

Два года назад я уже делал пост про . Сейчас есть некоторое развитие проекта, а еще я опубликовал под , поэтому и решил написать на хабр этот небольшой обзор.
[ ]
Кому это может быть интересно
Вам это может быть интересно если вы работаете небольшой командой или вообще один. У вас нет мониторинга и вы не уверены, точно ли он нужен. Либо же вы пробовали какой-то популярный серьезный мониторинг «для больших мальчиков», но для вас он как-то «не взлетел», или работает в почти дефолтной конфигурации и не сильно изменил вашу жизнь. А еще — если вы точно не планируете выделять целого сотрудника (а то и отдел) на то, чтобы тот хотя бы пару часов в день мониторил в дашборд мониторинга или настраивал его.
Чем необычен okerr
Дальше я покажу интересные особенности окерра, которые отличают его от некоторых других мониторингов.
Okerr — это гибридный мониторинг
При внутреннем мониторинге на наблюдаемых машинах крутится «агент», который передает данные на сервер мониторинга (например, свободное место на дисках). При внешнем — сервер по сети выполняет проверки (например, ping или доступность вебсайта). У каждого подхода свои ограничения. Okerr использует оба варианта. Проверки внутри серверов выполняются очень легким (30Kb) агентом или вашими собственными скриптами и приложениями, а сетевые — через сенсоры okerr в разных странах.
okerr — это не просто софт, но еще и сервис
Серверная часть любого мониторинга — штука большая и сложная, ее сложно ставить и настраивать, она требует ресурсов. С okerr вы можете поставить свой собственный сервер мониторинга (он бесплатный и opensource), а можно просто использовать только клиентскую часть, и пользоваться сервисом нашего сервера. Тоже бесплатно.
Если мониторинг позволяет компенсировать, прикрыть нехватку надежности у серверов и приложений, то возникает философский вопрос — кто сторожит стражника? Как мониторинг нам сообщит о проблеме, если он сам «умер» по какой-то причине, отдельно или вместе с другими вашими ресурсами (например, упал канал в дата-центр)? При использовании внешнего сервиса okerr — эта проблема решается — вы получите алерт даже если весь дата-центр с вашими серверами будет обесточен или подвергнется атаке зомби.
Конечно, есть риск, что сервер okerr сам будет недоступен, это так (как известно, 90% надежности получаются всегда просто и «бесплатно», 99% — с минимумом усилий, и каждая следующая девяточка — экспоненциально сложнее). Но, во-первых шансы этого ниже, а во-вторых, проблема может оказаться незамеченной только если ли она совпадет по времени с проблемами на наших серверах. Если у нас надежность 99.9%, и у вас 99.9% (не слишком уж высокие числа), то шанс незамеченного сбоя — 0.1% от 0.1% = 0.0001%. Добавить себе три девятки в надежность почти без усилий и без затрат — это очень неплохо!
Еще одно преимущество мониторинга как сервиса — хостинг-провайдер или веб-студия может установить у себя сервер okerr и предоставлять доступ клиентам как платную или бесплатную дополнительную услугу. У ваших конкурентов просто хостинг и сайты — а у вас надежный хостинг с мониторингом.
Okerr — это про индикаторы
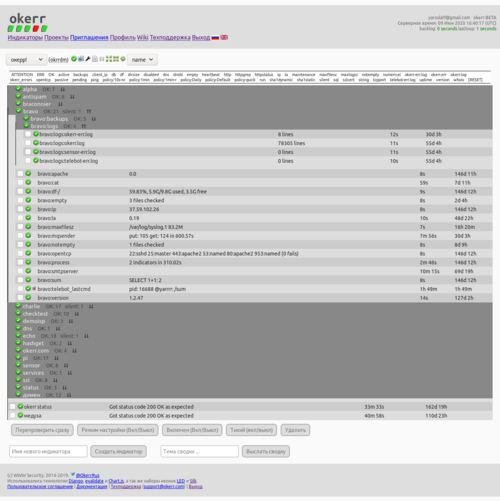
Индикатор — это «лампочка». У него два основных состояния — зеленый (OK) или красный (ERR). В проекте — множество сгруппированных (например, по серверам) индикаторов. На главной странице проекта вы сразу видите, либо у вас все зеленое (и можно закрывать), либо что-то горит красненьким и нужно исправлять. При переходе между этими состояниями — высылается оповещение. Раз в сутки в то время как настроите — высылается сводка по проекту.
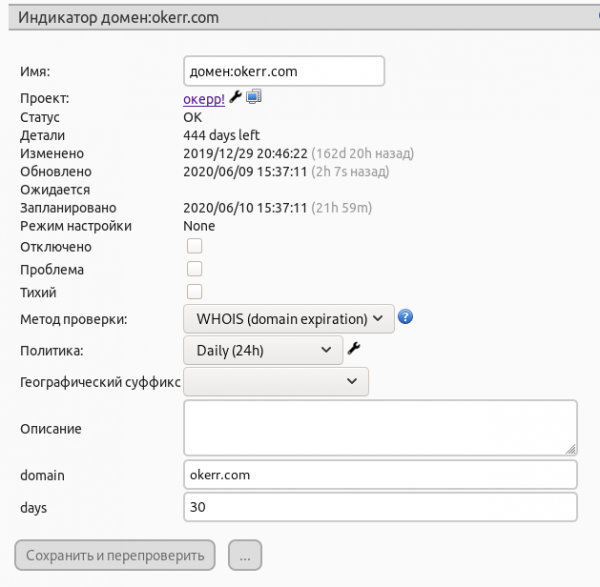
Каждый индикатор okerr имеет встроенные условия, по которым он меняет состояние (в Zabbix это называется trigger). Например, load average должен быть не более 2 (конечно же, это настраивается). И для каждой внутренней проверки (load average, disk free, …) — есть watchdog. Если по каким-то причинам мы не получили успешное подтверждение в назначенное время — регистрируется ошибка и высылается алерт.
Обычная схема работы у нас — утренняя проверка почты, там среди прочих писем смотрим сводку (ее время назначаем на начало работы). Если в ней все окей — занимаемся другими важными делами (но можем для надежности быстро глянуть в дашборд окерра, убедиться, что и в эту минуту все зеленое). Если приходит алерт — реагируем.
Конечно, есть возможность просто держать «информационные» индикаторы (чтобы видеть картину сети из мониторинга), но все сделано чтобы просто, легко и быстро делать индикаторы именно для автоматического наблюдения и рассылки алертов.
Смысл, ради которого вы настраиваете okerr — в алертах, в том чтобы вы могли за минуту создать индикатор, он может быть год бы «спал», просто принимал апдейты, а когда через год у вас что-то поломается — он загорелся и выслал алерт. Минута, которую потратили однажды на создание индикатора, окупилась, вы узнали о проблеме сразу, раньше всех. Возможно, что и починили, до того, как кто-то заметил. Быстро поднятое не считается упавшим!
Безопасность
Было бы обидно, если вы ставите мониторинг ради повышения надежности, а в результате — вас через него атакуют по сети, и сетевых уязвимостей у разных средств мониторинга довольно много (, ).
Агент (okerrmod из пакета ), работающий на системе — это не сетевой сервер, а клиент. Поэтому на наблюдаемом сервере нет дополнительных открытых портов, клиент легко работает за файрволом или NAT’ом и его очень сложно (я бы сказал «невозможно») взломать по сети, так как он в принципе не слушает сетевой сокет.
Полный охват мониторинга
Сейчас у нас правило — мы узнаем о всех технических проблемах из okerr. Если вдруг правило нарушилось (okerr не предупредил о ее скором наступлении (если это возможно) или о том, что она уже наступила) — мы добавляем проверки в okerr.
Внешние проверки
Довольно типовой набор:
- ping
- http status
- проверка валидности и свежести SSL сертификата (предупредит, если срок скоро истекает)
- открытый TCP порт и баннер на нем
- http grep (на странице [не] должен находиться определенный текст)
- sha1 hash для того, чтобы отловить изменение страницы.
- DNS (DNS запись должна иметь определенное значение)
- WHOIS (предупредит, если домен скоро протухнет)
- Antispam DNSBL (проверка хоста сразу по 50+ антиспамерским блеклистам)
Внутренние проверки
Тоже, довольно типовой набор (но легко расширяемый).
- df (свободное место на дисках)
- load average
- opentcp (открытые слушающие TCP сокеты — уведомит, если что-то запустилось или упало)
- uptime — просто uptime сервере. Уведомит, если он изменился вниз (т.е. сервер перегрузился)
- client_ip
- dirsize — мы его используем, чтобы отслеживать, когда у нас rootfs виртуалок выходят за разрешенный размер, не вводя жесткие ограничения, и за размерами домашних каталогов пользователей
- empty и nonempty — следят за файлами которые должны быть пустыми (или не пустыми). Например, error log самого сервера okerr — должен быть пустой, и если в нем есть хоть строчка — я получу уведомление и проверю. А вот mail.log на почтовом сервере должен быть НЕ пустым (через N минут после ротации). А иногда у нас бывал пустым, после обновления системы, когда logrotate не мог правильно рестартануть rsyslog.
- linecount — количество строк в файле (как wc -l). Мы используем как более мягкую замена для empty, когда error log все таки может расти, но только медленно (у нас, например, гуглобот долбится на некоторые закрытые страницы). Стоит лимит на 2 строчки за 20 минут. Если будет выше — будет алерт
Интересные внутренние проверки
Если до этого места вы читали «по диагонали», сейчас будет интереснее прочитать внимательнее.
backups
Следит за бэкапами в каталоге. У нас файлы бэкапов имеют имена вроде «ServerName-20200530.tar.gz». По каждому серверу в okerr создается индикатор ServerName-DATE.tar.gz (фактическая дата меняется на строчку «DATE»). Отслеживается и само наличие свежего бэкапа и его размер (например, он не может быть меньше чем 90% от предыдущего бэкапа).
Что нужно сделать чтобы новый бэкап начал отслеживаться, после того как мы его начали создавать и класть в этот каталог? Ничего! Это очень удобный подход, когда нужно сделать «ничего», потому что:
- Сделать «ничего» — довольно быстро, это экономит время
- Сложно забыть сделать «ничего»
- Сложно сделать «ничего» неправильно, с ошибкой. Ничего — это самый надежный метод
Если же вдруг перестали появляться свежие файлы бэкапа — будет алерт. Если же вы, например, отключили один из серверов, и его бэкапов и не должно больше быть — вам нужно будет удалить индикатор (через веб-интерфейс или из шелла через API).
maxfilesz
Следит за размером самых больших файлов (обычно: /var/log/*). Это позволяет отлавливать непредсказуемые проблемы, например, перебор паролей или рассылка спама через сервер.
runstatus/runline
Это два важных proxy модуля, для запуска других программ на сервере. Runstatus сообщает в индикатор код выхода программы. Например, в okerr нет (не требуется) модуля для проверки того, что systemd сервисы работают. Это делается через runstatus (смотрите ниже). Runline — сообщает на сервер строку, которую выдает программа. Например, temp_RUN="cat /sys/class/thermal/thermal_zone0/temp" в конфиге Runline на нашем сервере создает индикатор servername:temp с температурой процессора.
sql
Выполняет числовой запрос к MySQL и сообщает результат в индикатор. В простом случае, можно сделать, например, «SELECT 1» — это проверит, что в целом СУБД работает.
Но гораздо более интересное применение — например, отслеживать количество заказов в интернет-магазине. Если вы знаете, что в час у вас от 100 заказов, можно установить минимальную границу в 100 или 80. Тогда если внезапно у вас упадут продажи — вы получите алерт, и сможете разобраться.
Заметьте — неважно, по какой непредсказуемой причине это случилось:
- Сервер просто недоступен (обесточен или без сети), а алерт пришел от того, что индикатор «протух».
- Сервер чем-то нагружен, медленно работает или теряются пакеты, пользователям неудобно и они уходят без покупок
- Сервер попал в спам-листы и почта от него не принимается, пользователи не могут зарегистрироваться
- Кончился бюджет рекламной кампании, баннеры не крутятся.
Причин может быть сколько угодно, и все их заранее не предусмотришь, и технически сложно отследить. Но можно удобно следить за конечным параметром (заказами) и по ним определять, что ситуация подозрительная и заслуживает того, чтобы разобраться с ней.
Логические индикаторы
Позволяет использовать логические выражения (синтаксис Python) через модуль (). Для выражения доступны данные проекта и его индикаторов. Например, в главе про SQL проверку выше, вы, возможно, заметили слабое место — днем у нас может быть от 100 продаж в час, но ночью-то — 20, и это обычное дело, не проблема. Как быть? Индикатор ведь будет постоянно паниковать по ночам.
Можно создать два индикатора, дневной и ночной. Оба сделать «тихими» (они не будут слать оповещения). И создать логический индикатор, который требует до 20:00 чтобы дневной индикатор был OK, а после 20:00 достаточно чтобы ночной индикатор был ОК.
Другой пример использования логического индикатора — это эскалация. Например, менеджер проекта отписывается от алертов (ему это незачем, админы должны реагировать на обычные проблемы), но подписывается на логический индикатор, который краснеет, если любой индикатор в проекте не исправлен за отведенное время.
Еще — есть возможность назначить разрешенное время для работ, например, с 3 до 5 утра. Нас не волнует, если сервера и сайты «падают» в это время. Но в 5:00 они должны работать. Если не работают в любое другое время — алерт. Так же логический индикатор позволяет учитывать резервирование серверов. Если у вас 5 веб-серверов, то админы могут выключать 1-2 сервера в любое время. Но если в бою будет менее 3 из 5 серверов — будет алерт.
Примеры выше — это не функции окерр, не какие-то фичи, которые нужно активировать и настроить. Всех этих функций в окерре нет, зато есть логический модуль, который позволяет реализовать и этот функционал (Примерно, как в языке программирования — если у нас есть арифметические операторы, то нам не нужна от языка особая функция расчета 20% НДС, ее всегда можно самому сделать под свои нужды).
Логический индикатор, наверное, одна из немногих относительно сложных тем в okerr, но хорошая новость в том, что вам не нужно их осваивать, пока не возникнет надобность. Но при этом они очень сильно расширяют возможности, сохраняя саму систему достаточно простой.
Добавление своих проверок
Я бы очень хотел донести мысль, что okerr — это не набор из тысячи готовых проверок на все случаи жизни, а наоборот — в первую очередь — простой движок с простой возможностью создавать свои проверки. Создание своих проверок в okerr — это не задача для хакеров, со-разработчиков системы, или хотя бы продвинутых юзеров okerr, а посильная задача для любого админа, который месяц назад впервые поставил linux.
Проверки на минималочках делаются через модуль :
Эта строчка в конфиге оповестит, если вдруг /bin/true не запустится или вернет не 0.
true_OK=/bin/trueВсего одна строчка — и вот мы уже немного расширили функционал okerr.
Даже такая проверка — уже имеет свою ценность: если вдруг ваш сервер ляжет — соответствующий индикатор на сервере okerr не обновится своевременно, и по истечении времени возникнет алерт.
Эта проверка оповестит, что сервер apache2 упал (ну мало ли…):
apache_OK="systemctl is-active --quiet apache2"Так что, если вы владеете любым языком программирования, хотя бы можете писать shell скрипты — то вы уже можете добавлять собственные проверки.
Более сложно — можно написать (на любом языке) свой модуль для okerrmod. В простейшем случае он выглядит так:
#!/usr/bin/python3
print("STATUS: OK")Правда же, не очень сложно? Модуль должен сделать саму проверку, и выдать результаты на STDOUT. Более сложный модуль дает, например, такое:
$ okerrmod --dump df
NAME: pi:df-/
TAGS: df
METHOD: numerical|maxlim=90
DETAILS: 49.52%, 13.9G/28.2G used, 13.0G free
STATUS: 49.52
NAME: pi:df-/boot
TAGS: df
METHOD: numerical|maxlim=90
DETAILS: 84.32%, 53.1M/62.9M used, 9.9M free
STATUS: 84.32Он обновляет сразу несколько индикатора (разделены пустой строкой), при необходимости создаст их, указывает детали проверки и тег, по которому в дашборде легко найти нужные индикаторы.
Telegram
Есть Telegram bot . Вам не нужно захламлять телефон отдельными приложениями (сам не люблю, что для Пятерочки нужно одно приложение с картой, для Ленты другое, для МТС третье, и так для всех-всех-всех). Один телеграмм — достаточно. Через телеграм можно и получать алерты сразу же и проверять статус проекта и отдать команду на перепроверку всех проблемных индикаторов. Вышли из театра/самолета, два часа не держали руку на пульсе, включили тел, нажали одну кнопку в чат-боте, и убедились, что все в порядке.
Страницы статуса
В наше время, страницы статуса — уже почти must have для любого бизнеса у которого есть IT, ответственное отношение к надежности и который уважительно относится к своим клиентам/пользователям.
Представьте ситуацию — пользователь хочет что-то сделать, посмотреть информацию или оформить заказ, и что-то не работает. Он не знает в чем дело, на чьей стороне проблема и когда она решится. Может у вашей фирмы просто нерабочий сайт? Или поломалось полгода назад, и починится через два года? А холодильник-то надо купить уже сейчас, он уже в корзине… И совсем другое дело, когда человек видит, что у вас что-то не в порядке (хотя бы ясно, что проблема не на его стороне), что проблема обнаружена, что вы над ней уже работаете, и может быть даже написали примерное время исправления. Пользователь может подписаться и получить на почту уведомление, когда проблема будет исправлена и можно будет сделать то, что он хотел (купить холодильник).
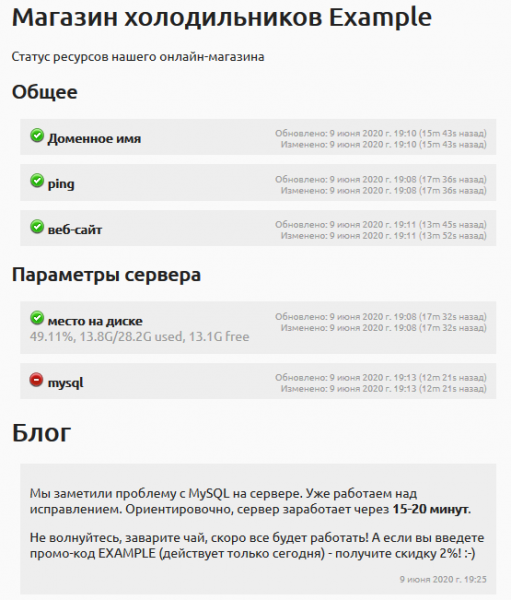
Проблемы, даунтайм — бывают у всех. Но пользователи и партнеры больше доверяют тем, кто более прозрачен и ответственно подходит к этому.
Вот . Вот примеры, как выглядят эти страницы у проектов и . .
Failover
Чтобы не делать эту статью еще больше, я еще раз сошлюсь на свою предыдущую статью — . Если вы можете сделать дублирующий сервер, то с использованием failover’а, у вас в принципе не будет долгого даунтайма — как только проблема будет обнаружена, автоматически пользователи перенаправятся на работающий резервный сервер. И мне кажется, это очень интересная, яркая функция, которая мало где есть.
Низкие системные требования
Для серверов okerr — мы используем машины с RAM от 2Gb. Для сетевых сенсоров — даже 512Mb достаточно. Клиентская часть — вообще почти ноль. (Пакет весит 26 Kb, но требует Python3 и стандартных библиотек). Клиент запускается из крон скрипта, так что имеет нулевое постоянное потребление памяти. Среди наблюдаемых машин у нас есть сенсоры (супер-дешевые VPSки с 512Mb RAM) и Raspberry Pi. Можно даже без клиентской части ! (см ниже)
С учетом этого — okerr, наверное, наиболее бесплатная система мониторинга из имеющихся, ведь даже чтобы использовать другую бесплатную опен-сорсную систему вроде Zabbix или Nagios, нужно выделить ей ресурсы (сервер), а это уже деньги. Кроме того — все таки требуется некоторое обслуживание сервера. С okerr — эту часть можно убрать. А можно и не убирать и использовать собственный сервер — смотря как вам больше нравится.
API и интеграция в собственное ПО
Простая и открытая архитектура. У okerr есть довольно простой , с которым легко работать. Нужно создать 1000 индикаторов? Один шелл-скрипт в 3-4 строчки это сделает. Нужно перенастроить 1000 индикаторов? Тоже очень легко. Например, мы хотим перепроверить все наши HTTPS сертификаты именно с российского сенсора:
#!/bin/sh
for indicator in `okerrclient --api-filter sslcert`
do
echo set location for $indicator
okerrclient --api-set location=ru retest=1 --name $indicator
doneОбновить индикатор можно хоть используя наш клиентский модуль, хоть даже без него, просто через curl.
# short and nice (using okerrupdate and config file)
$ okerrupdate MyIndicator OK
# only curl is enough!
$ curl -d 'textid=MyProject&name=MyIndicator&secret=MySecret&status=OK' https://bravo.okerr.com/Можно обновлять индикаторы прямо из своей программы. Например, посылая heartbeat сигналы, чтобы okerr знал, что она запущена, и поднял тревогу, если она упала либо зависла. Кстати, компоненты okerr так и делают — okerr сам за собой следит, и проблемы в почти любом модуле — будут обнаружены и сгенерируют оповещение о проблеме. (А на случай этого «почти» — они перекрестно проверяются с другого сервера)
Вот такой код (упрощенно) в нашем телеграм-боте:
from okerrupdate import OkerrProject, OkerrExc
op = OkerrProject()
uptimei = op.indicator("{}:telebot_uptime".format(hostname))
...
uptimei.update('OK', 'pid: {} Uptime: {} cmds: {}'.format(
os.getpid(), dhms(uptime), commands_cnt))Для обновления индикаторов из Python программ — есть библиотека , для любых других языков — библиотек нет, но можно либо вызвать скрипт okerrupdate, либо выполнить HTTP запрос к серверу okerr.
Как нам помогает okerr
Okerr изменил нашу жизнь. В самом деле. Возможно, другая система мониторинга тоже могла бы, но с okerr работать нам легко и просто и в нем есть все функции, которые нам были нужны (чего не было — мы дописали). Кстати, если какой-то фичи нет — спросите, и я их добавлю (не обещаю, но мне хочется, чтобы okerr был лучшей системой мониторинга для малых-средних проектов). Или, еще лучше, добавьте сами — это просто.
У нас получилось жить по принципу «обо всех проблемах узнать из окерра». Если вдруг случилась проблема, о которой мы узнали не от okerr — мы добавляем проверку в okerr. (в данном случае под «мы» — я понимаю нас как пользователей системы, а не со-разработчиков). Поначалу это было часто, но сейчас стало очень редким.
Мониторинг
Через okerr мы следим за размерами логов на всех серверах. Вдумчиво читать глазами каждую строчку лога — конечно, невозможно, но вот просто слежение за скоростью роста — уже многое дает. Через это мы обнаруживали и рассылку спама и брутфорс перебор паролей, и когда какие-то из приложений «сходят с ума», у них что-то не получается и они повторяют снова и снова (каждый раз добавляя пару строчек в лог).
SSL сертификаты. Почти сразу после запуска наш заказчик начал предоставлять своим клиентам бесплатные SSL сертификаты (порядка тысячи их). И это оказалось просто адом для администрирования! Дело в том, что сайты «живые», клиенты периодически чего-то просят им сделать, программисты делают. Могут совершенно свободно перенести сайт на другой DocumentRoot например. Или добавить безусловный Rewrite в конфиг виртхоста. Естественно, после такого ломается автоматическое обновление сертификатов. Сейчас у нас все SSL хосты добавляются в okerr автоматически через еще одну нашу полезную утилитку из пакета . Просто запускаем a2okerr.py — и если на сервере появилось несколько новых сайтов — они автоматически появятся в okerr. Если вдруг почему-то сертификат не обновляется, за три недели до протухания сертификата — мы в курсе, и разбираемся, почему же он не обновляется, собака такая. a2certbot.py из того же пакета — очень помогает в этом (сразу проверяет наиболее вероятные проблемы — и пишет, что хорошо проверилось, а где скорее всего есть проблема).
Мы следим за сроком истечения всех наших доменов. А все наши почтовые сервера, которые отсылают почту — еще и проверяются по 50+ различным блеклистам. (И иногда попадают в них). Кстати, знаете ли вы, что почтовые сервера google тоже в блеклистах? Просто для самотестирования мы добавили mail-wr1-f54.google.com к отслеживаемым серверам, и он таки в блеклисте SORBS! (Это к вопросу о ценности «антиспамеров»)
Бэкапы — выше я уже написал, как просто за ними следить с okerr. Но мы следим и за свежими бэкапами на нашем сервер, и (с помощью отдельной утилитки, которая использует okerr) — за бэкапами, которые мы заливаем на Amazon Glacier. И, да — периодически проблемы случаются. Не зря следили.
Мы используем индикатор эскалации. По нему видно, если какая-то проблема не исправлена долгое время. И я сам, когда решаю какие-то задачи, иногда могу забыть о них. Эскалация — хорошая напоминалочка, даже если сам за собой следишь.
В целом, я считаю, что качество нашей работы повысилось на порядок. Даунтайма почти нет (ну или клиент не успевает его заметить. Только тссс!), при этом объем работы стал меньше а условия работы — спокойнее. Мы перешли от авральной работы с латанием пробоин скотчем к спокойной и размеренной работе, когда многие проблемы предсказываются заранее и есть время, чтобы их предотвратить. Даже свершившиеся проблемы — тоже исправлять стало проще: во-первых, мы о них узнаем до того, как клиенты устраивают панику, во-вторых, часто бывает так, проблема связана с недавней работой (пока делал одно, поломал другое) — поэтому по горячим следам с ней проще разобраться.
А вот еще был случай…
Знаете ли вы, что в популярном Debian 9 (Stretch) такой популярный пакет как phpmyadmin до сих пор (уже много месяцев!) находится в статусе vulnerable? (). Когда уязвимость вышла — мы быстренько разными путями ее прикрыли. Но я поставил в okerr слежение за страничкой security-tracker’а, чтобы знать, когда выйдет «красивое» решение (через SHA1 сумму контента). Несколько раз индикатор дергал меня, страничка менялась, но как видите — до сих пор (с января 2019 года!) там не указано, что проблема решена. Может быть, кстати, кто-то знает, что там за проблема, что до сих пор такой важный пакет больше года vulnerable?
Другой раз в похожей ситуации: после уязвимости в SSH нужно было обновить все серваки. А когда ставишь задачу — нужно контролировать исполнение. (Подчиненные имеют свойство не так понимать, забывать, путаться, совершать ошибки). Поэтому, сначала мы в okerr добавили проверку версии SSH на всех серверах, и через okerr следили, чтобы обновления накатили на всех серверах. (Удобно! Выбрал этот тип индикатора, и сразу видно, на каком сервере какая версия). Когда мы убедились, что задача выполнена на всех серверах — мы удалили индикаторы.
Пару раз была ситуация, что некоторая проблема возникает, а потом сама проходит. (наверное, всем знакомо?). Пока заметишь, пока проверишь — а там уже и проверять нечего — все уже хорошо работает. Но потом снова поломается. У нас это было, например, с товарами, которые мы загружали в Amazon Marketplace (MWS). В какой-то момент загруженные inventory были неверными (не те количества товаров и не те цены). Разобрались. Но чтобы разобраться — важно было узнать о проблеме сразу. К сожалению, MWS как и все сервисы амазона — немного тормозной, поэтому всегда был лаг, но все таки — удалось хотя бы примерно уловить связь между проблемой, и скриптами, которые ее вызывают (сделали проверку, приляпали ее к окерру, и проверяли сразу по получении алерта).
Интересный случай в копилочку совсем недавно добавил крупный и дорогой европейский хостер, которым пользуется наш заказчик. Внезапно вдруг с радаров пропали ВСЕ наши сервера! Сначала заказчик сам «ручками» (быстрее окерра!) заметил, что сайт с которым он работал — не открывается и сделал тикет про это. Но, полег не один сайт, а вообще все! (Наташа, мы все уронили!). Тут и Okerr начал слать длинные портянки со всеми индикаторами, которые у него загорелись. Паника-паника, бегаем кругами (а что еще делать?). Потом все поднялось. Оказывается, в дата-центре были регламентные работы (раз в много лет) и нас, конечно же, должны были предупредить. Но вот запердыка случилась у них какая-то и не предупредили. Ну инфарктом больше, инфарктом меньше. Но после восстановления всего — нужно же все перепроверить! Я не представляю, как я бы это делал руками. Okerr за несколько минут все оттестировал. Оказалось, что бОльшая часть серверов просто была временно недоступна, но работала. Некоторые — перегрузились, но тоже встали как надо. Из всех потерь — мы потеряли два бэкапа, которые по крону должны были создаться и загрузиться в то время, пока шел этот полный бананас. Я даже не стал их создавать, просто через сутки прилетели алерты, что все ОК, бэкапы появились. Мне этот пример очень нравится, потому что okerr оказался очень полезным в ситуации, о которой мы даже и не думали заранее, но в этом и задача мониторинга — противостоять непредсказуемому.
Для сенсоров Okerr мы используем максимально дешевые хостинги (там качество и надежность не важны, они страхуют друг-друга). Так вот, недавно нашли очень бодрый хостинг и супер дешево, бенчмарки офигительные. Но… иногда оказывается, что исходящие соединения с виртуалки выполняются с другого (соседнего) IP. Чудеса. Модуль client_ip с получает не тот IP. Да и по серверным логам индикатора видно, что апдейт пришел тоже с этого соседнего IP. Разбираемся сейчас с саппортом. Хорошо, что заметили это в мирное время. Но, например, часто ведь бывает так, что доступ прописывается по белому списку IP — и если сервер будет иногда на короткое время так моргать — можно очень долго пытаться отловить эту проблему.
Ну и еще — раз заговорили о VPS хостингах — мы всегда используем недорогие (hetzner, ovh, scaleway). И по бенчмаркам и по стабильности — очень нравится. Используем и гораздо более дорогой Amazon EC2 для других проектов. Так вот, благодаря okerr у нас есть свое обоснованное мнение. Падают — и те и другие. И я бы не сказал, что за долгое время наших наблюдений дешевые хостинги вроде hetzner оказались заметно менее стабильны, чем EC2. Поэтому, если вы не завязаны на другие фичи Амазона — зачем платить больше? 🙂
Что дальше?
Если на этом этапе я вас еще не сильно отпугнул от Okerr’а — то попробуйте! Прямо по этой ссылке можно зайти в (Кликните прямо сейчас!). Но учитывайте — что демо аккаунт один на всех, поэтому, если вы что-то делаете — кто-то другой в этом же аккаунте может в это же время помешать вам. Или (лучше) зарегистрируейтесь через ссылку на — все просто, без SMS. Если не любите использовать свой настоящий емейл — можно одноразовый, типа mailinator’а (Я рекомендую ). Такие аккаунты со временем могут удаляться — но для теста подойдет.
После регистрации будет предложено пройти тренинг (выполнить несколько не очень сложных обучающих задач). Изначальные лимиты очень небольшие, но для тренинга или одного сервера их достаточно. После прохождения тренинга — лимиты (например, максимальное количество индикаторов) будут повышены.
Из документации — в первую очередь на серверную часть и на клиент (). Но если что-то непонятно — пишите на support (at) okerr.com или оставляйте тикет — постараемся быстро все решить.
Если будете использовать всерьез и этих повышенных лимитов будет не хватать — тоже, напишите в саппорт, увеличим (бесплатно).
Захотите поставить сервер okerr на свой сервер? Вот . Мы рекомендуем ставить на чистую виртуалку, тогда получится это просто сделать установочным скриптом. На своей виртуалке — никаких ограничений :-). Ну и опять же — если что — всегда постараемся помочь.
Мы хотим чтобы этот проект взлетел, чтобы мир стал надежнее благодаря нам. Благодаря бесплатному ПО и сервисам мир стал дружественнее и развивается динамичнее. Исходники можно хранить в бесплатном github’е, для почты использовать бесплатный gmail. Мы используем бесплатный для саппорта. Ни для чего этого не нужно оплачивать сервера, не нужно скачивать и настраивать и решать разные проблемы с эксплуатацией. Каждый новый проект, каждая команда — сразу и имеет и почту, и репозитории и CRM. И все это очень качественное и бесплатно и сразу. Мы хотим, чтобы для мониторинга было так же — небольшие компании и проекты могли бы бесплатно использовать okerr и даже на этапе рождения и роста иметь надежность как у взрослых серьезных проектов.
Источник: habr.com
