

И снова здравствуйте! Заголовок статьи говорит сам о себе. В преддверии старта курса предлагаем разобраться в том, кто же такие дата-инженеры. В статье очень много полезных ссылок. Приятного прочтения.

Простое руководство о том, как поймать волну Data Engineering и не дать ей затянуть вас в пучину.
Складывается впечатление, что в наши дни каждый хочет стать дата-саентистом (Data Scientist). Но как насчет Data Engineering (инжиниринга данных)? По сути, это своего рода гибрид дата-аналитика и дата-саентиста; дата-инженер обычно отвечает за управление рабочими процессами, конвейерами обработки и ETL-процессами. Ввиду важности этих функций, в настоящее время это очередной популярный профессиональный жаргонизм, который активно набирает обороты.
Высокая зарплата и огромный спрос — это лишь малая часть того, что делает эту работу чрезвычайно привлекательной! Если вы хотите пополнить ряды героев, никогда не поздно начать учиться. В этом посте я собрал всю необходимую информацию, чтобы помочь вам сделать первые шаги.
Итак, начнем!
Что такое Data Engineering?
Честно говоря, нет лучшего объяснения, чем это:
«Ученый может открыть новую звезду, но не может ее создать. Ему придется просить инженера сделать это за него.»
–Гордон Линдсей Глегг
Таким образом, роль дата-инженера достаточно весома.
Из названия следует, что инженерия данных связана с данными, а именно с их доставкой, хранением и обработкой. Соответственно, основная задача инженеров — обеспечить надежную инфраструктуру для данных. Если мы посмотрим на ИИ-иерархию потребностей, инженерия данных занимает первые 2–3 этапа: сбор, перемещение и хранение, подготовка данных.
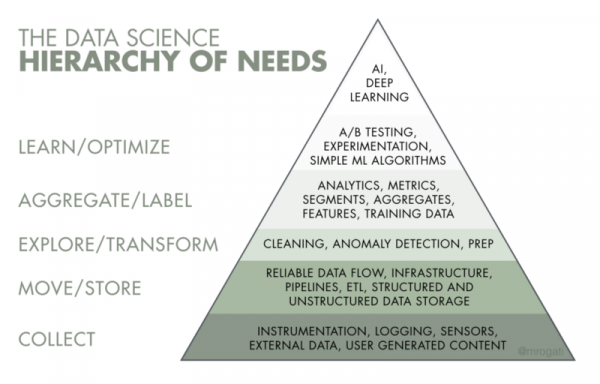
Чем занимается инженер данных?
С появлением больших данных сфера ответственности резко изменилась. Если раньше эти эксперты писали большие SQL-запросы и перегоняли данные с помощью таких инструментов, как Informatica ETL, Pentaho ETL, Talend, то теперь требования к дата-инженерам повысились.
Большинство компаний с открытыми вакансиями на должность дата-инженера предъявляют следующие требования:
- Отличное знание SQL и Python.
- Опыт работы с облачными платформами, в частности Amazon Web Services.
- Предпочтительно знание Java/Scala.
- Хорошее понимание баз данных SQL и NoSQL (моделирование данных, хранение данных).
Имейте в виду, это только самое необходимое. Из этого списка можно предположить, что дата-инженеры являются специалистами в области разработки программного обеспечения и бекенда.
Например, если компания начинает генерировать большой объем данных из разных источников, ваша задача как дата-инженера состоит в том, чтобы организовать сбор информации, ее обработку и хранение.
Список используемых в этом случае инструментов может отличаться, все зависит от объема этих данных, скорости их поступления и неоднородности. Большинство компаний вообще не сталкиваются с большими данными, поэтому в качестве централизованного хранилища, так называемого хранилища данных, можно использовать базу данных SQL (PostgreSQL, MySQL и т. д.) с небольшим набором скриптов, которые направляют данные в хранилище.
IT-гиганты, такие как Google, Amazon, Facebook или Dropbox, предъявляют более высокие требования: знание Python, Java или Scala.
- Опыт работы с большими данными: Hadoop, Spark, Kafka.
- Знание алгоритмов и структур данных.
- Понимание основ распределенных систем.
- Опыт работы с инструментами визуализации данных, такими как Tableau или ElasticSearch, будет большим плюсом.
То есть наблюдается явное смещение в сторону больших данных, а именно в их обработке при высоких нагрузках. У этих компаний повышенные требования к отказоустойчивости системы.
Дата-инженеры Vs. дата-саентисты

Ладно, это было простое и забавное сравнение (ничего личного), но на самом деле все намного сложнее.
Во-первых, вы должны знать, что существует достаточно много неясности в разграничении ролей и навыков дата-саентиста и дата-инженера. То есть, вы легко можете быть озадачены тем, какие все-таки навыки необходимы для успешного дата-инженера. Конечно, есть определенные навыки, которые накладываются на обе роли. Но также есть целый ряд диаметрально противоположных навыков.
Наука о данных — это серьезное дело, но мы движется к миру с функциональной дата саенс, где практикующие способны делать свою собственную аналитику. Чтобы задействовать конвейеры данных и интегрированные структуры данных, вам нужны инженеры данных, а не ученые.
Является ли дата-инженер более востребованным, чем дата-саентист?
— Да, потому что прежде чем вы сможете приготовить морковный пирог, вам нужно сначала собрать, очистить и запастись морковью!
Дата-инженер разбирается в программировании лучше, чем любой дата-саентист, но когда дело доходит до статистики, все с точностью до наоборот.
Но вот преимущество дата-инженера:
без него/нее ценность модели-прототипа, чаще всего состоящей из фрагмента кода ужасного качества в файле Python, полученной от дата-саентиста и каким-то образом дающей результат, стремится к нулю.
Без дата-инженера этот код никогда не станет проектом, и никакая бизнес-проблема не будет эффективно решена. Инженер данных пытается превратить это все в продукт.
Основные сведения, которые должен знать дата-инженер

Итак, если эта работа пробуждает в вас свет и вы полны энтузиазма — вы способны научиться этому, вы можете овладеть всеми необходимыми навыками и стать настоящей рок-звездой в области разработки данных. И, да, вы можете осуществить это даже без навыков программирования или других технических знаний. Это сложно, но возможно!
Каковы первые шаги?
Вы должны иметь общее представление о том, что есть что.
Прежде всего, Data Engineering относится к информатике. Конкретне — вы должны понимать эффективные алгоритмы и структуры данных. Во-вторых, поскольку дата-инженеры работают с данными, необходимо понимание принципов работы баз данных и структур, лежащих в их основе.
Например, обычные B-tree SQL базы данных основаны на структуре данных B-Tree, а также, в современных распределенных репозиториях, LSM-Tree и других модификациях хеш-таблиц.
* Эти шаги основаны на замечательной статье . Итак, если вы знаете русский язык, поддержите этого автора и прочитайте .
1. Алгоритмы и структуры данных
Использование правильной структуры данных может значительно улучшить производительность алгоритма. В идеале, мы все должны изучать структуры данных и алгоритмы в наших школах, но это редко когда-либо освещается. Во всяком случае, ознакомится никогда не поздно.
Итак, вот мои любимые бесплатные курсы для изучения структур данных и алгоритмов:
Плюс не забывайте о классической работе над алгоритмами Томаса Кормена — . Это идеальный справочник, когда вам нужно освежить свою память.
- Чтобы улучшить свои навыки, используйте .
Вы также можете погрузиться в мир баз данных с помощью потрясающих видеороликов Университета Карнеги-Меллона на Youtube:
- .
- .
2. Изучение SQL
Вся наша жизнь — это данные. И для того, чтобы извлечь эти данные из базы данных, вам нужно «говорить» с ними на одном языке.
SQL (Structured Query Language — язык структурированных запросов) является языком общения в области данных. Независимо от того, что кто-то говорит, SQL жил, жив и будет жить еще очень долго.
Если вы долгое время находились в разработке, вы, вероятно, заметили, что слухи о скорой смерти SQL появляются периодически. Язык был разработан в начале 70-х годов и до сих пор пользуется огромной популярностью среди аналитиков, разработчиков и просто энтузиастов.
Без знания SQL в инженерии данных делать нечего, так как вам неизбежно придется создавать запросы для извлечения данных. Все современные хранилища больших данных поддерживают SQL:
- Amazon Redshift
- HP Vertica
- Oracle
- SQL Server
… и множество других.
Для анализа большого слоя данных, хранящихся в распределенных системах, таких как HDFS, были изобретены механизмы SQL: Apache Hive, Impala и т. д. Видите, он не собирается никуда уходить.
Как выучить SQL? Просто делай это на практике.
Для этого я бы порекомендовал ознакомиться с отличным учебником, который, кстати, бесплатный, от .
Отличительной особенностью этих курсов является наличие интерактивной среды, в которой вы можете писать и выполнять SQL-запросы прямо в браузере. Ресурс не будет лишним. И вы можете применить эти знания в в разделе Базы данных.
3. Программирование на Python и Java/Scala
Почему стоит изучать язык программирования Python, я уже писал в статье . Что касается Java и Scala, большинство инструментов для хранения и обработки огромных объемов данных написаны на этих языках. Например:
- Apache Kafka (Scala)
- Hadoop, HDFS (Java)
- Apache Spark (Scala)
- Apache Cassandra (Java)
- HBase (Java)
- Apache Hive (Java)
Чтобы понять, как работают эти инструменты, вам нужно знать языки, на которых они написаны. Функциональный подход Scala позволяет эффективно решать задачи параллельной обработки данных. Python, к сожалению, не может похвастаться скоростью и параллельной обработкой. В целом, знание нескольких языков и парадигм программирования хорошо влияет на широту подходов к решению проблем.
Чтобы погрузиться в язык Scala, вы можете прочитать от автора языка. Также компания Twitter опубликовала хорошее вводное руководство — .
Что касается Python, я считаю лучшей книгой среднего уровня.
4. Инструменты для работы с большими данными
Вот список самых популярных инструментов в мире больших данных:
- Apache Spark
- Apache Kafka
- Apache Hadoop (HDFS, HBase, Hive)
- Apache Cassandra
Больше информации о построении больших блоков данных вы можете найти в этой удивительной . Самые популярные инструменты — Spark и Kafka. Их определенно стоит изучить, желательно понять, как они работают изнутри. Jay Kreps (соавтор Kafka) в 2013 году опубликовал монументальную работу , кстати, основные идеи из этого талмуда были использованы для создания Apache Kafka.
- Введением в Hadoop может служить .
- Наиболее полное руководство по Apache Spark для меня — .
5. Облачные платформы
Знание хотя бы одной облачной платформы находится в списке базовых требований, предъявляемым к соискателям на должность дата-инженера. Работодатели отдают предпочтение Amazon Web Services, на втором месте — облачная платформа Google, и замыкает тройку лидеров Microsoft Azure.
Вы должны хорошо ориентироваться в Amazon EC2, AWS Lambda, Amazon S3, DynamoDB.
6. Распределенные системы
Работа с большими данными подразумевает наличие кластеров независимо работающих компьютеров, связь между которыми осуществляется по сети. Чем больше кластер, тем больше вероятность отказа его узлов-членов. Чтобы стать крутым экспертом в области данных, вам необходимо вникнуть в проблемы и существующие решения для распределенных систем. Эта область старая и сложная.
Эндрю Таненбаум считается пионером в этой области. Для тех, кто не боится теории, я рекомендую его книгу , для начинающих она может показаться сложной, но это действительно поможет вам отточить свои навыки.
Я считаю лучшей вводной книгой. Кстати, у Мартина есть замечательный . Его работа поможет систематизировать знания о построении современной инфраструктуры для хранения и обработки больших данных.
Для тех, кто любит смотреть видео, на Youtube есть курс .
7. Конвейеры данных
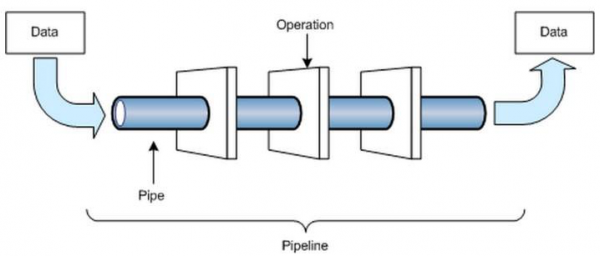
Конвейеры данных — это то, без чего вы не можете жить в качестве дата-инженера.
Большую часть времени дата-инженер строит так называемую пайплайн дату, то есть создает процесс доставки данных из одного места в другое. Это могут быть пользовательские сценарии, которые идут к API внешнего сервиса или делают SQL-запрос, дополняют данные и помещают их в централизованное хранилище (хранилище данных) или хранилище неструктурированных данных (озера данных).
Подводя итог: основной чеклист дата-инженера

Подытожим — необходимо хорошее понимание следующего:
- Информационные системы;
- Разработка программного обеспечения (Agile, DevOps, Design Techniques, SOA);
- Распределенные системы и параллельное программирование;
- Основы баз данных — планирование, проектирование, эксплуатация и устранение неисправностей;
- Проектирование экспериментов — A/B-тесты для доказательства концепций, определения надежности, производительности систем, а также для разработки надежных путей для оперативного предоставления хороших решений.
Это лишь несколько требований для того, чтобы стать инженером данных, поэтому изучите и разберитесь с системами данных, информационными системами, непрерывной доставкой/ развертыванием/интеграцией, языками программирования и другими темами по информатике (не во всех предметных областях).
И, наконец, последнее, но очень важное, что я хочу сказать.
Путь становления Data Engineering не так прост, как может показаться. Он не прощает, фрустрирует, и вы должны быть готовы к этому. Некоторые моменты в этом путешествии могут подтолкнуть вас все бросить. Но это настоящий труд и учебный процесс.
Просто не приукрашивайте его с самого начала. Весь смысл путешествия в том, чтобы узнать как можно больше и быть готовым к новым вызовам.
Вот отличная картинка, с которой я столкнулся, которая хорошо иллюстрирует этот момент:
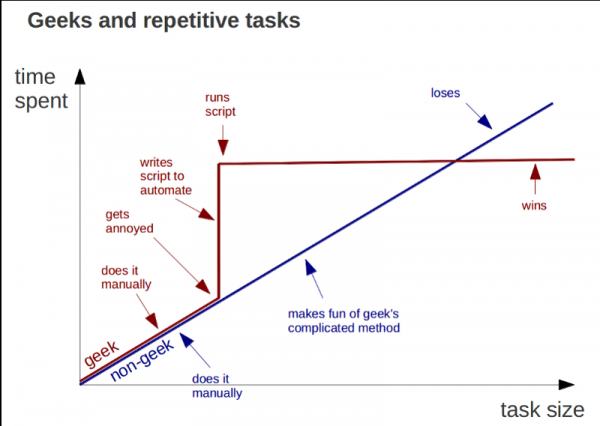
И да, не забудьте избегать выгорания и отдыхать. Это тоже очень важно. Удачи!
Как вам статья, друзья? Приглашаем на , который состоится уже сегодня в 20.00. В рамках вебинара обсудим, как построить эффективную и масштабируемую систему обработки данных для небольшой компании или стартапа с минимальными затратами. В качестве практики познакомимся с инструментами обработки данных Google Cloud. До встречи!
Источник: habr.com
