

В предыдущей статье я рассказал об основах DATA VAULT, описал основные элементы DATA VAULT и их назначение. На этом нельзя считать тему DATA VAULT исчерпанной, необходимо поговорить о следующих ступенях эволюции DATA VAULT.
И в этой статье я сконцентрируюсь на развитии DATA VAULT и переходу к BUSINESS DATA VAULT или просто BUSINESS VAULT.
Причины появления BUSINESS DATA VAULT
Следует отметить, DATA VAULT имея определенные сильные стороны не лишен недостатков. Одним из таких недостатков является сложность в написании аналитических запросов. Запросы имеют значительное количество JOIN’ов, код получается длинным и громоздким. Также данные попадающие в DATA VAULT не подвергаются никаким преобразованиям, поэтому с точки зрения бизнеса DATA VAULT в чистом виде не имеет безусловной ценности.
Именно для устранения этих недостатков методология DATA VAULT была расширена такими элементами как:
- PIT (point in time) таблицы;
- BRIDGE таблицы;
- PREDEFINED DERIVATIONS.
Давайте более детально разберем назначение этих элементов.
PIT таблицы
Как правило один бизнес объект (HUB) может иметь в своем составе данные с различной частотой обновления, например, если мы говорим о данных характеризующих человека, мы можем сказать, что информация о номере телефона, адресе или электронной почте имеет более высокую частоту обновления, чем скажем, ФИО, данные паспорта, семейное положение или пол.
Поэтому, при определении сателлитов, следует иметь ввиду частоту их обновления. Почему это важно?
Если в одной таблице хранить атрибуты с различной частотой обновления, придется добавлять строку в таблицу при каждом обновлении самого часто изменяемого атрибута. Как следствия – рост объема дискового пространства, увеличение времени исполнения запросов.
Теперь, когда мы разделили сателлиты по частоте обновления, и можем загружать в них данные независимо, следует обеспечить возможность получения актуальных данных. Лучше, без использования излишних JOIN’ов.
Поясню, например, требуется получить актуальную (по дате последнего обновления) информацию из сателлитов имеющих разную частоту обновления. Для этого потребуется не только сделать JOIN, но и создать несколько вложенных запросов (к каждому сателлиту содержащему информацию) с выбором максимальной даты обновления MAX(Дата обновления). С каждым новым JOIN’ом такой код разрастается, и очень быстро становится сложным для понимания.
PIT таблица призвана упростить такие запросы, PIT таблицы заполняются одновременно с записью новых данных в DATA VAULT. PIT таблица:
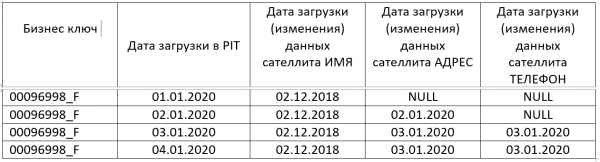
Таким образом у нас есть информация об актуальности данных по всем сателлитам на каждый момент времени. Используя JOIN’ы к PIT таблице, мы можем полностью исключить вложенные запросы, естественно с условие, что PIT заполняется каждый день и без пропусков. Даже, если пропуски в PIT имеют место, получить актуальные данные можно лишь используя один вложенный запрос к самому PIT’у. Один вложенный запрос отработает быстрее чем вложенные запросы к каждому сателлиту.
BRIDGE
Таблицы типа BRIDGE также используется для упрощения аналитических запросов. Однако отличием от PIT является средством упрощения и ускорения запросов между различными хабами, линками и их сателлитами.
Таблица содержит все необходимы ключи для всех сателлитов, которые часто используются в запросах. Кроме того, при необходимости хешированные бизнес ключи могут дополняться ключами в текстовом виде, если наименования ключей нужны для анализа.
Дело в том, что без использования BRIDGE, в процессе получения данных находящихся в сателлитах принадлежащим разным хабам, потребуется произвести JOIN не только самих сателлитов, но и линков связывающих хабы.
Наличие или отсутствие BRIDGE определяется конфигурацией хранилища, необходимостью оптимизации скорости исполнения запросов. Универсального пример BRIGE придумать сложно.
PREDEFINED DERIVATIONS
Еще одним типом объектов, который приближает нас к BUSINESS DATA VAULT являются таблицы содержащие предварительно рассчитанные показатели. Такие таблицы действительно важны для бизнеса, они содержат информацию, агрегированную по заданным правилам и позволяют получить к ней доступ относительно просто.
Архитектурно PREDEFINED DERIVATIONS представляют из себя, ничто иное, как еще один сателлит определенного хаба. Он, как и обычный сателлит содержит бизнес ключ и дату формирования записи в сателлите. На этом, однако, сходства заканчиваются. Дальнейший состав атрибутов такого «специализированного» сателлита определяется бизнес пользователями на основе наиболее востребованных, предварительно рассчитанных показателей.
Например, хаб содержащий информацию о сотруднике, может включать в себя сателлит с такими показателями, как:
- Минимальная зарплата;
- Максимальная зарплата;
- Средняя зарплата;
- Накопительный итог начисленной зарплаты и т.д.
Логично включать PREDEFINED DERIVATIONS в состав PIT таблицы этого же хаба, тогда можно без труда получить срезы данных по сотрудника на конкретно выбранную дату.
ВЫВОДЫ
Как показывает практика использование DATA VAULT бизнес пользователями несколько затруднительно по нескольким причинам:
- Код запросов сложный и громоздкий;
- Обилие JOIN’ов влияет на быстродействие запросов;
- Для написания аналитических запросов требуется выдающееся знание структуры хранилища.
Чтобы упростить доступ к данным, DATA VAULT расширяется дополнительными объектами:
- PIT (point in time) таблицы;
- BRIDGE таблицы;
- PREDEFINED DERIVATIONS.
В следующей я планирую рассказать, на мой взгляд, самое интересное, для тех, кто работает с BI. Я представлю способы создания таблиц – фактов и таблиц – измерений на базе DATA VAULT.
Материалы статьи основаны:
- На Кента Грациано, в которой помимо детального описания содержатся схемы модели;
- Книге: «Building a Scalable Data Warehouse with DATA VAULT 2.0»;
- Статья .
Источник: habr.com
