

В последнее время на Хабре стали чаще появляться посты о том, как хорош Telegram, как гениальны и опытны братья Дуровы в построении сетевых систем, и т.п. В то же время, очень мало кто действительно погружался в техническое устройство — как максимум, используют достаточно простой (и весьма отличающийся от MTProto) Bot API на базе JSON, а обычно просто принимают на веру все те дифирамбы и пиар, что крутятся вокруг мессенджера. Почти полтора года назад мой коллега по НПО «Эшелон» Василий (к сожалению, его учетку на Хабре стёрли вместе с черновиком) начал писать свой собственный клиент Telegram с нуля на Perl, позже присоединился и автор этих строк. Почему на Perl, немедленно спросят некоторые? Потому что на других языках такие проекты уже есть На самом деле, суть не в этом, мог быть любой другой язык, где еще нет готовой библиотеки, и соответственно автор должен пройти весь путь с нуля. Тем более, криптография дело такое — доверяй, но проверяй. С продуктом, нацеленным на безопасность, вы не можете просто взять и положиться на готовую библиотеку от производителя, слепо ему поверив (впрочем, это тема более для второй части). На данный момент библиотека вполне работает на «среднем» уровне (позволяет делать любые API-запросы).
Тем не менее, в данной серии постов будет не так много криптографии и математики. Зато будет много других технических подробностей и архитектурных костылей (пригодится и тем, кто не будет писать с нуля, а будет пользоваться библиотекой на любом языке). Итак, главной целью было — попытаться реализовать клиент с нуля по официальной документации. То есть, предположим, что исходный код официальных клиентов закрыт (опять же во второй части подробнее раскроем тему того, что это и правда бывает так), но, как в старые времена, например, есть стандарт по типу RFC — возможно ли написать клиент по одной лишь спецификации, «не подглядывая» в исходники, хоть официальных (Telegram Desktop, мобильных), хоть неофициальных Telethon?
Оглавление:
Документация… она ведь есть? Правда?..
Фрагменты заметок для этой статьи начали собираться еще прошлым летом. Всё это время на официальном сайте документация была по состоянию на Layer 23, т.е. застряв где-то в 2014 году (помните, тогда даже каналов еще не было?). Конечно, по идее, это должно было позволять реализовать клиент с функциональностью на тот момент 2014 года. Но и в таком состоянии документация была, во-первых, неполна, во-вторых, местами противоречила сама себе. Чуть более месяца назад, в сентябре 2019, было случайно обнаружено, что на сайте большое обновление документации, на вполне свежий Layer 105, с пометкой, что теперь всю надо читать заново. Действительно, многие статьи были переработаны, но многие — так и остались без изменений. Поэтому, читая критику ниже по поводу документации, следует иметь в виду, что некоторые из этих вещей уже неактуальны, но некоторые — всё еще вполне. В конце концов, 5 лет в современном мире — это не просто много, а очень много. С тех времен (особенно если не учитывать выброшенные и заново возрожденные с тех пор геочаты) число API-методов в схеме выросло с сотни до более чем двухсот пятидесяти!
С чего начать молодому автору?
Неважно, пишете ли Вы с нуля или используете например готовые библиотеки типа или , в любом случае Вам потребуется сначала зарегистрировать своё приложение — api_id и api_hash (работавшие с API ВКонтакте сразу понимают), по которым сервер будет идентифицировать приложение. Это придется сделать и по юридическим соображениям, но подробнее о том, почему авторы библиотек не могут его публиковать, поговорим во второй части. Возможно, вас удовлетворят тестовые значения, хотя они сильно ограничены — дело в том, что сейчас на свой номер можно зарегистрировать только одно приложение, так что не кидайтесь сразу очертя голову.
Сейчас же нас, с технической точки зрения, должно было интересовать то, что после регистрации нам должны приходить от Telegram уведомления об обновлениях документации, протокола, и т.д. То есть можно было бы предположить, что на сайт с доками просто «забили» и продолжили работать конкретно с теми, кто стал делать клиенты, т.к. так проще. Но нет, ничего такого не наблюдалось, никакой информации не приходило.
И если писать с нуля, то до использования полученных параметров на самом деле еще далеко. Хотя и говорит в Getting Started о них первым делом, на самом деле сначала придется реализовать — но если Вы поверили в конце страницы общего описания протокола, то совершенно зря.
На самом деле, и до MTProto, и после, на нескольких уровнях сразу (как говорят зарубежные работающие в ядре ОС сетевики, layer violation) на пути встанет большая, больная и ужасная тема…
Бинарная сериализация: TL (Type Language) и его схема, и слои, и много других страшных слов
Эта тема, собственно, в проблемах Telegram — ключевая. И страшных слов, если Вы попытаетесь в неё вникнуть, будет много.
Итак, схема. Если на это слово Вам вспомнилась, скажем, , Вы подумали правильно. Цель та же: некоторый язык для описания возможного набора передаваемых данных. На этом, собственно, сходство и заканчивается. Если со страницы , или из дерева исходных текстов официального клиента, мы попытаемся открыть какую-нибудь схему, то увидим нечто вроде:
int ? = Int;
long ? = Long;
double ? = Double;
string ? = String;
vector#1cb5c415 {t:Type} # [ t ] = Vector t;
rpc_error#2144ca19 error_code:int error_message:string = RpcError;
rpc_answer_unknown#5e2ad36e = RpcDropAnswer;
rpc_answer_dropped_running#cd78e586 = RpcDropAnswer;
rpc_answer_dropped#a43ad8b7 msg_id:long seq_no:int bytes:int = RpcDropAnswer;
msg_container#73f1f8dc messages:vector<%Message> = MessageContainer;
---functions---
set_client_DH_params#f5045f1f nonce:int128 server_nonce:int128 encrypted_data:bytes = Set_client_DH_params_answer;
ping#7abe77ec ping_id:long = Pong;
ping_delay_disconnect#f3427b8c ping_id:long disconnect_delay:int = Pong;
invokeAfterMsg#cb9f372d msg_id:long query:!X = X;
invokeAfterMsgs#3dc4b4f0 msg_ids:Vector<long> query:!X = X;
account.updateProfile#78515775 flags:# first_name:flags.0?string last_name:flags.1?string about:flags.2?string = User;
account.sendChangePhoneCode#8e57deb flags:# allow_flashcall:flags.0?true phone_number:string current_number:flags.0?Bool = auth.SentCode;Человек, видящий это впервые, интуитивно сможет распознать только часть написанного — ну, это видимо структуры (хотя где имя, слева или справа?), вот есть поля в них, после которых через двоеточие идёт тип… наверное. Вот в угловых скобках наверное шаблоны как в Си++ (на самом деле, не совсем). А что значат все остальные символы, знаки вопроса, восклицательные, проценты, решетки (причем явно ведь в разных местах значат разное), где-то присутствующие, а где-то нет, шестнадцатиричные циферки — и самое главное, как из этого получить правильный (который не будет отвергнут сервером) поток байт? Придется читать документацию (да, там рядом бывают ссылки на схему в JSON-версии — но понятнее от этого не становится).
Открываем страницу и погружаемся в волшебный мир грибов и дискретной математики нечто похожее на матан на 4 курсе. Алфавит, тип, значение, комбинатор, функциональный комбинатор, нормальная форма, композитный тип, полиморфный тип… и всё это только первая страница! Дальше Вас ожидает , который хоть уже и содержит пример тривиального запроса и ответа, совершенно не дает ответа на более типичные случаи, а значит, придется продираться через пересказ математики в переводе с русского на английский еще на восьми вложенных страницах!
Читатели, знакомые с функциональными языками и автоматическим выводом типов, разумеется, увидели в этом языке описания, даже из примера, гораздо больше знакомого, и могут сказать, что это вообще-то в принципе неплохо. Возражения на это таковы:
- да, цель звучит хорошо, но увы, она не достигается
- образование в ВУЗах России варьирует даже среди IT-шных специальностей — соответствующий курс читали не всем
- наконец, как мы увидим, на практике это не требуется, поскольку используется лишь ограниченное подмножество даже того TL, что был описан
Как сказал на канале #perl в IRC-сети FreeNode, пытавшийся реализовать гейт из Telegram в Matrix (перевод цитаты неточный по памяти):
Такое чувство, что кто-то впервые познакомился с теорией типов, пришел в восторг и начал пытаться играться с этим, не особенно заботясь, нужно ли это на практике.
Смотрите сами, если необходимость bare-типов (int, long и т.д.) как чего-то элементарного вопросов не вызывают — в конечном счете их надо реализовать вручную — для примера возьмем попытку вывести из них вектор. То есть, на самом деле, массив, если называть получившиеся вещи своими именами.
Но прежде
Краткое описание подмножества синтаксиса TL для тех, кто не… ет читать официальную документацию
constructor = Type;
myVec ids:Vector<long> = Type;
fixed#abcdef34 id:int = Type2;
fixedVec set:Vector<Type2> = FixedVec;
constructorOne#crc32 field1:int = PolymorType;
constructorTwo#2crc32 field_a:long field_b:Type3 field_c:int = PolymorType;
constructorThree#deadcrc bit_flags_of_what_really_present:# optional_field4:bit_flags_of_what_really_present.1?Type = PolymorType;
an_id#12abcd34 id:int = Type3;
a_null#6789cdef = Type3;Начинает определение всегда конструктор, после которого опционально (на практике — всегда) через символ # следует CRC32 от нормализованной строки описания данного типа. Дальше идет описание полей, если они есть — тип может быть и пустым. Заканчивает это всё через знак равенства имя типа, которому данный конструктор — то есть, фактически, подтип — принадлежит. Тот тип, что справа от знака равенства, он полиморфный — то есть ему может соответствовать несколько конкретных типов.
Если же определение встретилось после строки ---functions---, то синтаксис останется таким же, но смысл будет уже другой: конструктор станет именем RPC-функции, поля — параметрами (ну то есть он останется точно такой же структурой данной, как описано ниже, просто таков будет наделяемый смысл), а «полиморфный тип» — типом возвращаемого результата. Он, правда, всё равно останется полиморфным — просто определенным в секции ---types---, а этот вот конструктор будет «не считаться». Перегрузки типов вызываемых функций по их аргументам, т.е. несколько функций с одним и тем же именем, но разной сигнатурой, как в C++, в TL почему-то не предусмотрено.
Почему «конструктор» и «полиморфный», если это не ООП? Ну, на самом деле, кому-то будет проще будет думать об этом именно в терминах ООП — полиморфный тип как абстрактный класс, а конструкторы — это его прямые классы-наследники, причем final в терминологии ряда языков. На самом деле, конечно, здесь лишь похожесть с реальными перегруженными методами конструкторов в ОО-языках программирования. Поскольку тут — всего лишь структуры данных, никаких методов нет (хотя описание функций и методов далее вполне способно создать путаницу в голове, что они есть, но то речь о другом) — то можно думать о конструкторе как о значении, из которого конструируется тип при чтении потока байт.
Как это происходит? Десериализатор, который всегда читает по 4 байта, видит значение 0xcrc32 — и понимает, что дальше будет field1 с типом int, т.е. читает ровно 4 байта, на этом вышележащее поле с типом PolymorType прочитано. Видит 0x2crc32 и понимает, что дальше два поля, сначала long, значит читаем 8 байт. А дальше опять сложный тип, который десериализуется аналогично. Например, Type3 мог быть объявлен в схеме как только два конструктора, соответственно, дальше должны встретиться либо 0x12abcd34, после которого надо прочитать еще 4 байта int, либо 0x6789cdef, после которого не будет ничего. Чтоугодно другое — надо выкинуть исключение. В любом случае после этого мы возвращаемся к чтению 4 байт int поля field_c в constructorTwo и на том заканчиваем читать наш PolymorType.
Наконец, если попался 0xdeadcrc для constructorThree, то всё становится сложнее. Первым у нас поле bit_flags_of_what_really_present с типом # — на самом деле, это всего лишь алиас для типа nat, означающего «натуральное число». То есть, по сути, unsigned int — единственный, кстати, случай, когда в реальных схемах встречаются беззнаковые числа. Итак, дальше конструкция со знаком вопроса, означающая, что вот это поле — оно будет присутствовать on the wire, только если установлен соответствующий бит в поле, на которое сослались (примерно как тернарный оператор). Итак, предположим, что этот бит стоял, значит, дальше надо читать поле типа Type, у которого в нашем примере 2 конструктора. Один пустой (состоит только из идентификатора), в другом есть поле ids с типом ids:Vector<long>.
Вы можете подумать, что как шаблоны и generic’и в плюсах или Java. Но нет. Ну, почти. Это единственный случай применения угловых скобок в реальных схемах, и он используется ТОЛЬКО для Vector. В потоке байт это будут 4 байт CRC32 для самого типа Vector, всегда одинаковые, потом 4 байта — число элементов массива, и дальше сами эти элементы.
Добавьте к этому то, что сериализация всегда происходит словами по 4 байта, все типы ей кратны — к встроенным типам описаны еще bytes и string с ручной сериализацией длины и этого выравнивания по 4 — ну, вроде бы звучит нормально и даже сравнительно эффективно? Хотя TL заявляется как эффективная бинарная сериализация, но хрен уж с ними, с расширением чего попало, даже булевых значений и односимвольных строк до 4 байт, всё равно JSON будет куда толще? Вон, даже ненужные поля могут быть пропущены битовыми флагами, всё совсем хорошо, и даже расширяемо на будущее, взял да и досыпал новых опциональных полей в конструктор потом?..
А вот нет, если читать не моё краткое описание, а полную документацию, и подумать над реализацией. Во-первых, CRC32 конструктора считается по нормализованной строке текстового описания схемы (убрать лишние whitespace и т.д.) — так что если добавляется новое поле, изменится строка описания типа, а значит и её CRC32 и, следовательно, сериализация. Да и что старый клиент делал бы, если бы ему пришло поле с новыми установленными флагами, а он не знает, что с ними делать дальше?..
Во-вторых, вспомним о CRC32, которая применяется здесь по сути в качестве хэш-функции для уникального определения, что за тип (де)сериализуется. Тут мы сталкиваемся с проблемой коллизий — и нет, вероятность не единица на 232, а значительно больше. Кто вспомнил о том, что CRC32 заточена на обнаружение (и исправление) ошибок в канале связи, и соответственно улучшает эти свойства в ущерб другим? Например, ей плевать на перестановку байт: если Вы посчитаете CRC32 от двух строк, во второй первые 4 байта поменяете местами со следующими 4 байтами — она будет одинакова. Когда у нас на входе текстовые строки из латинского алфавита (и немного пунктуации), и имена эти не особо случайны, вероятность такой перестановки здорово повышается.
Кстати, а кто проверял, что там действительно CRC32? В одном из ранних исходников (еще до Вальтмана) была хэш-функция, умножавшая каждый символ на так любимое этими людьми число 239, ха-ха!
Наконец, ладно, мы поняли, что конструкторы с типом поля Vector<int> и Vector<PolymorType> будут иметь разный CRC32. А что насчет представления на линии? И с точки зрения теории, становится ли это частью типа? Допустим, мы передаем массив из десяти тысяч чисел, ну с Vector<int> всё понятно, длина и еще 40000 байт. А если это Vector<Type2>, который состоит только из одного поля int и он один в типе — надо ли нам 10000 раз повторять 0xabcdef34 и затем 4 байта int, или же язык в состоянии ВЫВЕСТИ это за нас из конструктора fixedVec и вместо 80000 байт передать опять только 40000 ?
Это совсем не праздный теоретический вопрос — представьте, Вы получаете список пользователей группы, каждый из которых имеет id, имя, фамилию — разница в объеме передаваемых данных по мобильному соединению может быть значительной. Именно эффективность сериализации Telegram нам и рекламируют.
Итак…
Vector, который так и не смогли вывести
Если Вы попытаетесь продраться через страницы описания комбинаторов и около, Вы увидите, что вектор (и даже матрицу) формально пытаются вывести через tuples несколько листов. Но в конечном итоге забивают, конечный шаг пропускается, и просто дается определение вектора, который еще и не привязан к типу. В чем тут дело? В языках программирования, особенно функциональных, вполне типично описать структуру рекурсивно — компилятор с его lazy evaluation сам всё поймёт и сделает. В языке сериализации данных же необходима ЭФФЕКТИВНОСТЬ: достаточно просто описать список, т.е. структуру из двух элементов — первым элемент данных, вторым — саму эту же структуру либо пустое место для хвоста (пачка (cons) в Lisp). Но это, очевидно, потребует для каждого элемента дополнительно тратить 4 байта (CRC32 в случае в TL) на описание его типа. Легко можно описать и массив фиксированного размера, но вот в случае массива заранее неизвестной длины — обламываемся.
Поэтому, поскольку TL не позволяет вывести вектор, его пришлось добавить сбоку. В конечном итоге документация сообщает:
Serialization always uses the same constructor “vector” (const 0x1cb5c415 = crc32(«vector t:Type # [ t ] = Vector t”) that is not dependent on the specific value of the variable of type t.
The value of the optional parameter t is not involved in the serialization since it is derived from the result type (always known prior to deserialization).
Присмотритесь: vector {t:Type} # [ t ] = Vector t — но нигде в самом этом определении не сказано, что первое число должно быть равным длине вектора! И ниоткуда это не следует. Это данность, которую нужно держать в голове и реализовывать руками. В других местах документация даже честно упоминает, что тип ненастоящий:
The Vector t polymorphic pseudotype is a “type” whose value is a sequence of values of any type t, either boxed or bare.
… но не акцентирует на этом внимание. Когда Вы, устав продираться через натягивание математики (может быть даже известной Вам из университетского курса), решаете забить и смотреть уже собственно как с этим работать на практике, в голове осталось впечатление: тут Серьезная Математика в основе, придумывали явно Крутые Люди (два математика-призера ACM), а не кто попало. Цель — пустить пыль в глаза — достигнута.
Кстати, о числе. Напомним,
#это синонимnat, натурального числа:There are type expressions (type-expr) and numeric expressions (nat-expr). However, they are defined the same way.
type-expr ::= expr nat-expr ::= exprно в грамматике они описаны одинаково, т.е. эту разницу опять надо помнить и закладывать в реализацию руками.
Ну и да, шаблонные типы (vector<int>, vector<User>) имеют общий идентификатор (#1cb5c415), т.е. если знаешь, что вызов объявлен как
users.getUsers#d91a548 id:Vector<InputUser> = Vector<User>;то ждёшь уже не просто вектор, а вектор юзеров. Точнее, должен ждать — в реальном коде каждый элемент, если не bare-тип, будет иметь конструктор, и по-хорошему в имплементации надо бы проверять — а нам точно в каждом элементе этого вектора прислали того типа? А если это был какой-нибудь PHP, у которого в массиве могут лежать разные типа в разных элементах?
На этом месте начинаешь задумываться — а нужен ли такой TL? Может, для телеги можно было бы и человеческий сериализатор использовать, тот же protobuf, уже тогда существовавший? Это была теория, давайте посмотрим на практику.
Существующие реализации TL в коде
TL родился в недрах ВКонтакте еще до известных событий с продажей доли Дурова и (наверное), еще до начала разработки Telegram. И в выложенных в опенсорс можно найти много весёлых костылей. Да и сам язык там был реализован более полно, чем сейчас в Telegram. Например, хэши в схеме не используются совсем (имеется в виду встроенный псевдотип (как вектор) с девиантным поведением). Или
Templates are not used now. Instead, the same universal constructors (for example, vector {t:Type} [t] = Vector t) are used wно рассмотрим для полноты картины, чтобы проследить, так сказать, эволюцию Гиганта Мысли.
#define ZHUKOV_BYTES_HACK
#ifdef ZHUKOV_BYTES_HACK
/* dirty hack for Zhukov request */Или вот, прекрасное:
static const char *reserved_words_polymorhic[] = {
"alpha", "beta", "gamma", "delta", "epsilon", "zeta", "eta", "theta", NULL
};Этот фрагмент — про шаблоны, вида:
intHash {alpha:Type} vector<coupleInt<alpha>> = IntHash<alpha>;Это определение шаблонного типа хэшмэп, как вектора пар int — Type. В C++ это выглядело бы примерно так:
template <T> class IntHash {
vector<pair<int,T>> _map;
}так вот, alpha — ключевое слово! Но только в C++ ты можешь писать T, а должен писать alpha, beta… Но не Больше 8 параметров, на тэте фантазия кончилась. Так и представляется, что когда-то в Питере случились примерно такие диалоги:
-- Надо сделать в TL шаблоны
-- Бл... Ну пусть параметры зовут альфа, бета,... Какие там ещё буквы есть... О, тэта!
-- Грамматика? Ну потом напишем
-- Смотрите, какой я синтаксис придумал для шаблонов и вектора!
-- Ты долбанулся, как мы это парсить будем?
-- Да не ссыте, он там один в схеме, захаркодить -- и окНо это было про первую выложенную реализацию TL «вообще». Перейдём к рассмотрению реализаций в собственно Telegram-клиентах.
Слово Василию:
Vasily, [09.10.18 17:07]
Больше всего жопа раскаляется от того, что они навертели кучу абстракций, а потом забили на них болт, и обложили кодогегератор костылями
В результате, сначала от доки лётчик.jpg
Потом от кода джекичан.webp
Конечно, от знакомых с алгоритмами и математикой людей мы можем ожидать, что они читали Ахо, Ульмана, и знакомы со ставшими за десятилетия стандартом де-факто в отрасли инструментами для написания компиляторов своих DSL, правда?..
Автором является Виталий Вальтман, как можно понять по встречаемости формата TLO за его (cli) пределами, член команды — сейчас библиотека для парсинга TL выделена , какое складывается впечатление о её ?..
16.12 04:18 Vasily: по-моему, кто-то не осилил lex+yacc
16.12 04:18 Vasily: иначе я не могу объяснить это
16.12 04:18 Vasily: ну или им за количество строк в вк платили
16.12 04:19 Vasily: 3к+ строк др<censored>вместо парсера
Может, исключение? Давайте посмотрим, как это ОФИЦИАЛЬНЫЙ клиент — Telegram Desktop:
nametype = re.match(r'([a-zA-Z.0-9_]+)(#[0-9a-f]+)?([^=]*)=s*([a-zA-Z.<>0-9_]+);', line);
if (not nametype):
if (not re.match(r'vector#1cb5c415 {t:Type} # [ t ] = Vector t;', line)):
print('Bad line found: ' + line);1100+ строк на Питоне, пара регулярок + особые случаи типа вектора, который, конечно, объявлен в схеме как полагается по синтаксису TL, но клали они на этот синтаксис, парсить его еще… Спрашивается, зачем было городить всё это чудище слоёное, если всё равно никто не собирается это парсить по документации?!
Кстати… Помните, мы говорили о проверке CRC32? Так вот, в кодогенераторе Telegram Desktop есть список исключений для тех типов, в которых рассчитанный CRC32 не совпадает с указанным в схеме!
Vasily, [18.12 22:49]
и тут бы задуматься, а нужен ли такой TL
если бы я хотел подгадить альтернативным реализациям, я бы начал переносы строк вставлять, половина парсеров сломается на многострочных определениях
tdesktop, впрочем, тоже
Запомните момент об однострочности, мы к нему вернемся чуть позже.
Ладно, telegram-cli — неофициальный, Telegram Desktop — официальный, но что насчет других? А кто знает?.. В коде Android-клиента вообще не нашлось парсера схемы (что вызывает вопросы к опенсорсности, но это для второй части), зато нашлось несколько других весёлых кусков кода, но о них в подразделе ниже.
Какие еще вопросы на практике поднимает сериализация? Например, наворотили они, конечно, с битовыми полями и условными полями:
Vasily:
flags.0? true
означает, что поле присутствует и равно true, если флаг выставленVasily:
flags.1? int
означает, что поле присутствует, и его надо десериализоватьVasily: Жопа, не гори, что ты делаешь!
Vasily: Там где-то в доке есть упоминание, что true — это голый тип нулевой длины, но из их доки что-то собрать нереально
Vasily: В сорцах открытых реализаций этого тоже нет, зато есть куча костылей и подпорок
А, допустим, Telethon? Забегая вперёд по теме MTProto, пример — в документации есть вот такие куски, но знак % в ней описан только как «соответствующий данному bare-тип», т.е. в примерах ниже или ошибка, или нечто недокументированное:
Vasily, [22.06.18 18:38]
В одном месте:msg_container#73f1f8dc messages:vector message = MessageContainer;В другом:
msg_container#73f1f8dc messages:vector<%Message> = MessageContainer;И это две большие разницы, в реале приходит какой-то голый вектор
Я не видел bare определения вектора и не встречал его
В telethon руками написан разбор
В его схеме закоментировано определение
msg_containerОпять же, остаётся вопрос про %. Оно не описано.
Vadim Goncharov, [22.06.18 19:22]
а в tdesktop?Vasily, [22.06.18 19:23]
Но их парсер TL на регуляиках это тоже скорее всего не съест
// parsed manuallyTL красивая абстракция, никто его не реализует полностью
А % в их версии схемы нет
Но тут документация противоречит сама себе, так что хз
Оно встречалось в грамматике, они могли просто забыть описать семантику
Ты ж видел доку на TL, там без поллитры не разберёшься
«Ну допустим», скажет иной читатель, «что-то вы всё критикуете, так покажите, как надо».
Василий отвечает: «а что касается парсера, мне штуки вида
args: /* empty */ { $$ = NULL; }
| args arg { $$ = g_list_append( $1, $2 ); }
;
arg: LC_ID ':' type-term { $$ = tl_arg_new( $1, $3 ); }
| LC_ID ':' condition '?' type-term { $$ = tl_arg_new_cond( $1, $5, $3 ); free($3); }
| UC_ID ':' type-term { $$ = tl_arg_new( $1, $3 ); }
| type-term { $$ = tl_arg_new( "", $1 ); }
| '[' LC_ID ']' { $$ = tl_arg_new_mult( "", tl_type_new( $2, TYPE_MOD_NONE ) ); }
;как-то больше нравятся, чем
struct tree *parse_args4 (void) {
PARSE_INIT (type_args4);
struct parse so = save_parse ();
PARSE_TRY (parse_optional_arg_def);
if (S) {
tree_add_child (T, S);
} else {
load_parse (so);
}
if (LEX_CHAR ('!')) {
PARSE_ADD (type_exclam);
EXPECT ("!");
}
PARSE_TRY_PES (parse_type_term);
PARSE_OK;
}или
# Regex to match the whole line
match = re.match(r'''
^ # We want to match from the beginning to the end
([w.]+) # The .tl object can contain alpha_name or namespace.alpha_name
(?:
# # After the name, comes the ID of the object
([0-9a-f]+) # The constructor ID is in hexadecimal form
)? # If no constructor ID was given, CRC32 the 'tl' to determine it
(?:s # After that, we want to match its arguments (name:type)
{? # For handling the start of the '{X:Type}' case
w+ # The argument name will always be an alpha-only name
: # Then comes the separator between name:type
[wd<>#.?!]+ # The type is slightly more complex, since it's alphanumeric and it can
# also have Vector<type>, flags:# and flags.0?default, plus :!X as type
}? # For handling the end of the '{X:Type}' case
)* # Match 0 or more arguments
s # Leave a space between the arguments and the equal
=
s # Leave another space between the equal and the result
([wd<>#.?]+) # The result can again be as complex as any argument type
;$ # Finally, the line should always end with ;
''', tl, re.IGNORECASE | re.VERBOSE)это ВЕСЬ лексер:
---functions--- return FUNCTIONS;
---types--- return TYPES;
[a-z][a-zA-Z0-9_]* yylval.string = strdup(yytext); return LC_ID;
[A-Z][a-zA-Z0-9_]* yylval.string = strdup(yytext); return UC_ID;
[0-9]+ yylval.number = atoi(yytext); return NUM;
#[0-9a-fA-F]{1,8} yylval.number = strtol(yytext+1, NULL, 16); return ID_HASH;
n /* skip new line */
[ t]+ /* skip spaces */
//.*$ /* skip comments */
/*.**/ /* skip comments */
. return (int)yytext[0];т.е. попроще — это мягко сказано».
В общем, в итоге парсер и кодогенератор для реально используемого подмножества TL уложился в примерно 100 строк грамматики и ~300 строк генератора (считая и все print‘ы генерируемого кода), включая плюшки типа информацию о типах для интроспекции в каждом классе. Каждый полиморфный тип превращается в пустой абстрактный базовый класс, а конструкторы — наследуются от него и имеют методы для сериализации и десериализации.
Нехватка типов в языке типов
Строгая типизация — это ведь хорошо, правда? Нет, это не холивар (хотя я предпочитаю динамические языки), а постулат в рамках TL. Исходя из него, язык должен обеспечивать всяческие проверки за нас. Ну окей, пусть не он сам, а реализация, но он должен их хотя бы описывать. И какие же возможности мы хотим?
Прежде всего, constraints. Вот мы видим в документации по закачке файлов:
The file’s binary content is then split into parts. All parts must have the same size ( part_size ) and the following conditions must be met:
part_size % 1024 = 0(divisible by 1KB)524288 % part_size = 0(512KB must be evenly divisible by part_size)The last part does not have to satisfy these conditions, provided its size is less than part_size.
Each part should have a sequence number, file_part, with a value ranging from 0 to 2,999.
After the file has been partitioned you need to choose a method for saving it on the server. Use in case the full size of the file is more than 10 MB and for smaller files.
[…] one of the following data input errors may be returned:
- FILE_PARTS_INVALID — Invalid number of parts. The value is not between
1..3000
Что-нибудь из этого присутствует в схеме? Это как-то выразимо средствами TL? Нет. Но позвольте, ведь даже дедовский Turbo Pascal умел описывать типы, задаваемые диапазонами. И еще одну вещь умел, ныне более известную как enum — тип, состоящий из перечисления фиксированного (небольшого) количества значений. В языках типа Си — числовых, заметьте, мы пока говорили только о типах чисел. А ведь есть еще массивы, строки… например, неплохо было бы описать, что вот эта строка может содержать только номер телефона, да?
Ничего из этого в TL нет. Зато есть, например, в JSON Schema. И если про делимость 512 Кб кто-то еще может возразить, что такое всё равно надо проверять в коде, то сделать так, чтобы клиент попросту не мог послать номер вне диапазона 1..3000 (и соответствующей ошибки не могло возникнуть) уж можно было бы, да?..
Кстати, об ошибках и возвращаемых значениях. Глаз замыливается даже у тех, кто поработал с TL — до нас не сразу дошло, что каждая функция в TL на самом деле может вернуть не только описанный тип возврата, но и ошибку. Но это средствами самого TL не выводимо никак. Конечно, оно и так понятно и нафиг не нужно на практике (хотя на самом деле, RPC можно делать по-разному, мы еще вернемся к этому) — но как же Чистота концепций Математики Абстрактных Типов из мира горнего?.. Взялся за гуж — так соответствуй уж.
И в конце концов, что насчет читабельности? Ну, там, вообще хотелось бы description иметь прямо в схеме (в JSON-схеме опять же есть), но если уж с ним напряг, то как насчет практической стороны — хотя бы банально смотреть диффы при обновлениях? Смотрите сами на :
—channelFull#76af5481 flags:# can_view_participants:flags.3?true can_set_username:flags.6?true can_set_stickers:flags.7?true hidden_prehistory:flags.10?true id:int about:string participants_count:flags.0?int admins_count:flags.1?int kicked_count:flags.2?int banned_count:flags.2?int read_inbox_max_id:int read_outbox_max_id:int unread_count:int chat_photo:Photo notify_settings:PeerNotifySettings exported_invite:ExportedChatInvite bot_info:Vector<BotInfo> migrated_from_chat_id:flags.4?int migrated_from_max_id:flags.4?int pinned_msg_id:flags.5?int stickerset:flags.8?StickerSet available_min_id:flags.9?int = ChatFull;
+channelFull#1c87a71a flags:# can_view_participants:flags.3?true can_set_username:flags.6?true can_set_stickers:flags.7?true hidden_prehistory:flags.10?true can_view_stats:flags.12?true id:int about:string participants_count:flags.0?int admins_count:flags.1?int kicked_count:flags.2?int banned_count:flags.2?int online_count:flags.13?int read_inbox_max_id:int read_outbox_max_id:int unread_count:int chat_photo:Photo notify_settings:PeerNotifySettings exported_invite:ExportedChatInvite bot_info:Vector<BotInfo> migrated_from_chat_id:flags.4?int migrated_from_max_id:flags.4?int pinned_msg_id:flags.5?int stickerset:flags.8?StickerSet available_min_id:flags.9?int = ChatFull;
или
—message#44f9b43d flags:# out:flags.1?true mentioned:flags.4?true media_unread:flags.5?true silent:flags.13?true post:flags.14?true id:int from_id:flags.8?int to_id:Peer fwd_from:flags.2?MessageFwdHeader via_bot_id:flags.11?int reply_to_msg_id:flags.3?int date:int message:string media:flags.9?MessageMedia reply_markup:flags.6?ReplyMarkup entities:flags.7?Vector<MessageEntity> views:flags.10?int edit_date:flags.15?int post_author:flags.16?string grouped_id:flags.17?long = Message;
+message#44f9b43d flags:# out:flags.1?true mentioned:flags.4?true media_unread:flags.5?true silent:flags.13?true post:flags.14?true from_scheduled:flags.18?true id:int from_id:flags.8?int to_id:Peer fwd_from:flags.2?MessageFwdHeader via_bot_id:flags.11?int reply_to_msg_id:flags.3?int date:int message:string media:flags.9?MessageMedia reply_markup:flags.6?ReplyMarkup entities:flags.7?Vector<MessageEntity> views:flags.10?int edit_date:flags.15?int post_author:flags.16?string grouped_id:flags.17?long = Message;
У кого как, но GitHub, например, изменения внутри таких длинных строк подсвечивать отказывается. Игра «найди 10 отличий», причем что мозг сразу видит, это что начала и концы в обоих примерах одинаковы, нужно нудно вчитываться где-то в середине… На мой взгляд, вот это вот не то что в теории, а чисто визуально выглядит грязно и неряшливо.
Кстати, о чистоте теории. А зачем нужны битовые поля? Не кажется ли, что они пахнут нехорошо с точки зрения теории типов? Объяснение можно увидеть в ранних версиях схемы. Сначала да, так и было, на каждый чих создавался новый тип. Эти рудименты и сейчас есть вот в таком виде например:
storage.fileUnknown#aa963b05 = storage.FileType;
storage.filePartial#40bc6f52 = storage.FileType;
storage.fileJpeg#7efe0e = storage.FileType;
storage.fileGif#cae1aadf = storage.FileType;
storage.filePng#a4f63c0 = storage.FileType;
storage.filePdf#ae1e508d = storage.FileType;
storage.fileMp3#528a0677 = storage.FileType;
storage.fileMov#4b09ebbc = storage.FileType;
storage.fileMp4#b3cea0e4 = storage.FileType;
storage.fileWebp#1081464c = storage.FileType;Но теперь представьте, если у Вас в структуре 5 опциональных полей, то Вам понадобится 32 типа для всех возможных вариантов. Комбинаторный взрыв. Так хрустальная чистота теории TL в очередной раз разбилась о чугунную задницу суровой реальности сериализации.
Кроме того, местами эти ребята сами нарушают свою же типизацию. Например, в MTProto (следующая глава) ответ может быть пожат Gzip, всё здраво — кроме того, что нарушение слоев и схемы. Раз, и пожали не сам RpcResult, а его содержимое. Ну вот зачем так делать?.. Пришлось впиливать костыль, чтобы сжатие работало где угодно.
Или еще пример, мы однажды обнаружили ошибку — посылался InputPeerUser вместо InputUser. Или наоборот. Но это работало! То есть серверу было пофиг на тип. Как такое может быть? Ответ, возможно, подскажут нам фрагменты кода из telegram-cli:
if (tgl_get_peer_type (E->id) != TGL_PEER_CHANNEL || (C && (C->flags & TGLCHF_MEGAGROUP))) {
out_int (CODE_messages_get_history);
out_peer_id (TLS, E->id);
} else {
out_int (CODE_channels_get_important_history);
out_int (CODE_input_channel);
out_int (tgl_get_peer_id (E->id));
out_long (E->id.access_hash);
}
out_int (E->max_id);
out_int (E->offset);
out_int (E->limit);
out_int (0);
out_int (0);Иными словами, здесь сериализация делается ВРУЧНУЮ, а не сгенерированным кодом! Может быть, сервер реализован аналогично?.. В принципе, такое сгодится, если сделать один раз, но как это потом поддерживать при обновлениях? Уж не за этим ли схема была придумана? И тут мы переходим к следующему вопросу.
Версионность. Слои (layers)
Почему версии схемы названы слоями, можно делать только предположения, исходя из истории опубликованных схем. По всей видимости, поначалу авторам показалось, что базовые вещи можно делать на неизмененной схеме, и только там, где надо, на конкретные запросы указывать, что они делаются по другой версии. В принципе, даже неплохая идея — и новое будет как бы «подмешиваться», наслаиваться на старое. Но посмотрим, как это было сделано. Правда, посмотреть с самого начала не удалось — забавно, но схемы базового слоя просто не существует. Слои начались с 2. Документация рассказывает нам о специальной фиче TL:
If a client supports Layer 2, then the following constructor must be used:
invokeWithLayer2#289dd1f6 {X:Type} query:!X = X;In practice, this means that before every API call, an int with the value
0x289dd1f6must be added before the method number.
Звучит нормально. Но что было дальше? Дальше появился
invokeWithLayer3#b7475268 query:!X = X;А дальше? Как нетрудно догадаться,
invokeWithLayer4#dea0d430 query:!X = X;Смешно? Нет, еще рано смеяться, подумайте над тем, что каждый запрос с другого слоя нужно оборачивать в такой специальный тип — если они у Вас все разные, как их иначе различать-то? И добавление всего лишь 4 байт перед — довольно эффективный метод. So,
invokeWithLayer5#417a57ae query:!X = X;Но очевидно, что через некоторое время это станет некоторой вакханалией. И пришло решение:
Update: Starting with Layer 9, helper methods
invokeWithLayerNcan be used only together withinitConnection
Ура! Через 9 версий мы пришли, наконец, к тому, что в Internet-протоколах делалось еще в 80-е — согласованию версии один раз в начале соединения!
А дальше?..
invokeWithLayer10#39620c41 query:!X = X;
...
invokeWithLayer18#1c900537 query:!X = X;А вот теперь таки можно смеяться. Только еще через 9 слоев был, наконец, добавлен универсальный конструктор с номером версии, который нужно вызывать только один раз в начале соединения, и смысл в слоях вроде бы пропал, теперь это просто условная версия, как и везде. Проблема решена.
Точно?..
Vasily, [16.07.18 14:01]
Ещё в пятницу подумалось:
События телесервер посылает без запроса. Запросы нужно заворачивать в InvokeWithLayer. Апдейты сервер не заворачивает, нет структуры для оборачивания ответов и апдейтов.Т.е. клиент не может указать слой, в котором он хочет апдейты
Vadim Goncharov, [16.07.18 14:02]
а InvokeWithLayer разве не костыль в принципе?Vasily, [16.07.18 14:02]
Это единственный способVadim Goncharov, [16.07.18 14:02]
который по сути должен значить согласование лэйера в начале сессиикстати, из этого следует, что даунгрейд клиента не предусмотрен
Апдейты, т.е. тип Updates в схеме — это то, что сервер присылает клиенту не в ответ на API-запрос, а самостоятельно по возникновению события. Это сложная тема, которая будет рассмотрена в другом посте, сейчас же важно знать, что сервер копит Updates и во время оффлайна клиента.
Таким образом, при отказе от оборачивания каждого пакета в указание ему версии, отсюда логически возникают следующие возможные проблемы:
- сервер посылает клиенту апдейты еще до того, как тот сообщил, какая им поддерживается версия
- что надо делать после апгрейда клиента?
- кто гарантирует, что мнение сервера о номере слоя не поменяется в процессе?
Думаете, это сугубо теоретические умствования, и на практике такого не может возникнуть, ведь сервер написан корректно (во всяком случае, тестируется хорошо)? Ха! Как бы не так!
Именно на это мы в августе и напоролись. 14 августа мелькали сообщения, что на серверах Telegram что-то обновляеют… а дальше в логах:
2019-08-15 09:28:35.880640 MSK warn main: ANON:87: unknown object type: 0x80d182d1 at TL/Object.pm line 213.
2019-08-15 09:28:35.751899 MSK warn main: ANON:87: unknown object type: 0xb5223b0f at TL/Object.pm line 213.и далее несколько мегабайт стэктрейсов (ну, заодно и логирование пофиксили). Ведь если у Вас в TL что-то не распозналось — он же бинарный по сигнатурам, дальше в потоке ВСЁ поедет, декодирование станет невозможным. Что вообще в такой ситуации делать?
Ну, первое что любому в голову приходит — отсоединиться и попробовать заново. Не помогло. Гуглим по CRC32 — это оказались объекты с 73 схемы, хотя мы работали на 82. Внимательно смотрим в логи — там идентификаторы с двух разных схем!
Может, проблема сугубо в нашем неофициальном клиенте? Нет, запускаем Telegram Desktop 1.2.17 (версия, поставляемая в ряде дистрибутивов Linux), он пишет в лог Exception: MTP Unexpected type id #b5223b0f read in MTPMessageMedia…
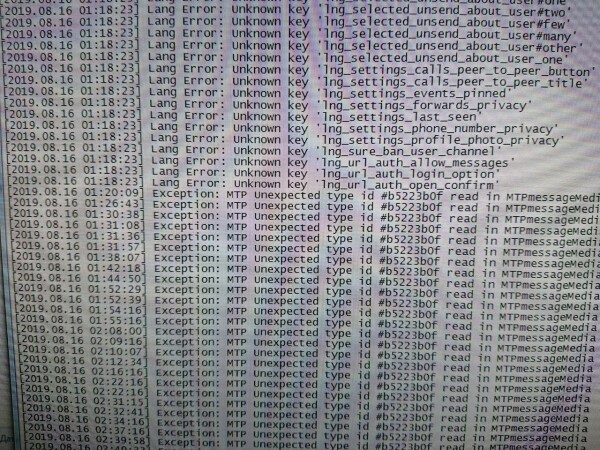
Гугль показал, что подобная проблема у кого-то из неофициальных клиентов уже случалась, но тогда номера версий и соответственно предположения были другие…
Так что же делать-то? Мы с Василием разделились: он попробовал обновить схему до 91, я решил подождать несколько дней и попробовать на 73. Оба способа сработали, но поскольку они эмпирические, нет никакого понимания, ни на сколько версий вверх или вниз надо прыгать, ни сколько времени надо ждать.
Позже у меня получилось воспроизвести ситуацию: запускаем клиент, отключаем, перекомпилируем схему на другой слой, перезапускаем, снова ловим проблему, возвращаемся на предыдущий — опа, уже никакие переключения схемы и перезапуски клиента в течение нескольких минут не помогут. Вам будет приходить микс из структур данных с разных слоёв.
Объяснение? Как можно догадаться по различным косвенным симптомам, сервер состоит из многих процессов разных типов на различных машинах. Скорее всего, тот из серверов, что отвечает за «буферизацию», положил в очередь то, что ему отдавали вышестоящие, а они отдавали в той схеме, которая была на момент генерации. И пока эта очередь не «протухла», ничего с этим сделать было нельзя.
Разве что… но ведь это жуткий костыль?!.. Нет, прежде чем думать о безумных идеях, давайте посмотрим в код официальных клиентов. В версии для Android мы не находим никакого TL-парсера, но находим здоровенный файл (гитхаб отказывается его подкрашивать) с (де)сериализацией. Вот фрагменты кода:
public static class TL_message_layer68 extends TL_message {
public static int constructor = 0xc09be45f;
//...
//еще пачка подобных
//...
public static class TL_message_layer47 extends TL_message {
public static int constructor = 0xc992e15c;
public static Message TLdeserialize(AbstractSerializedData stream, int constructor, boolean exception) {
Message result = null;
switch (constructor) {
case 0x1d86f70e:
result = new TL_messageService_old2();
break;
case 0xa7ab1991:
result = new TL_message_old3();
break;
case 0xc3060325:
result = new TL_message_old4();
break;
case 0x555555fa:
result = new TL_message_secret();
break;
case 0x555555f9:
result = new TL_message_secret_layer72();
break;
case 0x90dddc11:
result = new TL_message_layer72();
break;
case 0xc09be45f:
result = new TL_message_layer68();
break;
case 0xc992e15c:
result = new TL_message_layer47();
break;
case 0x5ba66c13:
result = new TL_message_old7();
break;
case 0xc06b9607:
result = new TL_messageService_layer48();
break;
case 0x83e5de54:
result = new TL_messageEmpty();
break;
case 0x2bebfa86:
result = new TL_message_old6();
break;
case 0x44f9b43d:
result = new TL_message_layer104();
break;
case 0x1c9b1027:
result = new TL_message_layer104_2();
break;
case 0xa367e716:
result = new TL_messageForwarded_old2(); //custom
break;
case 0x5f46804:
result = new TL_messageForwarded_old(); //custom
break;
case 0x567699b3:
result = new TL_message_old2(); //custom
break;
case 0x9f8d60bb:
result = new TL_messageService_old(); //custom
break;
case 0x22eb6aba:
result = new TL_message_old(); //custom
break;
case 0x555555F8:
result = new TL_message_secret_old(); //custom
break;
case 0x9789dac4:
result = new TL_message_layer104_3();
break;или
boolean fixCaption = !TextUtils.isEmpty(message) &&
(media instanceof TLRPC.TL_messageMediaPhoto_old ||
media instanceof TLRPC.TL_messageMediaPhoto_layer68 ||
media instanceof TLRPC.TL_messageMediaPhoto_layer74 ||
media instanceof TLRPC.TL_messageMediaDocument_old ||
media instanceof TLRPC.TL_messageMediaDocument_layer68 ||
media instanceof TLRPC.TL_messageMediaDocument_layer74)
&& message.startsWith("-1");Кхм… выглядит дико. Но, наверное, это сгенерированный код, тогда ладно?.. Зато уж точно все версии поддерживает! Правда, непонятно, почему всё намешано в одну кучу, и секретные чаты, и всякие _old7 как-то не похожи на машинную генерацию… Впрочем, больше всего я офигел от
TL_message_layer104
TL_message_layer104_2
TL_message_layer104_3Ребята, вы там что, даже внутри одного слоя определиться не можете?! Ну, ладно, «два», допустим, релизнулись с ошибкой, ну бывает, но ТРИ?.. Сходу же еще раз на те же грабли? Что это за порнография, пардон?..
В исходниках Telegram Desktop, кстати, случается аналогичное — раз так, и несколько коммитов подряд в схему не меняют её номера слоя, а что-то фиксят. В условиях, когда официального источника данных по схеме нет, откуда её брать, кроме исходников официального клиента? А возьмешь оттуда, не можешь быть уверен, что схема целиком правильная, пока не протестируешь все методы.
А как такое вообще можно тестировать? Надеюсь, любители юнит-, функциональных и прочих тестов поделятся в комментариях.
Ладно, рассмотрим еще фрагмент кода:
public static class TL_folders_deleteFolder extends TLObject {
public static int constructor = 0x1c295881;
public int folder_id;
public TLObject deserializeResponse(AbstractSerializedData stream, int constructor, boolean exception) {
return Updates.TLdeserialize(stream, constructor, exception);
}
public void serializeToStream(AbstractSerializedData stream) {
stream.writeInt32(constructor);
stream.writeInt32(folder_id);
}
}
//manually created
//RichText start
public static abstract class RichText extends TLObject {
public String url;
public long webpage_id;
public String email;
public ArrayList<RichText> texts = new ArrayList<>();
public RichText parentRichText;
public static RichText TLdeserialize(AbstractSerializedData stream, int constructor, boolean exception) {
RichText result = null;
switch (constructor) {
case 0x1ccb966a:
result = new TL_textPhone();
break;
case 0xc7fb5e01:
result = new TL_textSuperscript();
break;Вот этот комментарий «manually created» наводит на мысль, что лишь часть этого файла написана вручную (представляете весь кошмар в части maintenance?), а остальное таки сгенерировано машиной. Однако, тогда возникает другой вопрос — о том, что исходники доступны не полностью (а-ля блобы под GPL в ядре Linux), однако это уже тема для второй части.
Но довольно. Перейдём к протоколу, поверх которого вся эта сериализация гоняется.
MTProto
Итак, открываем и и первым делом спотыкаемся о терминологию. И с обилием всего. Вообще, это похоже фирменная фишка Telegram — называть вещи в разных местах по-разному, либо разные вещи одним словом, либо наоборот (например, в высокоуровневом API если увидите sticker pack — это не то, что Вы подумали).
Например, «сообщение» (message) и «сессия» (session) — здесь значат другое, чем в привычном интерфейсе Telegram-клиента. Ну, с сообщением всё понятно, его можно было бы трактовать в терминах ООП, или же просто называть словом «пакет» — это низкий, транспортный уровень, здесь не те сообщения, что в интерфейсе, много служебных. А вот сессия… но обо всём по порядку.
Транспортный уровень
Первым делом — транспорт. Нам расскажут аж про 5 вариантов:
- TCP
- Websocket
- Websocket over HTTPS
- HTTP
- HTTPS
Vasily, [15.06.18 15:04]
А ещё есть UDP транспорт, но он не документированА TCP в трёх вариантах
Первый похож на UDP поверх TCP, каждый пакет включает в себя sequence number и crc
Почему читать доки на тележку так больно?
Ну, сейчас там :
- Abridged
- Intermediate
- Padded intermediate
- Full
Ну хорошо, Padded intermediate для MTProxy, это позже добавили из-за известных событий. А вот зачем еще две версии (итого три), когда можно было бы обойтись одной? Все четыре по сути отличаются лишь тем, каким образом задать длину и payload собственно того основного MTProto, о котором речь пойдёт дальше:
- в Abridged это 1 или 4 байта, но не 0xef, затем тело
- в Intermediate это 4 байта длины и поле, причем первый раз клиент должен послать
0xeeeeeeeeдля указания, что это Intermediate - в Full самая наркомания, с точки зрения сетевика: длина, sequence number, причем НЕ ТОТ, что в основном MTProto, тело, CRC32. Да, всё это поверх TCP. Который предоставляет нам надежный транспорт в виде последовательного потока байт, никакие последовательности не нужны, тем более контрольные суммы. Окей, мне сейчас возразят, что в TCP 16-битная контрольная сумма, так что искажение данных случается. Отлично, только у нас вообще-то криптографический протокол с хэшами длиннее 16 байт, все эти ошибки — и дажее более — будут отловлены на несовпадении SHA уровнем выше. Никакого смысла в CRC32 поверх этого — НЕТ.
Сравним Abridged, в котором возможен один байт длины, с Intermediate, который обосновывается «In case 4-byte data alignment is needed», что довольно-таки чепуха. Что, считается, что программисты Telegram настолько неумехи, что не могут прочитать данные из сокета в выровненный буфер? Это всё равно придется делать, потому что чтение может вернуть Вам какое попало количество байт (а еще бывают например прокси-сервера…). Или с другой стороны, зачем городить Abridged, если сверху у нас всё равно будут здоровенные padding’и от 16 байт — сэкономить 3 байта иногда ?
Складывается впечатление, что Николай Дуров очень любит изобретать велосипеды, в том числе сетевые протоколы, без реальной практической надобности.
Остальные варианты транспорта, в т.ч. Web и MTProxy, мы сейчас рассматривать не будем, может быть, в другом посте, если будет запрос. Про этот самый MTProxy вспомним сейчас лишь, что вскоре после его выпуска в 2018, провайдеры быстренько научились блокировать именно его, предназначенного для обхода блокировок, по размеру пакета! А также тот факт, что написанный (опять же Вальтманом) сервер MTProxy на Си был излишне завязан на линуксовую специфику, хотя это совсем не требовалось (Фил Кулин подтвердит), и что аналогичный сервер то ли на Go, то ли на Node.js уместился менее чем в сотню строк.
Но делать выводы о технической грамотности этих людей делать будем в конце раздела, после рассмотрения других вопросов. Пока перейдём к 5-му уровню OSI, сессионному — на который они поместили MTProto session.
Ключи, сообщения, сессии, Diffie-Hellman
Поместили они его туда не совсем корректно… Сессия — это не та сессия, что видна в интерфейсе под Active sessions. Но по порядку.
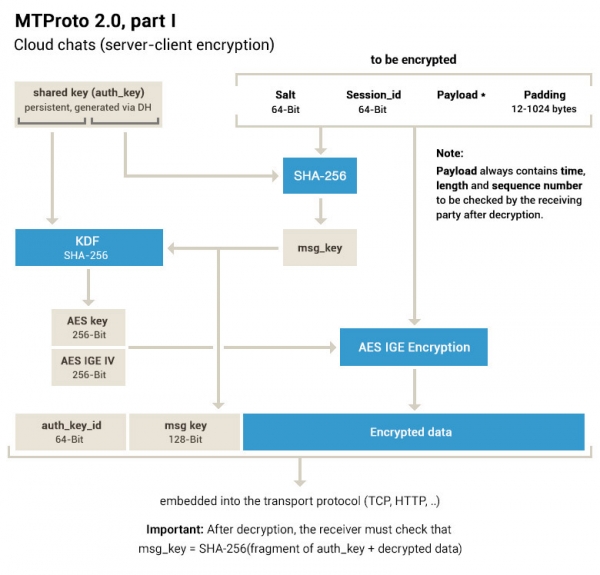
Вот мы получили с транспортного уровня строку байт известной длины. Это либо шифрованное сообщение, либо plaintext — если мы еще на стадии согласования ключа и собственно им и занимаемся. О каком из кучи понятий под названием «ключ» идет речь? Проясним этот вопрос за саму команду Telegram (приношу извинения за перевод с английского собственной документации к либе усталым мозгом в 4 утра, некоторые фразы было проще оставить как есть):
Есть две сущности под названием session — одна в UI официальных клиентов под «current sessions», где каждой сессии соответствует целое устройство / OS.
Вторая — MTProto session, у которой есть sequence number сообщения (в низкоуровневом смысле) в ней, и которая может длиться между разными TCP-соединениями. Одновременно могут быть установлены несколько MTProto-сессий, например для ускорения закачки файлов.Между этими двумя sessions находится понятие authorization. В вырожденном случае, можно сказать, что UI-сессия есть то же, что authorization, но увы, всё сложно. Смотрим:
- Пользователь на новом устройстве сначала генерирует auth_key и bounds it to account, например по SMS — потому и authorization
- Произошло это внутри первой MTProto session, которая имеет
session_idвнутри себя.- На данном шаге, комбинация authorization и
session_idмогла быть названа instance — это слово встречается в документации и коде некоторых клиентов- Затем, клиент может открыть несколько MTProto sessions под одним и тем же auth_key — к одному и тому же DC.
- Затем, однажды клиенту понадобится запросить файл у другого DC — и для этого DC будет сгенерирован новый auth_key !
- Чтобы сообщить системе, что это не новый юзер регистрируется, а та же самая authorization (UI-сессия), клиент использует вызовы API
auth.exportAuthorizationв домашнем DCauth.importAuthorizationв новом DC.- Всё так же, может быть открыто несколько MTProto sessions (каждая с собственным
session_id) к этому новому DC, под его auth_key.- Наконец, клиент может захоть Perfect Forward Secrecy. Каждый auth_key был permanent key — per DC — и клиент может вызвать
auth.bindTempAuthKeyдля использования temporary auth_key — и снова, только один temp_auth_key per DC, общий для всех MTProto sessions к этому DC.Заметим, что salt (и future salts) тоже одна на auth_key т.е. shared между всеми MTProto sessions к одному и тому же DC.
Что значит «между разными TCP-соединениями»? Значит, что это нечто вроде авторизации кукой на веб-сайте — она сохраняется (переживает) много TCP-соединений к данному серверу, но однажды протухнет. Только в отличие от HTTP, в MTProto внутри сессии сообщения последовательно нумеруются и подтверждаются, въехали в туннель, разорвалось соединение — после установления нового соединения сервер любезно отправит всё то в этой сессии, что не доставил в прошлом TCP-соединении.
Однако, информация выше приведена выжимкой после долгих месяцев разбирательств. А пока что — мы ведь реализуем свой клиент с нуля? — вернемся к началу.
Так что, генерируем auth_key по . Попытаемся понять документацию…
Vasily, [19.06.18 20:05]
data_with_hash := SHA1(data) + data + (any random bytes); such that the length equal 255 bytes;
encrypted_data := RSA (data_with_hash, server_public_key); a 255-byte long number (big endian) is raised to the requisite power over the requisite modulus, and the result is stored as a 256-byte number.У них какой-то наркоманский DH
Не похоже на DH здорового человека
В дх нет двух публичных ключей
Ну с этим в итоге разобрались но осадочек остался — делается proof of work клиентом, что он смог факторизовать число. Типа защита от DoS-атак. И RSA-ключ используется только один раз в одном направлении, по сути, для шифрования new_nonce. Но пока эта вроде бы простая операция получится, с чем придется столкнуться?
Vasily, [20.06.18 00:26]
Я ещё не дошёл до запроса appidЭто я запрос на DH отправил
А, в доке на транспорт написано, что может ответить 4 байтами кода ошибки. И всё
Ну вот сказал он мне -404, и что?
Вот я ему: «лови свою ефигню шифрованную ключом сервера с отпечатком таким-то, хочу DH», а оно в ответ тупо 404
Что бы Вы подумали на такой ответ сервера? Что делать? Спросить-то не у кого (но об этом во второй части).
Тут весь интерес по доке сделать
Мне вот больше заняться нечем, только и мечтал числа туда-сюда конвертить
Два 32 битных числа. Я их и упаковал как все остальные
Но нет, именно эти два нужно сначала в строку как BE
Vadim Goncharov, [20.06.18 15:49]
и из-за этого 404?Vasily, [20.06.18 15:49]
ДА!Vadim Goncharov, [20.06.18 15:50]
вот я и не понимаю, что он может «не нашла»Vasily, [20.06.18 15:50]
примерноНе нашла такого разложения на простые делители %)
Даже error reporting не осилили
Vasily, [20.06.18 20:18]
О, там ещё и MD5. Уже три разных хэшаThe key fingerprint is computed as follows:
digest = md5(key + iv) fingerprint = substr(digest, 0, 4) XOR substr(digest, 4, 4)SHA1 и sha2
Итак, положим, auth_key размером 2048 бит мы по Диффи-Хеллману получили. Что дальше? Дальше мы обнаруживаем, что младшие 1024 бита этого ключа никак не используются… но подумаем пока вот о чем. На данном шаге у нас есть с сервером общий секрет. Установлен аналог TLS-сессии, весьма затратной процедурой. Но сервер еще ничего не знает о том, кто мы такие! Еще нет, собственно, авторизации. Т.е. если Вы мыслили в понятиях «логин-пароль», как когда-то в ICQ, или хотя бы «логин-ключ», как в SSH (например на какой-нибудь gitlab/github). Мы получили анонимуса. А если сервер ответит нам «данные телефонные номера обслуживаются другим DC»? Или вообще «ваш телефонный номер забанен»? Лучшее, что мы можем сделать — это сохранить ключ в надежде, что еще пригодится и не протухнет к тому моменту.
Кстати, «получили» мы его с оговорками. Вот например, мы доверяем серверу? Вдруг он поддельный? Нужны бы криптографические проверки:
Vasily, [21.06.18 17:53]
Они предлагают мобильным клиентам проверять 2кбитное число на простоту %)Но вообще непонятно, нафейхоа
Vasily, [21.06.18 18:02]
В доке не сказано, что делать, если оно не простое оказалось
Не сказано. Давайте посмотрим, что в этом случае делает официальный клиент под Андроид? А (и да, там весь файл интересный) — как говорится, я просто оставлю это здесь:
278 static const char *goodPrime = "c71caeb9c6b1c9048e6c522f70f13f73980d40238e3e21c14934d037563d930f48198a0aa7c14058229493d22530f4dbfa336f6e0ac925139543aed44cce7c3720fd51f69458705ac68cd4fe6b6b13abdc9746512969328454f18faf8c595f642477fe96bb2a941d5bcd1d4ac8cc49880708fa9b378e3c4f3a9060bee67cf9a4a4a695811051907e162753b56b0f6b410dba74d8a84b2a14b3144e0ef1284754fd17ed950d5965b4b9dd46582db1178d169c6bc465b0d6ff9ca3928fef5b9ae4e418fc15e83ebea0f87fa9ff5eed70050ded2849f47bf959d956850ce929851f0d8115f635b105ee2e4e15d04b2454bf6f4fadf034b10403119cd8e3b92fcc5b";
279 if (!strcasecmp(prime, goodPrime)) {Не, там конечно еще какие-то проверки простоты числа есть, но лично я достаточными познаниями в математике уже не обладаю.
Ладно, мы получили основной ключ. Чтобы авторизоваться, т.е. послать запросы, надо производить дальнейшее шифрование, уже с помощью AES.
The message key is defined as the 128 middle bits of the SHA256 of the message body (including session, message ID, etc.), including the padding bytes, prepended by 32 bytes taken from the authorization key.
Vasily, [22.06.18 14:08]
Средние, сука, битыПолучил
auth_key. Всё. Дальше них… не понятно из доки. Feel free to study the open source code.Note that MTProto 2.0 requires from 12 to 1024 bytes of padding, still subject to the condition that the resulting message length be divisible by 16 bytes.
Так сколько паддинга сыпать?
И да, тут тоже 404 в случае ошибки
Если кто внимательно изучил схему и текст документации, обратил внимание, что никакого MAC там нет. И что AES используется в некоем, более нигде не применяющемся режиме IGE. Они, конечно, пишут об этом в своем FAQ… Здесь, типа, сам ключ сообщения заодно и является SHA-хэшом расшифрованных данных, используемым для проверки целостности — причем в случае несовпадения документация почему-то рекомендует silently ignore их (а как же безопасность, вдруг нас ломают?).
Я не криптограф, может быть, в этом режиме в данном случае и нет ничего плохого с теоретической точки зрения. Но я могу совершенно точно назвать практическую проблему, на примере Telegram Desktop. Он локальный кэш (все вот эти D877F783D5D3EF8C) шифрует тем же способом, что сообщения в MTProto (только в данном случае версии 1.0), т.е. сначала ключ сообщения, потом сами данные (и где-то в стороне основной большой auth_key на 256 байт, без которого msg_key бесполезен). Так вот, проблема становится заметна на больших файлах. А именно, Вам надо держать две копии данных — шифрованную и расшифрованную. А если там мегабайты, или потоковое видео, например?.. Классические схемы с MAC после шифротекста позволяют Вам считать его потоково, сразу передавая. А с MTProto придется сначала зашифровать или расшифровать сообщение целиком, только потом передавать в сеть или на диск. Поэтому в свежих версиях Telegram Desktop в кэше в user_data применяется уже и другой формат — с AES в режиме CTR.
Vasily, [21.06.18 01:27]
О, я узнал, что такое IGE: IGE was the first attempt at an «authenticating encryption mode,» originally for Kerberos. It was a failed attempt (it does not provide integrity protection), and had to be removed. That was the beginning of a 20 year quest for an authenticating encryption mode that works, which recently culminated in modes like OCB and GCM.А теперь аргументы со стороны телеги:
The team behind Telegram, led by Nikolai Durov, consists of six ACM champions, half of them Ph.Ds in math. It took them about two years to roll out the current version of MTProto.
Чот смешно. Два года на нижний уровень
А могли бы просто взять tls
Ладно, допустиим, шифрование и прочие нюансы мы сделали. Можно, наконец, посылать сериализованные в TL запросы и десериализовывать ответы? Так а что и как слать надо? Вот, допустим, метод , наверное это оно?
Vasily, [25.06.18 18:46]
Initializes connection and save information on the user’s device and application.Оно принимает app_id, device_model, system_version, app_version и lang_code.
И некий query
Документация как всегда. Feel free to study the open source
Если с invokeWithLayer всё было примерно понятно, то здесь-то что? Оказывается, предположим у нас — клиент уже имел нечто, о чем спросить сервер — имеется запрос, который мы хотели послать:
Vasily, [25.06.18 19:13]
Судя по коду, первый вызов заворачивается в эту дрисню, а сама дрисня в invokewithlayer
Почему initConnection не мог быть отдельным вызовом, а обязательно должен быть оберткой? Да, как оказалось, его надо обязательно каждый раз в начале каждой сессии делать, а не разово, как с основным ключом. Но! Его не может вызвать неавторизованный пользователь! Вот мы добрались до этапа, в котором применима страница документации — и она сообщает нам, что…
Only a small portion of the API methods are available to unauthorized users:
- auth.sendCode
- auth.resendCode
- account.getPassword
- auth.checkPassword
- auth.checkPhone
- auth.signUp
- auth.signIn
- auth.importAuthorization
- help.getConfig
- help.getNearestDc
- help.getAppUpdate
- help.getCdnConfig
- langpack.getLangPack
- langpack.getStrings
- langpack.getDifference
- langpack.getLanguages
- langpack.getLanguage
Самый первый из них, auth.sendCode, и есть тот заветный первый запрос, в котором мы отправим api_id и api_hash, и после которого нам приходит SMS с кодом. А если мы попали не в тот DC (телефонные номера этой страны обслуживает другой, например), то нам придёт ошибка с номером нужного DC. Чтобы узнать, на какой IP-адрес по номеру DC надо соединяться, нам поможет help.getConfig. Когда-то там было всего 5 записей, но после известных событий 2018 года число значительно возросло.
Теперь вспомним то, что мы попали на этом этапе на сервере анонимусом. Не слишком ли затратно для того, чтобы просто получить IP-адрес? Почему было бы не делать это, и другие операции, в нешифрованной части MTProto? Слышу возражение: «а как удостовериться, что это не РКН фальшивыми адресами ответит?». На это мы вспомним, что вообще-то в официальные клиенты вшиты RSA-ключи, т.е. можно просто подписать эту информацию. Собственно, так уже и делается для информации по обходам блокировок, которую клиенты получают по другим каналам (логично, что это нельзя сделать в самом MTProto, еще ведь надо знать, куда соединиться).
Ну, ладно. На этом этапе авторизации клиента мы еще не авторизованы и не регистрировали своё приложение. Мы хотим просто пока посмотреть, что отвечает сервер на методы, доступные неавторизованному пользователю. И тут…
Vasily, [10.07.18 14:45]
config#7dae33e0 [...] = Config; help.getConfig#c4f9186b = Config;config#232d5905 [...] = Config; help.getConfig#c4f9186b = Config;В схеме первое, приходит второе
В схеме tdesktop третье значение
Да, с тех пор, конечно, документацию обновили. Хотя скоро она снова может стать неактуальной. А откуда должен знать начинающий разработчик? Может быть, если зарегистрировать своё приложение, то сообщат? Василий сделал это, но увы — ничего ему не прислали (снова, поговорим об этом во второй части).
… Вы заметили, что мы уже как-то перешли к API, т.е. к следующему уровню, и что-то пропустили в теме MTProto? Ничего удивительного:
Vasily, [28.06.18 02:04]
Мм, они шарят часть алгоритмов на e2eMtproto определяет алгоритмы и ключи шифрования для обоих доменов, а также немного структуру обёртки
Но они постоянно смешивают разные уровни стека, так что не всегда понятно, где закончился mtproto и начался следующий уровень
Как смешивают? Ну вот тот же временный ключ для PFS, например (кстати, Telegram Desktop его не умеет). Он выполняется запросом API auth.bindTempAuthKey, т.е. с верхнего уровня. Но при этом вторгается в шифрование на нижнем уровне — после него, например, надо заново делать initConnection и т.п., это не просто обычный запрос. Отдельно доставляет еще и то, что можно иметь только ОДИН временный ключ на DC, хотя поле auth_key_id в каждом сообщении позволяет менять ключ хоть каждое сообщение, и что сервер имеет право в любой момент «забыть» временный ключ — что в этом случае делать, документация не говорит… ну почему нельзя было бы иметь несколько ключей, как с набором future salts, а?..
Стоит отметить в теме MTProto еще некоторые вещи.
Сообщения о сообщениях, msg_id, msg_seqno, подтверждения, пинги не в ту сторону и другие идиосинкразии
Почему о них нужно знать? Потому что они «протекают» на уровень выше, и о них нужно знать, работая с API. Положим, msg_key нас не интересует, нижний уровень расшифровал всё для нас. Но внутри расшифрованных данных у нас такие поля (еще длина данных, чтоб знать, где padding, но это не важно):
- salt — int64
- session_id — int64
- message_id — int64
- seq_no — int32
Напомним, соль — одна на весь DC. Зачем о ней знать? Не только потому, что есть запрос get_future_salts, который сообщает, в какие интервалы какие будут валидны, но и потому, что если Ваша соль «протухла», то сообщение (запрос) — просто потеряется. Сервер, конечно, сообщит новую соль, выдав new_session_created — но со старым придется как-то делать перепосылку, например. И этот вопрос влияет на архитектуру приложения.
Серверу разрешено вообще дропать сессии и отвечать таким образом по многим поводам. Собственно, что такое сессия MTProto со стороны клиента? Это два числа, session_id и seq_no сообщения внутри этой сессии. Ну, и нижележащее TCP-соединение, конечно. Допустим, наш клиент еще много чего не умеет, отсоединился, переподсоединился. Если это произошло быстро — в новом TCP-соединении продолжилась старая сессия, увеличиваем seq_no дальше. Если долго — сервер мог её удалить, потому что на его стороне это еще и очередь, как мы выяснили.
Каков должен быть seq_no? О, это хитрый вопрос. Попробуйте честно понять, что имелось в виду:
Content-related Message
A message requiring an explicit acknowledgment. These include all the user and many service messages, virtually all with the exception of containers and acknowledgments.
Message Sequence Number (msg_seqno)
A 32-bit number equal to twice the number of “content-related” messages (those requiring acknowledgment, and in particular those that are not containers) created by the sender prior to this message and subsequently incremented by one if the current message is a content-related message. A container is always generated after its entire contents; therefore, its sequence number is greater than or equal to the sequence numbers of the messages contained in it.
Что это за цирк с инкрементом на 1, а потом еще на 2?.. Подозреваю, изначально имелось в виду «младший бит для ACK, остальное номер», но в результате получается не совсем так — в частности, выходит, может быть послано несколько подтверждений, имеющих один и тот же seq_no! Как? Ну например сервер нам что-то шлет, шлёт, а мы сами молчим, только отвечаем сервисными сообщениями подтверждений о получении его сообщений. В этом случае наши исходящие подтверждения будут иметь один и тот же исходящий номер. Если Вы знакомы с TCP и подумали, что это звучит как-то дико, но вроде бы не очень и дико, ведь в TCP seq_no не меняется, а подтверждение идёт на seq_no той стороны — то поспешу огорчить. В MTProto подтверждения идут НЕ по seq_no, как в TCP, а по msg_id !
Что же это за msg_id, самое важное из этих полей? Уникальный идентификатор сообщения, как явствует из названия. Определён он как 64-битное число, самые младшие биты которого опять имеют магию «сервер-не сервер», а остальное — Unix timestamp, включая дробную часть, сдвинутый на 32 бита влево. Т.е. метка времени по сути (и сообщения со слишком отличающимся временем будут отвергнуты сервером). Из этого выходит, что в общем-то это идентификатор, глобальный для клиента. При том, что — вспомним session_id — нам гарантируется: Under no circumstances can a message meant for one session be sent into a different session. То есть, получается, что есть аж три уровня — сессия, номер в сессии, id сообщения. Зачем такое переусложнение, сия тайна есть велика весьма.
Итак, msg_id нужен для…
RPC: запросы, ответы, ошибки. Подтверждения.
Как Вы, может быть, заметили, нигде в схеме нет специального типа или функции «сделать RPC-запрос», хотя есть ответы. Ведь у нас же есть content-related сообщения! То есть, любое сообщение может быть запросом! Или не быть. Ведь у каждого есть msg_id. А вот ответы — есть:
rpc_result#f35c6d01 req_msg_id:long result:Object = RpcResult;Вот здесь и указывается, на какое сообщение это ответ. Поэтому Вам, на верхнем уровне API, придется помнить, какой номер был у Вашего запроса — думаю, не надо пояснять, что работа асинхронная, и одновременно в работе может быть несколько запросов, ответы на которые могут вернуться в любом порядке? В принципе, из этого, и сообщений об ошибках типа no workers, прослеживается стоящая за этим архитектура: поддерживающий с Вами TCP-соединение сервер — фронтенд-балансировщик, он направляет запросы на бэкенды и собирает их обратно по message_id. Вроде тут всё понятно, логично и хорошо.
Да?.. А если задуматься? Ведь у самого RPC-ответа тоже есть поле msg_id! Надо ли нам орать серверу «вы не отвечаете на мой ответ!»? И да, что там было про подтверждения? Страница про говорит нам, что есть
msgs_ack#62d6b459 msg_ids:Vector long = MsgsAck;и его должна делать каждая сторона. Но не всегда! Если Вы получили RpcResult, он сам служит подтверждением. То есть, на Ваш запрос сервер может ответить MsgsAck — типа, «я получил». Может сразу ответить RpcResult. Может быть и то и другое.
И да, Вы таки должны ответить на ответ! Подтверждением. Иначе сервер будет считать его недоставленным и вывалит Вам его опять. Даже после переподсоединения. Но тут, конечно, вопрос таймаутов возникнет. Рассмотрим их чуть позже.
А пока рассмотрим возможные ошибки выполнения запросов.
rpc_error#2144ca19 error_code:int error_message:string = RpcError;О, воскликнет кто-то, здесь более человечный формат — есть строка! Не торопитесь. Вот , но, конечно, не полный. Из него мы узнаем, что код — нечто вроде HTTP-ошибки (ну разумеется, семантика ответов не соблюдается, местами они распределены по кодам как попало), а строка имеет вид типа БОЛЬШИЕ_БУКВЫ_И_ЦИФРЫ. Например, PHONE_NUMBER_OCCUPIED или FILE_PART_Х_MISSING. Ну то есть, Вам эту строку еще придется пропарсить. Например, FLOOD_WAIT_3600 будет означать, что надо ждать час, а PHONE_MIGRATE_5, что телефонному номеру с этим префиксом надо регистрироваться в 5-м DC. У нас ведь язык типов, да? Аргумент из строки нам не нужен, регулярками обойдутся, чо.
Опять же, на странице сервисных сообщений этого нет, но, как уже привычно с этим проектом, информация может найтись на другой странице документации. Или навести на подозрение. Во-первых, смотрите, нарушение типизации/слоёв — RpcError может быть вложен в RpcResult. Почему не снаружи? Что мы не учли?.. Соответственно, где гарантия, что RpcError может быть и НЕ вложен в RpcResult, а быть напрямую или вложен в другой тип?.. А если не может, почему он не верхнего уровня, т.е. в нём отсутствует req_msg_id ?..
Но продолжим о сервисных сообщениях. Клиент может счесть, что сервер долго думает, и сделать вот такой замечательный запрос:
rpc_drop_answer#58e4a740 req_msg_id:long = RpcDropAnswer;На него возможны три варианта ответа, опять пересекающихся с механизмом подтверждений, попытаться понять, какими они должны быть (и каков вообще список типов, не требущих подтверждений), читателю оставляется в качестве домашнего задания (замечание: в исходниках Telegram Desktop информация не полна).
Наркомания: статусы сообщений о сообщениях
Вообще, ощущение упоротости оставляют многие места в TL, MTProto и Telegram в целом, но из вежливости, тактичности и прочих soft skills мы об этом вежливо промолчали, а маты в диалогах отцензурировали. Однако это место, бОльшая часть страницы про вызывает оторопь даже у меня, давно работающего с сетевыми протоколами и видывавшего велосипеды разной степени кривости.
Начинается она безобидно, с подтверждений. Дальше нам рассказывают о
bad_msg_notification#a7eff811 bad_msg_id:long bad_msg_seqno:int error_code:int = BadMsgNotification;
bad_server_salt#edab447b bad_msg_id:long bad_msg_seqno:int error_code:int new_server_salt:long = BadMsgNotification;Ну, с ними придется столкнуться каждому начинающему работать с MTProto, в цикле «поправил — перекомпилировал — запустил» получить ошибки номеров или успевшую протухнуть за время правок соль — обычное дело. Однако тут два момента:
- Из этого следует, что оригинальное сообщение потеряно. Нужно городить какие-то очереди, рассмотрим это позже.
- Что за странные номера ошибок? 16, 17, 18, 19, 20, 32, 33, 34, 35, 48, 64… где остальные номера, Томми?
Документация утверждает:
The intention is that error_code values are grouped (error_code >> 4): for example, the codes 0x40 — 0x4f correspond to errors in container decomposition.
но, во-первых, сдвиг в другую сторону, во-вторых, всё равно, где остальные коды? В голове автора?.. Впрочем, это мелочи.
Наркомания начинается в сообщениях о статусах сообщений и копиях сообщений:
- Request for Message Status Information
If either party has not received information on the status of its outgoing messages for a while, it may explicitly request it from the other party:
msgs_state_req#da69fb52 msg_ids:Vector long = MsgsStateReq; - Informational Message regarding Status of Messages
msgs_state_info#04deb57d req_msg_id:long info:string = MsgsStateInfo;
Here,infois a string that contains exactly one byte of message status for each message from the incoming msg_ids list:- 1 = nothing is known about the message (msg_id too low, the other party may have forgotten it)
- 2 = message not received (msg_id falls within the range of stored identifiers; however, the other party has certainly not received a message like that)
- 3 = message not received (msg_id too high; however, the other party has certainly not received it yet)
- 4 = message received (note that this response is also at the same time a receipt acknowledgment)
- +8 = message already acknowledged
- +16 = message not requiring acknowledgment
- +32 = RPC query contained in message being processed or processing already complete
- +64 = content-related response to message already generated
- +128 = other party knows for a fact that message is already received
This response does not require an acknowledgment. It is an acknowledgment of the relevant msgs_state_req, in and of itself.
Note that if it turns out suddenly that the other party does not have a message that looks like it has been sent to it, the message can simply be re-sent. Even if the other party should receive two copies of the message at the same time, the duplicate will be ignored. (If too much time has passed, and the original msg_id is not longer valid, the message is to be wrapped in msg_copy).
- Voluntary Communication of Status of Messages
Either party may voluntarily inform the other party of the status of the messages transmitted by the other party.
msgs_all_info#8cc0d131 msg_ids:Vector long info:string = MsgsAllInfo - Extended Voluntary Communication of Status of One Message
…
msg_detailed_info#276d3ec6 msg_id:long answer_msg_id:long bytes:int status:int = MsgDetailedInfo;
msg_new_detailed_info#809db6df answer_msg_id:long bytes:int status:int = MsgDetailedInfo; - Explicit Request to Re-Send Messages
msg_resend_req#7d861a08 msg_ids:Vector long = MsgResendReq;
The remote party immediately responds by re-sending the requested messages […] - Explicit Request to Re-Send Answers
msg_resend_ans_req#8610baeb msg_ids:Vector long = MsgResendReq;
The remote party immediately responds by re-sending answers to the requested messages […] - Message Copies
In some situations, an old message with a msg_id that is no longer valid needs to be re-sent. Then, it is wrapped in a copy container:
msg_copy#e06046b2 orig_message:Message = MessageCopy;
Once received, the message is processed as if the wrapper were not there. However, if it is known for certain that the message orig_message.msg_id was received, then the new message is not processed (while at the same time, it and orig_message.msg_id are acknowledged). The value of orig_message.msg_id must be lower than the container’s msg_id.
Даже помолчим о том, что в msgs_state_info опять торчат уши недоделанного TL (нужен был вектор байт, и в младших двух битах enum, а в старших флаги). Суть в другом. Кто-нибудь понимает, зачем всё это на практике в реальном клиенте нужно?.. С трудом, но можно представить себе какую-то пользу, если человек занимается отладкой, причем в интерактивном режиме — спросить у сервера, что да как. Но здесь описываются запросы в обе стороны.
Отсюда вытекает, что каждая сторона должна не просто шифровать и отправлять сообщения, но и хранить данные о них самих, об ответах на них, причем неизвестное количество времени. Документация ни тайминги, ни практическую применимость этих фич не описывает никак. Что самое удивительное, они действительно используются в коде официальных клиентов! Видимо, им сообщили что-то, что не вошло в открытую документацию. Понять же из кода, зачем, уже не так просто, как в случае TL — это не (сравнительно) логически изолированная часть, а кусок, завязанный на архитектуру приложения, т.е. потребует значительно больше времени на вникание в код приложения.
Пинги и тайминги. Очереди.
Из всего, если вспомнить догадки об архитектуре сервера (распределение запросов по бэкендам), вытекает довольно унылая вещь — несмотря на все гарантии доставки что в TCP (либо данные доставлены, либо Вам сообщат о разрыве, но данные до момента проблемы будут доставлены), что подтверждения в самом MTProto — гарантий нет. Сервер может запросто прое потерять или выкинуть Ваше сообщение, и ничего с этим сделать нельзя, только городить костыли разных видов.
И прежде всего — очереди сообщений. Ну, с одной-то всё было очевидно с самого начала — неподтвержденное сообщение надо хранить и перепосылать. А через какое время? А шут его знает. Возможно, вон те наркоманские сервисные сообщение как-то костылями решают эту проблему, скажем, в Telegram Desktop примерно штуки 4 очереди, им соответствующих (может больше, как уже говорилось, для этого надо вникать в его код и архитектуру более серьезно; при этом мы знаем, что за образец его брать нельзя, энное количество типов из схемы MTProto в нём не используется).
Почему так происходит? Вероятно, программисты сервера не смогли обеспечить надежность внутри кластера, или хотя бы даже буферизацию на фронте-балансировщике, и переложили эту проблему на клиента. От безысходности Василий попытался реализовать альтернативный вариант, с всего двумя очередями, используя алгоритмы из TCP — замеряя RTT до сервера и корректируя размер «окна» (в сообщениях) в зависимости от числа неподтвержденных запросов. То есть, грубая такая эвристика для оценки загруженности сервера — сколько одновременно наших запросов он может жевать и не терять.
Ну то есть, Вы понимаете, да? Если поверх работающего по TCP протокола приходится реализовывать опять TCP — это говорит об очень плохо спроектированном протоколе.
Ах да, почему нужно более одной очереди, и вообще, что это значит для человека, работающего с высокоуровневым API? Смотрите, Вы делаете запрос, сериализуете его, но отправить его немедленно зачастую нельзя. Почему? Потому что ответ будет по msg_id, который есть временная метка, назначение которой лучше отложить на как можно более позже — вдруг сервер отвергнет из-за несовпадения времени у нас и у него (конечно, мы можем сделать костыль, сдвигающий наше время от настоящего к серверному прибавлением дельты, вычисленной из ответов сервера — официальные клиенты так и делают, но этот способ груб и неточен из-за буферизации). Поэтому, когда Вы делаете запрос локальным вызовом функции из библиотеки, сообщение проходит такие стадии:
- Лежит в одной очереди и ожидает шифрования.
- Назначен
msg_idи сообщение легло в другую очередь — возможной перепосылки; отправляем в сокет. - а) Сервер ответил MsgsAck — сообщение доставлено, удаляем из «другой очереди».
б) Или наоборот, что-то ему не понравилось, он ответил badmsg — перепосылаем из «другой очереди»
в) Ничего неизвестно, надо перепослать сообщение из другой очереди — но неизвестно точно, когда. - Сервер наконец ответил
RpcResult— собственно ответом (или ошибкой) — не просто доставлено, но и обработано.
Возможно, частично решить проблему могло бы использование контейнеров. Это когда пачка сообщений упаковывается в одно, и сервер ответил подтверждением на всю сразу, одним msg_id. Но и отвергнет он эту пачку, если что-то пошло не так, тоже всю целиком.
И в этом месте вступают в действие уже не технические соображения. По опыту, мы видели много костылей, а кроме того, сейчас увидим еще примеры плохих советов и архитектуры — в таких условиях, стоит ли доверять и принимать такие решения? Вопрос риторический (конечно, нет).
О чем речь? Если по теме «наркоманские сообщения о сообщениях» еще можно спекулировать возражениями вида «это вы тупые, не поняли наш гениальный замысел!» (так напишите сначала документацию, как полагается у нормальных людей, с rationale и примерами обмена пакетов, тогда и поговорим), то тайминги/таймауты — вопрос сугубо практический и конкретный, тут всё давно известно. А что же нам говорит документация о таймаутах?
A server usually acknowledges the receipt of a message from a client (normally, an RPC query) using an RPC response. If a response is a long time coming, a server may first send a receipt acknowledgment, and somewhat later, the RPC response itself.
A client normally acknowledges the receipt of a message from a server (usually, an RPC response) by adding an acknowledgment to the next RPC query if it is not transmitted too late (if it is generated, say, 60-120 seconds following the receipt of a message from the server). However, if for a long period of time there is no reason to send messages to the server or if there is a large number of unacknowledged messages from the server (say, over 16), the client transmits a stand-alone acknowledgment.
… Перевожу: мы сами не знаем, сколько и как надо, ну давайте прикинем, что пусть будет вот так.
И о пингах:
Ping Messages (PING/PONG)
ping#7abe77ec ping_id:long = Pong;A response is usually returned to the same connection:
pong#347773c5 msg_id:long ping_id:long = Pong;These messages do not require acknowledgments. A pong is transmitted only in response to a ping while a ping can be initiated by either side.
Deferred Connection Closure + PING
ping_delay_disconnect#f3427b8c ping_id:long disconnect_delay:int = Pong;Works like ping. In addition, after this is received, the server starts a timer which will close the current connection disconnect_delay seconds later unless it receives a new message of the same type which automatically resets all previous timers. If the client sends these pings once every 60 seconds, for example, it may set disconnect_delay equal to 75 seconds.
Да вы с ума сошли?! За 60 секунд поезд въедет на станцию, высадит-возьмет пассажиров, и снова потеряет связь в туннеле. За 120 секунд, пока прочухаетесь, он приедет на другую, и соединение скорее всего порвётся. Ну, понятно откуда ноги растут — «слышал звон, да не знает где он», есть алгоритм Нагла и опция TCP_NODELAY, предназначавшаяся для интерактивной работы. Но, простите, её дефолтное значение задержи — 200 миллисекунд. Если вам так уж хочется изобразить нечто похожее и сэкономить на возможной паре пакетов — ну отложите, накрайняк, на 5 секунд, или чему там сейчас равен таймаут сообщения «User is typing…». Но не больше.
И наконец, пинги. То бишь, проверка живости TCP-соединения. Забавно, но примерно 10 лет назад я писал критический текст о мессенджере общаги нашего факультета — там авторы тоже пинговали сервер с клиента, а не наоборот. Но одно дело студенты 3 курса, а другое — международная контора, да?..
Сначала небольшой ликбез. TCP-соединение, при отсутствии обмена пакетами, может жить неделями. Это и хорошо, и плохо, в зависимости от цели. Хорошо, если у Вас было открыто SSH-соединение на сервер, Вы встали из-за компа, перезагрузили роутер по питанию, вернулись на место — сессия через этот сервер не порвалась (ничего не набирали, пакетов не было), удобно. Плохо, если на сервере тысячи клиентов, каждый занимает ресурсы (привет, Постгрес!), и хост клиента, возможно, давно уже перезагрузился — но мы об этом не узнаем.
Системы чатов / IM относятся ко второму случаю по еще одной, дополнительной причине — онлайн-статусы. Если пользователь «отвалился», надо сообщить об этом его собеседникам. Иначе получится ошибка, которую допустили создатели Jabber (и 20 лет исправляли) — пользователь отсоединился, но ему продолжают писать сообщения, считая, что он online (которые еще и полностью терялись в эти несколько минут до обнаружения разрыва). Нет, опция TCP_KEEPALIVE, которую многие не понимающие, как работают таймеры TCP, суют куда попало (ставя дикие значения типа десятков секунд), здесь не поможет — Вам нужно убедиться, что живо не только ядро ОС машины пользователя, но и нормально функционирует, в состоянии ответить, и само приложение (думаете, оно не может зависнуть? Telegram Desktop на Ubuntu 18.04 у меня зависал неоднократно).
Именно поэтому пинговать должен сервер клиента, а не наоборот — если это делает клиент, при разрыве соединения пинг не будет доставлен, цель не достигнута.
А что же мы видим в Telegram? Всё ровно наоборот! Ну т.е. формально, конечно, обе стороны могут пинговать друг друга. На практике же — клиенты пользуются костылём ping_delay_disconnect, который взводит на сервере таймер. Ну простите, это не дело клиента решать, сколько он там хочет жить без пинга. Серверу, исходя из своей нагрузки, видней. Но, конечно, если ресурсов не жалко, то сами себе злобные буратины, и костыль сойдёт…
А как надо было проектировать?
Полагаю, вышеприведенные факты достаточно явственно свидетельствуют о не очень высокой компетенции команды Telegram/ВКонтакте в области транспортного (и ниже) уровня компьютерных сетей и их низкой квалификации в соответствующих вопросах.
Почему же оно такое сложное вышло, и чем архитекторы Telegram могут попытаться возразить? Тем, что они пытались сделать сессию, которая переживает разрывы TCP-соединений, т, е. что не доставили сейчас — доставим позже. Вероятно, еще попытались сделать UDP-транспорт, правда столкнулись со сложностями и забросили (потому и в документации пусто — нечем похвастаться было). Но из-за непонимания того, как работают сети вообще и TCP в частности, где можно на него положиться, а где нужно делать самому (и как), и попытки совместить это с криптографией «одним выстрелом двух зайцев» — получился вот такой кадавр.
А как надо было? Исходя из того, что msg_id является меткой времени, необходимой с криптографической точки зрения для предотвращения replay-атак, ошибкой является навешивание на него функции уникального идентификатора. Поэтому, без кардинального изменения текущей архитектуры (когда формируется поток Updates, это тема высокоуровневого API для другой части этой серии постов), нужно было бы:
- Сервер, держащий TCP-соединение с клиентом, берет на себя ответственность — если вычитал из сокета, изволь подтвердить, обработать или вернуть ошибку, никаких потерь. Тогда подтверждением становится не вектор id’ов, а просто «последний полученный seq_no» — просто число, как в TCP (два числа — свой seq и подтвержденный). Мы ведь в рамках сессии всегда, не так ли?
- Метка времени для предотвращения replay-атак становится отдельным полем, а-ля nonce. Проверяется, но больше ни на что другое не влияет. Хватит и
uint32— если у нас соль меняется не реже каждых полсуток, можно отвести 16 бит на младшие биты целой части текущего времени, остальное — на дробную часть секунды (как и сейчас). - Убирается
msg_idвовсе — с точки зрения различения запросов на бэкендах есть, во-первых, id клиента, во-вторых, id сессии, их и конкатенируйте. Соответственно, в качестве идентификатора запроса достаточно одно лишьseq_no.
Тоже не самый удачный вариант, идентификатором мог бы служить и полный рандом — так уже делается в высокоуровневом API при отправке соообщения, кстати. Лучше было бы вообще переделать архитектуру с относительной на абсолютную, но это тему уже для другой части, не этого поста.
API ?
Та-даам! Итак, продравшись через путь, полный боли и костылей, мы наконец смогли отправлять на сервер любые запросы и получать на них любые ответы, а также получать от сервера апдейты (не в ответ на запрос, а он сам нам присылает, типа PUSH, если кому-то так понятней).
Внимание, сейчас будет единственный в статье пример на Perl! (для тех, кто не знаком с синтаксисом, первый аргумент bless — структура данных объекта, второй — его класс):
2019.10.24 12:00:51 $1 = {
'cb' => 'TeleUpd::__ANON__',
'out' => bless( {
'filter' => bless( {}, 'Telegram::ChannelMessagesFilterEmpty' ),
'channel' => bless( {
'access_hash' => '-6698103710539760874',
'channel_id' => '1380524958'
}, 'Telegram::InputPeerChannel' ),
'pts' => '158503',
'flags' => 0,
'limit' => 0
}, 'Telegram::Updates::GetChannelDifference' ),
'req_id' => '6751291954012037292'
};
2019.10.24 12:00:51 $1 = {
'in' => bless( {
'req_msg_id' => '6751291954012037292',
'result' => bless( {
'pts' => 158508,
'flags' => 3,
'final' => 1,
'new_messages' => [],
'users' => [],
'chats' => [
bless( {
'title' => 'Хулиномика',
'username' => 'hoolinomics',
'flags' => 8288,
'id' => 1380524958,
'access_hash' => '-6698103710539760874',
'broadcast' => 1,
'version' => 0,
'photo' => bless( {
'photo_small' => bless( {
'volume_id' => 246933270,
'file_reference' => '
'secret' => '1854156056801727328',
'local_id' => 228648,
'dc_id' => 2
}, 'Telegram::FileLocation' ),
'photo_big' => bless( {
'dc_id' => 2,
'local_id' => 228650,
'file_reference' => '
'secret' => '1275570353387113110',
'volume_id' => 246933270
}, 'Telegram::FileLocation' )
}, 'Telegram::ChatPhoto' ),
'date' => 1531221081
}, 'Telegram::Channel' )
],
'timeout' => 300,
'other_updates' => [
bless( {
'pts_count' => 0,
'message' => bless( {
'post' => 1,
'id' => 852,
'flags' => 50368,
'views' => 8013,
'entities' => [
bless( {
'length' => 20,
'offset' => 0
}, 'Telegram::MessageEntityBold' ),
bless( {
'length' => 18,
'offset' => 480,
'url' => 'https://alexeymarkov.livejournal.com/[url_вырезан].html'
}, 'Telegram::MessageEntityTextUrl' )
],
'reply_markup' => bless( {
'rows' => [
bless( {
'buttons' => [
bless( {
'text' => '???? 165',
'data' => 'send_reaction_0'
}, 'Telegram::KeyboardButtonCallback' ),
bless( {
'data' => 'send_reaction_1',
'text' => '???? 9'
}, 'Telegram::KeyboardButtonCallback' )
]
}, 'Telegram::KeyboardButtonRow' )
]
}, 'Telegram::ReplyInlineMarkup' ),
'message' => 'А вот и новая книга!
// [текст сообщения вырезан чтоб не нарушать правил Хабра о рекламе]
напечатаю.',
'to_id' => bless( {
'channel_id' => 1380524958
}, 'Telegram::PeerChannel' ),
'date' => 1571724559,
'edit_date' => 1571907562
}, 'Telegram::Message' ),
'pts' => 158508
}, 'Telegram::UpdateEditChannelMessage' ),
bless( {
'pts' => 158508,
'message' => bless( {
'edit_date' => 1571907589,
'to_id' => bless( {
'channel_id' => 1380524958
}, 'Telegram::PeerChannel' ),
'date' => 1571807301,
'message' => 'Почему Вы считаете Facebook плохой компанией? Можете прокомментировать? По-моему, это шикарная компания. Без долгов, с хорошей прибылью, а если решат дивы платить, то и еще могут нехило подорожать.
Для меня ответ совершенно очевиден: потому что Facebook делает ужасный по качеству продукт. Да, у него монопольное положение и да, им пользуется огромное количество людей. Но мир не стоит на месте. Когда-то владельцам Нокии было смешно от первого Айфона. Они думали, что лучше Нокии ничего быть не может и она навсегда останется самым удобным, красивым и твёрдым телефоном - и доля рынка это красноречиво демонстрировала. Теперь им не смешно.
Конечно, рептилоиды сопротивляются напору молодых гениев: так Цукербергом был пожран Whatsapp, потом Instagram. Но всё им не пожрать, Паша Дуров не продаётся!
Так будет и с Фейсбуком. Нельзя всё время делать говно. Кто-то когда-то сделает хороший продукт, куда всё и уйдут.
#соцсети #facebook #акции #рептилоиды',
'reply_markup' => bless( {
'rows' => [
bless( {
'buttons' => [
bless( {
'data' => 'send_reaction_0',
'text' => '???? 452'
}, 'Telegram::KeyboardButtonCallback' ),
bless( {
'text' => '???? 21',
'data' => 'send_reaction_1'
}, 'Telegram::KeyboardButtonCallback' )
]
}, 'Telegram::KeyboardButtonRow' )
]
}, 'Telegram::ReplyInlineMarkup' ),
'entities' => [
bless( {
'length' => 199,
'offset' => 0
}, 'Telegram::MessageEntityBold' ),
bless( {
'length' => 8,
'offset' => 919
}, 'Telegram::MessageEntityHashtag' ),
bless( {
'offset' => 928,
'length' => 9
}, 'Telegram::MessageEntityHashtag' ),
bless( {
'length' => 6,
'offset' => 938
}, 'Telegram::MessageEntityHashtag' ),
bless( {
'length' => 11,
'offset' => 945
}, 'Telegram::MessageEntityHashtag' )
],
'views' => 6964,
'flags' => 50368,
'id' => 854,
'post' => 1
}, 'Telegram::Message' ),
'pts_count' => 0
}, 'Telegram::UpdateEditChannelMessage' ),
bless( {
'message' => bless( {
'reply_markup' => bless( {
'rows' => [
bless( {
'buttons' => [
bless( {
'data' => 'send_reaction_0',
'text' => '???? 213'
}, 'Telegram::KeyboardButtonCallback' ),
bless( {
'data' => 'send_reaction_1',
'text' => '???? 8'
}, 'Telegram::KeyboardButtonCallback' )
]
}, 'Telegram::KeyboardButtonRow' )
]
}, 'Telegram::ReplyInlineMarkup' ),
'views' => 2940,
'entities' => [
bless( {
'length' => 609,
'offset' => 348
}, 'Telegram::MessageEntityItalic' )
],
'flags' => 50368,
'post' => 1,
'id' => 857,
'edit_date' => 1571907636,
'date' => 1571902479,
'to_id' => bless( {
'channel_id' => 1380524958
}, 'Telegram::PeerChannel' ),
'message' => 'Пост про 1С вызвал бурную полемику. Человек 10 (видимо, 1с-программистов) единодушно написали:
// [текст сообщения вырезан чтоб не нарушать правил Хабра о рекламе]
Я бы добавил, что блестящая у 1С дистрибуция, а маркетинг... ну, такое.'
}, 'Telegram::Message' ),
'pts_count' => 0,
'pts' => 158508
}, 'Telegram::UpdateEditChannelMessage' ),
bless( {
'pts' => 158508,
'pts_count' => 0,
'message' => bless( {
'message' => 'Здравствуйте, расскажите, пожалуйста, чем вредит экономике 1С?
// [текст сообщения вырезан чтоб не нарушать правил Хабра о рекламе]
#софт #it #экономика',
'edit_date' => 1571907650,
'date' => 1571893707,
'to_id' => bless( {
'channel_id' => 1380524958
}, 'Telegram::PeerChannel' ),
'flags' => 50368,
'post' => 1,
'id' => 856,
'reply_markup' => bless( {
'rows' => [
bless( {
'buttons' => [
bless( {
'data' => 'send_reaction_0',
'text' => '???? 360'
}, 'Telegram::KeyboardButtonCallback' ),
bless( {
'data' => 'send_reaction_1',
'text' => '???? 32'
}, 'Telegram::KeyboardButtonCallback' )
]
}, 'Telegram::KeyboardButtonRow' )
]
}, 'Telegram::ReplyInlineMarkup' ),
'views' => 4416,
'entities' => [
bless( {
'offset' => 0,
'length' => 64
}, 'Telegram::MessageEntityBold' ),
bless( {
'offset' => 1551,
'length' => 5
}, 'Telegram::MessageEntityHashtag' ),
bless( {
'length' => 3,
'offset' => 1557
}, 'Telegram::MessageEntityHashtag' ),
bless( {
'offset' => 1561,
'length' => 10
}, 'Telegram::MessageEntityHashtag' )
]
}, 'Telegram::Message' )
}, 'Telegram::UpdateEditChannelMessage' )
]
}, 'Telegram::Updates::ChannelDifference' )
}, 'MTProto::RpcResult' )
};
2019.10.24 12:00:51 $1 = {
'in' => bless( {
'update' => bless( {
'user_id' => 2507460,
'status' => bless( {
'was_online' => 1571907651
}, 'Telegram::UserStatusOffline' )
}, 'Telegram::UpdateUserStatus' ),
'date' => 1571907650
}, 'Telegram::UpdateShort' )
};
2019.10.24 12:05:46 $1 = {
'in' => bless( {
'chats' => [],
'date' => 1571907946,
'seq' => 0,
'updates' => [
bless( {
'max_id' => 141719,
'channel_id' => 1295963795
}, 'Telegram::UpdateReadChannelInbox' )
],
'users' => []
}, 'Telegram::Updates' )
};
2019.10.24 13:01:23 $1 = {
'in' => bless( {
'server_salt' => '4914425622822907323',
'unique_id' => '5297282355827493819',
'first_msg_id' => '6751307555044380692'
}, 'MTProto::NewSessionCreated' )
};
2019.10.24 13:24:21 $1 = {
'in' => bless( {
'chats' => [
bless( {
'username' => 'freebsd_ru',
'version' => 0,
'flags' => 5440,
'title' => 'freebsd_ru',
'min' => 1,
'photo' => bless( {
'photo_small' => bless( {
'local_id' => 328733,
'volume_id' => 235140688,
'dc_id' => 2,
'file_reference' => '
'secret' => '4426006807282303416'
}, 'Telegram::FileLocation' ),
'photo_big' => bless( {
'dc_id' => 2,
'file_reference' => '
'volume_id' => 235140688,
'local_id' => 328735,
'secret' => '71251192991540083'
}, 'Telegram::FileLocation' )
}, 'Telegram::ChatPhoto' ),
'date' => 1461248502,
'id' => 1038300508,
'democracy' => 1,
'megagroup' => 1
}, 'Telegram::Channel' )
],
'users' => [
bless( {
'last_name' => 'Panov',
'flags' => 1048646,
'min' => 1,
'id' => 82234609,
'status' => bless( {}, 'Telegram::UserStatusRecently' ),
'first_name' => 'Dima'
}, 'Telegram::User' )
],
'seq' => 0,
'date' => 1571912647,
'updates' => [
bless( {
'pts' => 137596,
'message' => bless( {
'flags' => 256,
'message' => 'Создать джейл с именем покороче ??',
'to_id' => bless( {
'channel_id' => 1038300508
}, 'Telegram::PeerChannel' ),
'id' => 119634,
'date' => 1571912647,
'from_id' => 82234609
}, 'Telegram::Message' ),
'pts_count' => 1
}, 'Telegram::UpdateNewChannelMessage' )
]
}, 'Telegram::Updates' )
};Да, специально не под спойлером — если Вы не вчитались, идите и сделайте это!
Oh, wai~~… на что же это похоже? Что-то очень знакомое… может, это структура данных типичного Web API в JSON, только разве что еще к объектам классы прицепили?..
Так это же получается… Что же это выходит, товарищи?.. Столько усилий — и мы остановились передохнуть там, где Web-программисты только начинают?.. А просто JSON поверх HTTPS был бы не проще?! А что же мы получили в обмен? Стоили ли эти усилия того?
Давайте оценим, что нам дали TL+MTProto, и какие возможны альтернативы. Ну, HTTP, ориентированный на модель «запрос-ответ», подходит плохо, но хотя бы что-то поверх TLS ?
Компактная сериализация. Видя вот эту структуру данных, похожую на JSON, вспоминается, что есть его бинарные варианты. Отметем MsgPack как недостаточно расширяемый, но вот есть, например, CBOR — между прочим, стандарт, описанный в . Примечателен он тем, что в нём определены теги, как механизм расширения, и среди имеются:
- 25 + 256 — замена повторяющихся строк на ссылку на номер строки, такой дешевый метод компрессии
- 26 — сериализованный объект Perl c именем класса и аргументами конструктора
- 27 — сериализованный языконезависимый объект с именем типа и аргументами конструктора
Ну что ж, я попробовал одни и те же данные сериализовать в TL и в CBOR со включенной упаковкой строк и объектов. Результат стал различаться в пользу CBOR где-то от мегабайта:
cborlen=1039673 tl_len=1095092Итак, вывод: есть существенно более простые форматы, не подверженные проблеме сбоя синхронизации или неизвестного идентификатора, с сопоставимой эффективностью.
Быстрое установление соединения. Имеется в виду нулевой RTT после переподключения (когда ключ был уже однажды выработан) — применимо с первого же сообщения MTProto, но при некоторых оговорках — попали в ту же соль, сессия не протухла, etc. Что нам взамен предлагает TLS? Цитата по теме:
При использовании PFS в TLS могут применяться TLS session tickets () для возобновления зашифрованной сессии без повторного согласования ключей и без сохранения ключевой информации на сервере. При открытии первого соединения и создания ключей, сервер шифрует состояние соединения и передает его клиенту (в виде session ticket). Соответственно, при возобновлении соединения клиент посылает session ticket, содержащий в том числе сессионный ключ, обратно серверу. Сам ticket шифруется временным ключом (session ticket key), который хранится на сервере и должен распределяться по всем frontend-серверам, обрабатывающим SSL в кластеризованных решениях.[10]. Таким образом, введение session ticket может нарушать PFS в случае компрометации временных серверных ключей, например, при их длительном хранении (OpenSSL, nginx, Apache по умолчанию хранят их в течение всего времени работы программы; популярные сайты используют ключ в течение нескольких часов, вплоть до суток).
Здесь RTT не нулевой, нужно обменяться как минимум ClientHello и ServerHello, после чего вместе с Finished клиент уже может слать данные. Но тут следует вспомнить, что у нас не Web, с его кучей вновь открываемых соединений, а мессенджер, соединение у которого часто одно и более-менее долгоживущее, относительно коротких запросов на Web-страницы — всё мультиплексируется внутри. То есть, вполне приемлемо, если нам не попался совсем уж плохой перегон метро.
Что-то еще забыл? Пишите в комментах.
To be continued!
Во второй части этой серии постов мы рассмотрим более не технические, а организационные моменты — подходы, идеология, интерфейс, отношение к пользователям и т.д. Опираясь, впрочем, на ту техническую информацию, что была изложена здесь.
В третьей части будет продолжение разбора технической составляющей / опыта разработки. Вы узнаете, в частности:
- продолжение свистопляски с многообразием TL-типов
- неизвестные вещи о каналах и супергруппах
- чем dialogs хуже roster
- об абсолютной vs относительной адресации сообщений
- чем отличается photo от image
- как эмодзи мешают размечать текст курсивом
и другие костыли! Stay tuned!
Источник: habr.com
