

В рамках данной статьи хотелось бы рассказать об особенностях работы All Flash массивов AccelStor с одной из популярнейших платформ виртуализации – VMware vSphere. В частности, акцентировать внимание на тех параметрах, которые помогут получить максимальный эффект от использования такого мощного инструмента, как All Flash.

All Flash массивы AccelStor NeoSapphire™ представляют собой или нодовые устройства на базе накопителей SSD с принципиально иным подходом в реализации концепции хранения данных и организации доступа к ней с использованием собственной технологии вместо весьма популярных алгоритмов RAID. Массивы предоставляют блочный доступ для хостов через интерфейсы Fibre Channel или iSCSI. Справедливости ради отметим, что модели с ISCSI интерфейсом также имеют файловый доступ в качестве приятного бонуса. Но в рамках данной статьи мы сфокусируемся на применении блочных протоколов как наиболее производительных для All Flash.
Весь процесс развертывания и последующей настройки совместной работы массива AccelStor и системы виртуализации VMware vSphere можно разделить на несколько этапов:
- Реализация топологии подключения и настройка SAN сети;
- Настройка All Flash массива;
- Настройка хостов ESXi;
- Настройка виртуальных машин.
В качестве оборудования для примеров использовались массивы AccelStor NeoSapphire™ с интерфейсом Fibre Channel и с интерфейсом iSCSI. В качестве базового ПО – VMware vSphere 6.7U1.
Перед развертыванием описываемых в статье систем крайне рекомендуется к ознакомлению документация от VMware касательно вопросов производительности ( ) и настроек iSCSI ()
Топология подключения и настройка SAN сети
Основными компонентами SAN сети являются адаптеры HBA в хостах ESXi, SAN коммутаторы и ноды массива. Типичная топология такой сети будет выглядеть так:
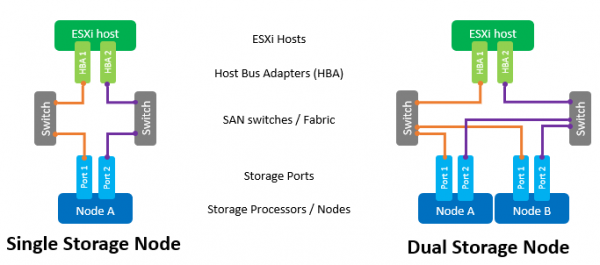
Под термином Switch здесь понимается как отдельный физический коммутатор или набор коммутаторов (Fabric), так и разделяемое между разными сервисами устройство (VSAN в случае Fibre Channel и VLAN в случае iSCSI). Использование двух независимых коммутаторов/Fabric позволит исключить возможную точку отказа.
Прямое подключение хостов к массиву хоть и поддерживается, но крайне не рекомендуется. Производительность All Flash массивов достаточно высока. И для максимальной скорости требуется задействовать все порты массива. Поэтому наличие хотя бы одного коммутатора между хостами и NeoSapphire™ обязательно.
Наличие двух портов у HBA хоста также является обязательным требованием для достижения максимальной производительности и обеспечения отказоустойчивости.
В случае использования интерфейса Fibre Channel требуется настройка зонирования для исключения возможных коллизий между инициаторами и таргетами. Зоны строятся по принципу «один порт инициатора – один или несколько портов массива».
Если же применяется подключение через iSCSI в случае использования разделяемого с другими сервисами коммутатора, то обязательно необходимо изолировать трафик iSCSI внутри отдельного VLAN. Также крайне рекомендуется включить поддержку Jumbo Frames (MTU = 9000) для увеличения размеров пакетов в сети и, тем самым, снижения количества служебной информации при передаче. Однако стоит помнить, что для корректной работы требуется изменить параметр MTU на всех компонентах сети по цепочке «инициатор-коммутатор-таргет».
Настройка All Flash массива
Массив поставляется заказчикам с уже сформированными группами . Поэтому никаких действий по объединению накопителей в единую структуру делать не нужно. Достаточно лишь создать тома требуемого размера и в необходимом количестве.
Для удобства присутствует функционал пакетного создания сразу нескольких томов заданного объема. По умолчанию создаются «тонкие» тома, поскольку это позволяет более рационально расходовать доступное пространство хранения (в том числе благодаря поддержке Space Reclamation). С точки зрения производительности разница между «тонкими» и «толстыми» томами не превышает 1%. Однако если требуется «выжать все соки» из массива, всегда можно сконвертировать любой «тонкий» том в «толстый». Но следует помнить, что такая операция необратима.
Далее остается «опубликовать» созданные тома и задать права доступа к ним со стороны хостов при помощи ACL (IP адреса для iSCSI и WWPN для FC) и физического разделения по портам массива. Для iSCSI моделей это делается через создание Target.
Для FC моделей публикация происходит через создание LUN для каждого порта массива.
Для ускорения процесса настройки хосты можно объединять в группы. Причем, если на хосте используется многопортовая FC HBA (что на практике чаще всего и происходит), то система автоматически определяет, что порты такой HBA относятся к единому хосту благодаря WWPN, отличающимся на единицу. Также для обоих интерфейсов поддерживается пакетное создание Target/LUN.
Важным замечанием в случае использования интерфейса iSCSI является создание для томов сразу нескольких таргетов для увеличения производительности, поскольку очередь на таргете нельзя изменить, и он фактически будет узким местом.
Настройка хостов ESXi
Со стороны ESXi хостов базовая настройка выполняется по вполне ожидаемому сценарию. Порядок действий для iSCSI соединения:
- Добавить Software iSCSI Adapter (не требуется, если он уже добавлен, либо в случае использования Hardware iSCSI Adapter);
- Создание vSwitch, через который будет проходить iSCSI трафик, и добавление в него физических uplink и VMkernal;
- Добавление в Dynamic Discovery адресов массива;
- Создание Datastore
Некоторые важные замечания:
- В общем случае, конечно, можно использовать и уже существующий vSwitch, но в случае отдельного vSwitch управление настройками хоста будет значительно проще.
- Необходимо разделять Management трафик и iSCSI по отдельным физическим линкам и/или VLAN во избежание проблем с производительностью.
- IP адреса VMkernal и соответствующих портов All Flash массива должны находиться в пределах одной подсети опять же из-за вопросов производительности.
- Для обеспечения отказоустойчивости по правилам VMware у vSwitch должно быть хотя бы два физических uplink
- Если используются Jumbo Frames необходимо изменить MTU и у vSwitch, и у VMkernal
- Не лишним будет напомнить, что согласно рекомендациям VMware для физических адаптеров, которые будут использоваться для работы с iSCSI трафиком, обязательно необходимо произвести настройку Teaming and Failover. В частности, каждый VMkernal должен работать только через один uplink, второй uplink необходимо перевести в режим unused. Для отказоустойчивости необходимо добавить два VMkernal, каждый из которых будет работать через свой uplink.
VMkernel Adapter (vmk#)
Physical Network Adapter (vmnic#)
vmk1 (Storage01)
Active Adapters
vmnic2
Unused Adapters
vmnic3
vmk2 (Storage02)
Active Adapters
vmnic3
Unused Adapters
vmnic2
Для соединения через Fibre Channel никаких предварительных действий не требуется. Можно сразу создавать Datastore.
После создания Datastore необходимо убедиться, что используется политика Round Robin для путей к Target/LUN как наиболее производительная.
По умолчанию настройками VMware предусматривает использование данной политики по схеме: 1000 запросов через первый путь, следующие 1000 запросов через второй путь и т.д. Такое взаимодействие хоста с двухконтроллерным массивом будет несбалансированным. Поэтому рекомендуем установить параметр Round Robin policy = 1 через Esxcli/ PowerCLI.
Параметры
Для Esxcli:
- Вывести доступные LUN
esxcli storage nmp device list
- Cкопировать Device Name
- Изменить Round Robin Policy
esxcli storage nmp psp roundrobin deviceconfig set —type=iops —iops=1 —device=«Device_ID»
Большинство современных приложений спроектировано для обмена пакетами данных большого размера с целью максимальной утилизации полосы пропускания и снижения нагрузки на центральный процессор. Поэтому ESXi по умолчанию передает запросы ввода/вывода на устройство хранения порциями до 32767KB. Однако для ряда сценариев обмен меньшими порциями будет производительнее. Применительно к массивам AccelStor это следующие сценарии:
- Виртуальная машина использует UEFI вместо Legacy BIOS
- Используется vSphere Replication
Для таких сценариев рекомендуется изменить значение параметра Disk.DiskMaxIOSize на 4096.
Для iSCSI соединений рекомендуется изменить параметр Login Timeout на 30 (по умолчанию 5) для повышения стабильности соединения и выключить задержку подтверждений пересылаемых пакетов DelayedAck. Обе опции находятся в vSphere Client: Host → Configure → Storage → Storage Adapters → Advanced Options для iSCSI адаптера
Достаточно тонким моментом является количество используемых томов для datastore. Понятно, что для простоты управления возникает желание создать один большой том на весь объем массива. Однако наличие нескольких томов и, соответственно, datastore благотворно сказывается на общей производительности (подробнее об очередях чуть ниже по тексту). Поэтому мы рекомендуем создание как минимум двух томов.
Еще сравнительно недавно VMware советовала ограничивать количество виртуальных машин на одном datastore опять же с целью получить максимально возможную производительность. Однако сейчас, особенно с распространением VDI, эта проблема уже не стоит так остро. Но это не отменяет давнего правила — распределять виртуальные машины, требующие интенсивного IO, по разным datastore. Для определения оптимального количества виртуалок на один том нет ничего лучше, чем провести в рамках своей инфраструктуры.
Настройка виртуальных машин
При настройке виртуальных машин особых требований нет, точнее они вполне заурядные:
- Использование максимально возможную версию VM (compatibility)
- Аккуратнее задавать размер ОЗУ при плотном размещении виртуальных машин, например, в VDI (т.к. по умолчанию при старте создается файл подкачки соизмеримого с ОЗУ размера, что расходует полезную емкость и оказывает эффект на итоговую производительность)
- Использовать наиболее производительные по части IO версии адаптеров: сетевой типа VMXNET 3 и SCSI типа PVSCSI
- Использовать тип диска Thick Provision Eager Zeroed для максимальной производительности и Thin Provisioning для максимально эффективного использования пространства хранения
- По возможности ограничивать работу некритичных к вводу/выводу машин с помощью Virtual Disk Limit
- Обязательно устанавливать VMware Tools
Замечания об очередях
Очередь (или Outstanding I/Os) – это число запросов ввода/вывода (SCSI команд), которые ждут обработки в каждый момент времени у конкретного устройства/приложения. В случае переполнения очереди выдается ошибки QFULL, что в итоге выражается в увеличение параметра latency. При использовании дисковых (шпиндельных) систем хранения теоретически чем выше очередь, тем выше их производительность. Однако злоупотреблять не стоит, поскольку легко нарваться на QFULL. В случае All Flash систем, с одной стороны, все несколько проще: ведь массив имеет задержки на порядки ниже и потому чаще всего не требуется отдельно регулировать размер очередей. Но с другой стороны, в некоторых сценариях использования (сильный перекос в требованиях к IO для конкретных виртуальных машин, тесты на максимальную производительность и т.п.) требуется если не изменять параметры очередей, то хотя бы понимать, каких показателей можно достичь, и, главное, какими путями.
На самом All Flash массиве AccelStor нет никаких лимитов по отношению к томам или портам ввода/вывода. При необходимости даже единственный том может получить все ресурсы массива. Единственное ограничение на очереди имеется у iSCSI таргетов. Именно по этой причине выше указывалась необходимость в создании нескольких (в идеале до 8 шт.) таргетов на каждый том для преодоления этого лимита. Также повторим, что массивы AccelStor являются весьма производительными решениями. Поэтому следует задействовать все интерфейсные порты системы для достижения максимальной скорости.
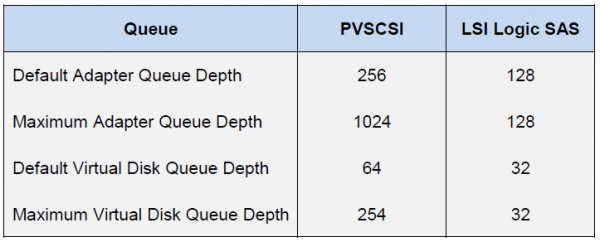
Со стороны ESXi хоста ситуация совершенно иная. Сам хост применяет практику равноправного доступа к ресурсам для всех участников. Поэтому существуют отдельные очереди IO к гостевой ОС и HBA. Очереди к гостевой ОС комбинируются из очередей к виртуальному SCSI адаптеру и виртуальному диску:
Очередь к HBA зависит от конкретного типа/вендора:
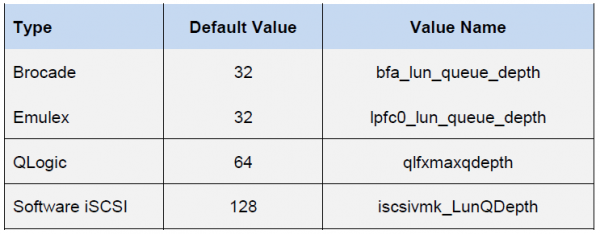
Итоговая производительность виртуальной машины будет определяться наименьшим значением показателя очереди (Queue Depth limit) среди компонентов хоста.
Благодаря этим значениям можно оценить показатели производительности, которые мы можем получить в той или иной конфигурации. Например, мы хотим узнать теоретическую производительность виртуальной машины (без привязки к блоку) с latency 0.5ms. Тогда ее IOPS = (1,000/latency) * Outstanding I/Os (Queue Depth limit)
Примеры
Пример 1
- FC Emulex HBA Adapter
- Одна VM на datastore
- VMware Paravirtual SCSI Adapter
Здесь Queue Depth limit определяется Emulex HBA. Поэтому IOPS = (1000/0.5)*32 = 64K
Пример 2
- VMware iSCSI Software Adapter
- Одна VM на datastore
- VMware Paravirtual SCSI Adapter
Здесь Queue Depth limit определяется уже Paravirtual SCSI Adapter. Поэтому IOPS = (1000/0.5)*64 = 128K
Топовые модели All Flash массивов AccelStor (например, ) способны обеспечивать производительность 700K IOPS на запись при блоке 4K. При таком размере блока совершенно очевидно, что единственная виртуальная машина не способна загрузить подобный массив. Для этого понадобится 11 (для примера 1) или 6 (для примера 2) виртуалок.
В итоге при правильной настройке всех описанных компонент виртуального датацентра можно получить весьма впечатляющие результаты в плане производительности.
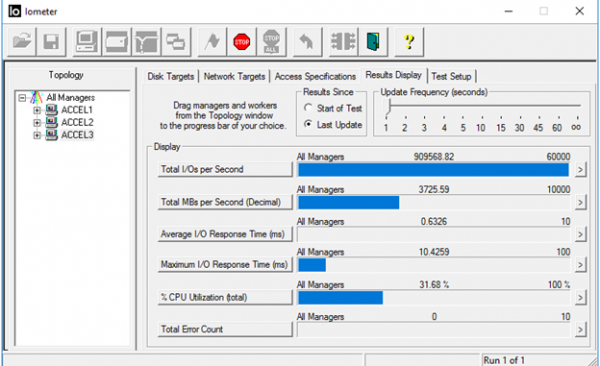
4K Random, 70% Read/30% Write
На самом деле реальный мир намного сложнее, чтобы описать его простой формулой. На одном хосте всегда расположено множество виртуальных машин с различными конфигурациями и требованиями к IO. Да и обработкой ввода/вывода занимается процессор хоста, мощность которого не бесконечна. Так, для раскрытия полного потенциала той же в реальности понадобится от трех хостов. Плюс приложения, работающие внутри виртуальных машин, вносят свои коррективы. Поэтому для точного сайзинга мы предлагаем All Flash массивов внутри инфраструктуры заказчика на реальных текущих задачах.
Источник: habr.com
