

Анонс
Коллеги, в середине лета я планирую выпустить еще один цикл статей по проектированию систем массового обслуживания: “Эксперимент VTrade” — попытка написать фреймворк для торговых систем. В цикле будет разобрана теория и практика построения биржи, аукциона и магазина. В конце статьи предлагаю проголосовать за наиболее интересные вам темы.

Это завершающая статья цикла по распределенным реактивным приложениям на Erlang/Elixir. В можно найти теоретические основы реактивной архитектуры. иллюстрирует основные шаблоны и механизмы построения подобных систем.
Сегодня мы поднимем вопросы развития кодовой базы и проектов в целом.
Организация сервисов
В реальной жизни при разработке сервиса часто приходится объединять несколько шаблонов взаимодействия в одном контроллере. Например, сервис users, решающий задачи управления профилями пользователей проекта, должен отвечать на запросы req-resp и сообщать об обновлениях профилей через pub-sub. Этот случай довольно простой: за messaging стоит один контроллер, реализующий логику сервиса и публикующий обновления.
Ситуация усложняется, когда нам нужно реализовать отказоустойчивый распределенный сервис. Представим, что требования к users изменились:
- теперь сервис должен обрабатывать запросы на 5 узлах кластера,
- иметь возможность выполнения фоновых задач обработки,
- а также уметь динамически управлять списками подписки на обновления профилей.
Замечание: Вопрос консистентного хранения и репликации данных мы не рассматриваем. Предположим, что эти вопросы решены ранее и в системе уже существует надежный и масштабируемый слой хранения, а обработчики имеют механизмы взаимодействия с ним.
Формальное описание сервиса users усложнилось. С точки зрения программиста благодаря использованию messaging изменения минимальны. Чтобы удовлетворить первому требованию, нам нужно настроить балансировку на точке обмена req-resp.
Требование обработки фоновых задач возникает часто. В users это могут быть проверки документов пользователей, обработка загруженного мультимедиа, или синхронизация данных с соц. сетями. Эти задачи нужно как-то распределять в рамках кластера и контролировать ход выполнения. Поэтому у нас два варианта решения: либо использовать шаблон распределения задач из прошлой статьи, либо, если он не подходит, написать кастомный планировщик задач, который будет необходимым нам образом управлять пулом обработчиков.
3 пункт требует расширения шаблона pub-sub. И для реализации, после создания точки обмена pub-sub, нам необходимо дополнительно запустить контроллер этой точки в рамках нашего сервиса. Таким образом, мы как будто выносим логику обработки подписки и отписки из слоя messaging в реализацию users.
В итоге, декомпозиция задачи показала, что для удовлетворения требований нам нужно запустить на разных узлах 5 экземпляров сервиса и создать дополнительную сущность – контроллер pub-sub, отвечающий за подписку.
Для запуска 5 обработчиков не требуется менять код сервиса. Единственное дополнительное действие – настройка правил балансировки на точке обмена, о чем мы поговорим чуть позже.
Также появилась дополнительная сложность: контроллер pub-sub и кастомный планировщик задач должны работать в единственном экземпляре. Опять же, сервис messaging, как фундаментальный, должен предоставлять механизм выбора лидера.
Выбор лидера
В распределенных системах выбор лидера – процедура назначения единственного процесса, отвечающего за планирование распределенной обработки какой-то нагрузки.
В системах, не склонных к централизации, находят применение универсальные алгоритмы и алгоритмы на основе консенсуса, например paxos или raft.
Поскольку messaging – это брокер и центральный элемент, то он знает обо всех контроллерах сервиса – кандидатах в лидеры. Messaging может назначать лидера без проведения голосования.
Все сервисы после старта и подключения к точке обмена получают системное сообщение #'$leader'{exchange = ?EXCHANGE, pid = LeaderPid, servers = Servers}. В случае если LeaderPid совпадает с pid текущего процесса, он назначается лидером, а список Servers включает в себя все узлы и их параметры.
В момент появления нового и отключения работающего узла кластера, все контроллеры сервиса получают #'$slave_up'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} и #'$slave_down'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} соответственно.
Таким образом, все компоненты знают обо всех изменениях, и в кластере в каждый момент времени гарантированно один лидер.
Посредники
Для реализации сложных распределенных процессов обработки, а также в задачах оптимизации уже существующей архитектуры удобно применять посредников.
Чтобы не менять код сервисов и решать, например, задачи дополнительной обработки, маршрутизации или логирования сообщений, перед сервисом можно включить proxy обработчик, который выполнит всю дополнительную работу.
Классическим примером оптимизации pub-sub является распределенное приложение с бизнес-ядром, генерирующим события обновлений, например изменение цены на рынке, и слой доступа — N серверов, предоставляющих websocket API для web клиентов.
Если решать “в лоб”, то обслуживание клиента выглядит следующим образом:
- клиент устанавливает соединения с платформой. На стороне сервера, терминирующего трафик, происходит запуск процесса, обслуживающего это подключение.
- в контексте обслуживающего процесса происходит авторизация и подписка на обновления. Процесс вызывает метод subscribe для топиков.
- после генерации события в ядре оно доставляется процессам, обслуживающим подключения.
Представим, что у нас 50000 подписчиков на топик “news”. Подписчики распределены по 5 серверам равномерно. В итоге каждое обновление, придя на точку обмена, будет реплицированно 50000 раз: 10000 раз на каждый сервер, по количеству подписчиков на нем. Не совсем эффективная схема, правда?
Чтобы улучшить ситуацию, введем proxy, имеющий одно и то же имя с точкой обмена. Регистратор глобальных имен должен уметь возвращать ближайший процесс по имени, это важно.
Запустим этот proxy на серверах слоя доступа, и все наши процессы, обслуживающие websocket api, подпишутся на него, а не на исходную pub-sub точку обмена в ядре. Proxy подписывается на ядро только в случае уникальной подписки и реплицирует поступившее сообщение по всем своим подписчикам.
В итоге между ядром и серверами доступа будет переслано 5 сообщений, вместо 50000.
Маршрутизация и балансировка
Req-Resp
В текущей реализации messaging существует 7 стратегий распределения запросов:
default. Запрос передается всем контроллерам.round-robin. Осуществляется перебор и циклическое распределение запросов между контроллерами.consensus. Контроллеры, обслуживающие сервис, делятся на лидера и ведомых. Запросы передаются только лидеру.consensus & round-robin. В группе есть лидер, но запросы распределяются между всеми членами.sticky. Вычисляется hash функция и закрепляется за определенным обработчиком. Последующие запросы с этой сигнатурой попадают к этому же обработчику.sticky-fun. При инициализации точки обмена дополнительно передается функция вычисления хэша дляstickyбалансировки.fun. Аналогичен sticky-fun, только дополнительно можно переадресовать, отклонить или предобработать его.
Стратегия распределения задается при инициализации точки обмена.
Кроме балансировки messaging позволяет тэгировать сущности. Рассмотрим виды тэгов в системе:
- Тэг подключения. Позволяет понять, через какое подключение пришли события. Используется, когда процесс контроллера подключается к одной точке обмена, но с различными ключами маршрутизации.
- Тэг сервиса. Позволяет для одного сервиса объединять в группы обработчики и расширять возможности маршрутизации и балансировки. Для req-resp паттерна маршрутизация линейна. Мы отправляем запрос на точку обмена, дальше она передает его сервису. Но если нам нужно разбить обработчики на логические группы, то разбиение осуществляется с помощью тэгов. При указании тэга, запрос будет направлен на конкретную группу контроллеров.
- Тэг запроса. Позволяет отличать ответы. Так как наша система асинхронная, то для обработки ответов сервиса нужно иметь возможность указать RequestTag при отправке запроса. По нему мы сможем понять, ответ на какой запрос к нам пришел.
Pub-sub
Для pub-sub все немного проще. Мы имеем точку обмена на которую публикуются сообщения. Точка обмена распределяет сообщения между подписчиками, которые подписались на нужные им ключи маршрутизации (можно сказать, что это аналог тем).
Масштабируемость и отказоустойчивость
Масштабируемость системы в целом зависит от степени масштабируемости слоев и компонентов системы:
- Сервисы масштабируются путем добавления в кластер дополнительных узлов с обработчиками этого сервиса. В процессе опытной эксплуатации можно выбрать оптимальную политику балансировки.
- Сам же сервис messaging в рамках отдельного кластера в общем случае масштабируется либо путем выноса особо нагруженных точек обмена на отдельные узлы кластера, либо добавлением proxy процессов в особо нагруженные зоны кластера.
- Масштабируемость всей системы как характеристика зависит от гибкости архитектуры и возможности объединения отдельных кластеров в общую логическую сущность.
От простоты и скорости масштабирования часто зависит успешность проекта. Messaging в текущем исполнении растет вместе с приложением. Даже если нам не хватает кластера в 50-60 машин, можно прибегнуть к федерации. К сожалению, тема федерирования выходит за рамки данной статьи.
Резервирование
При разборе балансировки нагрузки мы уже обсуждали резервирование контроллеров сервисов. Однако messaging тоже должен быть зарезервирован. В случае падения узла или машины, messaging должен автоматически восстановиться, причем в кратчайшие сроки.
В своих проектах я использую дополнительные узлы, которые подхватывают нагрузку в случае падения. В Erlang существует стандартная реализация распределенного режима для приложений OTP. Distributed mode, как раз и осуществляет восстановление в случае сбоя путем запуска упавшего приложения на другом предварительно запущенном узле. Процесс прозрачен, после сбоя приложение переезжает автоматически на failover узел. Почитать про этот функционал подробнее можно .
Производительность
Попробуем хотя бы приблизительно сравнить производительность rabbitmq и нашего кастомного messaging.
Я нашел тестирования rabbitmq от команды openstack.
В пункте 6.14.1.2.1.2.2. оригинального документа представлен результат RPC CAST:
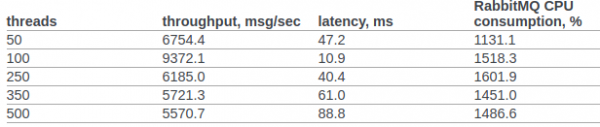
Предварительно никаких дополнительных настроек в ядро ОС или erlang VM вносить не будем. Условия для тестирования:
- erl opts: +A1 +sbtu.
- Тест в рамках одного узла erlang запускается на ноутбуке со стареньким i7 в мобильном исполнении.
- Кластерные тесты проходят на серверах с 10G сетью.
- Код работает в docker контейнерах. Сеть в режиме NAT.
Код теста:
req_resp_bench(_) ->
W = perftest:comprehensive(10000,
fun() ->
messaging:request(?EXCHANGE, default, ping, self()),
receive
#'$msg'{message = pong} -> ok
after 5000 ->
throw(timeout)
end
end
),
true = lists:any(fun(E) -> E >= 30000 end, W),
ok.Сценарий 1: Тест запускается на ноутбуке со стареньким i7 мобильного исполнения. Тест, messaging и сервис выполняются на одном узле в одном docker-контейнере:
Sequential 10000 cycles in ~0 seconds (26987 cycles/s)
Sequential 20000 cycles in ~1 seconds (26915 cycles/s)
Sequential 100000 cycles in ~4 seconds (26957 cycles/s)
Parallel 2 100000 cycles in ~2 seconds (44240 cycles/s)
Parallel 4 100000 cycles in ~2 seconds (53459 cycles/s)
Parallel 10 100000 cycles in ~2 seconds (52283 cycles/s)
Parallel 100 100000 cycles in ~3 seconds (49317 cycles/s)Сценарий 2: 3 узла запущенные на разных машинах под docker (NAT).
Sequential 10000 cycles in ~1 seconds (8684 cycles/s)
Sequential 20000 cycles in ~2 seconds (8424 cycles/s)
Sequential 100000 cycles in ~12 seconds (8655 cycles/s)
Parallel 2 100000 cycles in ~7 seconds (15160 cycles/s)
Parallel 4 100000 cycles in ~5 seconds (19133 cycles/s)
Parallel 10 100000 cycles in ~4 seconds (24399 cycles/s)
Parallel 100 100000 cycles in ~3 seconds (34517 cycles/s)Во всех случаях утилизация CPU не превышала 250%
Итоги
Надеюсь, данный цикл не выглядит, как дамп сознания и мой опыт принесет реальную пользу как исследователям распределенных систем, так и практикам, которые находятся в самом начале пути построения распределенных архитектур для своих бизнес-систем и с интересом смотрят на Erlang/Elixir, но сомневаются стоит ли…
Фото
Только зарегистрированные пользователи могут участвовать в опросе. , пожалуйста.
Какие темы мне стоит осветить наиболее подробно в рамках цикла “Эксперимент VTrade”?
Теория: Рынки, ордеры и время их действия: DAY, GTD, GTC, IOC, FOK, MOO, MOC, LOO, LOC
Книга ордеров. Теория и практика реализации книги с группировками
Визуализация торгов: Тики, бары, резолюции. Как хранить и как клеить
Бэкофис. Планирование и разработка. Контроль сотрудников и расследование инцидентов
API. Разбираемся какие интерфейсы нужны и как их реализовать
Хранение информации: PostgreSQL, Timescale, Tarantool в торговых системах
Реактивность в торговых системах
Другое. Напишу в комментариях
Проголосовали 6 пользователей. Воздержались 4 пользователя.
Источник: habr.com
