

Привет, Хабр! Приглашаем Data Engineer’ов и специалистов по Machine Learning на бесплатный Demo-урок . А также мы публикуем статью Luca Monno — Head of Financial Analytics at CDP SpA.
Одним из наиболее полезных и простых методов машинного обучения является Ensemble Learning. Ensemble Learning – это метод, лежащий в основе XGBoost, Бэггинга, Случайного Леса и многих других алгоритмов.
На Towards Data Science есть много классных статей, но я выбрал две истории ( и ), которые мне больше всего понравились. Так зачем же писать еще одну статью про EL? Потому что я хочу показать вам, как это работает на простом примере, который дал мне понять, что здесь нет никакого волшебства.
Когда я впервые увидел EL в действии (в работе с несколькими очень простыми регрессионными моделями) я не мог поверить своим глазам, и до сих пор вспоминаю профессора, который научил меня этому методу.
У меня было две разных модели (два слабых обучающих алгоритма) с показателями out-of-sample R² равными 0,90 и 0,93 соответственно. Перед тем, как посмотреть на результат, я думал, что получу R² где-то между двумя изначальными значениями. Другими словами, я считал, что EL можно использовать, чтобы модель работала не так плохо, как самая худшая, но и не настолько хорошо, как могла бы работать лучшая модель.
К моему величайшему удивлению, результаты простого усреднения предсказаний дали R² в 0,95.
Сперва я начал искать ошибку, но потом подумал, что здесь может скрываться какая-то магия!
Что такое Ensemble Learning
С помощью EL можно объединить предсказания двух и более моделей для получения более надежной и производительной модели. Существует множество методологий для работы с ансамблями моделей. Здесь я затрону две самые полезные, чтобы дать общее представление.
С помощью регрессии можно усреднить показатели имеющихся моделей.
С помощью классификации можно давать возможность моделям выбирать лейблы. Лейбл, который выбирался чаще всего – тот, что будет выбран новой моделью.
Почему EL работает лучше
Основная причина, по которой EL работает лучше, заключается в том, что у каждого предсказания есть ошибка (знаем мы это из теории вероятности), объединение двух предсказаний может помочь уменьшить ошибку, и, соответственно, улучшить показатели производительности (RMSE, R² и т.д.).
На следующей диаграмме видно, как два слабых алгоритма работают с набором данных. Первый алгоритм имеет больший угловой коэффициент, чем нужно, тогда как у второго он почти равен нулю (возможно, из-за чрезмерной регуляризации). Но ensemble показывает результат куда лучше.
Если смотреть на показатель R², то у первого и второго обучающего алгоритма он будет равен -0.01¹, 0.22, соответственно, тогда как у ансамбля он будет равен 0.73.
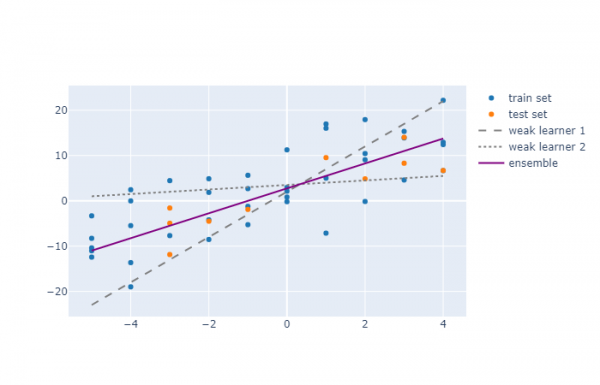
Есть множество причин, по которым алгоритм может оказаться плохой моделью даже на таком базовом примере, как этот: может быть, вы решили использовать регуляризацию, чтобы избежать переобучения, или решили не исключать некоторые аномалии, а может использовали полиномиальную регрессию и подобрали неверную степень (например, использовали полином второй степени, а на тестовых данных видна явная асимметрия, для которой лучше подошла бы третья степень).
Когда EL работает лучше
Давайте рассмотрим два обучающих алгоритма, работающих с одинаковыми данными.
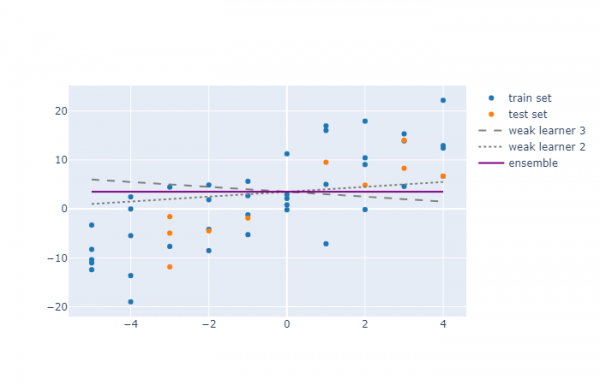
Здесь видно, что объединение двух моделей не сильно улучшило производительность. Изначально для двух обучающих алгоритмов показатели R² был равны -0,37 и 0,22, соответственно, а для ансамбля получилось -0,04. То есть модель EL получила среднее значение показателей.
Однако между этими двумя примерами есть большая разница: в первом примере ошибки моделей были отрицательно коррелированы, а во втором – положительно (коэффициенты трех моделей не оценивались, а просто были выбраны автором в качестве примера.)
Следовательно, Ensemble Learning может быть использовано для улучшения баланса смещения/дисперсии в любых случаях, но, когда ошибки моделей не коррелированы положительно, использование EL может привести к повышению производительности.
Однородные и разнородные модели
Очень часто EL используется на однородных моделях (как в данном примере или в случайном лесу), но на самом деле вы можете комбинировать разные модели (линейную регрессию + нейронную сеть + XGBoost) с различными наборами объясняющих переменных. Скорее всего это приведет к некоррелированным ошибкам и повышению производительности.
Сравнение с диверсификацией портфеля
EL работает по аналогии с диверсификацией в теории портфеля, но тем лучше для нас.
При диверсификации вы пытаетесь уменьшить дисперсию ваших показателей, инвестируя в некоррелированные акции. Хорошо диверсифицированный портфель акций будет выдавать показатель лучше, чем наихудшая отдельная акция, но никогда не лучше, чем самая лучшая.
Цитируя Уоррена Баффета:
«Диверсификация – это защита от невежества, для того, кто не знает, что он делает, она [диверсификация] имеет очень мало смысла.»
В машинном обучении EL помогает уменьшить дисперсию вашей модели, но это может привести к созданию модели с общей производительностью лучше, чем лучшая изначальная модель.
Подведем итоги
Объединение нескольких моделей в одну – это относительно простой метод, который может привести к решению проблемы смещения дисперсии и повышению производительности.
Если у вас есть две или более модели, которые хорошо работают, не выбирайте между ними: используйте их все (но с осторожностью)!
Интересно развиваться в данном направлении? Запишитесь на бесплатный Demo-урок и участвуйте в — Machine Learning Engineer в Mail.ru Group.
Источник: habr.com
