

Никогда не было, и вот опять!
На очередном проекте мы решили использовать Liquibase с самого начала, чтобы избежать проблем в будущем. Как оказалось, не все молодые члены команды умеют его правильно использовать. Я провёл внутренний воркшоп, который затем решил превратить в статью.
Статья включает в себя полезные советы и описание трех самых явных ловушек, в которые можно попасть, работая с инструментами миграции реляционных баз данных, в частности Liquibase. Рассчитана на Java разработчиков уровня Junior и Middle, для более опытных разработчиков может быть интересна для структуризации и повторения того, что, скорее всего, уже известно.

Liquibase и Flyway — основные конкурирующие технологии для решения задач контроля версий реляционных структур в мире Java. Первая является полностью бесплатной, на практике чаще выбирается для использования именно она, поэтому именно Liquibase выбран героем публикации. Тем не менее некоторые из описанных практик могут быть универсальными, в зависимости от архитектуры вашего приложения.
Миграции реляционных структур – это вынужденно появившийся способ борьбы со слабой гибкостью реляционных хранилищ данных. В эпоху моды на ООП стиль работы с БД подразумевал, что мы один раз опишем схему и не будем её больше трогать. Но реальность всегда такова, что всё меняется, и изменения в структуре таблиц требуются достаточно часто. Естественно, процесс сам по себе бывает болезненный и неприятный.
Не буду углубляться в описание технологии и инструкции по добавлению библиотеки в свой проект, на эту тему было написано достаточно статей:
Кроме того, уже была отличная статья на тему полезных советов:
Советы
Хочу поделиться своими советами и комментариями, которые родились через пот, кровь и боль решения проблем с миграцией.
1. Перед работой следует ознакомиться с разделом лучших практик на Liquibase
описаны простые, но очень важные вещи, без которых использование библиотеки может усложнить вам жизнь. К примеру, неструктурный подход к управлению ченджсетами рано или поздно приведёт к путанице и поломанным миграциям. Если выкатывать зависящие друг от друга изменения структуры БД и логики сервисов не одновременно, то есть большая вероятность, что это приведёт к красным тестам или поломанному окружению. Кроме того, рекомендации по использованию Liquibase на официальном сайте содержат пункт про разработку и проверку rollback скриптов вместе с основными скриптами миграции. Ну и в статье есть примеры кода, касающегося миграций и rollback механизма.
2. Если начали использовать средства миграции – не допускайте мануальных исправлений в структуре базы
Как говорится: «Один раз Persil — всегда Persil». Если база вашего приложения начала управляться средствами Liquibase — любые ручные изменения моментально приводят к неконсистентному состоянию, и уровень доверия ченджсетам становится равен нулю. Потенциальные риски — несколько потраченных часов на восстановление базы, при худшем раскладе — убитый сервер. Если в вашей команде есть DBA Architect «старой закалки», терпеливо и вдумчиво объясните ему, как всё будет плохо, если он просто отредактирует базу по своему разумению из условного SQL Developer.
3. Если ченджсет уже был запушен в репозиторий, избегайте редактирования
Если другой разработчик сделал pull и применил ченджсет, который впоследствии будет отредактирован, — он обязательно помянет вас добрым словом, когда получит ошибку при старте приложения. Если редактирование ченджсета каким-то образом протечёт в девелоп — придётся идти скользкой дорожкой хотфиксов. Суть проблемы упирается в валидацию изменений по хеш-сумме — основной механизм Liquibase. При редактировании кода ченджсета меняется хеш-сумма. Редактирование ченджсетов возможно только тогда, когда присутствует возможность без потери данных развернуть всю базу с нуля. В таком случае рефакторинг SQL или XML кода может, наоборот, облегчить жизнь, сделать миграции более читаемыми. Примером может быть ситуация, когда на старте приложения схема исходной БД согласовывалась внутри команды.
4. Имей проверенные бэкапы баз данных, если это возможно
Тут, думаю, всё понятно. В случае если вдруг миграция прошла неудачно, всё можно будет вернуть назад. В Liquibase есть инструмент отката изменений, но скрипты для отката пишет тоже сам разработчик, и в них могут быть проблемы с такой же вероятностью, как и в скриптах основного ченджсета. Это означает, что перестраховываться с бэкапами полезно в любом случае.
5. Используй проверенные бэкапы баз данных в разработке, если это возможно
Если это не противоречит договорам и privacy, в базе нет персональных данных, и она не весит как два солнца — перед применением на живых серверах миграции можно проверить, как оно сработает на машине разработчика, и вычислить почти 100% потенциальных проблем при миграции.
6. Общайся с другими разработчиками в команде
В правильно организованном процессе разработки все в команде знают, кто чем занят. В реальности часто это не так, поэтому, если в рамках своей задачи готовишь изменения в структуре БД, желательно дополнительно оповестить об этом всю команду. Если кто-то делает изменения параллельно — вам следует аккуратно организоваться. С коллегами стоит общаться и по завершении работы, не только на старте. Много потенциальных проблем с ченджсетами может разрешиться на этапе code review.
7. Думай, что делаешь!
Казалось бы, самоочевидный совет, применимый к любым ситуациям. Однако многих проблем удалось бы избежать, если бы разработчик ещё раз проанализировал, что он делает и на что это может повлиять. Работа с миграциями всегда требует дополнительного внимания и аккуратности.
Ловушки
Давайте теперь рассмотрим типичные ловушки, в которые можно попасть, если не следовать советам выше, и что, собственно, делать-то?
Ситуация 1. Два разработчика пытаются одновременно добавлять новые ченджсеты
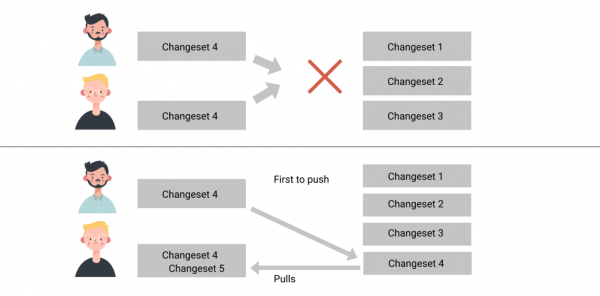
Вася и Петя хотят создать ченджсет версии 4, не зная друг о друге. Они произвели изменения в структуре БД, и выкатили pull request, с разными файлами ченджсета. Далее предлагается следующий механизм действий:
Как решать
- Каким-то образом коллеги должны договориться, в каком порядке должны идти их ченджсеты, допустим, Петин должен быть применён первый.
- Кто-то один должен подлить второй к себе и пометить ченджсет Васи версией 5. Это может быть сделано через Cherry Pick или аккуратный мердж.
- После изменений обязательно следует проверить валидность произведённых действий.
На самом деле механизмы Liquibase позволят иметь в репозитории два ченджсета версии 4, поэтому можно оставить всё как есть. То есть у вас просто будет два изменения версии 4 с разными названиями. При таком подходе впоследствии в версиях базы данных становится очень сложно ориентироваться.
Кроме того, Liquibase, как дома хоббитов, хранит в себе много секретов. Одним из них является ключ validCheckSum, который появился с версии 1.7 и позволяет указать валидное значение хеш-суммы для определенного ченджсета вне зависимости от того, что хранится в базе данных. Документация говорит следующее:
Add a checksum that is considered valid for this changeSet, regardless of what is stored in the database. Used primarily when you need to change a changeSet and don’t want errors thrown on databases on which it has already run (not a recommended procedure)
Да-да, такая процедура не рекомендуется. Но иногда сильный светлый маг владеет и темными техниками
Ситуация 2. Миграция, которая зависит от данных
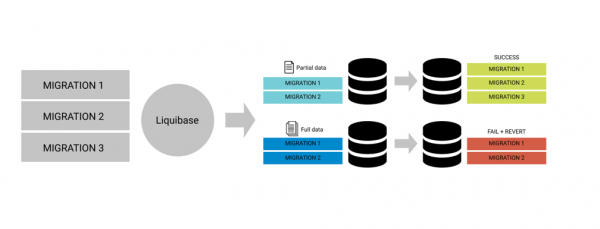
Предположим, у вас нет возможности использовать резервные копии баз с живых серверов. Петя создал ченджсет, проверил его локально и с полной уверенностью своей правоты сделал pull request в девелоп. Лид проекта на всякий случай уточнил, проверил ли его Петя, и затем влил. Но развертывание на девелоп сервере упало.
На самом деле такое возможно, и от этого никто не застрахован. Это происходит в том случае, если модификации структуры таблиц каким-то образом завязаны на конкретные данные из БД. Очевидно, что если база Пети заполнена только тестовыми данными, то она может не покрывать все проблемные кейсы. Например, при удалении таблицы выясняется, что есть записи в других таблицах по Foreign Key, связанные с записями в удаляемой. Или при изменении типа колонки выясняется, что не 100% данных могут быть преобразованы к новому типу.
Как решать
- Написать специальные скрипты, которые будут однократно применяться вместе с миграцией и приводить данные в надлежащий вид. Это общий путь решения проблемы переноса данных в новые структуры уже после применения миграций, но что-то подобное может быть применено и до, в частных случаях. Такой путь, конечно, не всегда доступен, ибо редактировать данные на живых серверах может быть опасно и даже губительно.
- Другой сложный путь — отредактировать имеющийся ченджсет. Сложность в том, что все БД, где он в имеющемся виде уже был применён, придётся восстанавливать. Вполне возможно, что вся бэкенд-команда вынуждена будет локально накатить БД с нуля.
- И самый универсальный путь — перенос проблемы с данными на environment разработчика с воссозданием той же ситуации и добавление нового ченджсета, до сломанного, который позволит обойти проблему.

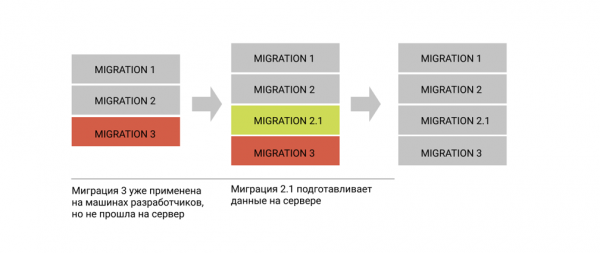
В целом, чем больше база по составу данных похожа на базу продакшн сервера, тем меньше шанс, что проблемы с миграциями протекут далеко. И, конечно, прежде чем отправить ченджсет в репозиторий, стоит несколько раз подумать, не сломает ли он что-нибудь.
Ситуация 3. Liquibase начинает применяться уже после выхода в продакшн
Предположим, тимлид попросил Петю подключить в проект Liquibase, однако проект уже в продакшене и имеется уже существующая структура базы.
Соответственно, проблема состоит в том, чтобы на любых новых серверах или машинах разработчиков данные таблицы должны воссоздаваться с нуля, а уже существующая среда должна остаться в консистентном состоянии, будучи готовой принимать новые ченджсеты.
Как решать
Тут также имеется несколько путей:
- Первый и самый очевидный — иметь отдельный скрипт, который должен быть применён вручную при инициализации нового окружения.
- Второй — менее очевидный, иметь Liquibase миграцию, которая находится в другом Liquibase Context, и применять её. Подробнее про Liquibase Context можно прочитать тут: . В целом это интересный механизм, который может быть успешно применён, например, для тестирования.
- Третий путь состоит из нескольких шагов. Сначала должна быть создана миграция для уже имеющихся таблиц. Затем она должна быть применена на каком-то environment’е и таким образом будет получена её хэш-сумма. Следующим шагом следует проинициализировать на нашем не пустом сервере пустые Liquibase таблицы, и в таблицу с историей применения ченджсетов можно мануально положить запись о «как будто бы применённом» ченджсете с уже имеющимися в базе изменениями. Таким образом, на уже существующем сервере отсчёт истории пойдёт с версии 2, а все новые environments будут вести себя идентично.

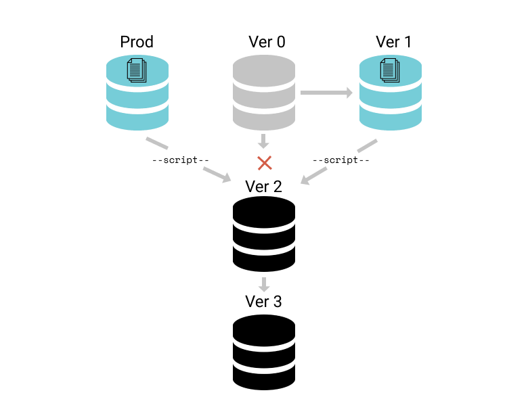
Ситуация 4. Миграции становятся огромными и не успевают выполняться
В начале разработки сервиса, как правило, Liquibase используется как внешняя зависимость, и все миграции обрабатываются при старте приложения. Однако со временем вы можете наткнуться на следующие кейсы:
- Миграции становятся огромными и выполняются долгое время.
- Появляется необходимость миграции в распределенных средах, допустим, на нескольких инстансах серверов БД одновременно.
В таком случае слишком долгое применение миграций приведет к таймауту при старте приложения. Кроме того, применение миграций для каждого инстанса приложения отдельно может привести к тому, что разные серверы окажутся в не синхронном состоянии.
Как решать
В таких случаях ваш проект уже большой, возможно даже совершеннолетний, и Liquibase начинает выступать как отдельный внешний инструмент. Дело в том, что Liquibase как библиотека собирается в jar файл, и может работать как зависимость внутри проекта, так и автономно.
В автономном режиме можно возложить применение миграций на вашу CI/CD среду или на крепкие плечи ваших системных администраторовспециалистов по развертыванию. Для этого понадобится командная строка Liquibase . В таком режиме появляется возможность производить запуск приложения уже после того, как все необходимые миграции были проведены.
Вывод
На самом деле ловушек при работе с миграциями БД может быть гораздо больше, и многие из них требуют творческого подхода. Важно понимать, что если правильно использовать инструмент, то большинство из этих ловушек удастся избежать. Конкретно мне приходилось в разных видах сталкиваться со всеми перечисленными проблемами, а некоторые из них были результатом моих косяков. В основном это происходит, конечно, по невнимательности, но иногда – по причине преступного неумения использовать инструмент.
Источник: habr.com
