшого количества VPC. Кэшировать информацию нужно только об этих VPC. Передача данных в другие VPC в «дефолтной» конфигурации все равно не легитимна. Если используется такая функциональность, как VPC-peering, то в кэш дополнительно подгружается информация о соответствующих VPC.
С передачей данных в VPC разобрались.
Blackfoot
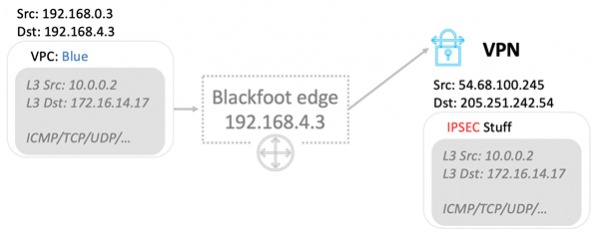
Как быть в случаях, когда трафик надо передавать наружу, например в Internet или через VPN на землю? Здесь нас выручает Blackfoot — внутренний сервис AWS. Он разработан нашей Южно-Африканской командой. Поэтому сервис называется в честь пингвина, который живет в Южной Африке.
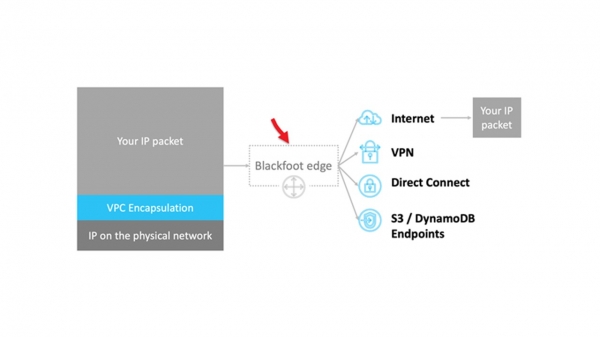
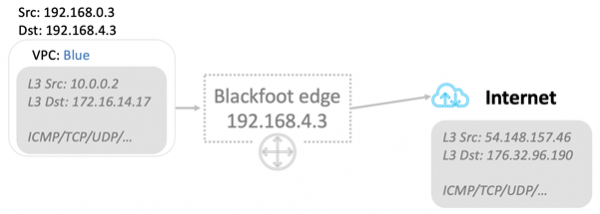
Blackfoot декапсулирует трафик и делает с ним то, что нужно. Данные в Internet отправляются как есть.
Данные декапсулируются и снова заворачиваются в обертку IPsec при использовании VPN.
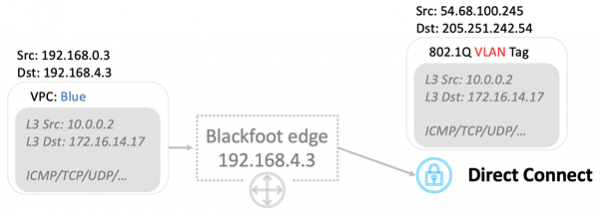
При использовании Direct Connect трафик тэгируется и передается в соответствующий VLAN.
HyperPlane
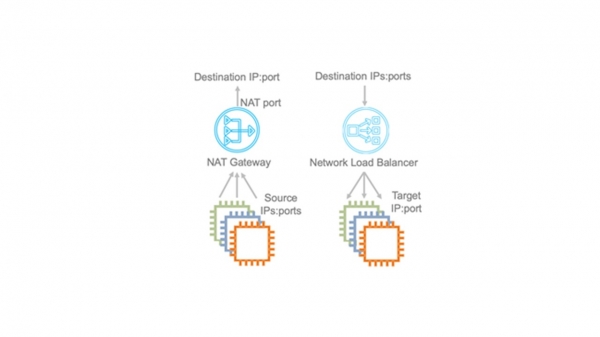
Это внутренний сервис контроля потока. Многие сетевые сервисы требуют контроля состояния потока данных. Например, при использовании NAT, контроль потока должен гарантировать, что каждой паре «IP: порт назначения» соответствует уникальный исходящий порт. В случае балансировщика NLB — Network Load Balancer, поток данных всегда должен направляться на одну и ту же целевую виртуалку. Security Groups — это файрвол с сохранением состояния. Он следит за входящим трафиком и неявно открывает порты для исходящего потока пакетов.
В облаке AWS требования к задержкам передачи предельно высокие. Поэтому HyperPlane критичен для работоспособности всей сети.
Hyperplane построен на виртуальных машинах EC2. Здесь нет никакой магии, только хитрость. Хитрость в том, что это виртуалки с большим RAM. Операции транзакционные и производятся исключительно в памяти. Это позволяет добиться задержек всего в десятки микросекунд. Работа с диском убила бы всю производительность.
Hyperplane это распределенная система из огромного количества таких EC2-машин. Каждая виртуалка имеет пропускную способность 5 ГБ/с. В масштабах всей региональной сети это дает бешеные терабиты пропускной способности и позволяет обрабатывать миллионы соединений в секунду.
HyperPlane работает только с потоками. VPC инкапсуляция пакетов для него совершенно прозрачна. Потенциальная уязвимость в этом внутреннем сервисе все равно не позволит пробить изоляцию VPC. За безопасность отвечают уровни ниже.
Noisy neighbor
Есть еще проблема шумного соседа — noisy neighbor. Предположим, что у нас 8 нод. Эти ноды обрабатывают потоки всех пользователей облака. Вроде все хорошо и нагрузка должна равномерно распределяться по всем нодам. Ноды очень мощные и перегрузить их сложно.
Но мы строим свою архитектуру исходя даже из маловероятных сценариев.
Низкая вероятность не означает невозможность.
Мы можем представить себе ситуацию, в которой один или несколько пользователей будут генерировать слишком большую нагрузку. В обработку этой нагрузки вовлечены все ноды HyperPlane и другие пользователи потенциально могут почувствовать какое-то снижение производительности. Это разрушает концепцию облака, в которой у тенантов нет возможности влиять друг на друга.

Как решить проблему шумного соседа? Первое что приходит на ум – шардирование. Наши 8 нод логически делятся на 4 шарда по 2 ноды в каждом. Теперь шумный сосед помешает всего лишь четверти всех пользователей, но зато сильно.
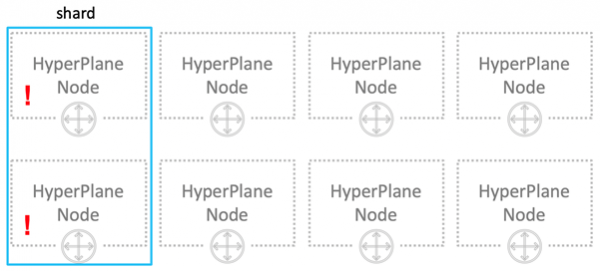
Давайте поступим по-другому. Каждому пользователю выделим всего по 3 ноды.
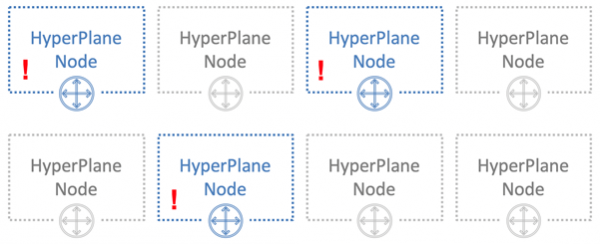
Хитрость в том, чтобы назначать ноды разным пользователям случайным образом. На картинке ниже синий пользователь пересекается по нодам с одним из двух других пользователей — зеленым и оранжевым.
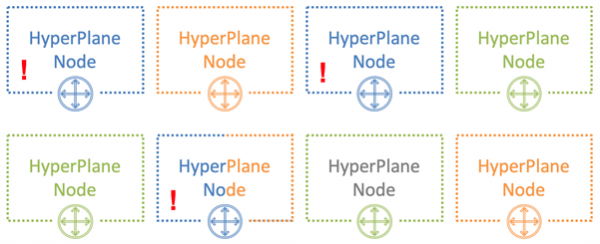
При 8 нодах и 3 пользователях вероятность пересечения шумного соседа с одним из пользователей составляет 54%. Именно с такой вероятностью синий пользователь повлияет на других тенантов. При этом только лишь частью частью своей нагрузки. В нашем примере это влияние будет хоть как-то заметно не всем, а всего трети всех пользователей. Это уже неплохой результат.
Число пользователей, которые пересекутся
Вероятность в процентах
0
18%
1
54%
2
26%
3
2%
Приблизим ситуацию к реальной — возьмем 100 нод и 5 пользователей на 5 нодах. В этом случае ни одна из нод не пересечется с вероятностью 77%.
Число пользователей, которые пересекутся
Вероятность в процентах
0
77%
1
21%
2
1,8%
3
0,06%
4
0,0006%
5
0,00000013%
В реальной ситуации при огромном количестве HyperPlane нод и пользователей потенциальное влияние шумного соседа на других пользователей минимально. Этот метод называется перемешивающим шардированием — shuffle sharding. Он минимизирует негативный эффект от выхода нод из строя.
На базе HyperPlane построено множество сервисов: Network Load Balancer, NAT Gateway, Amazon EFS, AWS PrivateLink, AWS Transit Gateway.
Масштабы сети
Теперь поговорим о масштабах самой сети. На октябрь 2019 AWS предлагает свои сервисы в 22 регионах, а запланировано еще 9.
- Каждый регион содержит несколько зон доступности — Availability Zone. Всего их по миру 69.
- Каждая AZ состоит из Центров Обработки Данных. Всего их не больше 8.
- В ЦОД располагается огромное количество серверов, в некоторых до 300 000.
Теперь все это усредним, перемножим и получим внушительную цифру, которая отображает масштаб облака Amazon.
Между зонами доступности и ЦОД проложено много оптических каналов. В одном крупнейшем нашем регионе только для связи AZ между собой и центрами связи с другими регионами (Transit Centers) проложено 388 каналов. В сумме это дает бешеные 5000 Тбит.
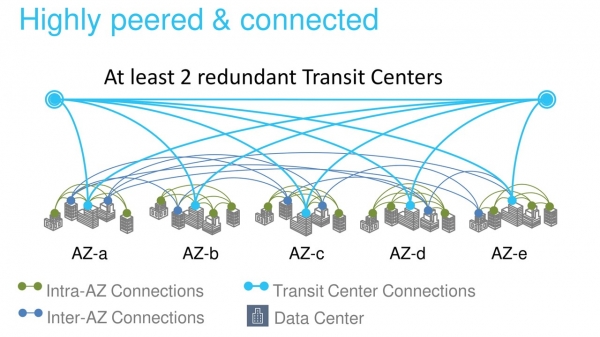
Backbone AWS построен специально для облака и оптимизирован для работы с ним. Мы строем его на каналах 100 ГБ/с. Мы их полностью контролируем, за исключением регионов в Китае. Трафик не разделяется с нагрузками других компаний.
Конечно, мы не единственный облачный провайдер с частной backbone-сетью. Все больше и больше крупных компаний идут по этому пути. Это подтверждается независимыми исследователями, например, от .
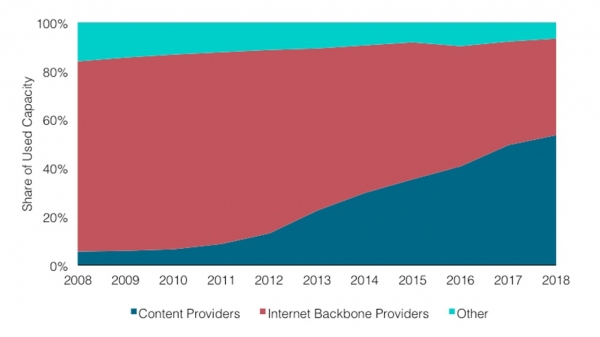
На графике видно, что доля провайдеров контента и cloud-провайдеров растет. Из-за этого доля Internet-трафика backbone-провайдеров постоянно снижается.
Объясню почему так происходит. Раньше большинство web-сервисов были доступны и потреблялись непосредственно из Internet. Сейчас все больше серверов расположены в облаке и доступны через CDN — Content Distribution Network. Для доступа к ресурсу пользователь идет через Internet только до ближайшей CDN PoP — Point of Presence. Чаще всего это где-то рядом. Дальше он покидает общедоступный Internet и по приватному backbone летит через Атлантику, например, и попадает непосредственно на ресурс.
Интересно, как поменяется Internet через 10 лет если эта тенденция сохранится?
Физические каналы
Ученые пока не придумали, как увеличить скорость света во Вселенной, но сильно продвинулись в методах его передачи по оптоволокну. Сейчас мы используем кабели с 6912 волокнами. Это помогает значительно оптимизировать стоимость их прокладки.
В некоторых регионах нам приходится использовать специальные кабели. Например, в регионе Сидней мы применяем кабели со специальным покрытием против термитов.

От неприятностей никто не застрахован и иногда наши каналы повреждаются. На фото справа оптические кабели в одном из Американских регионов, которые были порваны строителями. В результате аварии потерялось всего 13 пакетов данных, что удивительно. Еще раз – всего 13! Система буквально мгновенно переключилась на резервные каналы — масштаб работает.
Мы галопом пробежались по некоторым сервисам и технологиям облака Amazon. Надеюсь, что у вас появилось хотя бы некоторое представление о масштабе задач, которые приходится решать нашим инженерам. Лично меня это очень увлекает.
Это финальная часть трилогии от Василия Пантюхина об устройстве AWS. В части описаны оптимизация серверов и масштабирование базы данных, а во — серверлесс-функции и Firecracker.
На в ноябре Василий Пантюхин поделится новыми подробностями устройства Amazon. Он о причинах отказов и проектировании распределенные систем в Amazon. 24 октября еще можно билет по хорошей цене, а оплатить потом. Ждем вас на HighLoad++, приходите — пообщаемся!
Источник: habr.com
