

Структурирование неструктурированных данных с помощью GROK
Если вы используете стек Elastic (ELK) и заинтересованы в сопоставлении пользовательских журналов Logstash с Elasticsearch, то этот пост для вас.

Стек ELK – это аббревиатура для трех проектов с открытым исходным кодом: Elasticsearch, Logstash и Kibana. Вместе они образуют платформу управления журналами.
- Elasticsearch – это поисковая и аналитическая система.
- Logstash – это серверный конвейер обработки данных, который принимает данные из нескольких источников одновременно, преобразует их и затем отправляет в “тайник”, например Elasticsearch.
- Kibana позволяет пользователям визуализировать данные с помощью диаграмм и графиков в Elasticsearch.
Beats появился позже и является легким грузоотправителем данных. Введение Beats преобразовало Elk Stack в Elastic Stack, но это не главное.
Эта статья посвящена Grok, которая является функцией в Logstash, которая может преобразовать ваши журналы, прежде чем они будут отправлены в тайник. Для наших целей я буду говорить только об обработке данных из Logstash в Elasticsearch.

Grok-это фильтр внутри Logstash, который используется для разбора неструктурированных данных на что-то структурированное и подлежащее запросу. Он находится поверх регулярного выражения (regex) и использует текстовые шаблоны для сопоставления строк в файлах журналов.
Как мы увидим в следующих разделах, использование Grok имеет большое значение, когда речь заходит об эффективном управлении журналами.
Без Grok ваши данные журнала Неструктурированы
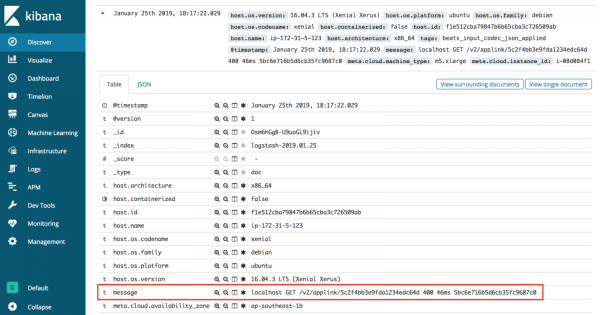
Без Grok, когда журналы отправляются из Logstash в Elasticsearch и визуализируются в Kibana, они появляются только в значении сообщения.
Запрос значимой информации в этой ситуации затруднен, поскольку все данные журнала хранятся в одном ключе. Было бы лучше, если бы сообщения журнала были организованы лучше.
Неструктурированные данные из логов
localhost GET /v2/applink/5c2f4bb3e9fda1234edc64d 400 46ms 5bc6e716b5d6cb35fc9687c0Если вы внимательно посмотрите на необработанные данные, то увидите, что они на самом деле состоят из разных частей, каждая из которых разделена пробелом.
Для более опытных разработчиков вы, вероятно, можете догадаться, что означает каждая из частей и что это сообщение журнала от вызова API. Представление каждого пункта изложено ниже.
Структурированный вид наших данных
- localhost == environment
- GET == method
- /v2/applink/5c2f4bb3e9fda1234edc64d == url
- 400 == response_status
- 46ms == response_time
- 5bc6e716b5d6cb35fc9687c0 == user_id
Как мы видим в структурированных данных, существует порядок для неструктурированных журналов. Следующий шаг – это программная обработка необработанных данных. Вот где Грок сияет.
Шаблоны Grok
Встроенные шаблоны Grok
Logstash поставляется с более чем 100 встроенными шаблонами для структурирования неструктурированных данных. Вы определенно должны воспользоваться этим преимуществом, когда это возможно для общих системных журналов, таких как apache, linux, haproxy, aws и так далее.
Однако что происходит, когда у вас есть пользовательские журналы, как в приведенном выше примере? Вы должны построить свой собственный шаблон Grok.
Кастомные шаблоны Grok
Нужно пробовать, чтобы построить свой собственный шаблон Grok. Я использовал и .
Обратите внимание, что синтаксис шаблонов Grok выглядит следующим образом: %{SYNTAX:SEMANTIC}
Первое, что я попытался сделать, это перейти на вкладку Discover в отладчике Grok. Я подумал, что было бы здорово, если бы этот инструмент мог автоматически генерировать шаблон Grok, но это было не слишком полезно, так как он нашел только два совпадения.
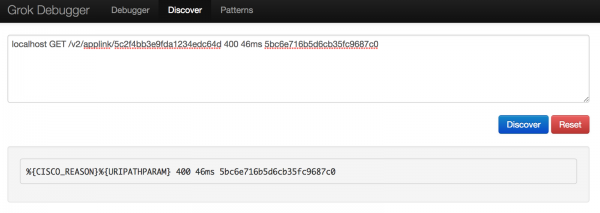
Используя это открытие, я начал создавать свой собственный шаблон на отладчике Grok, используя синтаксис, найденный на странице Github Elastic.
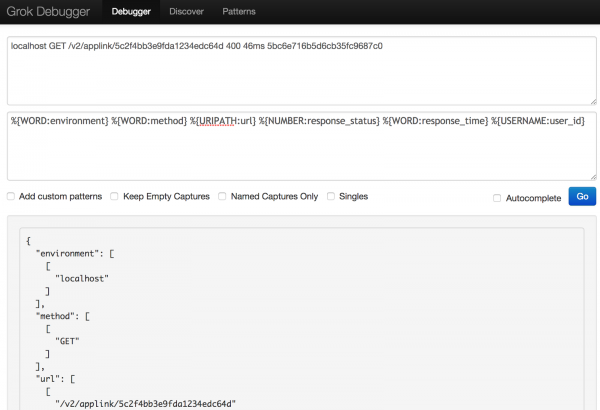
Поиграв с разными синтаксисами, я наконец-то смог структурировать данные журнала так, как мне хотелось.
Ссылка на отладчик Grok
Исходный текст:
localhost GET /v2/applink/5c2f4bb3e9fda1234edc64d 400 46ms 5bc6e716b5d6cb35fc9687c0Pattern:
%{WORD:environment} %{WORD:method} %{URIPATH:url} %{NUMBER:response_status} %{WORD:response_time} %{USERNAME:user_id}То что получилось в итоге
{
"environment": [
[
"localhost"
]
],
"method": [
[
"GET"
]
],
"url": [
[
"/v2/applink/5c2f4bb3e9fda1234edc64d"
]
],
"response_status": [
[
"400"
]
],
"BASE10NUM": [
[
"400"
]
],
"response_time": [
[
"46ms"
]
],
"user_id": [
[
"5bc6e716b5d6cb35fc9687c0"
]
]
}Имея в руках шаблон Grok и сопоставленные данные, последний шаг — добавить его в Logstash.
Обновление файла конфигурации Logstash.conf
На сервере, на котором вы установили стек ELK, перейдите к конфигурации Logstash:
sudo vi /etc/logstash/conf.d/logstash.confВставьте изменения.
input {
file {
path => "/your_logs/*.log"
}
}
filter{
grok {
match => { "message" => "%{WORD:environment} %{WORD:method} %{URIPATH:url} %{NUMBER:response_status} %{WORD:response_time} %{USERNAME:user_id}"}
}
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}После сохранения изменений перезапустите Logstash и проверьте его состояние, чтобы убедиться, что он все еще работает.
sudo service logstash restart
sudo service logstash statusНаконец, чтобы убедиться, что изменения вступили в силу, обязательно обновите индекс Elasticsearch для Logstash в Kibana!
С Grok ваши данные из логов структурированы!
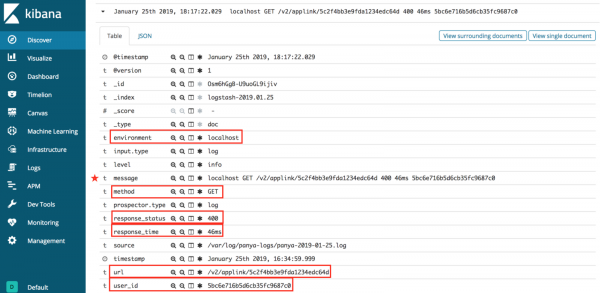
Как мы видим, на изображении выше, Grok способен автоматически сопоставлять данные журнала с Elasticsearch. Это облегчает управление журналами и быстрый запрос информации. Вместо того чтобы рыться в файлах журналов для отладки, вы можете просто отфильтровать то, что вы ищете, например среду или url-адрес.
Попробуйте дать Grok expressions шанс! Если у вас есть другой способ сделать это или у вас есть какие-либо проблемы с примерами выше, просто напишите комментарий ниже, чтобы сообщить мне об этом.
Спасибо за чтение — и, пожалуйста, следуйте за мной здесь, на Medium, для получения более интересных статей по программной инженерии!
Ресурсы
P.S
Телеграм-канал по
Источник: habr.com
