

О том, как пришлось заняться оптимизацией запроса PostgreSQL и что из всего этого получилось.
Почему пришлось? Да потому, что предыдущие 4 года все работало тихо, спокойно, как часики тикали.
В качестве эпиграфа.

Основано на реальных событиях.
Все имена изменены, совпадения случайны.
При достижении некоторого результата всегда интересно вспомнить, что-же послужило толчком к началу, с чего все началось.
Итак, что в результате получилось, кратко описано в статье «».
Наверное, занятно будет воссоздать цепочку предшествующих событий.
История сохранила точную дату начала — 2018-09-10 18:02:48.
Так же, в истории есть запрос, с которого всё началось:
Проблемный запросSELECT
p.«PARAMETER_ID» as parameter_id,
pd.«PD_NAME» AS pd_name,
pd.«CUSTOMER_PARTNUMBER» AS customer_partnumber,
w.«LRM» AS LRM,
w.«LOTID» AS lotid,
w.«RTD_VALUE» AS RTD_value,
w.«LOWER_SPEC_LIMIT» AS lower_spec_limit,
w.«UPPER_SPEC_LIMIT» AS upper_spec_limit,
p.«TYPE_CALCUL» AS type_calcul,
s.«SPENT_NAME» AS spent_name,
s.«SPENT_DATE» AS spent_date,
extract(year from «SPENT_DATE») AS year,
extract(month from «SPENT_DATE») as month,
s.«REPORT_NAME» AS report_name,
p.«STPM_NAME» AS stpm_name,
p.«CUSTOMERPARAM_NAME» AS customerparam_name
FROM wdata w,
spent s,
pmtr p,
spent_pd sp,
pd pd
WHERE s.«SPENT_ID» = w.«SPENT_ID»
AND p.«PARAMETER_ID» = w.«PARAMETER_ID»
AND s.«SPENT_ID» = sp.«SPENT_ID»
AND pd.«PD_ID» = sp.«PD_ID»
AND s.«SPENT_DATE» >= ‘2018-07-01’ AND s.«SPENT_DATE» <= ‘2018-09-30’
and s.«SPENT_DATE» = (SELECT MAX(s2.«SPENT_DATE»)
FROM spent s2,
wdata w2
WHERE s2.«SPENT_ID» = w2.«SPENT_ID»
AND w2.«LRM» = w.«LRM»);
Описание проблемы, предсказуемо стандартно — “Все плохо. Подскажите в чем проблема”.
Сразу же вспомнился анекдот времен дисководов на 3 с половиной дюйма:
Приходит ламер к хакеру.
-У меня ничего не работает, подскажи, где проблема.
-В ДНК…
Но так решать инциденты производительности, конечно, нельзя. “Нас могут не понять” (с). Надо разбираться.
Что ж, будем копать. Может, что и накопается в результате.

Investigation started
Итак, что видно сразу невооруженным взглядом, даже не прибегая к помощи EXPLAIN.
1) Не используются JOIN. Это плохо, особенно если число соединений больше одного.
2) Но что еще хуже — коррелированные подзапрос, к тому, же с агрегацией. Это очень плохо.
Это плохо конечно. Но это только, с одной стороны. С другой стороны, это очень хорошо, потому что задача однозначно имеет решение и запрос, можно улучшить.
К гадалке не ходи(С).
План запроса не такой уж сложный, однако вполне показательный:
План выполнения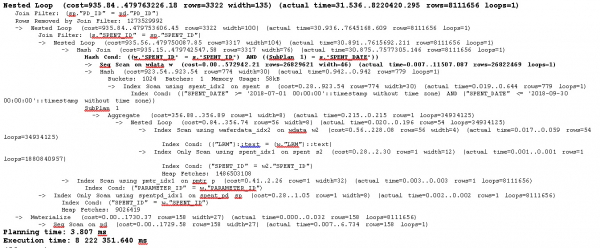
Самое интересное и полезное, как обычно, в начале и конце.
Nested Loop (cost=935.84..479763226.18 rows=3322 width=135) (actual time=31.536..8220420.295 rows=8111656 loops=1)
Planning time: 3.807 ms
Execution time: 8222351.640 ms
Время выполнения более 2-х часов.

Ложные гипотезы, занявшие время
Гипотеза 1- Оптимизатор ошибается, строит неправильный план.
Для визуализации плана выполнения воспользуемся сайтом . Впрочем, ничего интересного или полезного сайт не показал. На первый и второй взгляд — ничего, что могло бы реально помочь. Разве, что — Full Scan минимальный. Идем, дальше.
Гипотеза 2-Импакт на базу со стороны autovacuum, нужно избавиться от тормозов.
Но, демоны autovacuum ведут себя хорошо, долго висящих процессов нет. Сколь-нибудь серьезной нагрузки — нет. Нужно искать, что-то еще.
Гипотеза 3-Статистика устаревшая, нужно пересчитать всё залетает
Опять, не то. Статистика актуальная. Что, учитывая отсутствие проблем с autovacuum, неудивительно.
Начинаем оптимизировать
Главная таблица ‘wdata’ конечно же не маленькая, почти 3 миллиона записей.
И именно по этой таблице идет Full Scan.
Hash Cond: ((w.«SPENT_ID» = s.«SPENT_ID») AND ((SubPlan 1) = s.«SPENT_DATE»))
-> Seq Scan on wdata w (cost=0.00..574151.49 rows=26886249 width=46) (actual time=0.005..8153.565 rows=26873950 loops=1)
Поступаем стандартно: «а давай, сделаем индекс и все залетает».
Сделали индекс по полю «SPENT_ID»
В результате:
План выполнения запроса с использованием индекса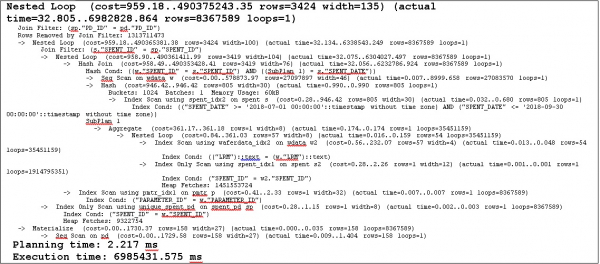
Ну что, помогло?
Было: 8 222 351.640 ms (чуть больше 2-х часов)
Стало: 6 985 431.575 ms (почти 2 часа)
В общем-то, те же яблоки, вид сбоку.
Вспоминаем классику:
«А у вас есть, такой же, но без крыльев? Будем искать».

В принципе, это можно было бы назвать хорошим результатом, ну не хорошим, но приемлемым. По крайней мере, предоставить большой отчет заказчику с описанием того, сколько много всего было сделано и почему то, что сделано то и хорошо.
Но все-таки до окончательного решения еще далеко. Очень далеко.
А вот теперь самое интересное — продолжаем оптимизировать, будем полировать запрос
Шаг первый — использовать JOIN
Переписанный запрос, теперь выглядит так (ну как минимум красивее):
Запрос с использованием JOINSELECT
p.«PARAMETER_ID» as parameter_id,
pd.«PD_NAME» AS pd_name,
pd.«CUSTOMER_PARTNUMBER» AS customer_partnumber,
w.«LRM» AS LRM,
w.«LOTID» AS lotid,
w.«RTD_VALUE» AS RTD_value,
w.«LOWER_SPEC_LIMIT» AS lower_spec_limit,
w.«UPPER_SPEC_LIMIT» AS upper_spec_limit,
p.«TYPE_CALCUL» AS type_calcul,
s.«SPENT_NAME» AS spent_name,
s.«SPENT_DATE» AS spent_date,
extract(year from «SPENT_DATE») AS year,
extract(month from «SPENT_DATE») as month,
s.«REPORT_NAME» AS report_name,
p.«STPM_NAME» AS stpm_name,
p.«CUSTOMERPARAM_NAME» AS customerparam_name
FROM wdata w INNER JOIN spent s ON w.«SPENT_ID»=s.«SPENT_ID»
INNER JOIN pmtr p ON p.«PARAMETER_ID» = w.«PARAMETER_ID»
INNER JOIN spent_pd sp ON s.«SPENT_ID» = sp.«SPENT_ID»
INNER JOIN pd pd ON pd.«PD_ID» = sp.«PD_ID»
WHERE
s.«SPENT_DATE» >= ‘2018-07-01’ AND s.«SPENT_DATE» <= ‘2018-09-30’AND
s.«SPENT_DATE» = (SELECT MAX(s2.«SPENT_DATE»)
FROM wdata w2 INNER JOIN spent s2 ON w2.«SPENT_ID»=s2.«SPENT_ID»
INNER JOIN wdata w
ON w2.«LRM» = w.«LRM» );
Planning time: 2.486 ms
Execution time: 1223680.326 ms
Итак, первый результат.
Было: 6 985 431.575 ms (почти 2 часа).
Стало: 1 223 680.326 ms (чуть больше 20 минут).
Хороший результат. В принципе, опять, можно было бы на этом и остановиться. Но так неинтересно, нельзя останавливаться.
ИБО

Шаг второй — избавиться от коррелированного подзапроса
Измененный текст запроса:
Без коррелированного подзапросаSELECT
p.«PARAMETER_ID» as parameter_id,
pd.«PD_NAME» AS pd_name,
pd.«CUSTOMER_PARTNUMBER» AS customer_partnumber,
w.«LRM» AS LRM,
w.«LOTID» AS lotid,
w.«RTD_VALUE» AS RTD_value,
w.«LOWER_SPEC_LIMIT» AS lower_spec_limit,
w.«UPPER_SPEC_LIMIT» AS upper_spec_limit,
p.«TYPE_CALCUL» AS type_calcul,
s.«SPENT_NAME» AS spent_name,
s.«SPENT_DATE» AS spent_date,
extract(year from «SPENT_DATE») AS year,
extract(month from «SPENT_DATE») as month,
s.«REPORT_NAME» AS report_name,
p.«STPM_NAME» AS stpm_name,
p.«CUSTOMERPARAM_NAME» AS customerparam_name
FROM wdata w INNER JOIN spent s ON s.«SPENT_ID» = w.«SPENT_ID»
INNER JOIN pmtr p ON p.«PARAMETER_ID» = w.«PARAMETER_ID»
INNER JOIN spent_pd sp ON s.«SPENT_ID» = sp.«SPENT_ID»
INNER JOIN pd pd ON pd.«PD_ID» = sp.«PD_ID»
INNER JOIN (SELECT w2.«LRM», MAX(s2.«SPENT_DATE»)
FROM spent s2 INNER JOIN wdata w2 ON s2.«SPENT_ID» = w2.«SPENT_ID»
GROUP BY w2.«LRM»
) md on w.«LRM» = md.«LRM»
WHERE
s.«SPENT_DATE» >= ‘2018-07-01’ AND s.«SPENT_DATE» <= ‘2018-09-30’;
Planning time: 2.291 ms
Execution time: 165021.870 ms
Было: 1 223 680.326 ms (чуть больше 20 минут).
Стало: 165 021.870 ms (чуть больше 2 минут).
Вот это уже совсем хорошо.
Однако, как говорят англичане «But, there is always a but». Слишком хороший результат, должен автоматически вызвать подозрение. Что-то тут не так.
Гипотеза о исправлении запроса с целью избавления от коррелированного подзапроса — правильная. Но нужно чуть-чуть доработать, чтобы итоговый результат был верным.
В итоге, первый промежуточный результат:
Отредактированный запрос без коррелированного подзапросаSELECT
p.«PARAMETER_ID» as parameter_id,
pd.«PD_NAME» AS pd_name,
pd.«CUSTOMER_PARTNUMBER» AS customer_partnumber,
w.«LRM» AS LRM,
w.«LOTID» AS lotid,
w.«RTD_VALUE» AS RTD_value,
w.«LOWER_SPEC_LIMIT» AS lower_spec_limit,
w.«UPPER_SPEC_LIMIT» AS upper_spec_limit,
p.«TYPE_CALCUL» AS type_calcul,
s.«SPENT_NAME» AS spent_name,
s.«SPENT_DATE» AS spent_date,
extract(year from s.«SPENT_DATE») AS year,
extract(month from s.«SPENT_DATE») as month,
s.«REPORT_NAME» AS report_name,
p.«STPM_NAME» AS stpm_name,
p.«CUSTOMERPARAM_NAME» AS customerparam_name
FROM wdata w INNER JOIN spent s ON s.«SPENT_ID» = w.«SPENT_ID»
INNER JOIN pmtr p ON p.«PARAMETER_ID» = w.«PARAMETER_ID»
INNER JOIN spent_pd sp ON s.«SPENT_ID» = sp.«SPENT_ID»
INNER JOIN pd pd ON pd.«PD_ID» = sp.«PD_ID»
INNER JOIN ( SELECT w2.«LRM», MAX(s2.«SPENT_DATE») AS «SPENT_DATE»
FROM spent s2 INNER JOIN wdata w2 ON s2.«SPENT_ID» = w2.«SPENT_ID»
GROUP BY w2.«LRM»
) md ON md.«SPENT_DATE» = s.«SPENT_DATE» AND md.«LRM» = w.«LRM»
WHERE
s.«SPENT_DATE» >= ‘2018-07-01’ AND s.«SPENT_DATE» <= ‘2018-09-30’;
Planning time: 3.192 ms
Execution time: 208014.134 ms
Итак, что имеем в итоге — первый приемлемый результат, который не стыдно показать заказчику:
Началось с: 8 222 351.640 ms (более 2-х часов)
Удалось добиться: 1 223 680.326 ms (чуть больше 20 минут).
Итог(промежуточный): 208 014.134 ms (чуть больше 3-х минут).
Отличный результат.

Итог
На этом можно было бы и остановиться.
НО…
Аппетит приходит во время еды. Дорогу осилит, идущий. Любой результат- промежуточный. Остановился-умер. И т.д и т.п.
А давайте, продолжим оптимизацию.
Отличная идея. Особенно, учитывая то, что заказчик был очень даже не против. А даже сильно — за.
Итак, пришло время для изменения дизайна базы данных. Саму структуру запроса уже не оптимизировать (хотя, как потом выяснилось, есть вариант для того, чтобы все реально залетало). Но вот заняться оптимизацией и развитием дизайна базы данных, это уже очень перспективная идея. И главное интересная. Опять-таки, молодость вспомнить. Я ведь ни сразу стал DBA, из программистов вырос (бейсик, ассемблер, си, си дважды плюсанутый, оракл,plsql). Интересная конечно тема, для отдельных мемуаров ;-).
Впрочем, не будем отвлекаться.
Итак,

А может быть секционирование нам поможет?
Спойлер — «Да помогло, и в оптимизации быстродействия, в том числе.»
Но это уже совсем другая история…
Продолжение, следует…
Источник: habr.com
