


В этой статье собраны некоторые общие шаблоны, помогающие инженерам работать с масштабными сервисами, к которым делают запросы миллионы пользователей.
По опыту автора, это не исчерпывающий список, но действительно эффективные советы. Итак, начнем.
Переведено при поддержке .
Начальный уровень
Перечисленные ниже меры относительно просты в реализации, но дают высокую отдачу. Если вы раньше их не предпринимали, то будете удивлены значительными улучшениями.
Инфраструктура как код
Первая часть советов заключается в том, чтобы реализовать инфраструктуру как код. Это означает, что у вас должен быть программный способ развертывания всей инфраструктуры. Звучит замысловато, но на самом деле мы говорим о следующем коде:
Развертывание 100 виртуальных машин
- с Ubuntu
- 2 ГБ RAM на каждой
- у них будет следующий код
- с такими параметрами
Вы можете отслеживать изменения в инфраструктуре и быстро возвращаться к ним с помощью системы управления версиями.
Модернист во мне говорит, что можно использовать Kubernetes/Docker, чтобы сделать всё выше перечисленное, и он прав.
Кроме того, обеспечить автоматизацию, можно с помощью Chef, Puppet или Terraform.
Непрерывная интеграция и доставка
Для создания масштабируемого сервиса важно наличие конвейера сборки и теста для каждого пул-реквеста. Даже если тест самый простой, он, по крайней мере, гарантирует, что код, который вы деплоите, компилируется.
Каждый раз на этом этапе вы отвечаете на вопрос: будет ли моя сборка компилироваться и проходить тесты, валидна ли она? Это может показаться низкой планкой, но решает множество проблем.
Нет ничего прекраснее, чем видеть эти галочки
Для этой технологии можете оценить Github, CircleCI или Jenkins.
Балансировщики нагрузки
Итак, мы хотим запустить балансировщик нагрузки, чтобы перенаправлять трафик, и обеспечить равную нагрузку на всех узлах или работу сервиса в случае сбоя:
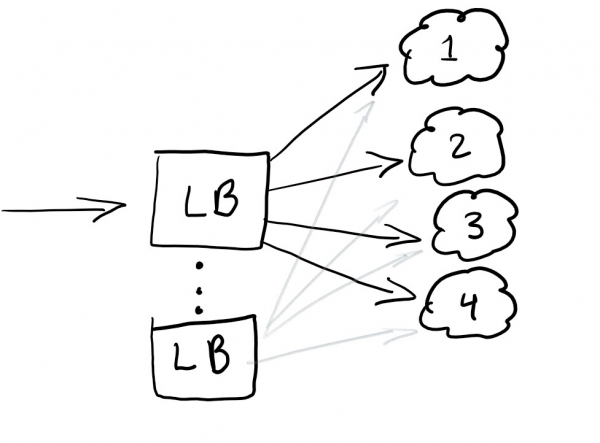
Балансировщик нагрузки, как правило, хорошо помогает распределять трафик. Наилучшей практикой является избыточная балансировка, чтобы у вас не было единой точки отказа.
Обычно балансировщики нагрузки настраиваются в том облаке, которым вы пользуетесь.
RayID, сorrelation ID или UUID для запросов
Вам когда-нибудь встречалась ошибка в приложении с сообщением вроде такого: «Что-то пошло не так. Сохраните этот id и отправьте его в нашу службу поддержки»?
Уникальный идентификатор, correlation ID, RayID или любой из вариантов — это уникальный идентификатор, который позволяет отслеживать запрос в течение его жизненного цикла. Это позволяет отследить весь путь запроса в логах.
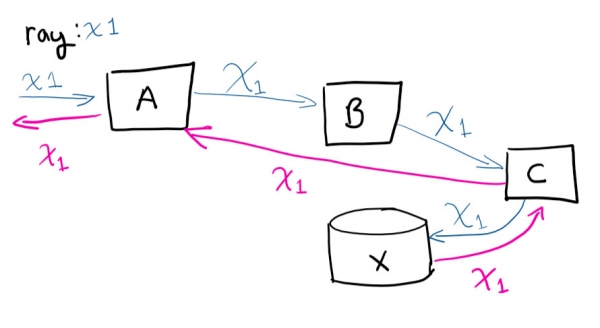
Пользователь делает запрос к системе A, затем А связывается с B, та связывается с C, сохраняет в X и затем запрос возвращается в A
Если бы вы удаленно подключились к виртуальным машинам и попытались проследить путь запроса (и вручную соотнести, какие происходят вызовы), то сошли бы с ума. Наличие уникального идентификатора значительно облегчает жизнь. Это одна из самых простых вещей, которую можно сделать, чтобы сэкономить время по мере роста сервиса.
Средний уровень
Здесь советы сложнее предыдущих, но правильные инструменты облегчают задачу, обеспечивая окупаемость инвестиций даже для малых и средних компаний.
Централизованное ведение журналов
Поздравляю! Вы развернули 100 виртуальных машин. На следующий день генеральный директор приходит и жалуется на ошибку, которую получил во время тестирования сервиса. Он сообщает соответствующий идентификатор, о котором мы говорили выше, но вам придется просматривать журналы 100 машин, чтобы найти ту, которая вызвала сбой. И ее нужно найти до завтрашней презентации.
Хотя это звучит как забавное приключение, однако, лучше убедиться, что у вас есть возможность поиска по всем журналам из одного места. Я решил задачу централизации журналов с помощью встроенной функциональности стека ELK: здесь поддерживается сбор журналов с возможностью поиска. Это действительно поможет решить проблему с поиском конкретного журнала. В качестве бонуса вы можете создавать диаграммы и тому подобные забавные штуки.
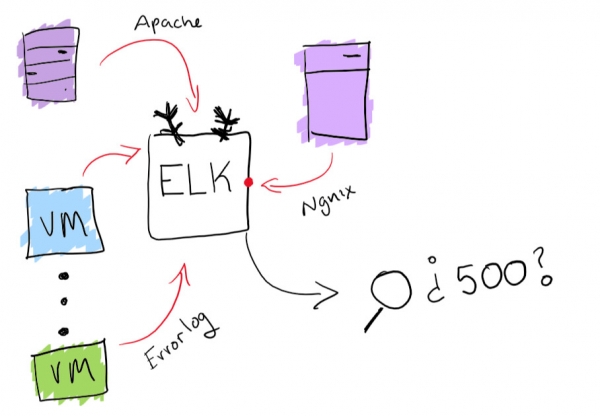
Функциональность стека ELK
Агенты мониторинга
Теперь, когда ваша служба введена в строй, нужно убедиться, что она работает без сбоев. Лучший способ сделать это — запустить несколько агентов, которые работают параллельно и проверяют, что она работает и выполняются базовые операции.
На этом этапе вы проверяете, что запущенная сборка хорошо себя чувствует и нормально работает.
Для небольших и средних проектов я рекомендую Postman для мониторинга и документирования API. Но в целом просто следует убедиться, что у вас есть способ узнать, когда произошел сбой, и получить своевременное оповещение.
Автомасштабирование в зависимости от нагрузки
Это очень просто. Если у вас есть виртуальная машина, обслуживающая запросы, и она приближается к тому, что 80% памяти занято, то можно либо увеличить ее ресурсы, либо добавить в кластер больше виртуальных машин. Автоматическое выполнение этих операций отлично подходит для эластичного изменения мощности под нагрузкой. Но вы всегда должны быть осторожны в том, сколько денег тратите, и установить разумные лимиты.
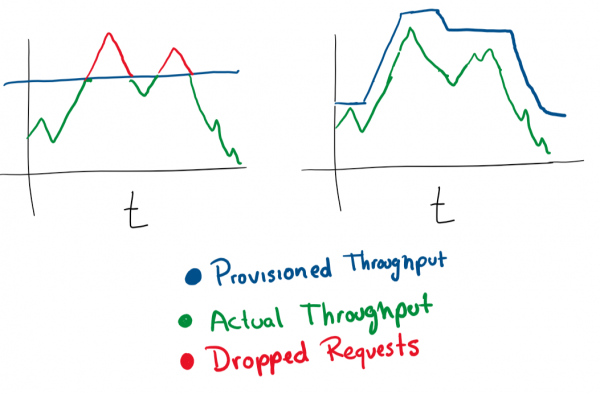
В большинстве облачных служб вы можете настроить автоматическое масштабирование, используя большее количество серверов или более мощные серверы.
Система экспериментов
Хорошим способом безопасно развернуть обновления станет возможность протестировать что-то для 1% пользователей в течение часа. Вы, конечно, видели такие механизмы в действии. Например, Facebook показывает части аудитории другой цвет или меняет размер шрифта, чтобы посмотреть, как пользователи воспринимают изменения. Это называют A/B-тестированием.
Даже выпуск новой функции можно запустить как эксперимент, а затем определить, как ее выпускать. Также вы получаете возможность «вспоминать» или изменять конфигурацию на лету с учетом функции, которая вызывает деградацию вашего сервиса.
Продвинутый уровень
Здесь советы, которые довольно сложно реализовать. Вероятно, вам потребуется немного больше ресурсов, поэтому небольшой или средней компании будет трудно с этим справиться.
Сине-зеленые развертывания
Это то, что я называю «эрланговским» способом развертывания. Erlang стали широко использовать, когда появились телефонные компании. Для маршрутизации телефонных звонков стали применять программные коммутаторы. Основная задача программного обеспечения этих коммутаторов заключалась в том, чтобы не сбрасывать вызовы во время обновления системы. У Erlang есть прекрасный способ загрузки нового модуля без падения предыдущего.
Этот шаг зависит от наличия балансировщика нагрузки. Представим, что у вас версия N вашего программного обеспечения, а затем вы хотите развернуть версию N+1.
Вы могли бы просто остановить службу и развернуть следующую версию в то время, которое считаете удобным для ваших пользователей, и получить некоторое время простоя. Но предположим, что у вас действительно строгие условия SLA. Так, SLA 99,99% означает, что вы можете уходить в офлайн только на 52 минуты в год.
Если вы действительно хотите достичь таких показателей, нужно два деплоя одновременно:
- тот, который есть прямо сейчас (N);
- следующая версия (N+1).
Вы указываете балансировщику нагрузки перенаправить процент трафика на новую версию (N+1), в то время как сами активно отслеживаете регрессии.
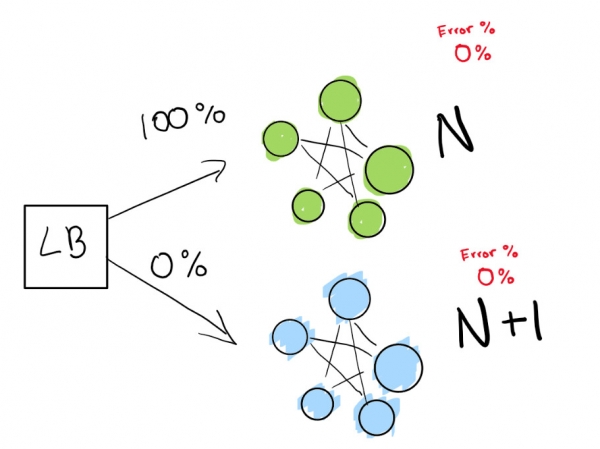
Здесь у нас есть зеленый деплой N, который нормально работает. Мы пытаемся перейти к следующей версии этого деплоя
Сначала мы посылаем действительно небольшой тест, чтобы посмотреть, работает ли наш деплой N+1 с небольшим количеством трафика:
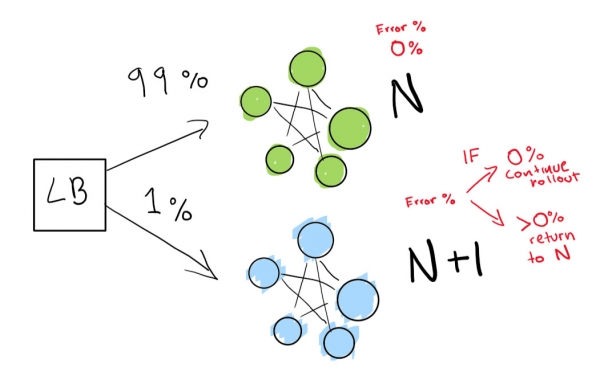
Наконец, у нас есть набор автоматических проверок, которые мы в конечном итоге запускаем до тех пор, пока наше развертывание не будет завершено. Если вы очень-очень осторожны, также можете сохранить свое развертывание N навсегда для быстрого отката в случае плохой регрессии:
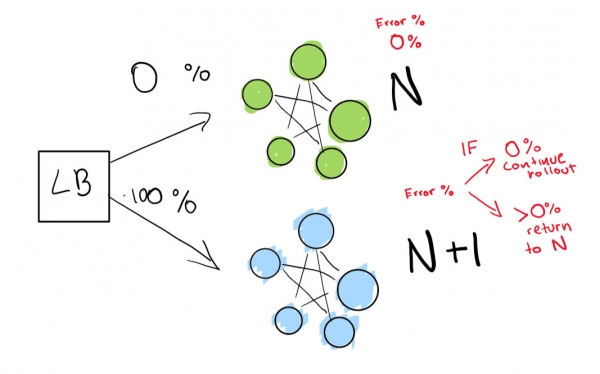
Если хотите перейти на еще более продвинутый уровень, пусть всё в сине-зеленом деплое выполняется автоматически.
Обнаружение аномалий и автоматическое смягчение последствий
Учитывая, что у вас централизованное ведение журналов и хороший сбор логов, уже можно ставить более высокие цели. Например, проактивно прогнозировать сбои. На мониторах и в журналах отслеживаются функции и строятся различные диаграммы — и можно заранее предсказать, что пойдет не так:
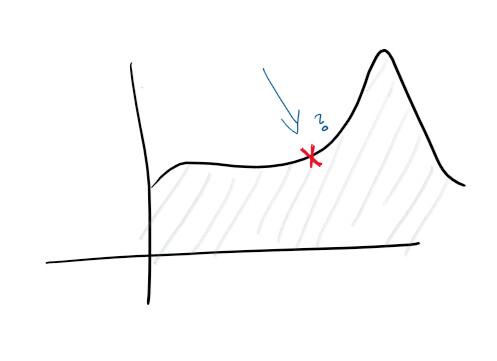
С обнаружением аномалий вы начинаете изучать некоторые подсказки, которые выдает сервис. Например, всплеск нагрузки на CPU может подсказать, что жесткий диск выходит из строя, а всплеск количества запросов означает, что нужно масштабироваться. Такого рода статистические данные позволяют сделать сервис проактивным.
Получая такие аналитические данные, вы можете масштабироваться в любом измерении, проактивно и реактивно изменять характеристики машин, баз данных, соединений и других ресурсов.
Вот и всё!
Этот список приоритетов избавит вас от многих проблем, если вы поднимаете облачный сервис.
Автор оригинальной статьи приглашает читателей оставлять свои комментарии и вносить изменения. Статья распространяется как open source, пул-реквесты автор .
Что еще почитать по теме:
Источник: habr.com
