

В статье я расскажу, как мы подошли к вопросу отказоустойчивости PostgreSQL, почему это стало для нас важно и что в итоге получилось.
У нас высоконагруженный сервис: 2,5 млн пользователей по всему миру, 50К+ активных пользователей каждый день. Сервера находятся в Amazone в одном регионе Ирландии: в работе постоянно 100+ различных серверов, из них почти 50 — с базами данных.
Весь backend — большое монолитное stateful-приложение на Java, которое держит постоянное websocket соединение с клиентом. При одновременной работе нескольких пользователей на одной доске все они видят изменения в режиме реального времени, потому что каждое изменение мы записываем в базу. У нас примерно 10К запросов в секунду к нашим базам. В пиковой нагрузке в Redis мы пишем по 80-100К запросов в секунду.
Почему мы перешли с Redis на PostgreSQL
Изначально наш сервис работал с Redis, key-value хранилищем, которое хранит все данные в оперативной памяти сервера.
Плюсы Redis:
- Высокая скорость ответа, т.к. всё хранится в памяти;
- Удобство бэкапа и репликации.
Минусы Redis для нас:
- Нет настоящих транзакций. Мы пытались имитировать их на уровне нашего приложения. К сожалению, это не всегда хорошо работало и требовало написания очень сложного кода.
- Объём данных ограничен количеством памяти. При увеличении количества данных память будет расти, и, в конце концов, мы упрёмся в характеристики выбранного инстанса, что в AWS требует остановки нашего сервиса для изменения типа инстанса.
- Необходимо постоянно поддерживать уровень низкого latency, т.к. у нас очень большое количество запросов. Оптимальный для нас уровень задержки — 17-20 ms. При уровне 30-40 ms мы получаем долгие ответы на запросы нашего приложения и деградацию сервиса. К сожалению, у нас это случилось в сентябре 2018 года, когда один из инстансов с Redis почему-то получил latency в 2 раза больше обычного. Для решения проблемы мы остановили сервис в середине рабочего дня для внепланового maintenance и заменили проблемный инстанс Redis.
- Легко получить неконсинстентность данных даже при незначительных ошибках в коде и потом потратить много времени на написание кода для исправления этих данных.
Мы учли минусы и поняли, что нам необходимо переехать на что-то более удобное, с нормальными транзакциями и меньшей зависимостью от latency. Провели исследование, проанализировали множество вариантов и выбрали PostgreSQL.
На новую БД мы переезжаем уже 1,5 года и перевезли только небольшую часть данных, поэтому сейчас работаем одновременно с Redis и PostgreSQL. Подробнее об этапах переезда и переключении данных между БД написано в статье моего коллеги.
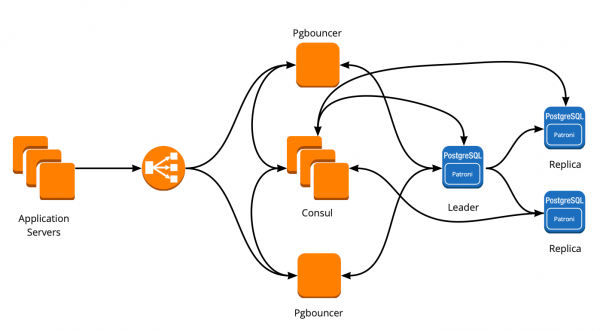
Когда мы только начинали переезжать, наше приложение работало напрямую с БД и обращалось к мастеру Redis и PostgreSQL. Кластер PostgreSQL состоял из мастера и реплики с асинхронной репликацией. Так выглядела схема работы с базами:
Внедрение PgBouncer
Пока мы переезжали, продукт тоже развивался: увеличивалось количество пользователей и количество серверов, которые работали с PostgreSQL, и нам стало не хватать соединений. PostgreSQL на каждое соединение создаёт отдельный процесс и потребляет ресурсы. Увеличивать число коннектов можно до определённого момента, иначе есть шанс получить неоптимальную работу БД. Идеальным вариантом в такой ситуации будет выбор менеджера коннектов, который встанет перед базой.
У нас было два варианта для менеджера соединений: Pgpool и PgBouncer. Но первый не поддерживает транзакционный режим работы с базой, поэтому мы выбрали PgBouncer.
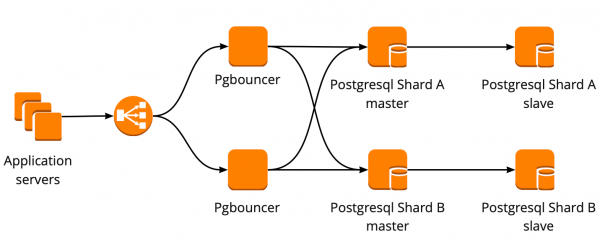
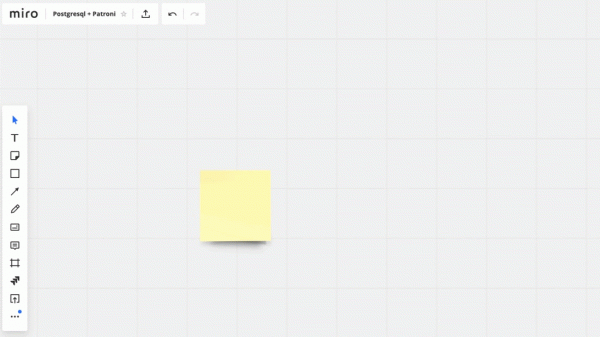
Мы настроили следующую схему работы: наше приложение обращается к одному PgBouncer, за которым находятся masters PostgreSQL, а за каждым мастером — одна реплика с асинхронной репликацией.
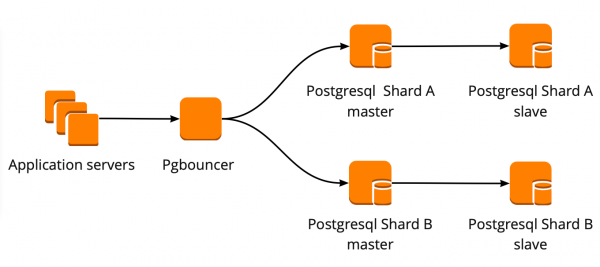
При этом мы не могли хранить весь объём данных в PostgreSQL и для нас была важна скорость работы с базой, поэтому мы начали шардировать PostgreSQL на прикладном уровне. Описанная выше схема является для этого относительно удобной: при добавлении нового шарда PostgreSQL достаточно обновить конфигурацию PgBouncer и приложение может сразу работать с новым шардом.
Отказоустойчивость PgBouncer
Эта схема проработала до момента, пока единственный инстанс PgBouncer не умер. Мы находимся в AWS, где все инстансы запущены на железе, которое периодически умирает. В таких случаях инстанс просто переезжает на новое железо и снова работает. Так произошло и с PgBouncer, однако он стал недоступен. Результатом этого падения стала недоступность нашего сервиса в течение 25 минут. AWS для таких ситуаций рекомендует использовать избыточность на стороне пользователя, что не было реализовано у нас на тот момент.
После этого мы всерьёз задумались об отказоустойчивости PgBouncer и кластеров PostgreSQL, потому что подобная ситуация могла повториться с любым инстансом в нашем AWS аккаунте.
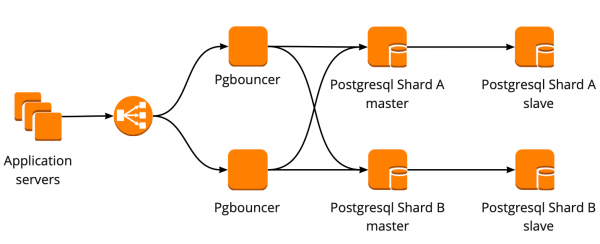
Схему отказоустойчивости PgBouncer мы построили следующим образом: все сервера приложения обращаются к Network Load Balancer, за которым стоят два PgBouncer. Каждый из PgBouncer смотрит на одни и те же master PostgreSQL каждого шарда. В случае повторения ситуации с падением инстанса AWS, весь трафик перенавравляется через другой PgBouncer. Отказоустойчивость Network Load Balancer обеспечивает AWS.
Такая схема позволяет без проблем добавлять новые сервера PgBouncer.
Создание отказоустойчивого кластера PostgreSQL
При решении этой задачи мы рассматривали разные варианты: самописный failover, repmgr, AWS RDS, Patroni.
Самописные скрипты
Могут мониторить работу мастера и, в случае его падения, продвигать реплику до мастера и обновлять конфигурацию PgBouncer.
Плюсы такого подхода в максимальной простоте, потому что вы сами пишите скрипты и точно понимаете, как они работают.
Минусы:
- Мастер мог не умереть, вместо этого мог произойти сетевой сбой. Failover, не зная об этом, продвинет реплику до мастера, а старый мастер будет продолжать работать. В результате мы получим два сервера в роли master и не будем знать, на каком из них последние актуальные данные. Такую ситуацию называют ещё split-brain;
- Мы остались без реплики. В нашей конфигурации мастер и одна реплика, после переключения реплика продвигается до мастера и у нас больше нет реплик, поэтому приходится в ручном режиме добавлять новую реплику;
- Нужен дополнительный мониторинг работы failover, при этом у нас 12 шардов PostgreSQL, а значит мы должны мониторить 12 кластеров. При увеличении количества шардов надо ещё не забыть обновить failover.
Самописный failover выглядит очень сложно и требует нетривиальной поддержки. При одном PostgreSQL кластере это будет самым простым вариантом, но он не масштабируется, поэтому не подходит для нас.
Repmgr
Replication Manager for PostgreSQL clusters, который умеет управлять работой кластера PostgreSQL. При этом в нём нет автоматического failover “из коробки”, поэтому для работы потребуется писать свою “обёртку” поверх готового решения. Так что всё может получится даже сложнее, чем с самописными скриптами, поэтому Repmgr мы даже не стали пробовать.
AWS RDS
Поддерживает всё необходимое для нас, умеет делать бэкапы и поддерживает пул коннектов. Имеет автоматическое переключение: при смерти мастера реплика становится новым мастером, а AWS меняет dns запись на нового мастера, при этом реплики могут находится в разных AZ.
К минусам можно отнести отсутствие тонких настроек. Как пример тонких настроек: на наших инстансах стоят ограничения для tcp коннектов, чего, к сожалению, нельзя сделать в RDS:
net.ipv4.tcp_keepalive_time=10
net.ipv4.tcp_keepalive_intvl=1
net.ipv4.tcp_keepalive_probes=5
net.ipv4.tcp_retries2=3
Кроме того у AWS RDS цена почти в два раза дороже обычной цены instance, что и послужило главной причиной отказа от этого решения.
Patroni
Это шаблон на python для управления PostgreSQL с хорошей документацией, автоматическим failover и исходным кодом на github.
Плюсы Patroni:
- Расписан каждый параметр конфигурации, понятно как что работает;
- Автоматический failover работает из коробки;
- Написан на python, а так как мы сами много пишем на python, то нам будет проще разбираться с проблемами и, возможно, даже помочь развитию проекта;
- Полностью управляет PostgreSQL, позволяет менять конфигурацию сразу на всех нодах кластера, а если для применения новой конфигурации требуется перезапуск кластера, то это можно сделать опять же с помощью Patroni.
Минусы:
- Из документации непонятно, как правильно работать с PgBouncer. Хотя минусом это назвать сложно, потому что задача Patroni — управлять PostgreSQL, а как будут ходить подключения к Patroni — уже наша проблема;
- Мало примеров внедрения Patroni на больших объёмах, при этом много примеров внедрения с нуля.
В итоге для создания отказоустойчивого кластера мы выбрали именно Patroni.
Процесс внедрения Patroni
До Patroni у нас было 12 шардов PostgreSQL в конфигурации один мастер и одна реплика с асинхронной репликацией. Сервера приложения обращались к базам данных через Network Load Balancer, за которым стояли два instance с PgBouncer, а за ними находились все PostgreSQL сервера.
Для внедрения Patroni нам нужно было выбрать распределенное хранилище конфигурации кластера. Patroni работает с распределёнными системами хранения конфигураций, такими как etcd, Zookeeper, Сonsul. У нас как раз на проде есть полноценный кластер Consul, который работает в связке с Vault и больше мы его никак не используем. Отличный повод начать использовать Consul по назначению.
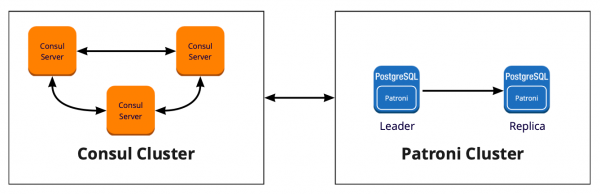
Как работает Patroni с Consul
У нас есть кластер Сonsul, который состоит из трёх нод и кластер Patroni, который состоит из лидера и реплики (в Patroni мастер называется лидером кластера, а слейвы — репликами). Каждый инстанс кластера Patroni постоянно посылает в Consul информацию о состоянии кластера. Поэтому из Сonsul всегда можно узнать текущую конфигурацию кластера Patroni и того, кто является лидером в данный момент.
Для подключения Patroni к Сonsul достаточно изучить официальную документацию, в которой написано, что необходимо указать хост в формате http или https в зависимости от того, как мы работаем с Сonsul, и схему подключения, опционально:
host: the host:port for the Consul endpoint, in format: http(s)://host:port
scheme: (optional) http or https, defaults to httpВыглядит просто, но тут начинаются подводные камни. С Сonsul мы работаем по защищённому соединению через https и наш конфиг подключения будет выглядеть следующим образом:
consul:
host: https://server.production.consul:8080
verify: true
cacert: {{ consul_cacert }}
cert: {{ consul_cert }}
key: {{ consul_key }}Но так не работает. При старте Patroni не может подключиться к Сonsul, потому что пытается всё равно идти по http.
Разобраться с проблемой помог исходный код Patroni. Хорошо, что он написан на python. Оказывается параметр host никак не парсится, а протокол необходимо указать в scheme. Вот так выглядит работающий блок конфигурации для работы с Сonsul у нас:
consul:
host: server.production.consul:8080
scheme: https
verify: true
cacert: {{ consul_cacert }}
cert: {{ consul_cert }}
key: {{ consul_key }}Consul-template
Итак, хранилище для конфигурации мы выбрали. Теперь нужно понять, как PgBouncer будет переключать свою конфигурацию при смене лидера в кластере Patroni. В документации на этот вопрос ответа нет, т.к. там в принципе не описана работа с PgBouncer.
В поисках решения мы нашли статью (название, к сожалению, не помню), где было написано, что Сonsul-template очень помог в связке PgBouncer и Patroni. Это подтолкнуло нас на исследование работы Consul-template.
Оказалось, что Сonsul-template постоянно мониторит конфигурацию кластера PostgreSQL в Сonsul. При смене лидера он обновляет конфигурацию PgBouncer и отправляет команду на её перезагрузку.
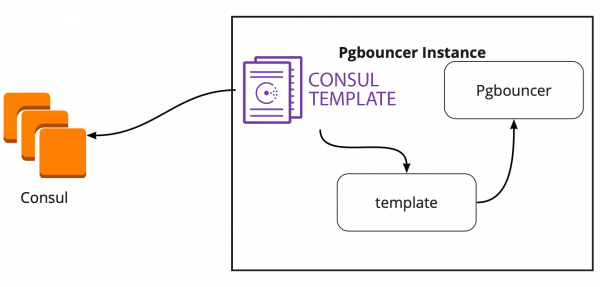
Большой плюс template в том, что он хранится в виде кода, поэтому при добавлении нового шарда достаточно сделать новый коммит и обновить template в автоматическом режиме, поддерживая принцип Infrastructure as code.
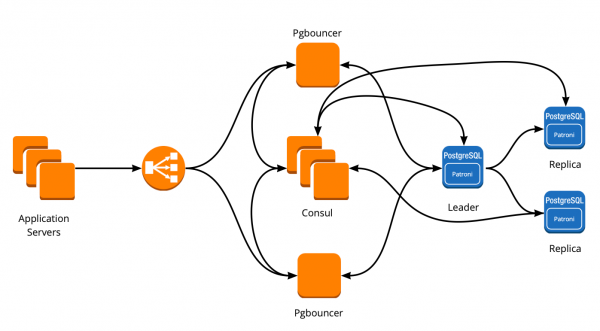
Новая архитектура с Patroni
В результате мы получили такую схему работы:
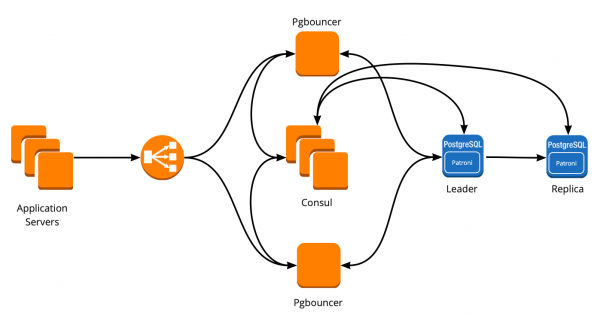
Все сервера приложения обращаются к балансировщику → за ним стоят два instance PgBouncer → на каждом instance запущен Сonsul-template, который мониторит состояние каждого кластера Patroni и следит за актуальностью конфига PgBouncer, который направляет запросы на текущего лидера каждого кластера.
Ручное тестирование
Эту схему перед выводом на прод мы запустили на небольшой тестовой среде и проверили работу автоматического переключения. Открывали доску, передвигали стикер и в этот момент “убивали” лидера кластера. В AWS для этого достаточно выключить инстанс через консоль.
Стикер в течение 10-20 секунд возвращался назад, а потом вновь начинал нормально перемещаться. Значит, кластер Patroni сработал верно: сменил лидера, отправил информацию в Сonsul, а Сonsul-template сразу подхватил эту информацию, заменил конфигурацию PgBouncer и отправил команду на reload.
Как выжить под высокой нагрузкой и сохранить минимальный даунтайм?
Всё работает отлично! Но появляются новые вопросы: Как это сработает под высокой нагрузкой? Как быстро и безопасно раскатать всё на production?
Ответить на первый вопрос нам помогает тестовая среда, на которой мы проводим нагрузочное тестирование. Она полностью идентична production по архитектуре и имеет сгенерированные тестовые данные, которые по объёму примерно равны production. Мы решаем просто “убить” один из мастеров PostgreSQL во время теста и посмотреть, что будет. Но перед этим важно проверить автоматическую раскатку, ведь на этой среде у нас есть несколько шардов PostgreSQL, так что мы получим отличное тестирование конфигурационных скриптов перед продом.
Обе задачи выглядят амбициозно, но у нас PostgreSQL 9.6. Может мы сразу на 11.2 обновимся?
Мы решаем сделать это в 2 этапа: сначала обновить версию до 11.2, потом запустить Patroni.
Обновление PostgreSQL
Для быстрого обновления версии PostgreSQL необходимо использовать опцию -k, в которой создаются hard link на диске и нет необходимости в копировании ваших данных. На базах в 300-400 ГБ обновление занимает 1 секунду.
У нас много шардов, поэтому обновление нужно сделать в автоматическом режиме. Для этого мы написали Ansible playbook, который выполняет весь процесс обновления за нас:
/usr/lib/postgresql/11/bin/pg_upgrade
<b>--link </b>
--old-datadir='' --new-datadir=''
--old-bindir='' --new-bindir=''
--old-options=' -c config_file='
--new-options=' -c config_file='Здесь важно отметить, что перед запуском апгрейда необходимо выполнить его с параметром —check, чтобы быть уверенным в возможности апгрейда. Так же наш сценарий делает подмену конфигов на время апгрейда. Сценарий у нас выполнился за 30 секунд, это отличный результат.
Запуск Patroni
Для решения второй проблемы достаточно взглянуть на конфигурацию Patroni. В официальном репозитории есть пример конфигурации с initdb, который отвечает за инициализацию новой базы при первом запуске Patroni. Но так как у нас есть уже готовая база, то мы просто удалили этот раздел из конфигурации.
Когда мы начали ставить Patroni уже на готовый кластер PostgreSQL и запускать его, то столкнулись с новой проблемой: оба сервера запускались как leader. Patroni ничего не знает о раннем состоянии кластера и пытается запустить оба сервера как два отдельных кластера с одинаковым именем. Для решения этой проблемы необходимо удалить директорию с данными на slave:
rm -rf /var/lib/postgresql/Это необходимо сделать только на slave!
При подключении чистой реплики Patroni делает basebackup leader и восстанавливает его на реплику, а затем догоняет актуальное состояние по wal-логам.
Ещё одна сложность, с которой мы столкнулись, — все кластеры PostgreSQL по умолчанию называются main. Когда каждый кластер ничего не знает про другой — это нормально. Но когда вы хотите использовать Patroni, то все кластера должны иметь уникальное имя. Решение — поменять имя кластера в конфигурации PostgreSQL.
Нагрузочный тест
Мы запустили тест, который имитирует работу пользователей на досках. Когда нагрузка достигла нашего среднего дневного значения, мы повторили точно такой же тест, мы выключили один instance с leader PostgreSQL. Автоматический failover сработал так, как мы ожидали: Patroni сменил лидера, Сonsul-template обновил конфигурацию PgBouncer и отправил команду на reload. По нашим графиками в Grafana было видно, что есть задержки на 20-30 секунд и небольшой объём ошибок с серверов, связанных с соединением к базе. Это нормальная ситуация, такие значения допустимы для нашего failover и точно лучше, чем даунтайм сервиса.
Вывод Patroni на production
В итоге у нас получился следующий план:
- Деплой Сonsul-template на сервера PgBouncer и запуск;
- Обновления PostgreSQL до версии 11.2;
- Смена имени кластера;
- Запуск кластера Patroni.
При этом наша схема позволяет сделать первый пункт практически в любое время, мы можем по очереди убрать каждый PgBouncer из работы и выполнить на него деплой и запуск consul-template. Так мы и сделали.
Для быстрой раскатки мы использовали Ansible, так как все playbook мы уже проверили на тестовой среде, а время выполнения полного сценария было от 1,5 до 2 минут для каждого шарда. Мы могли всё выкатить поочередно на каждый шард без остановки нашего сервиса, но нам пришлось бы на несколько минут выключать каждый PostgreSQL. В этом случае пользователи, чьи данные есть на этом шарде, не могли бы полноценно работать в это время, а это для нас неприемлемо.
Выходом из этой ситуации стал плановый maintenance, который проходит у нас каждые 3 месяца. Это окно для плановых работ, когда мы полностью выключаем наш сервис и обновляем инстансы баз данных. До очередного окна оставалась одна неделя, и мы решили просто подождать и дополнительно подготовиться. За время ожидания мы дополнительно подстраховались: для каждого шарда PostgreSQL подняли по запасной реплике на случай неудачи, чтобы сохранить самые последние данные, и добавили по новому инстансу для каждого шарда, который должен стать новой репликой в кластере Patroni, чтоб не выполнять команду для удаления данных. Всё это помогло максимально снизить риск ошибки.
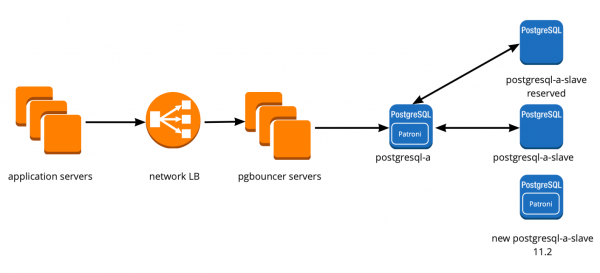
Мы перезапустили наш сервис, все заработало как надо, пользователи продолжили работать, но на графиках мы заметили аномально высокую нагрузку на Сonsul-сервера.
Почему мы не увидели это на тестовой среде? Эта проблема очень хорошо иллюстрирует, что необходимо следовать принципу Infrastructure as code и дорабатывать всю инфраструктуру, начиная с тестовых сред и заканчивая production. Иначе очень легко получить такую проблему, которую получили мы. Что произошло? Сonsul сначала появился на production, а потом на тестовых средах, в итоге на тестовых средах версия Consul была выше, чем на production. Как раз в одном из релизов была решена утечка CPU при работе с consul-template. Поэтому мы просто обновили Consul, решив таким образом проблему.
Restart Patroni cluster
Однако мы получили новую проблему, о которой даже не подозревали. При обновлении Consul мы просто удаляем ноду Consul из кластера с помощью команды consul leave → Patroni подключается к другому Consul серверу → всё работает. Но когда мы дошли до последнего инстанса кластера Consul и отправили ему команду consul leave, все кластеры Patroni просто перезапустились, а в логах мы увидели следующую ошибку:
ERROR: get_cluster
Traceback (most recent call last):
...
RetryFailedError: 'Exceeded retry deadline'
ERROR: Error communicating with DCS
<b>LOG: database system is shut down</b>Кластер Patroni не смог получить информацию о своём кластере и перезапустился.
Для поиска решения мы обратились к авторам Patroni через issue на github. Они предложили улучшения наших конфигурационных файлов:
consul:
consul.checks: []
bootstrap:
dcs:
retry_timeout: 8Мы смогли повторить проблему на тестовой среде и протестировали там эти параметры, но, к сожалению, они не сработали.
Проблема до сих пор остаётся нерешённой. Мы планируем попробовать следующие варианты решения:
- Использовать Сonsul-agent на каждом инстансе кластера Patroni;
- Исправить проблему в коде.
Нам понятно место возникновения ошибки: вероятно, проблема в использовании default timeout, который не переопределяется через файл конфигурации. При удалении последнего сервера Сonsul из кластера происходит зависание всего Сonsul-кластера, которое длится дольше секунды, из-за этого Patroni не может получить состояние кластера и полностью перезапускает весь кластер.
К счастью, больше никаких ошибок мы не встретили.
Итоги использования Patroni
После успешного запуска Patroni мы добавили по дополнительной реплике в каждом кластере. Теперь в каждом кластере есть подобие кворума: один лидер и две реплики, — для подстраховки на случай split-brain при переключении.
На production Patroni работает более трёх месяцев. За это время он уже успел нас выручить. Недавно в AWS умер лидер одного из кластеров, автоматический failover сработал и пользователи продолжили работать. Patroni выполнил свою главную задачу.
Небольшой итог использования Patroni:
- Удобство изменения конфигурации. Достаточно изменить конфигурацию на одном инстансе и она подтянется на весь кластер. Если требуется перезагрузка для применения новой конфигурации, то Patroni об этом сообщит. Patroni может перезапустить весь кластер с помощью одной команды, что тоже очень удобно.
- Автоматический failover работает и уже успел нас выручить.
- Обновление PostgreSQL без даунтайма приложения. Необходимо сначала обновить реплики на новую версию, затем сменить лидера в кластере Patroni и обновить старого лидера. При этом происходит необходимое тестирование автоматического failover.
Источник: habr.com
