

Инженер — в переводе с латыни — вдохновенный.
Инженер может всё. (с) Р.Дизель.
Эпиграфы.

Или история о том, зачем администратору баз данных вспоминать свое программистское прошлое.
Предисловие
Все имена изменены. Совпадения случайны. Материал представляет собой исключительно личное мнение автора.
Disclaimer of warranties: в планируемом цикле статей не будет подробного и точного описания используемых таблиц и скриптов. Материалы не получится сразу использовать «AS IS».
Во-первых, по причине большого объема материала,
во-вторых по причине заточенности с продакшн базой реального заказчика.
Поэтому в статьях будут приведены только идеи и описания в самом общем виде.
Может быть в будущем система дорастет до уровня выкладывания на GitHub, а может быть и нет. Время — покажет.
Начало истории- «».
Что получилось в результате, в самых общих чертах- «»
Зачем всё это мне?
Ну, во-первых, чтобы самому не забыть, вспоминая на пенсии славные денечки.
Во-вторых, чтобы систематизировать написанное. Ибо уже сам, иногда начинаю путаться и забывать отдельные части.
Ну и самое главное — вдруг может кому-то пригодится и поможет не изобретать велосипед и не собирать грабли. Другими словами, улучшить свою карму (не хабровскую). Ибо, самое ценное в этом мире это идеи. Главное найти идею. А реализовать идею в реальность это уже вопрос чисто технический.
Итак, начнем, потихоньку…
Постановка задачи.
Имеется:
База данных PostgreSQL(10.5), смешанного типа нагрузки (OLTP+DSS), средней-малой загруженности, расположенной в облаке AWS.
Мониторинг базы данных отсутствует, мониторинг инфраструктуры представлен в виде штатные средства AWS в минимальной конфигурации.
Требуется:
Мониторить производительность и состояние базы данных, находить и иметь начальную информацию для оптимизации тяжелых запросы к БД.
Краткое предисловие или анализ вариантов решения
Для начала попробуем разобрать варианты решения задачи с точки зрения сравнительного анализа выгод и неприятностей для инженера, а пользой и убытками менеджмента пусть занимаются те, кому положено по штатному расписанию.
Вариант 1- «Working on demand»
Оставляем все как есть. Если заказчика не устраивает что-то в работоспособности, производительности базы данных или приложения он известит инженеров DBA по e-mail или создав инцидент в тикетнице.
Инженер, получив оповещение, разберется в проблеме, предложит решение или отложит проблему в долгий ящик, надеясь, что все само собой рассосется, да и все равно, скоро всё забудется.
Пряники и пышки , синяки и шишкиПряники и пышки:
1. Ничего лишнего делать не надо
2. Всегда есть возможность отмазаться и сачкануть.
3. Куча времени, которое можно потратить по собственному усмотрению.
Синяки и шишки:
1. Рано или поздно заказчик задумается о сущности бытия и вселенской справедливости в этом мире и в очередной раз задаст себе вопрос — за, что я им плачу свои деньги? Последствие всегда одно — вопрос только когда заказчик поскучнеет и махнет рукой на прощанье. И кормушка опустеет. Это печально.
2. Развитие инженера — ноль.
3. Сложности планирования работы и загрузки
Вариант 2- «Танцуем с бубнами, впариваем и обуваем»
Пункт1-Зачем нам система мониторинга, мы будем все получать запросами. Запускам кучу всяких запросов к словарю данных и динамическим представлениям, включаем всякие счетчики, сводим все в таблицы, периодически как-бы анализируем списки и таблицы. В результате имеем красивые или не очень графики, таблицы, отчеты. Главное — что бы побольше, побольше.
Пункт2-Генерируем активность-запускаем анализ всего этого.
Пункт3-Готовим некий документ, называем сей документ, просто — «как нам обустроить базу данных».
Пункт4-Заказчик, видя все это великолепие графиков и цифр пребывает в детской наивной уверенности — вот теперь то у нас все заработает, скоро. И, легко и безболезненно расстается со своими денежными ресурсами. Менеджмент также уверен — инженеры у нас работают ого-го. Загрузка на максимуме.
Пункт5-Регулярно повторить Пункт 1.
Пряники и пышки , синяки и шишкиПряники и пышки:
1. Жизнь менеджеров и инженеров — проста, предсказуема и наполнена активностью. Всё жужжит, все заняты.
2. Жизнь заказчика тоже неплоха — он всегда уверен, что нужно вот чуть-чуть потерпеть и всё наладится. Не налаживается, ну, что ж — это мир несправедлив, в следующей жизни — повезет.
Синяки и шишки:
1. Рано или поздно, но найдется более шустрый поставщик аналогичной услуги, который будет делать тоже самое, но чуть дешевле. А если в результат тот же самый, зачем платить больше. Что опять-таки приведет к исчезновению кормушки.
2. Это скучно. Как скучна любая малоосмысленная активность.
3. Как и в предыдущем варианте — развития никакого. Но для инженера минус в том, что в отличии от первого варианта тут нужно постоянно генерировать ИБД. А это отнимает время. Которое можно потратить с пользой для себя любимого. Ибо сам о себе не позаботишься, всем на тебя по барабану.
Вариант 3-Не нужно придумывать велосипед, нужно его купит и кататься.
Инженеры других компаний не зря едят пиццу запивая пивом (эх, славные времена Питер 90-х). Давайте использовать мониторинговые системы, которые сделаны, отлажены и работают, и приносят вообще говоря пользу (ну как минимум их создателям).
Пряники и пышки , синяки и шишкиПряники и пышки:
1. Не нужно тратить время на придумывание того, что и так придумано. Бери и пользуйся.
2. Системы мониторинга пишут не дураки и они конечно же полезны.
3. Работающие системы мониторинга как правило дают полезную отфильтрованную информацию.
Синяки и шишки:
1. Инженер в данном случае не инженер, а всего лишь пользователь чужого продукта.Или юзер.
2. Заказчика надо убедить в необходимости купить что-то в чем он разбираться вообще говоря не хочет, да и не должен и вообще бюджет на год утвержден и меняться не будет. Потом нужно выделить отдельный ресурс, настроить под конкретную систему. Т.е. сначала нужно платит, платить и еще раз заплатить. А заказчик скуп. Это норма этой жизни.
Что же делать- Чернышевский? Твой вопрос весьма уместен. (с)
В данном конкретном случае и сложившейся ситуации можно поступить чуть-чуть по-другому — а давайте сделаем свою собственную систему мониторинга.

Ну не систему конечно, в полном смысле слова, это слишком громко сказано и самонадеянно, но хоть как-то облегчить себе задачу и собрать побольше информации для решения инцидентов производительности. Чтобы не оказываться в ситуации — «пойди туда не знаю куда, найди то, не знаю что».
Какие же плюсы и минусы этого варианта:
Плюсы:
1. Это интересно. Ну как минимум интереснее, чем постоянные «shrink datafile, alter tablespace, etc.»
2. Это новые скилы и новое развитие. Что в перспективе рано или поздно даст заслуженные пряники и пышки.
Минусы:
1. Придется работать. Работать много.
2. Придется регулярно объяснять смысл и перспективы всей активности.
3. Чем-то придется пожертвовать, ибо единственный доступный инженеру ресурс-время — ограничен Вселенной.
4. Самое страшное и самое неприятное — в результате может получится фигня типа «Не мышонок, не лягушка, а неведома зверушка».
Кто не рискует-то не пьет шампанское.
Итак — начинается самое интересное.
Общая идея — схематически
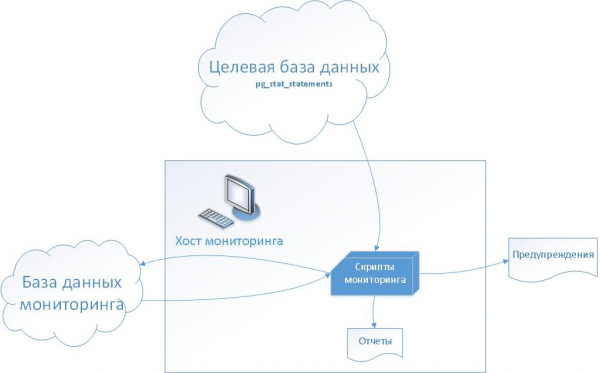
(Иллюстрация взята из статьи «»)
Пояснение:
- В целевой базе устанавливается стандартное расширение PostgreSQL — “pg_stat_statements”.
- В базе данных мониторинга создаем набор сервисных таблиц для хранения истории pg_stat_statements на начальном этапе и для настройки метрик и мониторинга в дальнейшем
- На хосте мониторинга создаем набор bash-скриптов, в том, числе для генерации инцидентов в тикетной системе.
Сервисные таблицы
Для начала схематично-упрощенная ERD, что же получилось в итоге:
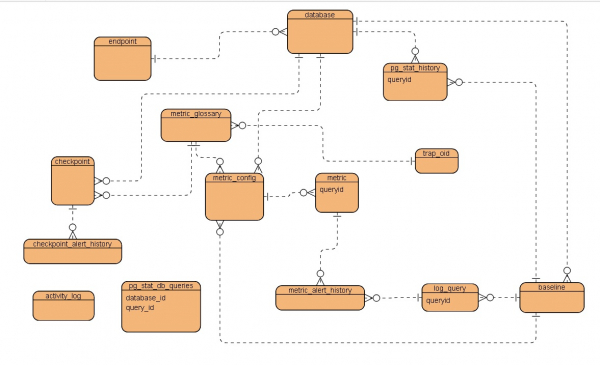
Краткое описание таблицendpoint — хост, точка подключения к инстансу
database — параметры базы данных
pg_stat_history — историческая таблица для хранения временных снимков представления pg_stat_statements целевой базы данных
metric_glossary — словарь метрик производительности
metric_config — конфигурация отдельных метрик
metric — конкретная метрика для запроса который мониторится
metric_alert_history — история предупреждений производительности
log_query — служебная таблица для хранения разобранных записей из log файла PostgreSQL загружаеммого с AWS
baseline — параметры временного периоды используемого в качестве базового
checkpoint — конфигурация метрик проверки состояния базы данных
checkpoint_alert_history — история предупреждений метрик проверки состояния базы данных
pg_stat_db_queries — служебная таблица активных запросов
activity_log — служебная таблица журнала активности
trap_oid — служебная таблица конфигурации trap
Этап 1 — собираем статистическую информацию о производительности и получаем отчеты
Для хранения статистической информации служит таблица pg_stat_history
Структура таблицы pg_stat_history
Table "public.pg_stat_history"
Column | Type | Modifiers
---------------------+-----------------------------+-------------------------------------------
id | integer | not null default nextval('pg_stat_history_id_seq'::regclass)
snapshot_timestamp | timestamp without time zone |
database_id | integer |
dbid | oid |
userid | oid |
queryid | bigint |
query | text |
calls | bigint |
total_time | double precision |
min_time | double precision |
max_time | double precision |
mean_time | double precision |
stddev_time | double precision |
rows | bigint |
shared_blks_hit | bigint |
shared_blks_read | bigint |
shared_blks_dirtied | bigint |
shared_blks_written | bigint |
local_blks_hit | bigint |
local_blks_read | bigint |
local_blks_dirtied | bigint |
local_blks_written | bigint |
temp_blks_read | bigint |
temp_blks_written | bigint |
blk_read_time | double precision |
blk_write_time | double precision |
baseline_id | integer |
Indexes:
"pg_stat_history_pkey" PRIMARY KEY, btree (id)
"database_idx" btree (database_id)
"queryid_idx" btree (queryid)
"snapshot_timestamp_idx" btree (snapshot_timestamp)
Foreign-key constraints:
"database_id_fk" FOREIGN KEY (database_id) REFERENCES database(id) ON DELETE CASCADEКак видно, таблица представляет собой всего лишь кумулятивные данные представления pg_stat_statements в целевой базе данных.
Использование этой таблицы очень простое
pg_stat_history будет представлять собой накопленную статистику выполнения запросов за каждый час. В начале каждого часа, после заполнения таблицы, статистика pg_stat_statements сбрасывается с помощью pg_stat_statements_reset().
Примечание: cтатистика собирается для запросов, с длительностью выполнения более 1 секунды.
Заполнение таблицы pg_stat_history
--pg_stat_history.sql
CREATE OR REPLACE FUNCTION pg_stat_history( ) RETURNS boolean AS $$
DECLARE
endpoint_rec record ;
database_rec record ;
pg_stat_snapshot record ;
current_snapshot_timestamp timestamp without time zone;
BEGIN
current_snapshot_timestamp = date_trunc('minute',now());
FOR endpoint_rec IN SELECT * FROM endpoint
LOOP
FOR database_rec IN SELECT * FROM database WHERE endpoint_id = endpoint_rec.id
LOOP
RAISE NOTICE 'NEW SHAPSHOT IS CREATING';
--Connect to the target DB
EXECUTE 'SELECT dblink_connect(''LINK1'',''host='||endpoint_rec.host||' dbname='||database_rec.name||' user=USER password=PASSWORD '')';
RAISE NOTICE 'host % and dbname % ',endpoint_rec.host,database_rec.name;
RAISE NOTICE 'Creating snapshot of pg_stat_statements for database %',database_rec.name;
SELECT
*
INTO
pg_stat_snapshot
FROM dblink('LINK1',
'SELECT
dbid , SUM(calls),SUM(total_time),SUM(rows) ,SUM(shared_blks_hit) ,SUM(shared_blks_read) ,SUM(shared_blks_dirtied) ,SUM(shared_blks_written) ,
SUM(local_blks_hit) , SUM(local_blks_read) , SUM(local_blks_dirtied) , SUM(local_blks_written) , SUM(temp_blks_read) , SUM(temp_blks_written) , SUM(blk_read_time) , SUM(blk_write_time)
FROM pg_stat_statements WHERE dbid=(SELECT oid from pg_database where datname=current_database() )
GROUP BY dbid
'
)
AS t
( dbid oid , calls bigint ,
total_time double precision ,
rows bigint , shared_blks_hit bigint , shared_blks_read bigint ,shared_blks_dirtied bigint ,shared_blks_written bigint ,
local_blks_hit bigint ,local_blks_read bigint , local_blks_dirtied bigint ,local_blks_written bigint ,
temp_blks_read bigint ,temp_blks_written bigint ,
blk_read_time double precision , blk_write_time double precision
);
INSERT INTO pg_stat_history
(
snapshot_timestamp ,database_id ,
dbid , calls ,total_time ,
rows ,shared_blks_hit ,shared_blks_read ,shared_blks_dirtied ,shared_blks_written ,local_blks_hit ,
local_blks_read,local_blks_dirtied,local_blks_written,temp_blks_read,temp_blks_written,
blk_read_time, blk_write_time
)
VALUES
(
current_snapshot_timestamp ,
database_rec.id ,
pg_stat_snapshot.dbid ,pg_stat_snapshot.calls,
pg_stat_snapshot.total_time,
pg_stat_snapshot.rows ,pg_stat_snapshot.shared_blks_hit ,pg_stat_snapshot.shared_blks_read ,pg_stat_snapshot.shared_blks_dirtied ,pg_stat_snapshot.shared_blks_written ,
pg_stat_snapshot.local_blks_hit , pg_stat_snapshot.local_blks_read , pg_stat_snapshot.local_blks_dirtied , pg_stat_snapshot.local_blks_written ,
pg_stat_snapshot.temp_blks_read , pg_stat_snapshot.temp_blks_written , pg_stat_snapshot.blk_read_time , pg_stat_snapshot.blk_write_time
);
RAISE NOTICE 'Creating snapshot of pg_stat_statements for queries with min_time more than 1000ms';
FOR pg_stat_snapshot IN
--All queries with max_time greater than 1000 ms
SELECT
*
FROM dblink('LINK1',
'SELECT
dbid , userid ,queryid,query,calls,total_time,min_time ,max_time,mean_time, stddev_time ,rows ,shared_blks_hit ,
shared_blks_read ,shared_blks_dirtied ,shared_blks_written ,
local_blks_hit , local_blks_read , local_blks_dirtied ,
local_blks_written , temp_blks_read , temp_blks_written , blk_read_time ,
blk_write_time
FROM pg_stat_statements
WHERE dbid=(SELECT oid from pg_database where datname=current_database() AND min_time >= 1000 )
'
)
AS t
( dbid oid , userid oid , queryid bigint ,query text , calls bigint ,
total_time double precision ,min_time double precision ,max_time double precision , mean_time double precision , stddev_time double precision ,
rows bigint , shared_blks_hit bigint , shared_blks_read bigint ,shared_blks_dirtied bigint ,shared_blks_written bigint ,
local_blks_hit bigint ,local_blks_read bigint , local_blks_dirtied bigint ,local_blks_written bigint ,
temp_blks_read bigint ,temp_blks_written bigint ,
blk_read_time double precision , blk_write_time double precision
)
LOOP
INSERT INTO pg_stat_history
(
snapshot_timestamp ,database_id ,
dbid ,userid , queryid , query , calls ,total_time ,min_time ,max_time ,mean_time ,stddev_time ,
rows ,shared_blks_hit ,shared_blks_read ,shared_blks_dirtied ,shared_blks_written ,local_blks_hit ,
local_blks_read,local_blks_dirtied,local_blks_written,temp_blks_read,temp_blks_written,
blk_read_time, blk_write_time
)
VALUES
(
current_snapshot_timestamp ,
database_rec.id ,
pg_stat_snapshot.dbid ,pg_stat_snapshot.userid ,pg_stat_snapshot.queryid,pg_stat_snapshot.query,pg_stat_snapshot.calls,
pg_stat_snapshot.total_time,pg_stat_snapshot.min_time ,pg_stat_snapshot.max_time,pg_stat_snapshot.mean_time, pg_stat_snapshot.stddev_time ,
pg_stat_snapshot.rows ,pg_stat_snapshot.shared_blks_hit ,pg_stat_snapshot.shared_blks_read ,pg_stat_snapshot.shared_blks_dirtied ,pg_stat_snapshot.shared_blks_written ,
pg_stat_snapshot.local_blks_hit , pg_stat_snapshot.local_blks_read , pg_stat_snapshot.local_blks_dirtied , pg_stat_snapshot.local_blks_written ,
pg_stat_snapshot.temp_blks_read , pg_stat_snapshot.temp_blks_written , pg_stat_snapshot.blk_read_time , pg_stat_snapshot.blk_write_time
);
END LOOP;
PERFORM dblink_disconnect('LINK1');
END LOOP ;--FOR database_rec IN SELECT * FROM database WHERE endpoint_id = endpoint_rec.id
END LOOP;
RETURN TRUE;
END
$$ LANGUAGE plpgsql;В результате, после некоторого периода времени в таблице pg_stat_history у нас будет набор снимков содержимого таблицы pg_stat_statements целевой базы данных.
Собственно репортинг
Используя простые запросы, можно получить вполне себе полезные и интересные отчеты.
Агрегированные данные за заданный промежуток времени
Запрос
SELECT
database_id ,
SUM(calls) AS calls ,SUM(total_time) AS total_time ,
SUM(rows) AS rows , SUM(shared_blks_hit) AS shared_blks_hit,
SUM(shared_blks_read) AS shared_blks_read ,
SUM(shared_blks_dirtied) AS shared_blks_dirtied,
SUM(shared_blks_written) AS shared_blks_written ,
SUM(local_blks_hit) AS local_blks_hit ,
SUM(local_blks_read) AS local_blks_read ,
SUM(local_blks_dirtied) AS local_blks_dirtied ,
SUM(local_blks_written) AS local_blks_written,
SUM(temp_blks_read) AS temp_blks_read,
SUM(temp_blks_written) temp_blks_written ,
SUM(blk_read_time) AS blk_read_time ,
SUM(blk_write_time) AS blk_write_time
FROM
pg_stat_history
WHERE
queryid IS NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
GROUP BY database_id ;DB Time
to_char(interval ‘1 millisecond’ * pg_total_stat_history_rec.total_time, ‘HH24:MI:SS.MS’)
I/O Time
to_char(interval ‘1 millisecond’ * ( pg_total_stat_history_rec.blk_read_time + pg_total_stat_history_rec.blk_write_time ), ‘HH24:MI:SS.MS’)
TOP10 SQL by total_time
Запрос
SELECT
queryid ,
SUM(calls) AS calls ,
SUM(total_time) AS total_time
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
GROUP BY queryid
ORDER BY 3 DESC
LIMIT 10------------------------------------------------------------------------------------- | TOP10 SQL BY TOTAL EXECUTION TIME | #| queryid| calls| calls %| total_time (ms) | dbtime % +----+-----------+-----------+-----------+--------------------------------+---------- | 1| 821760255| 2| .00001|00:03:23.141( 203141.681 ms.)| 5.42 | 2| 4152624390| 2| .00001|00:03:13.929( 193929.215 ms.)| 5.17 | 3| 1484454471| 4| .00001|00:02:09.129( 129129.057 ms.)| 3.44 | 4| 655729273| 1| .00000|00:02:01.869( 121869.981 ms.)| 3.25 | 5| 2460318461| 1| .00000|00:01:33.113( 93113.835 ms.)| 2.48 | 6| 2194493487| 4| .00001|00:00:17.377( 17377.868 ms.)| .46 | 7| 1053044345| 1| .00000|00:00:06.156( 6156.352 ms.)| .16 | 8| 3644780286| 1| .00000|00:00:01.063( 1063.830 ms.)| .03
TOP10 SQL by total I/O time
Запрос
SELECT
queryid ,
SUM(calls) AS calls ,
SUM(blk_read_time + blk_write_time) AS io_time
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
GROUP BY queryid
ORDER BY 3 DESC
LIMIT 10---------------------------------------------------------------------------------------- | TOP10 SQL BY TOTAL I/O TIME | #| queryid| calls| calls %| I/O time (ms)|db I/O time % +----+-----------+-----------+-----------+--------------------------------+------------- | 1| 4152624390| 2| .00001|00:08:31.616( 511616.592 ms.)| 31.06 | 2| 821760255| 2| .00001|00:08:27.099( 507099.036 ms.)| 30.78 | 3| 655729273| 1| .00000|00:05:02.209( 302209.137 ms.)| 18.35 | 4| 2460318461| 1| .00000|00:04:05.981( 245981.117 ms.)| 14.93 | 5| 1484454471| 4| .00001|00:00:39.144( 39144.221 ms.)| 2.38 | 6| 2194493487| 4| .00001|00:00:18.182( 18182.816 ms.)| 1.10 | 7| 1053044345| 1| .00000|00:00:16.611( 16611.722 ms.)| 1.01 | 8| 3644780286| 1| .00000|00:00:00.436( 436.205 ms.)| .03
TOP10 SQL by max time of execution
Запрос
SELECT
id AS snapshotid ,
queryid ,
snapshot_timestamp ,
max_time
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
ORDER BY 4 DESC
LIMIT 10----------------------------------------------------------------------------------------- | TOP10 SQL BY MAX EXECUTION TIME | #| snapshot| snapshotID| queryid| max_time (ms) +----+------------------+-----------+-----------+---------------------------------------- | 1| 05.04.2019 01:03| 4169| 655729273| 00:02:01.869( 121869.981 ms.) | 2| 04.04.2019 17:00| 4153| 821760255| 00:01:41.570( 101570.841 ms.) | 3| 04.04.2019 16:00| 4146| 821760255| 00:01:41.570( 101570.841 ms.) | 4| 04.04.2019 16:00| 4144| 4152624390| 00:01:36.964( 96964.607 ms.) | 5| 04.04.2019 17:00| 4151| 4152624390| 00:01:36.964( 96964.607 ms.) | 6| 05.04.2019 10:00| 4188| 1484454471| 00:01:33.452( 93452.150 ms.) | 7| 04.04.2019 17:00| 4150| 2460318461| 00:01:33.113( 93113.835 ms.) | 8| 04.04.2019 15:00| 4140| 1484454471| 00:00:11.892( 11892.302 ms.) | 9| 04.04.2019 16:00| 4145| 1484454471| 00:00:11.892( 11892.302 ms.) | 10| 04.04.2019 17:00| 4152| 1484454471| 00:00:11.892( 11892.302 ms.)
TOP10 SQL by SHARED buffer read/write
Запрос
SELECT
id AS snapshotid ,
queryid ,
snapshot_timestamp ,
shared_blks_read ,
shared_blks_written
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT AND
( shared_blks_read > 0 OR shared_blks_written > 0 )
ORDER BY 4 DESC , 5 DESC
LIMIT 10-------------------------------------------------------------------------------------------- | TOP10 SQL BY SHARED BUFFER READ/WRITE | #| snapshot| snapshotID| queryid| shared blocks read| shared blocks write +----+------------------+-----------+-----------+---------------------+--------------------- | 1| 04.04.2019 17:00| 4153| 821760255| 797308| 0 | 2| 04.04.2019 16:00| 4146| 821760255| 797308| 0 | 3| 05.04.2019 01:03| 4169| 655729273| 797158| 0 | 4| 04.04.2019 16:00| 4144| 4152624390| 756514| 0 | 5| 04.04.2019 17:00| 4151| 4152624390| 756514| 0 | 6| 04.04.2019 17:00| 4150| 2460318461| 734117| 0 | 7| 04.04.2019 17:00| 4155| 3644780286| 52973| 0 | 8| 05.04.2019 01:03| 4168| 1053044345| 52818| 0 | 9| 04.04.2019 15:00| 4141| 2194493487| 52813| 0 | 10| 04.04.2019 16:00| 4147| 2194493487| 52813| 0 --------------------------------------------------------------------------------------------
Гистограмма распределения запросов по максимальному времени выполнения
Запросы
SELECT
MIN(max_time) AS hist_min ,
MAX(max_time) AS hist_max ,
(( MAX(max_time) - MIN(min_time) ) / hist_columns ) as hist_width
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT ;
SELECT
SUM(calls) AS calls
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id =DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT AND
( max_time >= hist_current_min AND max_time < hist_current_max ) ;
|----------------------------------------------------------------------------------------------- | MAX_TIME HISTOGRAM | TOTAL CALLS : 33851920 | MIN TIME : 00:00:01.063 | MAX TIME : 00:02:01.869 --------------------------------------------------------------------------------- | min duration| max duration| calls +----------------------------------+----------------------------------+---------- | 00:00:01.063( 1063.830 ms.) | 00:00:13.144( 13144.445 ms.) | 9 | 00:00:13.144( 13144.445 ms.) | 00:00:25.225( 25225.060 ms.) | 0 | 00:00:25.225( 25225.060 ms.) | 00:00:37.305( 37305.675 ms.) | 0 | 00:00:37.305( 37305.675 ms.) | 00:00:49.386( 49386.290 ms.) | 0 | 00:00:49.386( 49386.290 ms.) | 00:01:01.466( 61466.906 ms.) | 0 | 00:01:01.466( 61466.906 ms.) | 00:01:13.547( 73547.521 ms.) | 0 | 00:01:13.547( 73547.521 ms.) | 00:01:25.628( 85628.136 ms.) | 0 | 00:01:25.628( 85628.136 ms.) | 00:01:37.708( 97708.751 ms.) | 4 | 00:01:37.708( 97708.751 ms.) | 00:01:49.789( 109789.366 ms.) | 2 | 00:01:49.789( 109789.366 ms.) | 00:02:01.869( 121869.981 ms.) | 0
TOP10 Snapshots by Query per Second
Запросы
--pg_qps.sql
--Calculate Query Per Second
CREATE OR REPLACE FUNCTION pg_qps( pg_stat_history_id integer ) RETURNS double precision AS $$
DECLARE
pg_stat_history_rec record ;
prev_pg_stat_history_id integer ;
prev_pg_stat_history_rec record;
total_seconds double precision ;
result double precision;
BEGIN
result = 0 ;
SELECT *
INTO pg_stat_history_rec
FROM
pg_stat_history
WHERE id = pg_stat_history_id ;
IF pg_stat_history_rec.snapshot_timestamp IS NULL
THEN
RAISE EXCEPTION 'ERROR - Not found pg_stat_history for id = %',pg_stat_history_id;
END IF ;
--RAISE NOTICE 'pg_stat_history_id = % , snapshot_timestamp = %', pg_stat_history_id ,
pg_stat_history_rec.snapshot_timestamp ;
SELECT
MAX(id)
INTO
prev_pg_stat_history_id
FROM
pg_stat_history
WHERE
database_id = pg_stat_history_rec.database_id AND
queryid IS NULL AND
id < pg_stat_history_rec.id ;
IF prev_pg_stat_history_id IS NULL
THEN
RAISE NOTICE 'Not found previous pg_stat_history shapshot for id = %',pg_stat_history_id;
RETURN NULL ;
END IF;
SELECT *
INTO prev_pg_stat_history_rec
FROM
pg_stat_history
WHERE id = prev_pg_stat_history_id ;
--RAISE NOTICE 'prev_pg_stat_history_id = % , prev_snapshot_timestamp = %', prev_pg_stat_history_id , prev_pg_stat_history_rec.snapshot_timestamp ;
total_seconds = extract(epoch from ( pg_stat_history_rec.snapshot_timestamp - prev_pg_stat_history_rec.snapshot_timestamp ));
--RAISE NOTICE 'total_seconds = % ', total_seconds ;
--RAISE NOTICE 'calls = % ', pg_stat_history_rec.calls ;
IF total_seconds > 0
THEN
result = pg_stat_history_rec.calls / total_seconds ;
ELSE
result = 0 ;
END IF;
RETURN result ;
END
$$ LANGUAGE plpgsql;
SELECT
id ,
snapshot_timestamp ,
calls ,
total_time ,
( select pg_qps( id )) AS QPS ,
blk_read_time ,
blk_write_time
FROM
pg_stat_history
WHERE
queryid IS NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT AND
( select pg_qps( id )) IS NOT NULL
ORDER BY 5 DESC
LIMIT 10
|----------------------------------------------------------------------------------------------- | TOP10 Snapshots ordered by QueryPerSeconds numbers ----------------------------------------------------------------------------------------------------------------------------------------------- | #| snapshot| snapshotID| calls| total dbtime| QPS| I/O time| I/O time % +-----+------------------+-----------+-----------+----------------------------------+-----------+----------------------------------+----------- | 1| 04.04.2019 20:04| 4161| 5758631| 00:06:30.513( 390513.926 ms.)| 1573.396| 00:00:01.470( 1470.110 ms.)| .376 | 2| 04.04.2019 17:00| 4149| 3529197| 00:11:48.830( 708830.618 ms.)| 980.332| 00:12:47.834( 767834.052 ms.)| 108.324 | 3| 04.04.2019 16:00| 4143| 3525360| 00:10:13.492( 613492.351 ms.)| 979.267| 00:08:41.396( 521396.555 ms.)| 84.988 | 4| 04.04.2019 21:03| 4163| 2781536| 00:03:06.470( 186470.979 ms.)| 785.745| 00:00:00.249( 249.865 ms.)| .134 | 5| 04.04.2019 19:03| 4159| 2890362| 00:03:16.784( 196784.755 ms.)| 776.979| 00:00:01.441( 1441.386 ms.)| .732 | 6| 04.04.2019 14:00| 4137| 2397326| 00:04:43.033( 283033.854 ms.)| 665.924| 00:00:00.024( 24.505 ms.)| .009 | 7| 04.04.2019 15:00| 4139| 2394416| 00:04:51.435( 291435.010 ms.)| 665.116| 00:00:12.025( 12025.895 ms.)| 4.126 | 8| 04.04.2019 13:00| 4135| 2373043| 00:04:26.791( 266791.988 ms.)| 659.179| 00:00:00.064( 64.261 ms.)| .024 | 9| 05.04.2019 01:03| 4167| 4387191| 00:06:51.380( 411380.293 ms.)| 609.332| 00:05:18.847( 318847.407 ms.)| 77.507 | 10| 04.04.2019 18:01| 4157| 1145596| 00:01:19.217( 79217.372 ms.)| 313.004| 00:00:01.319( 1319.676 ms.)| 1.666
Hourly Execution History with QueryPerSeconds and I/O Time
Запрос
SELECT
id ,
snapshot_timestamp ,
calls ,
total_time ,
( select pg_qps( id )) AS QPS ,
blk_read_time ,
blk_write_time
FROM
pg_stat_history
WHERE
queryid IS NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
ORDER BY 2
|----------------------------------------------------------------------------------------------- | HOURLY EXECUTION HISTORY WITH QueryPerSeconds and I/O Time ----------------------------------------------------------------------------------------------------------------------------------------------- | QUERY PER SECOND HISTORY | #| snapshot| snapshotID| calls| total dbtime| QPS| I/O time| I/O time % +-----+------------------+-----------+-----------+----------------------------------+-----------+----------------------------------+----------- | 1| 04.04.2019 11:00| 4131| 3747| 00:00:00.835( 835.374 ms.)| 1.041| 00:00:00.000( .000 ms.)| .000 | 2| 04.04.2019 12:00| 4133| 1002722| 00:01:52.419( 112419.376 ms.)| 278.534| 00:00:00.149( 149.105 ms.)| .133 | 3| 04.04.2019 13:00| 4135| 2373043| 00:04:26.791( 266791.988 ms.)| 659.179| 00:00:00.064( 64.261 ms.)| .024 | 4| 04.04.2019 14:00| 4137| 2397326| 00:04:43.033( 283033.854 ms.)| 665.924| 00:00:00.024( 24.505 ms.)| .009 | 5| 04.04.2019 15:00| 4139| 2394416| 00:04:51.435( 291435.010 ms.)| 665.116| 00:00:12.025( 12025.895 ms.)| 4.126 | 6| 04.04.2019 16:00| 4143| 3525360| 00:10:13.492( 613492.351 ms.)| 979.267| 00:08:41.396( 521396.555 ms.)| 84.988 | 7| 04.04.2019 17:00| 4149| 3529197| 00:11:48.830( 708830.618 ms.)| 980.332| 00:12:47.834( 767834.052 ms.)| 108.324 | 8| 04.04.2019 18:01| 4157| 1145596| 00:01:19.217( 79217.372 ms.)| 313.004| 00:00:01.319( 1319.676 ms.)| 1.666 | 9| 04.04.2019 19:03| 4159| 2890362| 00:03:16.784( 196784.755 ms.)| 776.979| 00:00:01.441( 1441.386 ms.)| .732 | 10| 04.04.2019 20:04| 4161| 5758631| 00:06:30.513( 390513.926 ms.)| 1573.396| 00:00:01.470( 1470.110 ms.)| .376 | 11| 04.04.2019 21:03| 4163| 2781536| 00:03:06.470( 186470.979 ms.)| 785.745| 00:00:00.249( 249.865 ms.)| .134 | 12| 04.04.2019 23:03| 4165| 1443155| 00:01:34.467( 94467.539 ms.)| 200.438| 00:00:00.015( 15.287 ms.)| .016 | 13| 05.04.2019 01:03| 4167| 4387191| 00:06:51.380( 411380.293 ms.)| 609.332| 00:05:18.847( 318847.407 ms.)| 77.507 | 14| 05.04.2019 02:03| 4171| 189852| 00:00:10.989( 10989.899 ms.)| 52.737| 00:00:00.539( 539.110 ms.)| 4.906 | 15| 05.04.2019 03:01| 4173| 3627| 00:00:00.103( 103.000 ms.)| 1.042| 00:00:00.004( 4.131 ms.)| 4.010 | 16| 05.04.2019 04:00| 4175| 3627| 00:00:00.085( 85.235 ms.)| 1.025| 00:00:00.003( 3.811 ms.)| 4.471 | 17| 05.04.2019 05:00| 4177| 3747| 00:00:00.849( 849.454 ms.)| 1.041| 00:00:00.006( 6.124 ms.)| .721 | 18| 05.04.2019 06:00| 4179| 3747| 00:00:00.849( 849.561 ms.)| 1.041| 00:00:00.000( .051 ms.)| .006 | 19| 05.04.2019 07:00| 4181| 3747| 00:00:00.839( 839.416 ms.)| 1.041| 00:00:00.000( .062 ms.)| .007 | 20| 05.04.2019 08:00| 4183| 3747| 00:00:00.846( 846.382 ms.)| 1.041| 00:00:00.000( .007 ms.)| .001 | 21| 05.04.2019 09:00| 4185| 3747| 00:00:00.855( 855.426 ms.)| 1.041| 00:00:00.000( .065 ms.)| .008 | 22| 05.04.2019 10:00| 4187| 3797| 00:01:40.150( 100150.165 ms.)| 1.055| 00:00:21.845( 21845.217 ms.)| 21.812
Text of all SQL-selects
Запрос
SELECT
queryid ,
query
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
GROUP BY queryid , query
Итог
Как видно, довольно простыми средствами, можно получить достаточно много полезной информации о загруженности и состоянии базы.
Примечение:Если в запросах фиксировать queryid то получим историю по отдельному запросу(с целью экономии места отчеты по отдельному запросу опущены).
Итак, статистические данные о производительности запросов — имеются и собираются.
Первый этап «сбор статистических данных» — завершен.
Можно переходить ко второму этапу-«настройка метрик производительности».

Но это уже совсем другая история.
Продолжение следует…
Источник: habr.com
