

Согласно , data engineer на данный момент является профессией, спрос на которую растет быстрее всех прочих. Data engineer играет в организации критически важную роль – создает и поддерживает в рабочем состоянии пайплайны и базы данных, которые используются для обработки, трансформации и хранения данных. Какие навыки нужны представителям этой профессии в первую очередь? Отличается ли список от того, что требуется от data scientists? Обо всем этом вы узнаете из моей статьи.
Я проанализировал вакансии на позицию data engineer в том виде, в котором они пребывают в январе 2020 года, чтобы понять, какие умения в области технологий пользуются наибольшей популярностью. Затем я сравнил полученные результаты со статистикой по вакансиям на позиции data scientist – при этом вскрылись некоторые занятные различия.
Обойдемся без долгих предисловий – вот топ-десять технологий, которые упоминаются в текстах вакансий чаще всего:
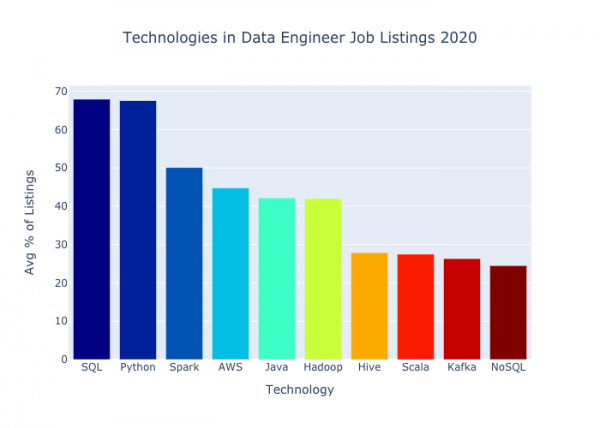
Упоминания технологий в вакансиях на позицию data engineer в 2020 году
Давайте разбираться.
Обязанности data engineer
На сегодняшний день работа, которую выполняют data engineers, имеет огромное значение для организаций – именно эти люди отвечают за хранение информации и приводят ее в такой вид, чтобы с другие сотрудники могли с ней работать. Data engineers выстраивают пайплайны, чтобы наладить получение данных, потоком или пакетами, из множества источников. Далее пайплайны производят операции по извлечению, трансформации и загрузке (иными словами, ETL-процессы), делая данные более пригодными для дальнейшего использования. После этого данные предаются аналитикам и data scientists для более глубокой обработки. Наконец, данные заканчивают свое путешествие на информационных панелях, в отчетах и моделях для машинного обучения.
Я искал информацию, которая позволила бы сделать вывод о том, какие технологии наиболее востребованы в работе data engineer на текущий момент.
Методы
Я собирал информацию с трех сайтов для поиска работы — , и и смотрел, какие ключевые слова попадаются в связке с «data engineer» в текстах вакансий, рассчитанных на жителей США. Для этой задачи я применял две библиотеки Python — и . В число ключевых слов я включал как те, которые входили в предыдущий список для анализа вакансий на позицию data scientist, так и те, которые вручную отобрал, читая предложения о работе для data engineers. LinkedIn в число источников не вошел, так как меня там забанили после прошлой попытки собрать данные.
Для каждого ключевого слова я подсчитал процент попаданий от общего числа текстов на каждом из сайтов в отдельности, а потом вычислил среднее значение по трем источникам.
Результаты
Ниже представлены тридцать технических терминов из сферы data engineering с самыми высокими показателями по всем трем сайтам вакансий.
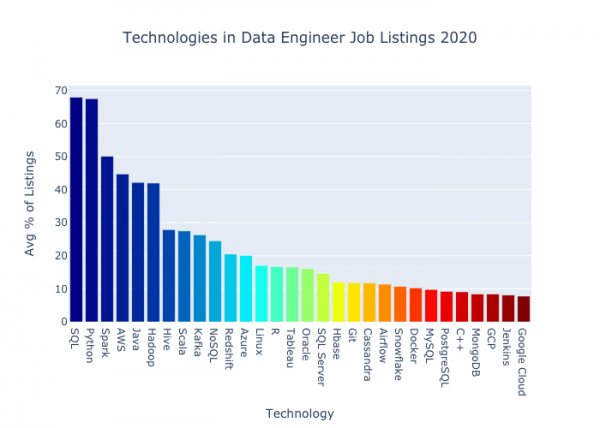
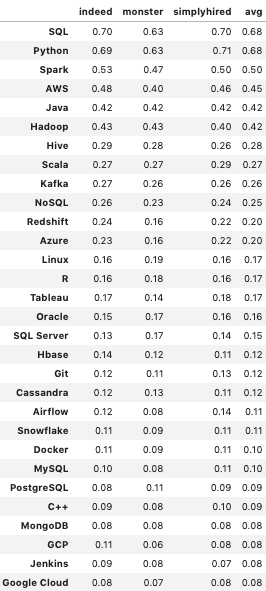
А вот те же самые цифры, но оформленные в виде таблицы:
Пойдем по порядку.
Обзор результатов
И SQL, и Python фигурируют в более чем двух третях рассмотренных вакансий. Именно эти две технологии имеет смысл изучать в первую очередь. – очень популярный язык программирования, применяющийся для работы с данными, создания вебсайтов и написания сценариев. расшифровывается как Structured Query Language (язык структурированных запросов); он предполагает стандарт, реализуемый группой языков, и применяется для извлечения данных из реляционных баз. Он появился уже давно и зарекомендовал себя высокой устойчивостью.
О Spark говорится примерно в половине вакансий. – это «объединенный аналитический движок для обработки больших данных со встроенными модулями для потоковой передачи, SQL, машинного обучения и обработки графов». Он пользуется особой популярностью у тех, кто работает с базами данных больших размеров.
AWS попадает примерно в 45% текстов вакансий. Это облачная вычислительная платформа производства Amazon; ей принадлежит наибольшая доля рынка среди всех облачных платформ.
Следом идут Java и Hadoop – чуть больше 40% на брата. – широко распространенный, проверенный в боях язык, который в удостоился десятого места среди языков, вызывающих у программистов ужас. В противоположность ему, Python оказался вторым из языков, пользующихся наибольшей любовью. Языком Java заправляет Oracle, и все, что о нем вообще нужно знать, можно понять вот из этого скриншота официальной страницы от января 2020 года.

Будто на машине времени прокатился
использует программную модель MapReduce с кластерами серверов для больших данных. Сейчас от этой модели начинают все чаще отказываться.
Дальше мы видим Hive, Scala, Kafka и NoSQL – каждая из этих технологий упоминается в четверти представленных вакансий. Apache Hive – это программа-хранилище данных, которая «упрощает чтение, написание и управление крупными наборами данных, располагающимися в распределенных хранилищах, при помощи SQL». – язык программирования, активно использующийся при работе с большими данными. В частности, на Scala создавался Spark. В уже упоминавшемся рейтинге наводящих страх языков Scala занимает одиннадцатую строчку. – распределенная платформа для обработки потоковых сообщений. Очень популярна как средство потоковой передачи данных.
противопоставляют себя SQL. Они отличаются тем, что не реляционны, не структурированы и обладают горизонтальной масштабируемостью. NoSQL завоевал некоторую популярность, однако лихорадочное увлечение этим подходом, вплоть до пророчеств, что он сменит SQL в качестве доминантной парадигмы хранения, похоже, уже позади.
Сравнение с терминами в вакансиях data scientist
Вот тридцать технологических терминов, наиболее распространенных у работодателей в сфере data science. Этот список я получил тем же путем, который описывал выше для data engineering.
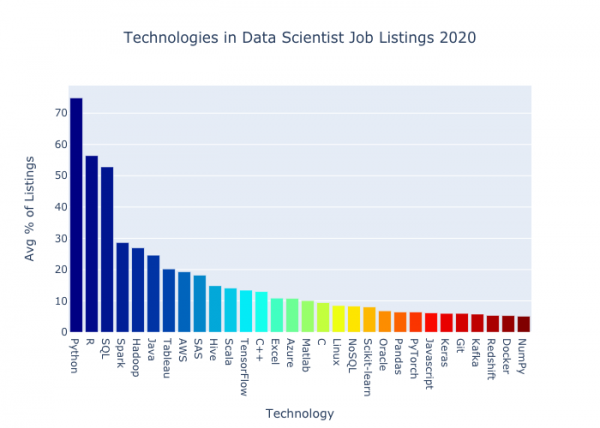
Упоминания технологий в вакансиях на позицию data scientist в 2020 году
Если говорить об общем числе, по сравнению с рассмотренным раннее набором, вакансий оказалось больше на 28% (12 013 против 9396). Давайте посмотрим, какие технологии встречаются в вакансиях для data scientists реже, чем для data engineers.
Более популярные в data engineering
На графике ниже показаны ключевые слова со средним различием в значениях больше 10% или же меньше -10%.
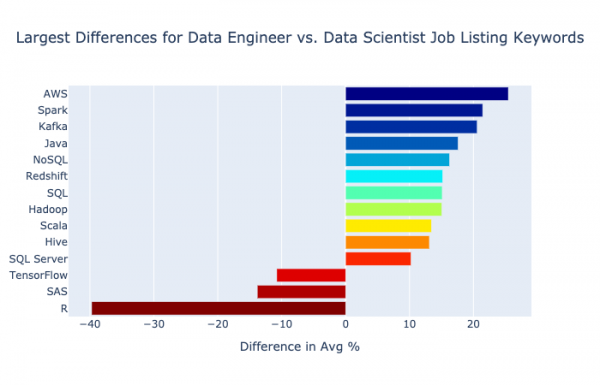
Наибольшие различия в частотности ключевых слов у data engineer и data scientist
Самый существенный прирост обнаруживает AWS: в data engineering он появляется на 25% регулярнее, чем в data science (приблизительно 45% и 20% от общего числа вакансий соответственно). Разница ощутимая!
Вот те же данные в немного ином представлении – на графике результаты для одного и того же ключевого слова в вакансиях на позицию data engineer и data scientist расположены бок о бок.
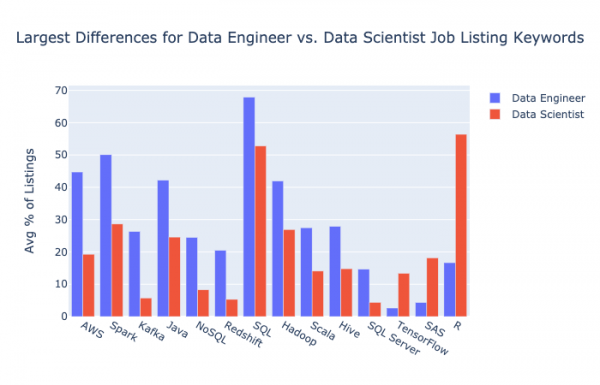
Наибольшие различия в частотности ключевых слов у data engineer и data scientist
Следующий по величине скачок я отметил у Spark – data engineer часто приходится работать с большими данными. тоже подрос на 20%, то есть почти в четыре раза по сравнению с результатом по вакансиям data scientist. Передача данных – одна из ключевых обязанностей data engineer. Наконец, число упоминаний оказалось на 15% больше в сфере data engineering у Java, NoSQL, Redshift, SQL и Hadoop.
Менее популярные в data engineering
Теперь давайте посмотрим, какие технологии менее популярны в вакансиях для data engineer.
Самый резкий спад по сравнению со сферой data science случился у : там он фигурировал примерно в 56% вакансий, здесь – только в 17%. Впечатляет. R – язык программирования, который пользуется успехом у ученых и статистиков, а также обладатель восьмого места в рейтинге вызывающих ужас языков.
также встречается в вакансиях на позицию data engineer ощутимо реже – разница составляет 14%. SAS является патентованным языком, рассчитанным на работу со статистикой и данными. Интересный момент: судя по результатам , в последнее время он сильно утратил позиции – сильнее, чем любая другая технология.
Востребованные и в data engineering, и в data science
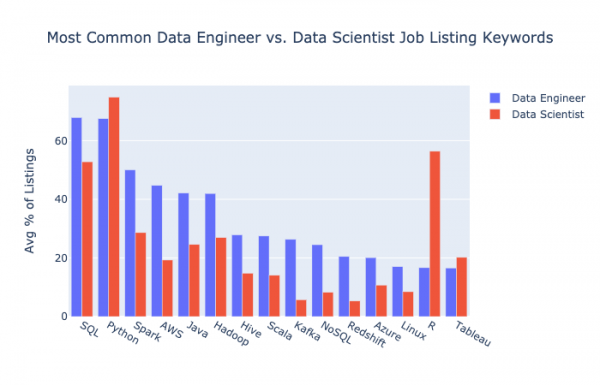
Нужно заметить, что восемь из десяти первых позиций в обоих наборах совпадают. SQL, Python, Spark, AWS, Java, Hadoop, Hive и Scala вошли в десятку как для отрасли data engineering, так и для data science. На графике ниже вы можете увидеть пятнадцать самых популярных технологий у работодателей data engineers, а рядом – их показатель по вакансиям для data scienctists.
Рекомендации
Если вы хотите заниматься data engineering, я бы посоветовал освоить следующие технологии – перечисляю их в порядке приблизительной приоритетности.
Изучите SQL. Я склоняю вас именно к PostgreSQL, потому что у него открытый код, большая популярность в сообществе и он находится в фазе роста. Как пользоваться языком, можно узнать из книги My Memorable SQL – ее пилотная версия доступна .
Освойте Python, пусть не на самом хардкорном уровне. Книга My Memorable Python рассчитана как раз на новичков. Ее можно купить на , электронную копию или физическую, на ваш выбор, или же скачать в формате pdf или epub .
Как только познакомитесь с Python, переходите к pandas – библиотеке Python, которая применяется при очистке и обработке данных. Если вы нацелены на работу в компании, где требуется умение писать на Python (а таких большинство), можете быть уверены, что знание pandas будет предполагаться по умолчанию. Я сейчас заканчиваю вводное руководство для работы с pandas – можете , чтобы не пропустить момент выхода.
Освойте AWS. Если хотите стать data engineer, без облачной платформы в загашнике вам не обойтись, а AWS – самая популярная из них. Мне очень помогли курсы , когда я изучал , думаю, что и по AWS у них найдутся хорошие материалы.
Если вы уже осилили весь этот список и хотите еще вырасти в глазах работодателей как data engineer, предлагаю добавить Apache Spark для работы с большими данными. Хоть мое исследование по вакансиям data science и показало спад интереса, у data engineer-ов он все-таки мелькает почти в каждой второй вакансии.
Напоследок
Надеюсь, этот обзор самых востребованных технологий для data engineer показался вам полезным. Если вам интересно, как обстоят дела в вакансиях у аналитиков, прочитайте . Успешного инженерства!
Источник: habr.com
