

Сегодня не будет никаких сложных кейсов и мудреных алгоритмов на SQL. Все будет очень просто, на уровне Капитана Очевидность — делаем просмотр реестра событий с сортировкой по времени.
То есть вот лежит в базе табличка events, а у нее поле ts — ровно то самое время, по которому мы хотим эти записи упорядоченно показывать:
CREATE TABLE events(
id
serial
PRIMARY KEY
, ts
timestamp
, data
json
);
CREATE INDEX ON events(ts DESC);Понятно, что записей у нас там будет не десяток, поэтому нам потребуется в каком-то виде постраничная навигация.
#0. «Я у мамы погроммист»
cur.execute("SELECT * FROM events;")
rows = cur.fetchall();
rows.sort(key=lambda row: row.ts, reverse=True);
limit = 26
print(rows[offset:offset+limit]);
Даже почти не шутка — редко, но встречается в дикой природе. Иногда после работы с ORM бывает тяжело перестроиться на «прямую» работу с SQL.
Но давайте перейдем к более распространенным и менее очевидным проблемам.
#1. OFFSET
SELECT
...
FROM
events
ORDER BY
ts DESC
LIMIT 26 OFFSET $1; -- 26 - записей на странице, $1 - начало страницыОткуда тут взялось число 26? Это примерное количество записей для заполнения одного экрана. Точнее, 25 отображаемых записей, плюс 1, сигнализирующая, что дальше в выборке хоть что-то еще есть и имеет смысл двигаться дальше.
Конечно, это значение можно не «вшивать» в тело запроса, а передавать через параметр. Но в этом случае планировщик PostgreSQL не сможет опереться на знание, что записей должно оказаться относительно немного, — и запросто выберет неэффективный план.
И пока в интерфейсе приложения просмотр реестра реализован как переключение между визуальными «страницами», никто долго не замечает ничего подозрительного. Ровно до момента, когда в борьбе за удобство UI/UX не решают переделать интерфейс на «бесконечный скролл» — то есть все записи реестра рисуются единым списком, который пользователь может крутить вверх-вниз.
И вот, при очередном тестировании вас ловят на дублировании записей в реестре. Почему, ведь на таблице есть нормальный индекс (ts), на который опирается ваш запрос?
Ровно потому, что вы не учли, что ts не является уникальным ключом в этой таблице. Собственно, и значения у него не уникальны, как у любого «времени» в реальных условиях — поэтому одна и та же запись в двух соседних запросах легко «перескакивает» со страницы на страницу за счет другого конечного порядка в рамках сортировки одинакового значения ключа.
На самом деле, тут скрыта еще и вторая проблема, которую заметить много сложнее — некоторые записи не будут показаны вовсе! Ведь «сдублировавшиеся» записи заняли чье-то место. Подробное объяснение с красивыми картинками можно .
Расширяем индекс
Хитрый разработчик понимает — надо сделать ключ индекса уникальным, а самый простой способ — расширить его заведомо уникальным полем в качестве которого отлично подойдет PK:
CREATE UNIQUE INDEX ON events(ts DESC, id DESC);А запрос мутирует:
SELECT
...
ORDER BY
ts DESC, id DESC
LIMIT 26 OFFSET $1;#2. Переход на «курсоры»
Некоторое время спустя к вам приходит DBA и «радует», что ваши запросы , и вообще, пора бы перейти на навигацию от последнего показанного значения. Ваш запрос мутирует снова:
SELECT
...
WHERE
(ts, id) < ($1, $2) -- последние полученные на предыдущем шаге значения
ORDER BY
ts DESC, id DESC
LIMIT 26;Вы облегченно вздохнули, пока не наступила…
#3. Чистка индексов
Потому что однажды ваш DBA прочитал и понял, что «непоследний» timestamp — это нехорошо. И снова пришел к вам — теперь с мыслью, что вот тот индекс должен все-таки превратиться обратно в (ts DESC).
Но что же делать с первоначальной проблемой «скакания» записей между страницами?.. А все просто — надо выбирать блоки с нефиксированным количеством записей!
Вообще, кто нам запрещает читать не «ровно 26», а «не менее 26»? Например, так, чтобы в следующем блоке оказались записи с заведомо другими значениями ts — тогда ведь и проблемы с «перепрыгиванием» записей между блоками не будет!
Вот как этого добиться:
SELECT
...
WHERE
ts < $1 AND
ts >= coalesce((
SELECT
ts
FROM
events
WHERE
ts < $1
ORDER BY
ts DESC
LIMIT 1 OFFSET 25
), '-infinity')
ORDER BY
ts DESC;Что здесь вообще происходит?
- Шагаем на 25 записей «вниз» и получаем «граничное» значение
ts. - Если там уже ничего нет, то подменяем NULL-значение на
-infinity. - Вычитываем весь сегмент значений между полученным значением
tsи переданным из интерфейса параметром $1 (предыдущим «последним» отрисованным значением). - Если блок вернулся меньше чем с 26 записями — он последний.
Или то же самое картинкой:
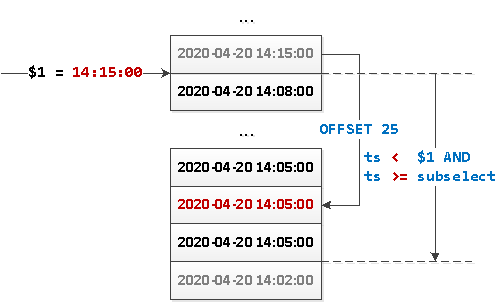
Поскольку теперь у нас выборка не имеет какого-то определенного «начала», то нам ничто не мешает «развернуть» этот запрос в обратную сторону и реализовать динамическую подгрузку блоков данных от «опорной точки» в обе стороны — как вниз, так и вверх.
Замечание
- Да, в таком случае мы обращаемся к индексу дважды, но все «чисто по индексу». Поэтому вложенный запрос приведет всего лишь к одному дополнительному Index Only Scan.
- Достаточно очевидно, что этой методикой можно пользоваться, только когда у вас значения
tsмогут пересечься лишь случайно, и их немного. Если же ваш типичный кейс — «миллион записей в 00:00:00.000», так делать не стоит. В смысле, не стоит допускать такого кейса. Но если уж так получилось, используйте вариант с расширенным индексом.
Источник: habr.com
