

Любой крупный проект начинался с пары серверов. Cначала был один DB-сервер, потом к нему добавились слейвы, чтобы масштабировать чтение. И тут — стоп! Мастер один, а слейвов много; если уйдет один из слейвов, то всё будет хорошо, а если уйдет мастер — будет плохо: даунтайм, админы в мыле поднимают сервер. Что делать? Резервировать мастер. Мой коллега Павел уже писал об этом , я не буду ее повторять. Вместо этого расскажу, почему вам обязательно нужен Orchestrator для MySQL!
Начнем с главного вопроса: «Как мы будем переключать код на новую машину при уходе мастера?».
- Схема с VIP (Virtual IP) мне нравится больше всего, про нее мы и поговорим ниже. Она самая простая и очевидная, хотя имеет явное ограничение: мастер, который мы будем резервировать, должен находиться в L2-сегменте с новой машиной, то есть о втором ДЦ можно забыть. Да и, по-хорошему, если следовать правилу, что большой L2 — это зло, потому что L2 только на стойку, а между стойками L3, а такая схема имеет еще больше ограничений.
- Можно прописать в коде DNS-имя и резолвить его через /etc/hosts. На самом деле резолва не будет. Достоинство схемы: нет ограничения, характерного для первого способа, то есть можно и cross-ДЦ организовать. Но тогда возникает очевидный вопрос, как быстро мы через Puppet-Ansible подвезем изменение в /etc/hosts.
- Можно второй способ немного изменить: на всех веб-серверах ставим кэширующий DNS, через который код будет ходить в мастер-базу. Можно прописать TTL 60 для этой записи в DNS. Кажется, что при правильной реализации способ хороший.
- Схема с service discovery, подразумевающая применение Consul и etcd.
- Интересный вариант с . Нужно весь трафик на MySQL завернуть через ProxySQL, ProxySQL сам умеет определять кто сейчас мастер. Кстати про один из вариантов использования данного продукта можно прочитать в моей .
Автор Orchestrator, работая в Github, сначала реализовал первую схему с VIP, а потом переделал на схему c consul.
Типичная схема инфраструктуры:
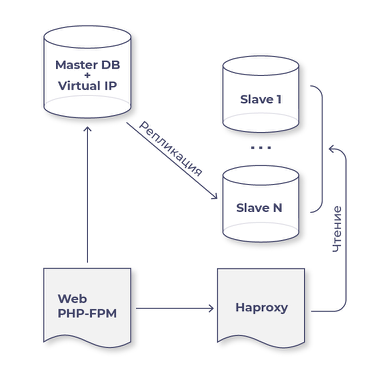
Сразу опишу очевидные ситуации, которые нужно учесть:
- VIP-адрес не должен быть прописан в конфиге ни на одном из серверов. Представим ситуацию: мастер перезагрузился, а пока он грузится, Orchestrator перешел в режим failover и сделал мастером один из слейвов; затем поднялся старый мастер, и теперь VIP на двух машинах. Это плохо.
- Для оркестратора нужно будет написать скрипт обращения к старому мастеру и новому мастеру. На старом необходимо выполнять ifdown, а на новом мастере — ifup vip. Хорошо бы еще в этот скрипт вписать, что в случае failover порт на коммутаторе старого мастера просто тушится, чтобы избежать любого splitbrain.
- После того, как Orchestrator вызвал ваш скрипт, чтобы сначала снять VIP и/или потушить порт на коммутаторе, а затем на новом мастере вызвал скрипт поднятия VIP, не забудьте командой arping сказать всем, что новый VIP теперь тут.
- На всех слейвах должно быть read_only=1, а как только промоутируете слейв до мастера, у него должно стать read_only=0.
- Не забывайте, что мастером может стать любой слейв, который мы выбрали для этого (у Orchestrator есть целый механизм предпочтения, какой слейв рассмотреть кандидатом на новый мастер в первую очередь, какой во вторую, а какой слейв вообще ни при каких обстоятельствах не должен быть выбран мастером). Если слейв станет мастером, то на нём останется нагрузка слейва и добавится нагрузка мастера, это нужно учитывать.
Почему же вам непременно нужен Orchestrator, если у вас его нет?
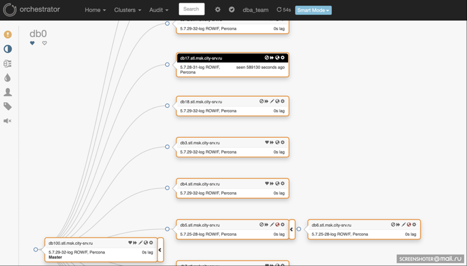
- У Orchestrator очень удобный графический интерфейс, отображающий всю топологию (смотрите скриншот ниже).
- Orchestrator может отслеживать, какие слейвы отстали, а где репликация вообще сломалась (у нас к Orchestrator прикручены скрипты для отправки SMS).
- Orchestrator говорит вам, на каких слейвах есть ошибка GTID errant.
Интерфейс Orchestrator:
Что же такое GTID errant?
Есть два основных требования для работы Orchestrator:
- Нужно, чтобы на всех машинах MySQL-кластера был включен pseudo GTID, у нас включен GTID.
- Нужно, чтобы везде был один тип бинлогов, можно statement. У нас была такая конфигурация, при которой на мастере и на большинстве слейвов был Row, а на двух исторически остался режим Mixed. В результате эти слейвы Orchestrator просто не захотел подключать в новому мастеру.
Помните, что самое главное в production-слейве — его консистентность с мастером! Если у вас и на мастере, и на слейв включен Global Transaction ID (GTID), то через функцию gtid_subset можно узнать, действительно ли на этих машинах выполнены одни и те же запросы на изменения данных. Подробнее об этом почитать можно .
Таким образом, Orchestrator показывает вам через ошибку GTID errant, что на слейве есть транзакции, которых нет на мастере. Почему так происходит?
- На слейве не включен read_only=1, кто-то подключился и выполнил запрос на изменение данных.
- На слейве не включен super_read_only=1, тогда админ, перепутав сервер, зашел и выполнил там запрос.
- Если вы учли оба предыдущих пункта, то есть ещё одна хитрость: в MySQL запрос о flush бинлогов тоже попадает в бинлог, поэтому при первом же flush на мастере и на всех слейвах появится GTID errant. Как этого избежать? В perona-5.7.25-28 появилась настройка binlog_skip_flush_commands=1, запрещающая писать flush в бинлоги. На сайте mysql.com есть заведенный .
Резюмирую все вышесказанное. Если вы пока не хотите использовать Orchestrator в режиме failover, то поставьте его в режиме наблюдения. Тогда у вас всегда будет перед глазами карта взаимодействия MySQL-машин и наглядная информация о том, какой тип репликации на каждой машине, отстают ли слейвы, и самое главное — насколько они консистентносты с мастером!
Очевидный вопрос: «А как же должен работать Orchestrator?». Он должен выбрать новый мастер из текущих слейвов, а потом переподключить к нему все слейвы (именно для этого нужен GTID; если использовать старый механизм с binlog_name и binlog_pos, то переключение слейва с текущего мастера на новый просто невозможно!). До того, как у нас появился Orchestrator, мне однажды пришлось делать всё это вручную. Старый мастер зависал из-за глючного контроллера Adaptec, у него было около 10 слейвов. Мне нужно было перекинуть VIP с мастера на один из слейвов и переподключить на него все остальные слейвы. Сколько же консолей мне пришлось открыть, сколько одновременных команд ввести… Пришлось подождать до 3 часов ночи, снять нагрузку со всех слейвов, кроме двух, сделать мастером первую машину из двух, сразу к ней подцепить вторую машину, потому к новому мастеру подцепить все остальные слейвы и вернуть нагрузку. В общем, ужас…
Как работает Orchestrator, когда переходит в режим failover? Это легче всего показать на примере ситуации, когда мы хотим сделать мастером более мощную, более современную машину, чем сейчас.
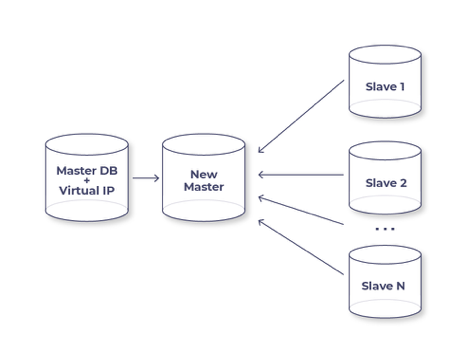
На рисунке представлена середина процесса. Что уже было сделано до этого момента? Мы сказали, что хотим сделать какой-то слейв новым мастером, Orchestrator начал просто переподключать к нему все остальные слейвы, при этом новый мастер выполняет роль транзитной машины. При такой схеме ошибок не возникает, все слейвы работают, Orchestrator снимает VIP со старого мастера, переносит на новый, делает read_only=0 и забывает о старом мастере. Всё! Даунтайм нашего сервиса – это время переноса VIP, это 2-3 секунды.
На сегодня всё, всем спасибо. Скоро будет вторая статья про Orchestrator. В известном советском фильме «Гараж» один герой сказал «Я с ним бы в разведку не пошёл!» Так вот, Orchestrator, я с тобой в разведку пошел бы!
Источник: habr.com
