

У нас было 2 анализатора кода, 4 инструмента для динамического тестирования, свои поделки и 250 скриптов. Не то, чтобы это всё было нужно в текущем процессе, но раз начал внедрять DevSecOps, то надо иди до конца.

. Авторы персонажей: Джастин Ройланд и Дэн Хармон.
Что такое SecDevOps? А DevSecOps? В чем отличия? Application Security — о чём это? Почему классический подход больше не работает? На все эти вопросы знает ответ Юрий Шабалин из Swordfish Security. Юрий подробно на всё ответит и разберет проблемы перехода от классической модели Application Security к процессу DevSecOps: как правильно подойти к встраиванию процесса безопасной разработки в процесс DevOps и ничего не сломать при этом, как пройти основные этапы тестирования на безопасность, какие инструменты можно применять, чем они отличаются и как их правильно настроить, чтобы избежать подводных камней.

О спикере: Юрий Шабалин — Chief Security Architect в компании Swordfish Security. Отвечает за внедрение SSDL, за общую интеграцию инструментов анализа приложений в единую экосистему разработки и тестирования. 7 лет опыта в информационной безопасности. Работал в Альфа-Банк, Сбербанк и в Positive Technologies, которая разрабатывает софт и предоставляет сервисы. Спикер международных конференций ZerONights, PHDays, RISSPA, OWASP.
Application Security: о чём это?
Application Security — это раздел безопасности, который отвечает за безопасность приложений. Это не относится к инфраструктуре или к сетевой безопасности, а именно к тому, что мы пишем и над чем работают разработчики — это недостатки и уязвимости самого приложения.
Направление — Security development lifecycle — разработала компания Microsoft. На схеме — каноническая модель SDLC, основная задача которой — участие безопасности на каждом этапе разработки, от требований, до релиза и выхода в продакшн. В Microsoft поняли, что в проме слишком много багов, их становится больше и с этим надо что-то делать, и предложили этот подход, который стал каноническим.
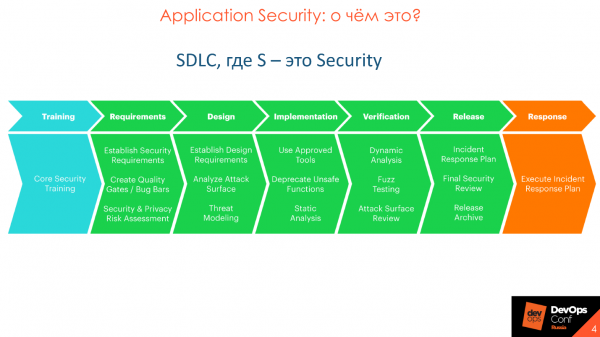
Application Security и SSDL направлены не на обнаружение уязвимостей, как принято считать, а на предотвращение их появления. Со временем канонический подход от Microsoft был улучшен, развит, в нем появилось более глубокое детальное погружение.

Канонический SDLC сильно детализирован в различных методологиях — OpenSAMM, BSIMM, OWASP. Методологии отличаются, но, в целом, похожи.
Building Security In Maturity Model
Мне больше всего по душе BSIMM — . Основа методологии — разделение процесса Application Security на 4 домена: Governance, Intelligence, SSDL Touchpoints и Deployment. В каждом домене 12 практик, которые представлены в виде 112 активностей.

У каждой из 112 активностей есть 3 уровня зрелости: начальный, средний и продвинутый. Все 12 практик можно изучать по разделам, отбирать важные для вас вещи, разбираться, как их внедрять и постепенно добавлять элементы, например, статический и динамический анализ кода или code review. Расписываете план и по нему спокойно работаете в рамках внедрения выбранных активностей.
Почему DevSecOps
DevOps — это общий большой процесс, в котором нужно заботиться о безопасности.
Изначально предполагал проверки на безопасность. На практике, численность команд безопасности была намного меньше, чем сейчас, и они выступали не как участники процесса, а как контрольный и надзорный орган, который предъявляет к нему требования и проверяет качество продукта в конце релиза. Это классический подход, в котором команды безопасности находились за стеной от разработки и не принимали участия в процессе.
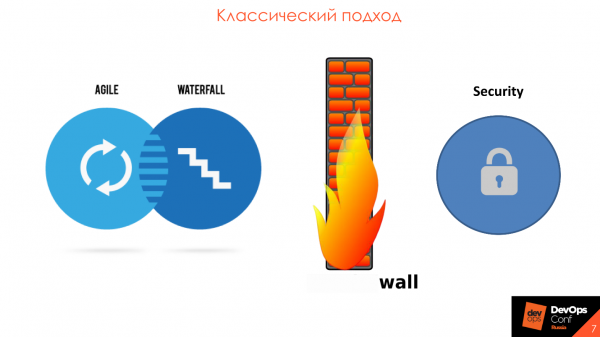
Основная проблема как раз в том, что ИБ стоят отдельно от разработки. Обычно это некий контур ИБ и в нём 2-3 больших и дорогих инструмента. Раз в полгода прилетает исходный код или приложение, которое нужно проверить, а раз в год производятся . Это все приводит к тому, что сроки выхода в пром откладываются, а на разработчика вываливается огромное количество уязвимостей из автоматизированных средств. Всё это невозможно разобрать и починить, потому что еще за предыдущие полгода не разобрали результаты, а тут новая партия.
В процессе работы нашей компании мы видим, что безопасность во всех сферах и индустриях понимает, что пора подтягиваться и крутиться с разработкой в одном колесе — в . Парадигма DevSecOps замечательно ложится на методологию гибкой разработки, на внедрение, поддержку и участие в каждом релизе и итерации.
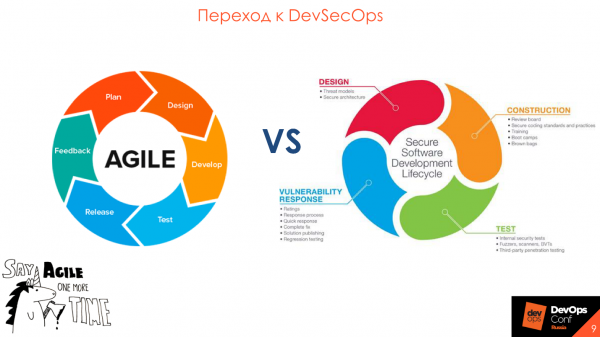
Переход к DevSecOps
Самое важное слово в Security Development Lifecycle — это «процесс». Вы должны это понять, прежде чем думать о покупке инструментов.
Просто включить инструменты в процесс DevOps недостаточно — важно взаимодействие и понимание между участниками процесса.
Важнее люди, а не инструменты
Часто планирование процесса безопасной разработки начинается с выбора и покупки инструмента, а заканчивается — попытками интегрировать инструмент в текущий процесс, которые так и остаются попытками. Это приводит к печальным последствиям, потому что у всех инструментов свои особенности и ограничения.
Распространенный случай, когда отдел безопасности выбрал хороший, дорогой инструмент, с широкими возможностями, и пришел к разработчикам — встраивать в процесс. Но не выходит — процесс построен так, что ограничения уже купленного инструмента не ложатся в текущую парадигму.
Сначала опишите, какой результат вы хотите и как будет выглядеть процесс. Это поможет понять роли инструмента и безопасности в процессе.
Начните с того, что уже используется
Перед покупкой дорогих инструментов посмотрите на то, что у вас уже есть. В каждой компании есть требования по безопасности, которые предъявляются разработке, есть проверки, пентесты — почему бы не преобразить всё это в понятный и удобный для всех вид?
Обычно требования — это бумажный талмуд, который лежит на полочке. Был случай, когда мы приходим в компанию, чтобы посмотреть процессы и просим показать требования по безопасности к софту. Специалист, который этим занимался, долго искал:
— Сейчас, где-то в заметках был путь, где лежит этот документ.
В итоге мы получили документ спустя неделю.
Для требований, проверок и прочего, создайте страницу, например, на Confluence — это удобно всем.
Проще переформатировать то, что уже есть и использовать для старта.
Используйте Security Champions
Обычно, в средней компании на 100-200 разработчиков трудится один безопасник, который выполняет несколько функций, и физически не успевает все проверять. Даже если он старается изо всех сил — в одиночку не проверит весь код, который генерирует разработка. Для таких случаев разработан концепт — .
Security Champions — это человек внутри команды разработки, который заинтересован в безопасности вашего продукта.

Security Champion — точка входа в команду разработки и евангелист безопасности в одном лице.
Обычно, когда в команду разработки приходит безопасник и указывает на ошибку в коде, то получает удивленный ответ:
— А вы кто? Я вас вижу в первый раз. У меня все хорошо — мне старший товарищ на code review поставил «apply», мы идем дальше!
Это типичная ситуация, потому что к старшим или просто коллегам по команде, с которыми разработчик постоянно взаимодействует по работе и в code review, доверия намного больше. Если вместо безопасника на ошибку и последствия укажет Security Champion, то его слово будет иметь больше веса.
Также разработчики лучше знают свой код, чем любой безопасник. Для человека, у которого минимум 5 проектов в инструменте статического анализа, обычно сложно помнить все нюансы. Security Champions знают свой продукт: что с чем взаимодействует и на что смотреть в первую очередь — они эффективнее.
Так что задумайтесь над тем, чтобы внедрить Security Champions и расширить влияние команды безопасности. Для самого чемпиона это также полезно: профессиональное развитие в новой области, расширение технического кругозора, прокачка технических, управленческих и лидерских навыков, повышение рыночной стоимости. Это некоторый элемент социальной инженерии, ваши «глаза» в команде разработки.
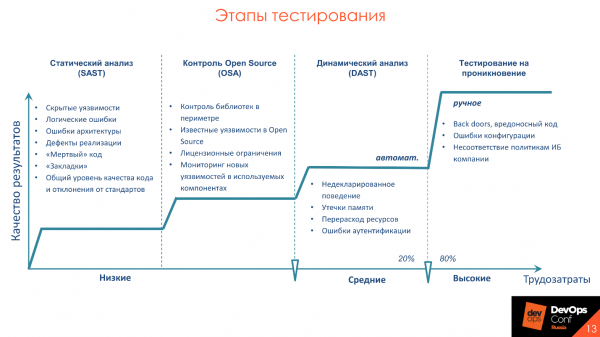
Этапы тестирования
гласит, что 20% усилий дают 80% результата. Эти 20% — это практики анализа приложений, которые можно и нужно автоматизировать. Примеры таких активностей — это статический анализ — SAST, динамический анализ — DAST, и контроль Open Source. Расскажу подробнее про активности, а также про инструменты, с какими особенностями мы обычно сталкиваемся при их внедрении в процесс, и как это делать правильно.
Основные проблемы инструментов
Выделю актуальные для всех инструментов проблемы, которые требуют внимания. Разберу их подробнее, чтобы не повторяться дальше.
Долгое время анализа. Если от коммита до выхода на прод уходит 30 минут на все тесты и сборку, то проверки на информационную безопасность займут сутки. Так тормозить процесс никто не будет. Учитывайте эту особенность и делайте выводы.
Высокий уровень False Negative или False Positive. Все продукты разные, все используют разные фреймворки и свой стиль написания кода. На разных кодовых базах и технологиях инструменты могут показывать разный уровень False Negative и False Positive. Поэтому смотрите, что именно в вашей компании и для ваших приложений будет показывать хороший и достоверный результат.
Нет интеграций с существующими инструментами. Смотрите на инструменты с точки зрения интеграций, с тем, что вы уже используете. Например, если у вас Jenkins или TeamCity — проверьте интеграцию инструментов именно с этим ПО, а не с GitLab CI, который вы не используете.
Отсутствие или чрезмерная сложность кастомизации. Если у инструмента нет API, то зачем он нужен? Всё, что можно сделать в интерфейсе должно быть доступно через API. В идеале, у инструмента должна быть возможность кастомизации проверок.
Нет Roadmap развития продукта. Разработка не стоит на месте, мы всегда используем новые фреймворки и функции, переписываем старый код на новые языки. Мы хотим быть уверенными, что инструмент, который мы купим, будет поддерживать новые фреймворки и технологии. Поэтому важно знать, что у продукта есть реальный и правильный развития.
Особенности процесса
Кроме особенностей инструментов учитывайте и особенности процесса разработки. Например, мешать разработке — это типичная ошибка. Давайте посмотрим какие ещё особенности следует учитывать и на что обратить внимание команде безопасности.
Чтобы не срывать сроки разработки и релиза, создайте разные правила и разные show stoppers — критерии остановки процесса сборки при наличии уязвимостей — для разных сред. К примеру, мы понимаем, что текущая ветка идет на девелоперский стенд или UAT, значит мы не останавливаем и не говорим:
— У вас здесь уязвимости, вы никуда дальше не пойдете!
На этом этапе важно сказать разработчикам, что есть проблемы безопасности, на которые стоит обратить внимание.
Наличие уязвимостей — не преграда для дальнейшего тестирования: ручного, интеграционного или мануального. С другой стороны, нам нужно как-то повысить безопасность продукта, и чтобы разработчики не забивали на то, что находит безопасность. Поэтому иногда мы поступаем так: на стенде, когда выкатывается на девелоперское окружение, просто оповещаем разработку:
— Ребята, у вас есть проблемы, пожалуйста, обратите на них внимание.
На этапе UAT опять показываем предупреждения о уязвимостях, а на этапе выхода в пром говорим:
— Ребята, мы несколько раз предупреждали, вы ничего не сделали — с этим не вас не выпустим.
Если говорить про код и динамику, то необходимо показывать и предупреждать об уязвимостях только тех фич и кода, который был написан только что в этой фиче. Если разработчик передвинул кнопочку на 3 пикселя и мы ему говорим, что у него там SQL-инъекция и поэтому нужно срочно поправить — это неправильно. Смотрите только на то, что написано сейчас, и на то изменение, которое приходит в приложение.
Допустим, у нас есть некий функциональный дефект — то, как приложение не должно работать: деньги не переводятся, при клике на кнопку нет перехода на следующую страницу или не загружается товар. Дефекты безопасности — это такие же дефекты, но не в разрезе работы приложения, а безопасности.
Не все проблемы качества ПО — это проблемы безопасности. Но все проблемы безопасности связаны с качеством ПО. Sherif Mansour, Expedia.
Поскольку все уязвимости — это такие же дефекты, они должны находится там же, где и все дефекты разработки. Поэтому забудьте об отчетах и страшных PDF, которые никто не читает.

Когда я работал в компании, которая занималась разработкой, мне пришел отчет из инструментов статического анализа. Я его открыл, ужаснулся, заварил кофе, полистал 350 страниц, закрыл и пошел работать дальше. Большие отчеты — мёртвые отчёты. Обычно они никуда не идут, письма удаляются, забываются, теряются или бизнес говорит, что он принимает риски.
Что делать? Подтвержденные дефекты, которые нашли, просто преобразуем в удобный для разработки вид, например, складываем в backlog в Jira. Дефекты приоритезируем и устраняем в порядке приоритета наравне с функциональными дефектами и дефектами тестов.
Статический анализ — SAST
Это анализ кода на наличие уязвимостей, но это не то же самое, что SonarQube. Мы проверяем не только по паттернам или стилю. При анализе применяется ряд подходов: по дереву уязвимостей, по , по анализу конфигурационных файлов. Это все, что касается непосредственно кода.
Плюсы подхода: выявление уязвимостей в коде на раннем этапе разработки, когда еще нет стендов и готового инструмента, и возможность инкрементального сканирования: сканирование участка кода, который изменился, и только той фичи, которую мы сейчас делаем, что уменьшает время сканирования.
Минусы — это отсутствие поддержки необходимых языков.
Необходимые интеграции, которые должны быть в инструментах, по моему субъективному мнению:
- Инструмент интеграции: Jenkins, TeamCity и Gitlab CI.
- Среда разработки: Intellij IDEA, Visual Studio. Разработчику удобнее не лазить в непонятный интерфейс, который еще надо запоминать, а прямо на рабочем месте в своей собственной среде разработки видеть все необходимые интеграции и уязвимости, которые он нашел.
- Code review: SonarQube и ручное ревью.
- Дефект-трекеры: Jira и Bugzilla.
На картинке несколько лучших представителей статического анализа.

Важны не инструменты, а процесс, поэтому существуют Open Source решения, которые также хороши для обкатки процесса.
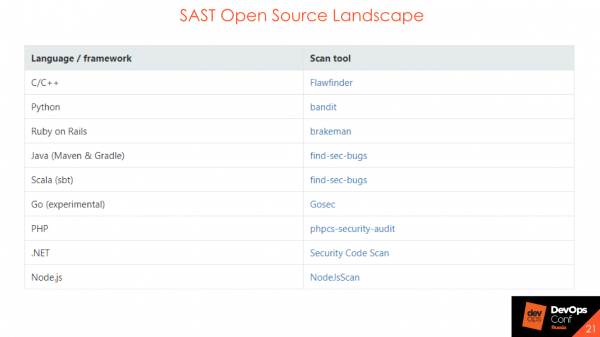
SAST Open Source не найдут огромное количество уязвимостей или сложные DataFlow, но при построении процесса их можно и нужно использовать. Они помогают понять, как будет построен процесс, кто будет отвечать на баги, кто репортить, кто — отчитываться. Если вы хотите провести начальный этап построения безопасности вашего кода — используйте Open Source решения.
Как это можно интегрировать, если вы в начале пути, у вас нет ничего: ни CI, ни Jenkins, ни TeamCity? Рассмотрим интеграции в процесс.
Интеграция на уровне CVS
Если у вас есть Bitbucket или GitLab, можно сделать интеграцию на уровне .
По событию — pull request, commit. Вы сканируете код и в статусе build’а показываете, что проверка на безопасность прошла или не прошла.
Обратная связь. Безусловно, обратная связь нужна всегда. Если вы просто выполнили на стороне security, в коробочку сложили и никому ничего не рассказали об этом, а потом в конце месяца вывалили кучу багов — это не правильно и не хорошо.
Интеграция с системой code review
Однажды, мы ставили в ряде важных проектов дефолтным ревьюером технического пользователя AppSec. В зависимости от того, выявлены ли ошибки в новом коде или ошибок нет, на pull request ревьюер проставляет статус на «accept» или «need work» — либо все ОК, либо нужно доработать и ссылки на то, что именно доработать. На интеграцию с версией, которая идет в прод, у нас был включен запрет merge, если тест по ИБ не пройден. Мы это включали в ручное code review, и остальные участники процесса видели статусы по безопасности именно для этого конкретного процесса.
Интеграция с SonarQube
У многих есть по качеству кода. Здесь то же самое — можно сделать те же самые gates только для инструментов SAST. Будет тот же интерфейс, тот же quality gate, только называться он будет security gate. И так же, если у вас поставлен процесс с использованием SonarQube, можно спокойно все туда интегрировать.
Интеграция на уровне CI
Здесь тоже все достаточно просто:
- На одном уровне с автотестами, юнит-тестами.
- Разделение по этапам разработки: dev, test, prod. Могут включаться разные наборы правил, либо разные fail conditions: стопаем сборку, не стопаем сборку.
- Синхронный/асинхронный запуск. Мы ждём окончание проверки тестов на безопасность или не ждем. То есть мы их просто запустили и идем дальше, а потом нам приходит статус, что все хорошо или плохо.
Это все в идеальном розовом мире. В реальной жизни такого нет, но мы стремимся. Результат выполнения проверок безопасности должен быть аналогичен результатам юнит-тестов.
Например, мы взяли большой проект и решили, что теперь будем сканировать его SAST’ом — ОК. Мы запихнули этот проект в SAST, он нам выдал 20 000 уязвимостей и волевым решением мы приняли, что все хорошо. 20 000 уязвимостей — это наш технический долг. Долг поместим в коробочку, будем потихонечку разгребать и заводить баги в дефект-трекеры. Наймем компанию, сделаем все сами или нам будут помогать Security Champions — и технический долг будет уменьшаться.
А все вновь появляющиеся уязвимости в новом коде должны быть устранены также, как ошибки в юнит или в автотестах. Условно говоря, запустилась сборка, прогнали, свалилось два теста и два теста по безопасности. ОК — сходили, посмотрели, что случилось, поправили одно, поправили второе, следующий раз прогнали — все хорошо, новых уязвимостей не появилось, тесты не провалены. Если эта задача глубже и нужно хорошо в ней разобраться, или исправление уязвимостей затрагивает большие пласты того, что лежит под капотом: завели баг в дефект-трекер, он приоретизируется и исправляется. К сожалению, мир не идеален и тесты иногда падают.
Пример security gate — аналог quality gate, по наличию и количеству уязвимостей в коде.
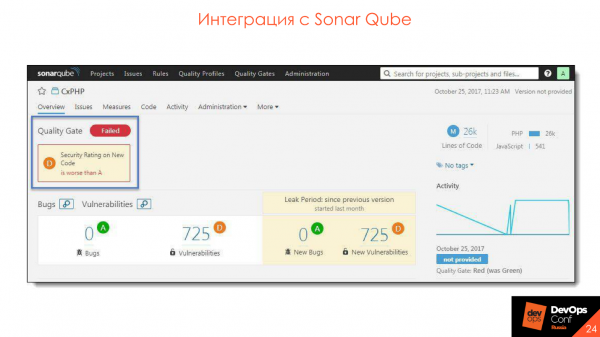 Интегрируем с SonarQube — плагин ставится, все очень удобно и классно.
Интегрируем с SonarQube — плагин ставится, все очень удобно и классно.
Интеграция cо средой разработки
Возможности интеграции:
- Запуск сканирования из среды разработки еще перед commit.
- Просмотр результатов.
- Анализ результатов.
- Синхронизация с сервером.
Примерно так выглядит получение результатов с сервера.
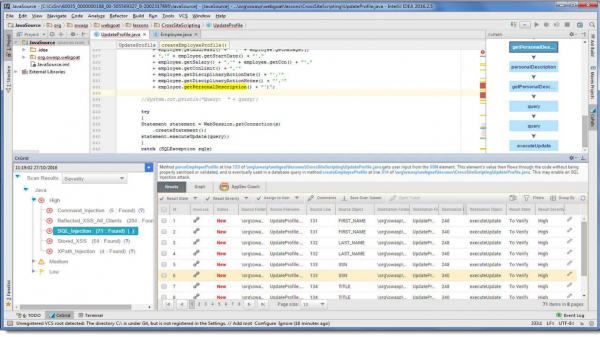
В нашей среде разработки просто появляется дополнительный пункт, который сообщает, что во время сканирования обнаружены такие уязвимости. Можно сразу править код, смотреть рекомендации и . Это все расположено на рабочем месте разработчика, что очень удобно — не надо ходить по остальным ссылкам и смотреть что-то дополнительно.
Open Source
Это моя любимая тема. Все используют Open Source библиотеки — зачем писать кучу костылей и велосипедов, когда можно взять готовую библиотеку, в которой все уже реализовано?

Конечно, это так, но библиотеки также пишутся людьми, также включают в себя определенные риски и также там присутствуют уязвимости, о которых периодически, или постоянно, сообщается. Поэтому есть следующий шаг в Application Security — это анализ Open Source компонент.
Анализ Open Source — OSA
Инструмент включает в себя три больших этапа.
Поиск уязвимостей в библиотеках. Например, инструмент знает, что мы используем какую-то библиотеку, и что в или в баг-трекерах есть какие-то уязвимости, которые относятся к этой версии библиотеки. При попытке ее использования инструмент выдаст предупреждение, что библиотека уязвима, и советует использовать другую версию, где уязвимостей нет.
Анализ лицензионной чистоты. У нас это пока не особо популярно, но если вы работаете с заграницей, то там периодически можно получить атата за использование компоненты с открытым исходным кодом, которую нельзя использовать или модифицировать. Согласно политике лицензионной библиотеки, мы это делать не можем. Либо, если мы ее модифицировали и используем, то должны выложить свой код. Конечно, никто не хочет выкладывать код своих продуктов, но от этого тоже можно защититься.
Анализ компонент, которые используются в промышленной среде. Представим гипотетическую ситуацию, что мы наконец завершили разработку и выпустили в пром последний релиз нашего микросервиса. Он там замечательно живет — неделю, месяц, год. Мы его не собираем, проверки по безопасности не проводим, вроде все хорошо. Но внезапно через две недели после выпуска выходит критическая уязвимость в Open Source компоненте, которую мы используем именно в этой сборке, в пром-среде. Если мы не записываем, что и где мы используем, то эту уязвимость просто не увидим. В некоторых инструментах есть возможность мониторинга уязвимостей в библиотеках, которые сейчас используются в проме. Это очень полезно.
Возможности:
- Различные политики для различных этапов разработки.
- Мониторинг компонент в промышленной среде.
- Контроль библиотек в контуре организации.
- Поддержка различных систем сборки и языков.
- Анализ Docker-образов.
Несколько примеров лидеров области, которые занимаются анализом Open Source.

Единственный бесплатный из них — это от OWASP. Его можно на первых этапах включить, посмотреть, как он работает и что поддерживает. В основном это все облачные продукты, либо on-premise, но за своей базой они все равно отправляются в интернет. Они отсылают не ваши библиотеки, а хэши или свои значения, которые высчитывают, и фингерпринты к себе на сервер, чтобы получить известие о наличии уязвимостей.
Интеграция в процесс
Контроль библиотек в периметре, которые скачиваются из внешних источников. У нас есть внешний и внутренний репозитории. Например, внутри Event Central стоит Nexus, и мы хотим, чтобы внутри нашего репозитория не было уязвимостей со статусом «критичный» или «высокий». Можно настроить проксирование с помощью инструмента Nexus Firewall Lifecycle так, чтобы такие уязвимости отсекались и не попадали во внутренний репозиторий.
Интеграция в CI. На одном уровне с автотестами, юнит-тестами и разделением по этапам разработки: dev, test, prod. На каждом этапе можно скачивать любые библиотеки, использовать что угодно, но, если там есть что-то жесткое со статусом «critical» -возможно, стоит обратить на это внимание разработчиков на этапе выхода в пром.
Интеграция с артефакториями: Nexus и JFrog.
Интеграция в среду разработки. Инструменты, которые вы выбираете, должны иметь интеграцию со средами разработки. Разработчик должен со своего рабочего места иметь доступ к результатам сканирования, либо возможность самому просканировать и проверить код на наличие уязвимостей до коммита в CVS.
Интеграция в CD. Это классная фишка, которая мне очень нравится и про которую я уже рассказывал — мониторинг появления новых уязвимостей в промышленной среде. Это работает примерно так.
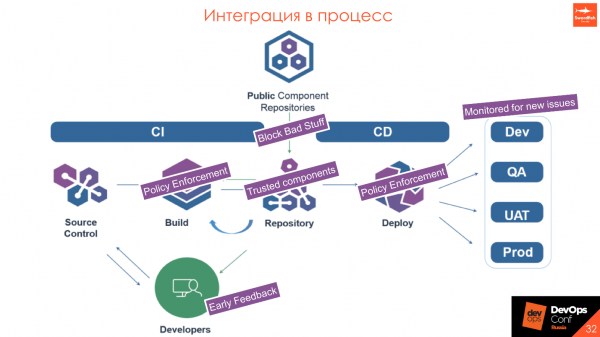
У нас есть Public Component Repositories — некие инструменты вовне, и наш внутренний репозиторий. Мы хотим, чтобы в нем были только trusted components. При проксировании запроса проверяем, что у скачиваемой библиотеки нет уязвимостей. Если она попадает под определенные политики, которые мы устанавливаем и обязательно согласовываем с разработкой, то ее не закачиваем и приходит отбивка на использование другой версии. Соответственно, если в библиотеке есть что-то реально критическое и плохое, то разработчик еще на этапе установки не получит библиотеку — пусть использует версию выше или ниже.
- При build’е мы проверяем, что никто не подсунул ничего плохого, что все компоненты безопасны и никто не принес на флэшке ничего опасного.
- В репозитории у нас только trusted components.
- При деплое мы еще раз проверяем именно сам пакет: war, jar, DL или Docker-образ на то, что он соответствует политике.
- При выходе в пром мы мониторим то, что происходит в промышленной среде: появляются или не появляются критические уязвимости.
Динамический анализ — DAST
Инструменты динамического анализа кардинально отличаются от всего, что было сказано до этого. Это некая имитация работы пользователя с приложением. Если это веб-приложение, мы отправляем запросы, имитируя работу клиента, нажимаем на кнопки на фронте, посылаем искусственные данные из формы: кавычки, скобки, символы в разной кодировке, чтобы посмотреть на то, как приложение работает и обрабатывает внешние данные.
Эта же система позволяет проверять шаблонные уязвимости в Open Source. Так как DAST не знает, какой Open Source мы используем, он просто кидает «зловредные» паттерны и анализирует ответы сервера:
— Ага, тут есть проблема десериализации, а тут нет.
В этом есть большие риски, потому что если вы проводите этот тест безопасности на том же стенде, с которым работают тестировщики — могут случиться неприятные вещи.
- Высокая нагрузка на сетьсервер приложения.
- Нет интеграций.
- Возможность изменения настроек анализируемого приложения.
- Нет поддержки необходимых технологий.
- Сложность настройки.
У нас была ситуация, когда мы наконец запустили AppScan: долго выбивали доступ к приложению, получили 3 учетки и обрадовались — наконец-то все проверим! Запустили сканирование, и первое, что сделал AppScan — залез в админ-панель, протыкал все кнопки, поменял половину данных, а потом вообще убил сервер своими -запросами. Разработка с тестированием сказали:
— Ребята, вы издеваетесь?! Мы вам дали учетки, а вы стенд положили!
Учитывайте возможные риски. В идеале готовьте отдельный стенд для тестирования ИБ, который будет изолирован от остального окружения хотя бы как-то, и условно проверять админку желательно в ручном режиме. Это пентест — те оставшиеся проценты усилий, которые мы сейчас не рассматриваем.
Стоит учесть, что можно использовать это как аналог нагрузочного тестирования. На первом этапе можно включить динамический сканер в 10-15 потоков и посмотреть, что получится, но обычно, как показывает практика, ничего хорошего.
Несколько ресурсов, которые обычно используем.

Стоит выделить — это «швейцарский нож» для любого специалиста по безопасности. Его используют все, и он очень удобный. Сейчас вышла новая демо-версия enterprise edition. Если раньше это была просто stand alone утилита с плагинами, то сейчас наконец-то разработчики делают большой сервер, с которого можно будет управлять несколькими агентами. Это круто, советую попробовать.
Интеграция в процесс
Интеграция происходит достаточно хорошо и просто: запуск сканирования после успешной установки приложения на стенд и сканирование после успешного проведения интеграционного тестирования.
Если интеграции не работают или там стоят заглушки и mock-функции, это бессмысленно и бесполезно — какой бы мы паттерн не отправляли, сервер будет все равно отвечать одинаково.
- Идеально — отдельный стенд для тестирования.
- До начала тестирования запишите последовательность логина.
- Тестирование системы администрирования — только ручное.
Процесс
Немножко обобщенно про процесс вообще и про работу каждого инструмента, в частности. Все приложения разные — у одного лучше работает динамический анализ, у другого статический, у третьего анализ OpenSource, пентесты или вообще что-то другое, например, события с .
Каждый процесс нуждается в контроле.
Чтобы понять как работает процесс и где его можно улучшить, нужно собирать метрики со всего, до чего дотянутся руки, в том числе производственные метрики, метрики с инструментов и из дефект-трекеров.
Любые данные полезны. Нужно смотреть в различных разрезах на то, где лучше применяется тот или иной инструмент, где процесс конкретно проседает. Может быть, стоит посмотреть на время отклика разработки, чтобы понять где улучшить процесс на основе времени. Чем больше данных, тем больше разрезов можно построить от верхнеуровневых до деталей каждого процесса.
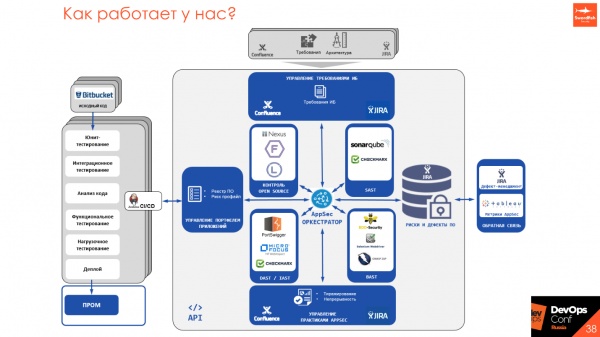
Так как у всех статических и динамических анализаторов свои API, свои способы запуска, принципы, у одних есть шедулеры, у других нет — мы пишем инструмент AppSec Оркестратор, который позволяет сделать единую точку входа в весь процесс с изделия и управлять им из одной точки.
У менеджеров, разработчиков и security-инженеров одна точка входа, из которой можно посмотреть, что запущено, настроить и запустить сканирование, получить результаты сканирования, предъявить требования. Мы стараемся уходить от бумажек, переводить все в человеческий, который использует разработка — страницы на Confluence со статусом и метриками, дефекты в Jira или в различных дефект-трекерах, либо встраивание в синхронный/асинхронный процесс в CI/CD.
Key Takeaways
Инструменты не главное. Сначала продумать процесс — затем внедрять инструменты. Инструменты хороши, но дороги, поэтому можно начать с процесса и настроить взаимодействие и понимание между разработкой и безопасностью. С точки зрения безопасности — не нужно «стопить» все подряд, С точки зрения разработки — если есть что-то high mega super critical, то это нужно устранять, а не закрывать на проблему глаза.
Качество продукта — общая цель как безопасности, так и разработки. Мы делаем одно дело, стараемся, чтобы все правильно работало и не было репутационных рисков и финансовых потерь. Именно поэтому мы пропагандируем подход к DevSecOps, SecDevOps, чтобы наладить общение и сделать продукт качественнее.
Начните с того, что уже есть: требования, архитектура, частичные проверки, тренинги, гайдлайны. Не нужно сразу применять все практики на все проекты — двигайтесь итерационно. Единого стандарта нет — экспериментируйте и пробуйте различные подходы и решения.
Между дефектами ИБ и функциональными дефектами знак равенства.
Автоматизируйте всё, что двигается. Всё, что не двигается — двигайте и автоматизируйте. Если что-то делается руками, это не хороший участок процесса. Возможно, стоит его пересмотреть и тоже автоматизировать.
Если размер команды ИБ небольшой — используйте Security Champions.
Возможно, то, о чем я рассказывал, вам не подойдет и вы придумаете что-то свое — и это хорошо. Но выбирайте инструменты, исходя из требований именно к своему процессу. Не смотрите на то, что говорит community, что этот инструмент плохой, а этот хороший. Возможно, именно на вашем продукте окажется все наоборот.
Требования к инструментам.
- Низкий уровень False Positive.
- Адекватное время анализа.
- Удобство использования.
- Наличие интеграций.
- Понимание Roadmap развития продукта.
- Возможность кастомизации инструментов.
Доклад Юрия выбрали одним из лучших на DevOpsConf 2018. Чтобы познакомиться с еще большим количеством интересных идей и практических кейсов приходите 27 и 28 мая в Сколково на в рамках . А еще лучше, если вы готовы делиться своим опытом, тогда на доклад до 21 апреля.
Источник: habr.com
