

Как вырасти в 10 раз под количеству запросов к БД не переезжая на более производительный сервер и сохранить работоспособность системы? Я расскажу, как мы боролись с падением производительности нашей базы данных, как оптимизировали SQL запросы, чтобы обслуживать как можно больше пользователей и не повышать расходы на вычислительные ресурсы.
Я делаю сервис для управления бизнес процессами в строительных компаниях. С нами работает около 3 тысяч компаний. Более 10 тысяч человек каждый день работают с нашей системой по 4-10 часов. Она решает разные задачи планирования, оповещения, предупреждения, валидации… Мы используем PostgreSQL 9.6. В базе данных у нас около 300 таблиц и каждые сутки в нее поступает до 200 млн запросов (10 тысяч различных). В среднем у нас 3-4 тысяч запросов в секунду, в самые активные моменты более 10 тысяч запросов в секунду. Большая часть запросов — OLAP. Добавлений, модификаций и удалений намного меньше, то есть OLTP нагрузка относительно небольшая. Все эти цифры я привел, чтобы вы могли оценить масштаб нашего проекта и понять насколько наш опыт может быть полезен для вас.
Картина первая. Лирическая
Когда мы начинали разработку, то особо не задумывались о том, какая нагрузка ляжет на БД и что мы будем делать если сервер перестанет вытягивать. При проектировании БД мы следовали общим рекомендациям и старались не стрелять себе в ногу, но дальше общих советов вроде “не используйте паттерн мы не заходили. Проектировали исходя из принципов нормализации избегая избыточности данных и не заботились об ускорения тех или иных запросов. Как только пришли первые пользователи мы столкнулись с проблемой производительности. Как обычно мы оказались абсолютно не готовы к этому. Первые проблемы оказались простыми. Как правило все решалось добавлением нового индекса. Но наступил момент когда простые заплатки перестали работать. Осознав, что опыта не хватает и нам все сложнее понять в чем причина проблем, мы наняли специалистов, которые помогли нам правильно настроить сервер, подключить мониторинг, показали куда смотреть, чтобы получить .
Картина вторая. Статистическая
Итак у нас есть около 10 тысяч различных запросов, которые выполняются на нашей БД за сутки. Из этих 10 тысяч есть монстры, которые выполняются по 2-3 млн раз со средним временем выполнения 0.1-0.3 мс и есть запросы со средним временем выполнения 30 секунд, которые вызываются 100 раз в сутки.
Оптимизировать все 10 тысяч запросов не представлялось возможным, поэтому мы решили разобраться с тем, куда направлять усилия, чтобы повышать производительность БД правильно. После нескольких итераций мы стали делить запросы на типы.
TOP запросы
Это самые тяжелые запросы, которые занимают больше всего времени (total time). Это запросы, которые либо очень часто вызываются либо запросы, которые очень долго выполняются (долгие и частые запросы были оптимизированы еще на первых итерациях борьбы за скорость). В итоге суммарно на их исполнение сервер тратит больше всего времени. Причем важно отделять топ запросы по общему времени исполнения и отдельно по IO time. Способы оптимизации таких запросов немного разные.
Обычная практика всех компаний- работать с TOP запросами. Их немного, оптимизация даже одного запроса может освободить 5-10% ресурсов. Однако, по мере “взросления” проекта оптимизация TOP запросов становится все более нетривиальной задачей. Все простые способы уже отработаны, да и самый “тяжелый” запрос отнимает “всего” 3-5% ресурсов. Если TOP запросы в сумме занимают менее 30-40% времени, то скорее всего вы уже приложили усилия, чтобы они работали быстро и пришла пора переходить к оптимизации запросов из следующей группы.
Остается ответить на вопрос сколько верхних запросов включить в эту группу. Я обычно беру не меньше 10, но не больше 20. Стараюсь, чтобы время первого и последнего в TOP группе отличалось не более чем в 10 раз. То есть если время исполнения запросов резко падает с 1 места до 10, то беру TOP-10, если падение более плавное, то увеличиваю размер группы до 15 или 20.
Середняки (medium)
Это все запросы, которые идут сразу за TOP, за исключением последних 5-10%. Обычно в оптимизации именно этих запросов кроется возможность сильно поднять производительность сервера. Эти запросы могут “весить” до 80%. Но даже если их доля перевалила за 50%, значит пора на них взглянуть более внимательно.
Хвост (tail)
Как было сказано, эти запросы идут в конце и на них уходит 5-10% времени. Про них можно забыть, только если вы не используете автоматические средства анализа запросов, тогда их оптимизация тоже может дешево обойтись.
Как оценить каждую группу?
Я использую SQL запрос, который помогает сделать такую оценку для PostgreSQL (уверен что для многих других СУБД можно написать похожий запрос)
SQL запрос для оценки размера TOP-MEDIUM-TAIL групп
SELECT sum(time_top) AS sum_top, sum(time_medium) AS sum_medium, sum(time_tail) AS sum_tail
FROM
(
SELECT CASE WHEN rn <= 20 THEN tt_percent ELSE 0 END AS time_top,
CASE WHEN rn > 20 AND rn <= 800 THEN tt_percent ELSE 0 END AS time_medium,
CASE WHEN rn > 800 THEN tt_percent ELSE 0 END AS time_tail
FROM (
SELECT total_time / (SELECT sum(total_time) FROM pg_stat_statements) * 100 AS tt_percent, query,
ROW_NUMBER () OVER (ORDER BY total_time DESC) AS rn
FROM pg_stat_statements
ORDER BY total_time DESC
) AS t
)
AS ts
Результат запроса- три столбца, каждый из которых содержит процент времени, который уходит на обработку запросов из этой группы. Внутри запроса есть два числа (в моем случае это 20 и 800), которые отделяет запросы одной группы от другой.
Вот так примерно соотносятся доли запросов на момент начала работ по оптимизации и сейчас.
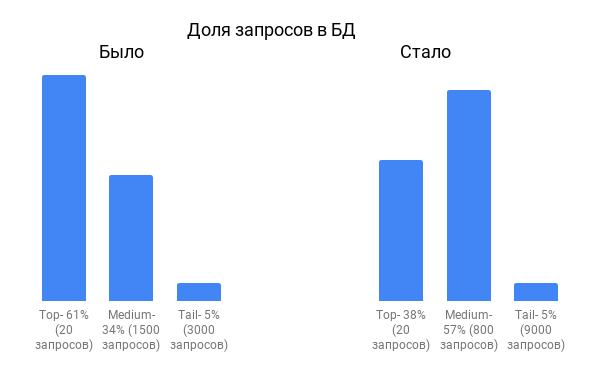
Из диаграммы видно, что доля TOP запросов резко снизилась, зато выросли “середняки”.
Поначалу в TOP запросы попадали откровенные ляпы. Со временем детские болезни исчезли, доля TOP запросов сокращалась, приходилось прилагать все больше усилий, чтобы ускорить тяжелые запросы.
Чтобы получить текст запросов используем такой запрос
SELECT * FROM (
SELECT ROW_NUMBER () OVER (ORDER BY total_time DESC) AS rn, total_time / (SELECT sum(total_time) FROM pg_stat_statements) * 100 AS tt_percent, query
FROM pg_stat_statements
ORDER BY total_time DESC
) AS T
WHERE
rn <= 20 -- TOP
-- rn > 20 AND rn <= 800 -- MEDIUM
-- rn > 800 -- TAIL
Вот список самых часто используемых приемов, которые помогали нам ускорять TOP запросы:
- Redesign системы, например переработка логики уведомлений на message broker вместо периодических запросов к БД
- Добавление или изменение индексов
- Переписывание ORM запросов на чистый SQL
- Переписывание логики lazy подгрузки данных
- Кеширование через денормализацию данных. Например у нас есть связь таблиц Доставка -> Счет -> Запрос -> Заявка. То есть каждая доставка связана с заявкой через другие таблицы. Чтобы не связывать в каждом запросе все таблицы, мы продублировали ссылку на заявку в таблице Доставка.
- Кэширование статических таблиц со справочниками и редко меняющихся таблиц в памяти программы.
Иногда изменения тянули на внушительный редизайн, но давали 5-10% разгрузки системы и были оправданы. Со временем выхлоп становился все меньше, а редизайн требовался все более серьезный.
Тогда мы обратили внимание на вторую группу запросов- группу середняков. В ней намного больше запросов и казалось, что на анализ всей группы уйдет очень много времени. Однако большинство запросов оказались очень просты для оптимизации, а многие проблемы повторялись десятки раз в разнличных вариациях. Вот примеры некоторых типовых оптимизаций, который мы применяли к десяткам похожих запросов и каждая группа оптимизированных запросов разгружала БД на 3-5%.
- Вместо проверки наличия записей с помощью COUNT и полного сканирования таблицы стали использовать EXISTS
- Избавились от DISTINCT (нет общего рецепта, но иногда можно легко от него избавиться ускоряя запрос в 10-100 раз).
Например, вместо запроса для выборки всех водителей по большой таблице доставок (DELIVERY)
SELECT DISTINCT P.ID, P.FIRST_NAME, P.LAST_NAME FROM DELIVERY D JOIN PERSON P ON D.DRIVER_ID = P.IDсделали запрос по сравнительно небольшой таблице PERSON
SELECT P.ID, P.FIRST_NAME, P.LAST_NAME FROM PERSON WHERE EXISTS(SELECT D.ID FROM DELIVERY WHERE D.DRIVER_ID = P.ID)Казалось бы, мы использовали коррелирующий подзапрос, но он дает ускорение более чем в 10 раз.
- Во многих случаях вообще отказались от COUNT и
- вместо
UPPER(s) LIKE JOHN%’используем
s ILIKE “John%”
Каждый конкретный запрос удавалось ускорить порой в 3-1000 раз. Несмотря на впечатляющие показатели, поначалу нам казалось, что нет смысла в оптимизации запроса, который выполняется 10 мс, входит в 3-ю сотню самых тяжелых запросов и в общем времени нагрузки на БД занимает сотые доли процента. Но применяя один и тот же рецепт к группе однотипных запросов мы отыгрывали по несколько процентов. Чтобы не тратить время на ручной просмотр всех сотен запросов мы написали несколько простых скриптов, которые с помощью регулярных выражений находили однотипные запросы. В итоге автоматический поиск групп запросов позволил нам еще больше улучшить нашу производительность, затратив скромные усилия.
В итоге мы уже три года работаем на одном и том же железе. Среднесуточная нагрузка около 30%, в пиках доходит до 70%. Количество запросов как и количество пользователей выросло примерно в 10 раз. И все это благодаря постоянному мониторингу этих самых групп запросов TOP-MEDIUM. Как только какой-то новый запрос появляется в группе TOP, мы его тут же анализируем и пытаемся ускорить. Группу MEDIUM мы раз в неделю просматриваем с помощью скриптов анализа запросов. Если попадаются новые запросы, которые мы уже знаем как оптимизировать, то мы их быстро меняем. Иногда находим новые способы оптимизации, которые можно применить сразу к нескольким запросам.
По нашим прогнозам текущий сервер выдержит увеличение количества пользователей еще в 3-5 раз. Правда у нас есть еще один козырь в рукаве- мы до сих пор не перевели SELECT- запросы на зеркало, как рекомендуется делать. Но мы этого не делаем осознанно, так как хотим сначала до конца исчерпать возможности «умной» оптимизации, прежде чем включать «тяжелую артиллерию».
Критический взгляд на проделанную работу может подсказать использовать вертикальное масштабирование. Купить более мощный сервер, вместо того, чтобы тратить время специалистов. Сервер может стоить не так дорого, тем более что лимиты вертикального масштабирования у нас еще не исчерпаны. Однако в 10 раз выросло лишь количество запросов. За несколько лет, увеличился функционал системы и сейчас разновидностей запросов стало больше. Тот функционал, который был, за счет кеширования выполняется меньшим количеством запросов, к тому же более эффективных запросов. Значит можно смело умножить еще на 5, чтобы получить реальный коэффициент ускорения. Итак по самым скромным подсчетам можно сказать, что ускорение составило 50 и более раз. Вертикально раскачать сервер в 50 раз обошлось бы дороже. Особенно учитывая, что однажды проведенная оптимизация работает все время, а счет за арендованный сервер приходит каждый месяц.
Источник: habr.com
