

Высокая производительность — одно из ключевых требований при работе с большими данными. Мы в управлении загрузки данных в Сбере занимаемся прокачкой практически всех транзакций в наше Облако Данных на базе Hadoop и поэтому имеем дело с действительно большими потоками информации. Естественно, что мы все время ищем способы повысить производительность, и теперь хотим рассказать, как удалось пропатчить RegionServer HBase и HDFS-клиент, благодаря чему удалось значительно увеличить скорость операции чтения.
Однако, прежде чем перейти к сути доработок, стоит проговорить про ограничения, которые в принципе невозможно обойти, если сидеть на HDD.
Почему HDD и быстрые Random Access чтения несовместимы
Как известно, HBase, да и многие другие БД, хранят данные блоками, размером в несколько десятков килобайт. По умолчанию это порядка 64 Кб. Теперь представим себе, что нам нужно достать всего 100 байт и мы просим HBase выдать нам эти данные по некоему ключу. Так как размер блока в HFiles равен 64 Кб то запрошено будет в 640 раз больше (на минуточку!) чем нужно.
Далее, так как запрос пойдет через HDFS и его механизм кэширования метаданных ShortCircuitCache (который позволяет осуществлять прямой доступ к файлам), то это приводит к чтению уже 1 Мб с диска. Впрочем это можно регулировать параметром dfs.client.read.shortcircuit.buffer.size и во многих случаях имеет смысл уменьшать это значение, например до 126 Кб.
Допустим мы сделаем это, но кроме того, когда мы начнем читать данные через java api, таким функциями как FileChannel.read и просим операционную систему прочитать указанный объем данных, она вычитывает «на всякий случай» в 2 раза больше, т.е. в 256 Кб в нашем случае. Это происходит потому, что в java нет простой возможности выставить флаг FADV_RANDOM, предотвращающий такое поведение.
В итоге, чтобы получить наши 100 байт, под капотом вычитывается в 2600 раз больше. Казалось бы — выход очевиден, давайте уменьшим размер блока до килобайта, выставим упомянутый флаг и обретем великое просветление ускорение. Но беда в том, что уменьшая размер блока в 2 раза, мы уменьшаем и количество вычитанных байт в единицу времени так же в 2 раза.
Некоторый выигрыш от выставления флага FADV_RANDOM можно получить, но только при большой многопоточности и при размере размер блока от 128 Кб, но это максимум пара десятков процентов:

Тесты проводились на 100 файлах, каждый размером в 1 Гб и размещенных на 10 дисках HDD.
Давайте посчитаем, на что мы с такой скоростью можем в принципе рассчитывать:
Допустим мы читаем с 10 дисков со скоростью 280 МБ/сек, т.е. 3 миллиона раз по 100 байт. Но как мы помним, нужны нам данные встречаются в 2600 раз меньше, чем прочитано. Таким образом 3 млн. делим на 2600 и получаем 1100 записей в секунду.
Удручающе, не так ли? Такова природа Random Access доступа к данным на HDD — вне зависимости от размера блока. Это физический предел случайного доступа и большего в таких условиях не сможет выжать ни одна БД.
Как же тогда базам получается достигать гораздо более высокую скорость? Чтобы ответить на этот вопрос давайте посмотрим, что происходит на следующей картинке:
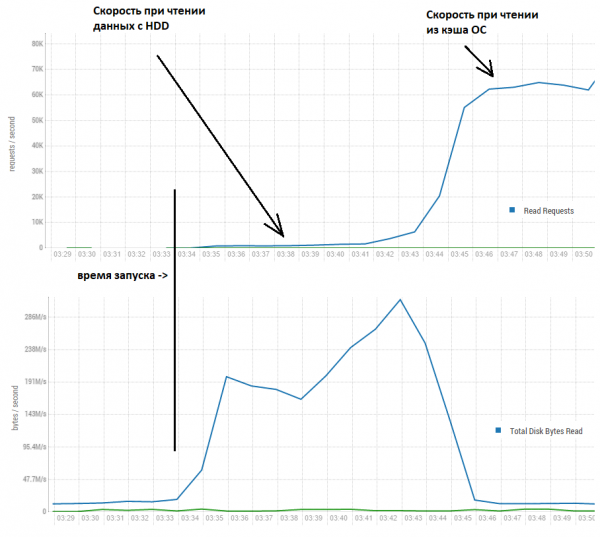
Тут мы видим, что первые несколько минут скорость действительно порядка тысячи записей в секунду. Однако далее, благодаря тому, что вычитывается гораздо больше чем было запрошено, то данные оседают в buff/cache операционной системы (linux) и скорость растет до более приличных 60 тыс. в секунду
Таким образом далее мы будем разбираться с ускорением доступа только к тем данным, которые есть в кэше ОС или находятся в сравнимых по скорости доступа хранилищ типа SSD/NVMe.
В нашем случае мы будем проводить тесты на стенде из 4х серверов, каждый из которых заряжен следующим образом:
CPU: Xeon E5-2680 v4 @ 2.40GHz 64 threads.
Память: 730 Гб.
java version: 1.8.0_111
И тут собственно ключевой момент — объем данных в таблицах, которые требуется вычитывать. Дело в том, что если читать данные из таблицы, которая целиком помещаются в кэш HBase, то до чтения из buff/cache операционки дело даже не дойдет. Потому что HBase по умолчанию выделяет 40% памяти под структуру которая называется BlockCache. По сути это ConcurrentHashMap, где ключ это имя файла+offset блока, а value собственно данные по этому смещению.
Таким образом, когда чтение идет только из этой структуры, мы , вроде миллиона запросов в секунду. Но давайте представим себе, что мы не можем отдавать сотни гигабайт памяти только под нужды БД, потому что на этих серверах крутится много чего еще полезного.
Например в нашем случае объем BlockCache на одном RS это порядка 12 Гб. Мы высадили два RS на одну ноду, т.е. под BlockCache выделено 96 Гб на всех нодах. А данных при этом во много раз больше, например пусть это будет 4 таблицы, по 130 регионов, в которых файлы размером по 800 Мб, пожатые FAST_DIFF, т.е. в сумме 410 Гб (это чистые данные, т.е. без учета фактора репликации).
Таким образом, BlockCache составляет лишь около 23% от общего объема данных и это гораздо ближе к реальным условиям того, что называется BigData. И вот тут начинается самое интересное — ведь очевидно, чем меньше попаданий в кэш, тем хуже производительность. Ведь в случае промаха придется выполнить кучу работы — т.е. спуститься до вызова системных функций. Однако этого не избежать и поэтому давайте рассмотрим совсем другой аспект — а что происходит с данными внутри кэша?
Упростим ситуацию и допустим, что у нас есть кэш в который помещается только 1 объект. Вот пример того что произойдет при попытке работы с объемом данных в 3 раза больше чем кэш, нам придется:
1. Поместить блок 1 в кэш
2. Удалить блок 1 из кэша
3. Поместить блок 2 в кэш
4. Удалить блок 2 из кэша
5. Поместить блок 3 в кэш
Проделано 5 действий! Однако нормальной этой ситуацию называть никак нельзя, по сути мы заставляем HBase проделывать кучу совершенно бесполезной работы. Он постоянно вычитывает данные из кэша ОС, помещает его себе в BlockCache, для того чтобы почти тут же выкинуть его, потому что приехала новая порция данных. Анимация в начале поста показывает суть проблемы — Garbage Collector зашкаливает, атмосфера греется, маленькая Грета в далекой и жаркой Швеции расстраивается. А мы айтишники очень не любим, когда грустят дети, поэтому начинаем думать, что с этим можно поделать.
А что если помещать в кэш не все блоки, а только определенный процент из них, так чтобы кэш не переполнялся? Давайте для начала просто добавим всего несколько строк кода в начало функции помещения данных в BlockCache:
public void cacheBlock(BlockCacheKey cacheKey, Cacheable buf, boolean inMemory) {
if (cacheDataBlockPercent != 100 && buf.getBlockType().isData()) {
if (cacheKey.getOffset() % 100 >= cacheDataBlockPercent) {
return;
}
}
...
Смысл тут в следующем, оффсет — это положение блока в файле и последние цифры его случайно и равномерно распределены от 00 до 99. Поэтому мы будем пропускать только те, которые попадают в нужный нам диапазон.
Например выставим cacheDataBlockPercent = 20 и посмотрим что будет:
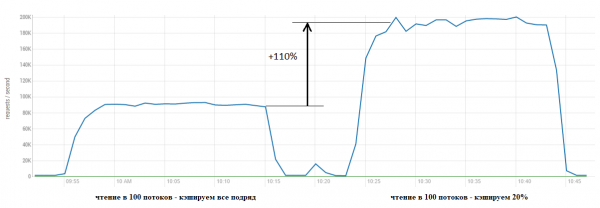
Результат налицо. На графиках ниже становится понятно, за счет чего произошло такое ускорение — мы экономим кучу ресурсов GC не занимаясь сизифовым трудом размещения данных к кэше лишь для того, чтобы тут же выбросить их в марсианским псам под хвост:
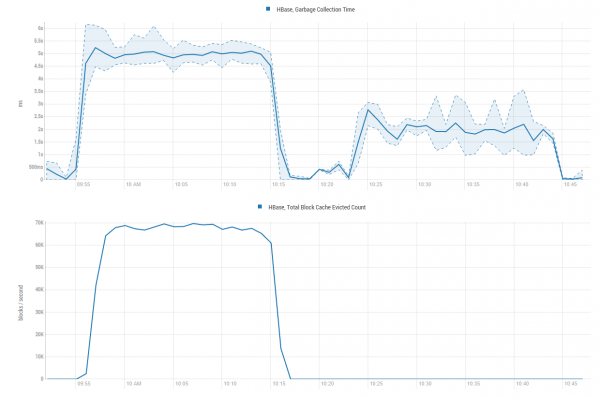
Утилизация CPU при этом растет, однако сильно меньше чем производительность:
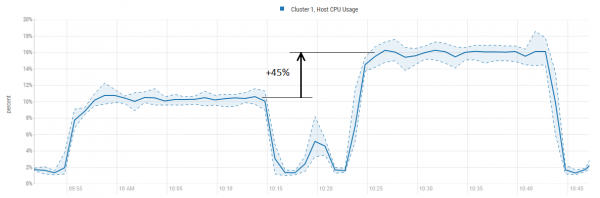
Тут еще стоит отметить, что блоки которые хранятся в BlockCache бывают разные. Большая часть, порядка 95% это собственно данные. А остальное это метаданных, типа Bloom фильтров или LEAF_INDEX и . Этих данных мало, но они очень полезные, так как прежде чем обратиться непосредственно к данным, HBase обращается к мете, чтобы понять нужно ли искать тут дальше и если да, то где именно находится интересующий его блок.
Поэтому в коде мы видим условие проверку buf.getBlockType().isData() и благодаря этому мету мы будем оставлять в кэше в любом случае.
Теперь давайте увеличим нагрузку и за одно слегка затюним фичу. В первом тесте мы сделали процент отсечения = 20 и BlockCache был немного недозагружен. Теперь поставим 23% и будем добавлять по 100 потоков каждые 5 минут, чтобы увидеть, в какой момент происходит насыщение:
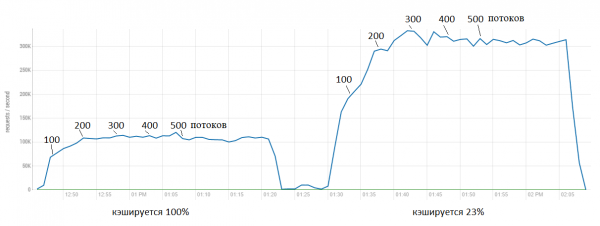
Тут мы видим, что исходная версия практически сразу упирается в потолок на уровне около 100 тыс запросов в секунду. Тогда как патч дает ускорение до 300 тысяч. При этом понятно, что дальнейшее ускорение уже не такое «бесплатное», утилизация CPU при этом тоже растет.
Однако это не очень изящное решение, так как мы заранее не знаем, какой процентов блоков нужно кешировать, это зависит от профиля нагрузки. Поэтому был реализован механизм автоматической подстройки этого параметра в зависимости от активности операций чтения.
Для управления этим было добавлено три параметра:
hbase.lru.cache.heavy.eviction.count.limit — устанавливает, сколько раз должен запуститься процесс выселения данных из кеша, прежде чем мы начнем использовать оптимизацию (т.е. пропускать блоки). По умолчанию оно равно MAX_INT = 2147483647 и фактически означает, что фича никогда не начнет работать при таком значении. Потому что процесс выселения запускается каждые 5 — 10 секунд (это зависит от нагрузки) и 2147483647 * 10 / 60 / 60 / 24 / 365 = 680 лет. Однако мы можем установить этот параметр равным 0 и заставить фичу работать сразу же после старта.
Однако есть и полезная нагрузка в этом параметре. Если у нас характер нагрузки такой, что постоянно перемежаются краткосрочные чтения (допустим днем) и долгосрочные (по ночам), то мы можем сделать так, что фича будет включаться только когда идут продолжительные операции чтения.
Например мы знаем, что краткосрочные чтения длятся обычно около 1 минуты. На не надо начинать выкидывать блоки, кеш не успеет устареть и тогда мы можем установить этот параметр равным например 10. Это приведет к тому, что оптимизация начнет работать только когда началось длительное активное чтение, т.е. через 100 секунд. Таким образом если мы имеем краткосрочное чтение, то все блоки попадут в кеш и будут доступны (за исключением тех что будут выселены стандартным алгоритмом). А когда мы делаем долгосрочные чтения, фича включается и бы имеем намного более высокую производительность.
hbase.lru.cache.heavy.eviction.mb.size.limit — устанавливает, как много мегабайт нам хотелось бы помещать в кеш (и естественно выселять) за 10 секунд. Фича будет пытаться достигнуть этого значения и поддерживать его. Смысл в следующем, если мы пихаем в кеш гигабайты, то и выселять придется гигабайты, а это, как мы видели выше, весьма накладно. Однако не нужно пытаться выставить его слишком маленьким, так как это приведет к преждевременному выходу из режима пропуска блоков. Для мощных серверов (порядка 20-40 физических ядер) оптимально выставлять около 300-400 МБ. Для среднего класса (~10 ядер) 200-300 МБ. Для слабых систем (2-5 ядра) может быть нормально 50-100 МБ (на таких не тестировалось).
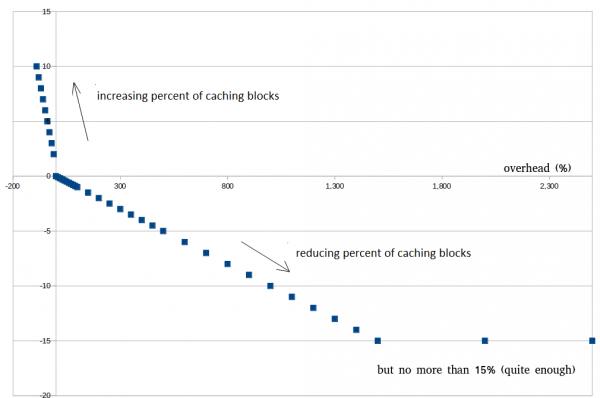
Рассмотрим, как это работает: допустим мы выставили hbase.lru.cache.heavy.eviction.mb.size.limit = 500, идет какая-то нагрузка (чтения) и тогда каждые ~10 секунд мы вычисляем, сколько байт было выселено по формуле:
Overhead = Freed Bytes Sum (MB) * 100 / Limit (MB) — 100;
Если по факту было выселено 2000 MB, то Overhead получается равным:
2000 * 100 / 500 — 100 = 300%
Алгоритмы же стараются поддерживать не больше чем несколько десятков процентов, так что фича будет уменьшать процент кешируемых блоков, тем самым реализуя механизм авто-тюнинга.
Однако если нагрузка упала, допустим выселено всего 200 МБ и Overhead стал отрицательным (так называемый overshooting):
200 * 100 / 500 — 100 = -60%
То фича наоборот, будет увеличивать процент кешируемых блоков до тех пор, пока Overhead не станет положительным.
Ниже будет пример как это выглядит на реальных данных. Не нужно пытаться достигнуть 0%, это невозможно. Весьма хорошо когда когда около 30 — 100%, это помогает избежать преждевременного выхода из режима оптимизации при краткосрочных всплесках.
hbase.lru.cache.heavy.eviction.overhead.coefficient — устанавливает, как быстро мы хотели бы получить результат. Если мы твердо знаем, что наши чтения в основном длительные и не хотим ждать, мы можем увеличить этот коэффициент и получить высокую производительность быстрее.
Например, мы установили этот коэффициент = 0.01. Это означает что Overhead (см. выше) будет умножен на это число на на полученный результат и будет уменьшен процент кешируемых блоков. Допустим, что Overhead = 300%, а коэффициент = 0.01, то процент кешируемых блоков будет уменьшен на 3%.
Подобная логика «Backpressure» — реализована и для отрицательных значений Overhead (overshooting). Так как всегда возможны краткосрочные колебания объема чтений-выселений, то этот механизм позволяет избегать преждевременный выход из режима оптимизации. Backpressure имеет перевернутую логику: чем сильнее overshooting, тем тем больше кешируется блоков.
Код реализации
LruBlockCache cache = this.cache.get();
if (cache == null) {
break;
}
freedSumMb += cache.evict()/1024/1024;
/*
* Sometimes we are reading more data than can fit into BlockCache
* and it is the cause a high rate of evictions.
* This in turn leads to heavy Garbage Collector works.
* So a lot of blocks put into BlockCache but never read,
* but spending a lot of CPU resources.
* Here we will analyze how many bytes were freed and decide
* decide whether the time has come to reduce amount of caching blocks.
* It help avoid put too many blocks into BlockCache
* when evict() works very active and save CPU for other jobs.
* More delails: https://issues.apache.org/jira/browse/HBASE-23887
*/
// First of all we have to control how much time
// has passed since previuos evict() was launched
// This is should be almost the same time (+/- 10s)
// because we get comparable volumes of freed bytes each time.
// 10s because this is default period to run evict() (see above this.wait)
long stopTime = System.currentTimeMillis();
if ((stopTime - startTime) > 1000 * 10 - 1) {
// Here we have to calc what situation we have got.
// We have the limit "hbase.lru.cache.heavy.eviction.bytes.size.limit"
// and can calculte overhead on it.
// We will use this information to decide,
// how to change percent of caching blocks.
freedDataOverheadPercent =
(int) (freedSumMb * 100 / cache.heavyEvictionMbSizeLimit) - 100;
if (freedSumMb > cache.heavyEvictionMbSizeLimit) {
// Now we are in the situation when we are above the limit
// But maybe we are going to ignore it because it will end quite soon
heavyEvictionCount++;
if (heavyEvictionCount > cache.heavyEvictionCountLimit) {
// It is going for a long time and we have to reduce of caching
// blocks now. So we calculate here how many blocks we want to skip.
// It depends on:
// 1. Overhead - if overhead is big we could more aggressive
// reducing amount of caching blocks.
// 2. How fast we want to get the result. If we know that our
// heavy reading for a long time, we don't want to wait and can
// increase the coefficient and get good performance quite soon.
// But if we don't sure we can do it slowly and it could prevent
// premature exit from this mode. So, when the coefficient is
// higher we can get better performance when heavy reading is stable.
// But when reading is changing we can adjust to it and set
// the coefficient to lower value.
int change =
(int) (freedDataOverheadPercent * cache.heavyEvictionOverheadCoefficient);
// But practice shows that 15% of reducing is quite enough.
// We are not greedy (it could lead to premature exit).
change = Math.min(15, change);
change = Math.max(0, change); // I think it will never happen but check for sure
// So this is the key point, here we are reducing % of caching blocks
cache.cacheDataBlockPercent -= change;
// If we go down too deep we have to stop here, 1% any way should be.
cache.cacheDataBlockPercent = Math.max(1, cache.cacheDataBlockPercent);
}
} else {
// Well, we have got overshooting.
// Mayby it is just short-term fluctuation and we can stay in this mode.
// It help avoid permature exit during short-term fluctuation.
// If overshooting less than 90%, we will try to increase the percent of
// caching blocks and hope it is enough.
if (freedSumMb >= cache.heavyEvictionMbSizeLimit * 0.1) {
// Simple logic: more overshooting - more caching blocks (backpressure)
int change = (int) (-freedDataOverheadPercent * 0.1 + 1);
cache.cacheDataBlockPercent += change;
// But it can't be more then 100%, so check it.
cache.cacheDataBlockPercent = Math.min(100, cache.cacheDataBlockPercent);
} else {
// Looks like heavy reading is over.
// Just exit form this mode.
heavyEvictionCount = 0;
cache.cacheDataBlockPercent = 100;
}
}
LOG.info("BlockCache evicted (MB): {}, overhead (%): {}, " +
"heavy eviction counter: {}, " +
"current caching DataBlock (%): {}",
freedSumMb, freedDataOverheadPercent,
heavyEvictionCount, cache.cacheDataBlockPercent);
freedSumMb = 0;
startTime = stopTime;
}
Рассмотрим теперь все это на реальном примере. Имеем следующий тестовый сценарий:
- Начинаем делать Scan (25 threads, batch = 100)
- Через 5 минут добавляем multi-gets (25 threads, batch = 100)
- Через 5 минут выключаем multi-gets (остается опять только scan)
Делаем два прогона, сначала hbase.lru.cache.heavy.eviction.count.limit = 10000 (что фактически выключает фичу), а затем ставим limit = 0 (включает).
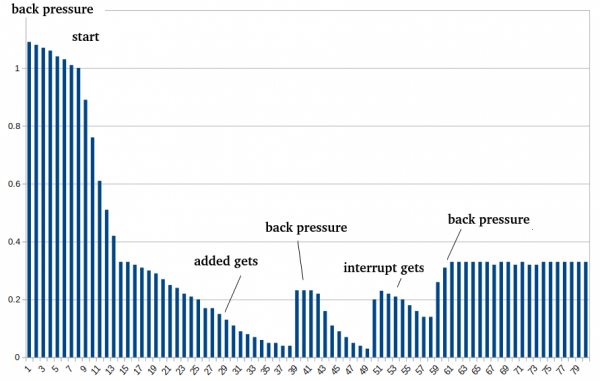
В логах ниже мы видим, как включается фича, сбрасывает Overshooting до 14-71%. Время от времени нагрузка снижается, что включает Backpressure и HBase вновь кеширует больше блоков.
Лог RegionServer
evicted (MB): 0, ratio 0.0, overhead (%): -100, heavy eviction counter: 0, current caching DataBlock (%): 100
evicted (MB): 0, ratio 0.0, overhead (%): -100, heavy eviction counter: 0, current caching DataBlock (%): 100
evicted (MB): 2170, ratio 1.09, overhead (%): 985, heavy eviction counter: 1, current caching DataBlock (%): 91 < start
evicted (MB): 3763, ratio 1.08, overhead (%): 1781, heavy eviction counter: 2, current caching DataBlock (%): 76
evicted (MB): 3306, ratio 1.07, overhead (%): 1553, heavy eviction counter: 3, current caching DataBlock (%): 61
evicted (MB): 2508, ratio 1.06, overhead (%): 1154, heavy eviction counter: 4, current caching DataBlock (%): 50
evicted (MB): 1824, ratio 1.04, overhead (%): 812, heavy eviction counter: 5, current caching DataBlock (%): 42
evicted (MB): 1482, ratio 1.03, overhead (%): 641, heavy eviction counter: 6, current caching DataBlock (%): 36
evicted (MB): 1140, ratio 1.01, overhead (%): 470, heavy eviction counter: 7, current caching DataBlock (%): 32
evicted (MB): 913, ratio 1.0, overhead (%): 356, heavy eviction counter: 8, current caching DataBlock (%): 29
evicted (MB): 912, ratio 0.89, overhead (%): 356, heavy eviction counter: 9, current caching DataBlock (%): 26
evicted (MB): 684, ratio 0.76, overhead (%): 242, heavy eviction counter: 10, current caching DataBlock (%): 24
evicted (MB): 684, ratio 0.61, overhead (%): 242, heavy eviction counter: 11, current caching DataBlock (%): 22
evicted (MB): 456, ratio 0.51, overhead (%): 128, heavy eviction counter: 12, current caching DataBlock (%): 21
evicted (MB): 456, ratio 0.42, overhead (%): 128, heavy eviction counter: 13, current caching DataBlock (%): 20
evicted (MB): 456, ratio 0.33, overhead (%): 128, heavy eviction counter: 14, current caching DataBlock (%): 19
evicted (MB): 342, ratio 0.33, overhead (%): 71, heavy eviction counter: 15, current caching DataBlock (%): 19
evicted (MB): 342, ratio 0.32, overhead (%): 71, heavy eviction counter: 16, current caching DataBlock (%): 19
evicted (MB): 342, ratio 0.31, overhead (%): 71, heavy eviction counter: 17, current caching DataBlock (%): 19
evicted (MB): 228, ratio 0.3, overhead (%): 14, heavy eviction counter: 18, current caching DataBlock (%): 19
evicted (MB): 228, ratio 0.29, overhead (%): 14, heavy eviction counter: 19, current caching DataBlock (%): 19
evicted (MB): 228, ratio 0.27, overhead (%): 14, heavy eviction counter: 20, current caching DataBlock (%): 19
evicted (MB): 228, ratio 0.25, overhead (%): 14, heavy eviction counter: 21, current caching DataBlock (%): 19
evicted (MB): 228, ratio 0.24, overhead (%): 14, heavy eviction counter: 22, current caching DataBlock (%): 19
evicted (MB): 228, ratio 0.22, overhead (%): 14, heavy eviction counter: 23, current caching DataBlock (%): 19
evicted (MB): 228, ratio 0.21, overhead (%): 14, heavy eviction counter: 24, current caching DataBlock (%): 19
evicted (MB): 228, ratio 0.2, overhead (%): 14, heavy eviction counter: 25, current caching DataBlock (%): 19
evicted (MB): 228, ratio 0.17, overhead (%): 14, heavy eviction counter: 26, current caching DataBlock (%): 19
evicted (MB): 456, ratio 0.17, overhead (%): 128, heavy eviction counter: 27, current caching DataBlock (%): 18 < added gets (but table the same)
evicted (MB): 456, ratio 0.15, overhead (%): 128, heavy eviction counter: 28, current caching DataBlock (%): 17
evicted (MB): 342, ratio 0.13, overhead (%): 71, heavy eviction counter: 29, current caching DataBlock (%): 17
evicted (MB): 342, ratio 0.11, overhead (%): 71, heavy eviction counter: 30, current caching DataBlock (%): 17
evicted (MB): 342, ratio 0.09, overhead (%): 71, heavy eviction counter: 31, current caching DataBlock (%): 17
evicted (MB): 228, ratio 0.08, overhead (%): 14, heavy eviction counter: 32, current caching DataBlock (%): 17
evicted (MB): 228, ratio 0.07, overhead (%): 14, heavy eviction counter: 33, current caching DataBlock (%): 17
evicted (MB): 228, ratio 0.06, overhead (%): 14, heavy eviction counter: 34, current caching DataBlock (%): 17
evicted (MB): 228, ratio 0.05, overhead (%): 14, heavy eviction counter: 35, current caching DataBlock (%): 17
evicted (MB): 228, ratio 0.05, overhead (%): 14, heavy eviction counter: 36, current caching DataBlock (%): 17
evicted (MB): 228, ratio 0.04, overhead (%): 14, heavy eviction counter: 37, current caching DataBlock (%): 17
evicted (MB): 109, ratio 0.04, overhead (%): -46, heavy eviction counter: 37, current caching DataBlock (%): 22 < back pressure
evicted (MB): 798, ratio 0.24, overhead (%): 299, heavy eviction counter: 38, current caching DataBlock (%): 20
evicted (MB): 798, ratio 0.29, overhead (%): 299, heavy eviction counter: 39, current caching DataBlock (%): 18
evicted (MB): 570, ratio 0.27, overhead (%): 185, heavy eviction counter: 40, current caching DataBlock (%): 17
evicted (MB): 456, ratio 0.22, overhead (%): 128, heavy eviction counter: 41, current caching DataBlock (%): 16
evicted (MB): 342, ratio 0.16, overhead (%): 71, heavy eviction counter: 42, current caching DataBlock (%): 16
evicted (MB): 342, ratio 0.11, overhead (%): 71, heavy eviction counter: 43, current caching DataBlock (%): 16
evicted (MB): 228, ratio 0.09, overhead (%): 14, heavy eviction counter: 44, current caching DataBlock (%): 16
evicted (MB): 228, ratio 0.07, overhead (%): 14, heavy eviction counter: 45, current caching DataBlock (%): 16
evicted (MB): 228, ratio 0.05, overhead (%): 14, heavy eviction counter: 46, current caching DataBlock (%): 16
evicted (MB): 222, ratio 0.04, overhead (%): 11, heavy eviction counter: 47, current caching DataBlock (%): 16
evicted (MB): 104, ratio 0.03, overhead (%): -48, heavy eviction counter: 47, current caching DataBlock (%): 21 < interrupt gets
evicted (MB): 684, ratio 0.2, overhead (%): 242, heavy eviction counter: 48, current caching DataBlock (%): 19
evicted (MB): 570, ratio 0.23, overhead (%): 185, heavy eviction counter: 49, current caching DataBlock (%): 18
evicted (MB): 342, ratio 0.22, overhead (%): 71, heavy eviction counter: 50, current caching DataBlock (%): 18
evicted (MB): 228, ratio 0.21, overhead (%): 14, heavy eviction counter: 51, current caching DataBlock (%): 18
evicted (MB): 228, ratio 0.2, overhead (%): 14, heavy eviction counter: 52, current caching DataBlock (%): 18
evicted (MB): 228, ratio 0.18, overhead (%): 14, heavy eviction counter: 53, current caching DataBlock (%): 18
evicted (MB): 228, ratio 0.16, overhead (%): 14, heavy eviction counter: 54, current caching DataBlock (%): 18
evicted (MB): 228, ratio 0.14, overhead (%): 14, heavy eviction counter: 55, current caching DataBlock (%): 18
evicted (MB): 112, ratio 0.14, overhead (%): -44, heavy eviction counter: 55, current caching DataBlock (%): 23 < back pressure
evicted (MB): 456, ratio 0.26, overhead (%): 128, heavy eviction counter: 56, current caching DataBlock (%): 22
evicted (MB): 342, ratio 0.31, overhead (%): 71, heavy eviction counter: 57, current caching DataBlock (%): 22
evicted (MB): 342, ratio 0.33, overhead (%): 71, heavy eviction counter: 58, current caching DataBlock (%): 22
evicted (MB): 342, ratio 0.33, overhead (%): 71, heavy eviction counter: 59, current caching DataBlock (%): 22
evicted (MB): 342, ratio 0.33, overhead (%): 71, heavy eviction counter: 60, current caching DataBlock (%): 22
evicted (MB): 342, ratio 0.33, overhead (%): 71, heavy eviction counter: 61, current caching DataBlock (%): 22
evicted (MB): 342, ratio 0.33, overhead (%): 71, heavy eviction counter: 62, current caching DataBlock (%): 22
evicted (MB): 342, ratio 0.33, overhead (%): 71, heavy eviction counter: 63, current caching DataBlock (%): 22
evicted (MB): 342, ratio 0.32, overhead (%): 71, heavy eviction counter: 64, current caching DataBlock (%): 22
evicted (MB): 342, ratio 0.33, overhead (%): 71, heavy eviction counter: 65, current caching DataBlock (%): 22
evicted (MB): 342, ratio 0.33, overhead (%): 71, heavy eviction counter: 66, current caching DataBlock (%): 22
evicted (MB): 342, ratio 0.32, overhead (%): 71, heavy eviction counter: 67, current caching DataBlock (%): 22
evicted (MB): 342, ratio 0.33, overhead (%): 71, heavy eviction counter: 68, current caching DataBlock (%): 22
evicted (MB): 342, ratio 0.32, overhead (%): 71, heavy eviction counter: 69, current caching DataBlock (%): 22
evicted (MB): 342, ratio 0.32, overhead (%): 71, heavy eviction counter: 70, current caching DataBlock (%): 22
evicted (MB): 342, ratio 0.33, overhead (%): 71, heavy eviction counter: 71, current caching DataBlock (%): 22
evicted (MB): 342, ratio 0.33, overhead (%): 71, heavy eviction counter: 72, current caching DataBlock (%): 22
evicted (MB): 342, ratio 0.33, overhead (%): 71, heavy eviction counter: 73, current caching DataBlock (%): 22
evicted (MB): 342, ratio 0.33, overhead (%): 71, heavy eviction counter: 74, current caching DataBlock (%): 22
evicted (MB): 342, ratio 0.33, overhead (%): 71, heavy eviction counter: 75, current caching DataBlock (%): 22
evicted (MB): 342, ratio 0.33, overhead (%): 71, heavy eviction counter: 76, current caching DataBlock (%): 22
evicted (MB): 21, ratio 0.33, overhead (%): -90, heavy eviction counter: 76, current caching DataBlock (%): 32
evicted (MB): 0, ratio 0.0, overhead (%): -100, heavy eviction counter: 0, current caching DataBlock (%): 100
evicted (MB): 0, ratio 0.0, overhead (%): -100, heavy eviction counter: 0, current caching DataBlock (%): 100
Сканы нужны были для того, чтобы показать этот же процесс в виде графика соотношения между двумя разделами кеша — single (куда попадают блоки которые еще никто ни разу не запрашивал) и multi (тут хранятся «востребованные» хотя бы раз данные):
Ну и наконец как выглядит работа параметров в виде графика. Для сравнения кеш был совсем выключен в начале, затем был запуск HBase с кешированием и отсрочкой начала работы оптимизации на 5 минут (30 циклов выселения).
Полный код можно найти в Pull Request на github.
Однако 300 тыс. чтений в секунду это не все, что можно выжать на данном железе в этих условиях. Дело в том, что когда нужно обратиться к данным через HDFS, то используется механизм ShortCircuitCache (далее SSC), который позволяет получить доступ к данным напрямую, избегая сетевых взаимодействий.
Профилировка показала, что этот механизм хоть и дает большой выигрыш, но сам также в какой-то момент становится узким горлышком, потому что практически все тяжелые операции происходят внутри lock, что приводит к блокировкам большую часть времени.

Осознав это мы поняли, что проблему можно обойти, если создать массив независимых SSC:
private final ShortCircuitCache[] shortCircuitCache;
...
shortCircuitCache = new ShortCircuitCache[this.clientShortCircuitNum];
for (int i = 0; i < this.clientShortCircuitNum; i++)
this.shortCircuitCache[i] = new ShortCircuitCache(…);
И далее работать с ними, исключая пересечения так же по последней цифре оффсета:
public ShortCircuitCache getShortCircuitCache(long idx) {
return shortCircuitCache[(int) (idx % clientShortCircuitNum)];
}
Теперь можно приступать к тестам. Для этого будем читать файлы из HDFS простым многопоточным приложением. Выставляем параметры:
conf.set("dfs.client.read.shortcircuit", "true");
conf.set("dfs.client.read.shortcircuit.buffer.size", "65536"); // по дефолту = 1 МБ и это сильно замедляет чтение, поэтому лучше привести в соответствие к реальным нуждам
conf.set("dfs.client.short.circuit.num", num); // от 1 до 10
И просто читаем файлы:
FSDataInputStream in = fileSystem.open(path);
for (int i = 0; i < count; i++) {
position += 65536;
if (position > 900000000)
position = 0L;
int res = in.read(position, byteBuffer, 0, 65536);
}
Этот код выполняется в отдельных потоках и мы будем наращивать количество одновременно читаемых файлов (от 10 до 200 — горизонтальная ось) и количество кэшей (от 1 до 10 — графики). Вертикальная оси показывает ускорение которое дает увеличение SSC относительно случая когда кеш только один.
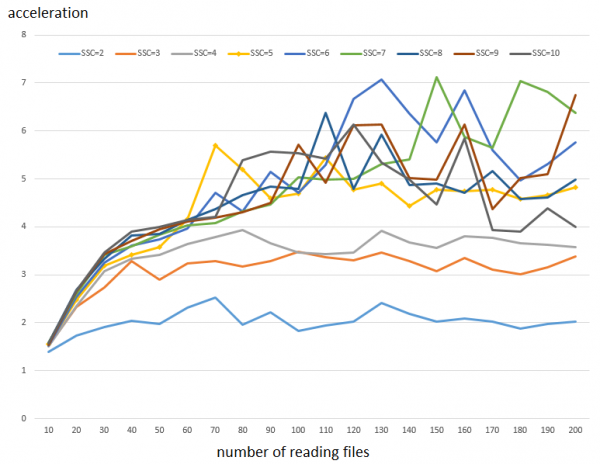
Как читать график: время выполнения 100 тысяч чтений блоками по 64 КБ с одним кэшом требует 78 секунд. Тогда как с 5 кэшами это выполняется за 16 секунд. Т.е. имеет место ускорение ~5 раз. Как видно из графика, на маленьком числе параллельных чтений эффект не очень заметный, это начинает играть заметную роль когда чтения потоков больше 50. Также заметно, что увеличение количества SSC от 6 и выше дает существенно меньше прироста производительности.
Примечание 1: так как результаты тестирования достаточно волатильны (см. ниже), было осуществлено 3 запуска и полученные значения были усреднены.
Примечание 2: Прирост производительности от настройки для случайного доступа такой же, хотя сам доступ чуть медленнее.
Однако необходимо уточнить, что в отличие от случая с HBase это ускорение не всегда бесплатное. Тут мы больше «разблокируем» возможности CPU делать работу, вместо того чтобы отвисать на локах.
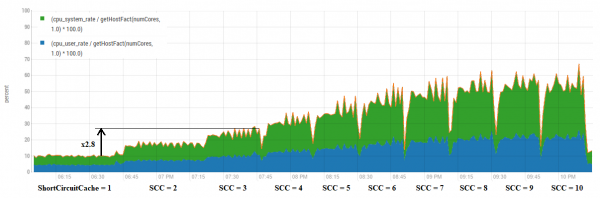
Тут можно наблюдать, что в целом увеличение количества кэшей дает примерно пропорциональный рост утилизации ЦПУ. Однако есть несколько более выигрышные комбинации.
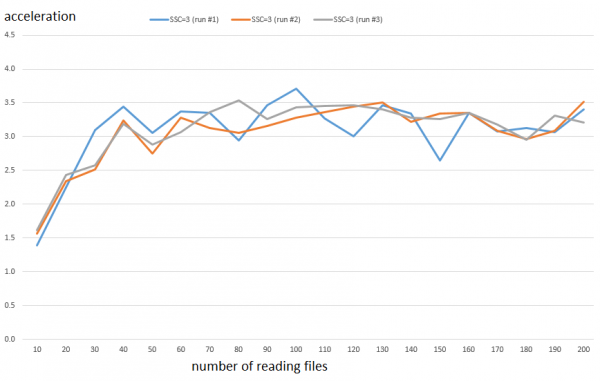
Например присмотримся внимательнее к настройке SSC = 3. Рост производительности на диапазоне составляет около 3.3 раз. Ниже результаты всех трех отдельных запусков.
Тогда как потребление CPU растет примерно в 2.8 раз. Разница не очень большая, но маленькой Грете уже радость и возможно появится время для посещения школы и уроков.
Таким образом это будет иметь позитивный эффект для любого инструмента использующего массовый доступ к HDFS (например Spark и т.д.), при условии что прикладной код легкий (т.е. затык именно на стороне клиента HDFS) и есть свободные мощности CPU. Для проверки давайте протестируем какой эффект даст совместное применение оптимизации BlockCache и тюнинга SSC для чтения из HBase.
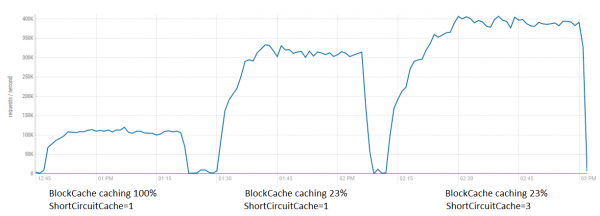
Тут видно, что в таких условиях эффект не такой большой, как в рафинированных тестах (чтение без всякой обработки), однако выжать дополнительные 80К тут вполне себе получается. Совместно обе оптимизации дают ускорение до 4х раз.
Так же по этой оптимизации был сделан PR , который был вмержен и данный функционал будет доступен в следующих релизах.
Ну и наконец было интересно сравнить производительность чтения подобной wide-column БД Cassandra и HBase.
Для этого запускались экземпляры стандартной утилиты нагрузочного тестирования YCSB с двух хостов (800 threads суммарно). На серверной стороне — по 4 экземпляра RegionServer и Cassandra на 4 хостах (не тех, где запущены клиенты, чтобы избежать их влияния). Чтения шли из таблиц размером:
HBase — 300 GB on HDFS (100 GB чистых данных)
Cassandra — 250 GB (replication factor = 3)
Т.е. объем был примерно одинаковый (в HBase немножко больше).
Параметры HBase:
dfs.client.short.circuit.num = 5 (оптимизация клиента HDFS)
hbase.lru.cache.heavy.eviction.count.limit = 30 — это означает то патч начнет работать через 30 выселений (~5 минут)
hbase.lru.cache.heavy.eviction.mb.size.limit = 300 — целевой объем кеширования и выселения
Логи YCSB были распарсены и сведены в графики Excel:
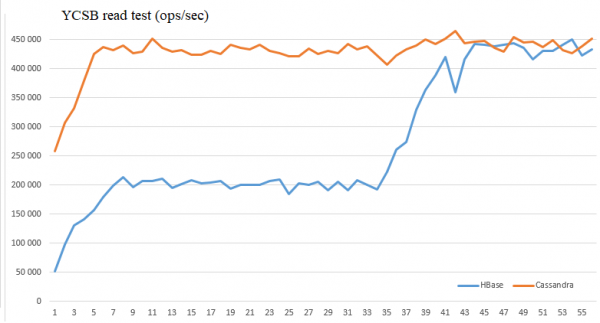
Как видно, данные оптимизации позволяют сравнять производительность этих БД в этих условиях и достигнуть 450 тыс. чтений в секунду.
Надеемся эта информация может быть кому-нибудь полезной в ходе увлекательной борьбы за производительность.
Источник: habr.com
