

В преддверии старта курса подготовили для вас еще один полезный перевод.
Графовые базы данных — это важная технология для специалистов по базам данных. Я стараюсь следить за инновациями и новыми технологиями в этой области и, после работы с реляционными и NoSQL базами данных, я вижу, что роль графовых баз данных становится все больше. В работе со сложными иерархическими данными малоэффективны не только традиционные базы данных, но и NoSQL. Часто, с увеличением количества уровней связей и размера базы, наблюдается снижение производительности. А с усложнением взаимосвязей увеличивается и количество JOIN.
Конечно, в реляционной модели есть решения для работы с иерархиями (например, с помощью рекурсивных CTE), но это все равно остается обходными путями. При этом, функционал графовых баз данных SQL Server позволяет с легкостью обрабатывать несколько уровней иерархии. Упрощаются как модель данных, так и запросы, а следовательно, увеличивается их эффективность. Значительно сокращается объем кода.
Графовые базы данных — это выразительный язык для представления сложных систем. Эта технология уже довольно широко используется в ИТ-индустрии в таких областях, как социальные сети, антифрод-системы, анализ ИТ-сетей, социальные рекомендации, рекомендации по продуктам и контенту.
Функционал графовых баз данных в SQL Server подходит для сценариев, в которых данные сильно связаны между собой и имеют четко определенные связи.
Графовая модель данных
Граф — это множество вершин (узлов, node) и ребер (взаимосвязей, edge). Вершины представляют сущности, а ребра — связи, в атрибутах которых может содержаться информация.
Графовая база данных моделирует сущности в виде графа в том виде, как это определено в теории графов. Структуры данных — это вершины и ребра. Атрибуты — это свойства вершин и ребер. Связь — это соединение вершин.
В отличие от других моделей данных, в графовых базах данных в приоритете взаимосвязи между сущностями. Поэтому не требуется вычислять связи с помощью внешних ключей или какими-то другими способами. Можно создавать сложные модели данных, используя только абстракции вершин и ребер.
В современном мире моделирование взаимосвязей требует все более сложных методик. Для моделирования связей SQL Server 2017 предлагает возможности графовых баз данных. Вершины и ребра графа представляются в виде новых типов таблиц: NODE и EDGE. Для запросов к графу используется новая функция T-SQL под названием MATCH(). Так как этот функционал встроен в SQL Server 2017, то его можно использовать в ваших существующих базах данных без необходимости какой-либо их конвертации.
Польза графовой модели
В настоящее время бизнес и пользователи требуют приложений, которые работают все с большим и большим объемом данных, ожидая при этом высокой производительности и надежности. Представление данных в виде графа предлагает удобные средства для обработки сложных связей. Этот подход позволяет решить многие проблемы и помогает получить результаты в рамках заданного контекста.
Судя по всему, в будущем многие приложения смогут выиграть от использования графовых баз данных.
Моделирование данных: от реляционной модели к графовой
Пример
Давайте рассмотрим пример организационной структуры с иерархией сотрудников: сотрудник подчиняется менеджеру, менеджер — старшему менеджеру и так далее. В зависимости от конкретной компании в этой иерархии может быть любое количество уровней. Но с увеличением количества уровней вычисление связей в реляционной базе данных становится все сложнее и сложнее. В ней довольно сложно представить иерархию сотрудников, иерархию в маркетинге или связи в социальных сетях. Давайте посмотрим, как с помощью SQL Graph можно решить проблему с обработкой различных уровней иерархии.
Для этого примера сделаем простую модель данных. Создадим таблицу сотрудников EMP с идентификатором EMPNO и колонкой MGR, указывающей на идентификатор руководителя (менеджера) сотрудника. Вся информация об иерархии хранится в этой таблице и может быть запрошена с помощью колонок EMPNO и MGR.
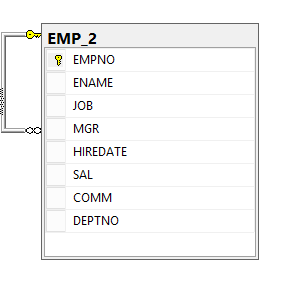
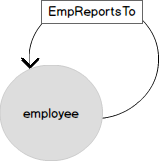
На следующей диаграмме изображена так же самая модель оргструктуры с четырьмя уровнями вложенности в более привычном виде. Сотрудники — это вершины графа из таблицы EMP. Сущность «сотрудник» связана сама с собою связью «подчиняется» (ReportsTo). В терминах графа, связь — это ребро (EDGE), которое связывает узлы (NODE) сотрудников.
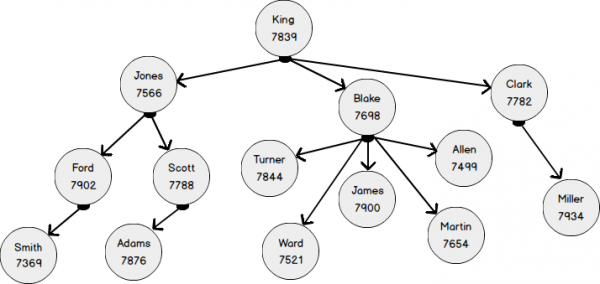
Давайте создадим обычную таблицу EMP и добавим туда значения в соответствии с вышеприведенной диаграммой.
CREATE TABLE EMP
(EMPNO INT NOT NULL,
ENAME VARCHAR(20),
JOB VARCHAR(10),
MGR INT,
JOINDATE DATETIME,
SALARY DECIMAL(7, 2),
COMMISIION DECIMAL(7, 2),
DNO INT)
INSERT INTO EMP VALUES
(7369, 'SMITH', 'CLERK', 7902, '02-MAR-1970', 8000, NULL, 2),
(7499, 'ALLEN', 'SALESMAN', 7698, '20-MAR-1971', 1600, 3000, 3),
(7521, 'WARD', 'SALESMAN', 7698, '07-FEB-1983', 1250, 5000, 3),
(7566, 'JONES', 'MANAGER', 7839, '02-JUN-1961', 2975, 50000, 2),
(7654, 'MARTIN', 'SALESMAN', 7698, '28-FEB-1971', 1250, 14000, 3),
(7698, 'BLAKE', 'MANAGER', 7839, '01-JAN-1988', 2850, 12000, 3),
(7782, 'CLARK', 'MANAGER', 7839, '09-APR-1971', 2450, 13000, 1),
(7788, 'SCOTT', 'ANALYST', 7566, '09-DEC-1982', 3000, 1200, 2),
(7839, 'KING', 'PRESIDENT', NULL, '17-JUL-1971', 5000, 1456, 1),
(7844, 'TURNER', 'SALESMAN', 7698, '08-AUG-1971', 1500, 0, 3),
(7876, 'ADAMS', 'CLERK', 7788, '12-MAR-1973', 1100, 0, 2),
(7900, 'JAMES', 'CLERK', 7698, '03-NOV-1971', 950, 0, 3),
(7902, 'FORD', 'ANALYST', 7566, '04-MAR-1961', 3000, 0, 2),
(7934, 'MILLER', 'CLERK', 7782, '21-JAN-1972', 1300, 0, 1)На приведенном ниже рисунке показаны сотрудники:
- сотрудник с EMPNO 7369 подчиняется 7902;
- сотрудник с EMPNO 7902 подчиняется 7566
- сотрудник с EMPNO 7566 подчиняется 7839
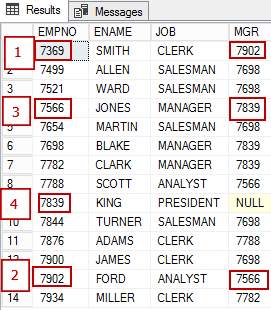
Теперь давайте посмотрим на представление тех же данных в виде графа. Вершина EMPLOYEE имеет несколько атрибутов и связана сама с собой связью «подчиняется» (EmplReportsTo). EmplReportsTo — это название связи.
В таблице ребер (EDGE) также могут присутствовать атрибуты.
Создадим таблицу узлов EmpNode
Синтаксис создания узла довольно прост: к выражению CREATE TABLE в конец добавляется «AS NODE».
CREATE TABLE dbo.EmpNode(
ID Int Identity(1,1),
EMPNO NUMERIC(4) NOT NULL,
ENAME VARCHAR(10),
MGR NUMERIC(4),
DNO INT
) AS NODE;Теперь преобразуем данные из обычной таблицы в графовую. Следующий INSERT вставляет данные из реляционной таблицы EMP.
INSERT INTO EmpNode(EMPNO,ENAME,MGR,DNO) select empno,ename,MGR,dno from emp 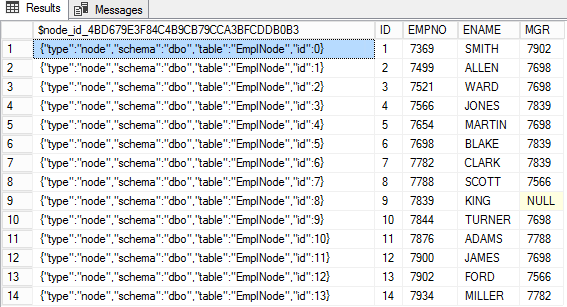
В таблице узлов в специальной колонке $node_id_* хранится идентификатор узла в виде JSON. В остальных столбцах этой таблицы находятся атрибуты узла.
Создаем ребра (EDGE)
Создание таблицы ребер очень похоже на создание таблицы узлов, за исключением того, что используется ключевое слово «AS EDGE».
CREATE TABLE empReportsTo(Deptno int) AS EDGE 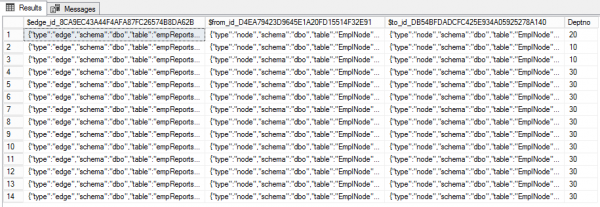
Теперь определим связи между сотрудниками, используя столбцы EMPNO и MGR. По диаграмме оргструктуры хорошо видно как написать INSERT.
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 1),
(SELECT $node_id FROM EmpNode WHERE id = 13),20);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 2),
(SELECT $node_id FROM EmpNode WHERE id = 6),10);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 3),
(SELECT $node_id FROM EmpNode WHERE id = 6),10)
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 4),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 5),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 6),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 7),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 8),
(SELECT $node_id FROM EmpNode WHERE id = 4),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 9),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 10),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 11),
(SELECT $node_id FROM EmpNode WHERE id = 8),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 12),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 13),
(SELECT $node_id FROM EmpNode WHERE id = 4),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 14),
(SELECT $node_id FROM EmpNode WHERE id = 7),30); Таблица ребер по умолчанию состоит из трех столбцов. Первый, $edge_id — идентификатор ребра в виде JSON. Два других ($from_id и $to_id) представляют связь между узлами. Кроме того, ребра могут иметь дополнительные свойства. В нашем случае это Deptno.
Системные представления
В системном представлении sys.tables появилось две новые колонки:
- is_edge
- is_node
SELECT t.is_edge,t.is_node,*
FROM sys.tables t
WHERE name like 'emp%' 
SSMS
Объекты, связанные с графами, располагаются в папке Graph Tables. Иконка таблицы узлов помечена точкой, а таблицы ребер — двумя связанными кругами (что немного похоже на очки).
Выражение MATCH
Выражение MATCH взято из CQL (Cypher Query Language). Это эффективный способ запроса к свойствам графа. CQL начинается с выражения MATCH.
Синтаксис
MATCH (<graph_search_pattern>)
<graph_search_pattern>::=
{<node_alias> {
{ <-( <edge_alias> )- }
| { -( <edge_alias> )-> }
<node_alias>
}
}
[ { AND } { ( <graph_search_pattern> ) } ]
[ ,...n ]
<node_alias> ::=
node_table_name | node_alias
<edge_alias> ::=
edge_table_name | edge_aliasПримеры
Давайте посмотрим на несколько примеров.
Приведенный ниже запрос отображает сотрудников, которым подчиняется Smith и его менеджер.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR
FROM
empnode e, empnode e1, empReportsTo m
WHERE
MATCH(e-(m)->e1)
and e.ENAME='SMITH' 
Следующий запрос предназначен для поиска сотрудников и менеджеров второго уровня для Smith. Если убрать предложение WHERE, то в результате будут отображаться все сотрудники.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR,E2.EMPNO,e2.ENAME,E2.MGR
FROM
empnode e, empnode e1, empReportsTo m ,empReportsTo m1, empnode e2
WHERE
MATCH(e-(m)->e1-(m1)->e2)
and e.ENAME='SMITH' 
И, наконец, запрос для сотрудников и менеджеров третьего уровня.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR,E2.EMPNO,e2.ENAME,E2.MGR,E3.EMPNO,e3.ENAME,E3.MGR
FROM
empnode e, empnode e1, empReportsTo m ,empReportsTo m1, empnode e2, empReportsTo M2, empnode e3
WHERE
MATCH(e-(m)->e1-(m1)->e2-(m2)->e3)
and e.ENAME='SMITH' 
Теперь давайте изменим направление, чтобы получить начальников Smith’а.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR,E2.EMPNO,e2.ENAME,E2.MGR,E3.EMPNO,e3.ENAME,E3.MGR
FROM
empnode e, empnode e1, empReportsTo m ,empReportsTo m1, empnode e2, empReportsTo M2, empnode e3
WHERE
MATCH(e<-(m)-e1<-(m1)-e2<-(m2)-e3) 
Заключение
SQL Server 2017 зарекомендовал себя как полноценное корпоративное решение для различных ИТ-задач бизнеса. Первая версия SQL Graph очень многообещающая. Даже несмотря на некоторые ограничения, уже сейчас есть достаточно функционала для изучения возможностей графов.
Функционал SQL Graph полностью интегрирован в SQL Engine. Однако, как уже было сказано, в SQL Server 2017 есть следующие ограничения:
Нет поддержки полиморфизма.
- Поддерживаются только однонаправленные связи.
- У ребер нельзя обновлять столбцы $from_id и $to_id через UPDATE.
- Не поддерживаются транзитивные замыкания (transitive closure), но их можно получить с помощью CTE.
- Ограничена поддержка объектов In-Memory OLTP.
- Не поддерживаются темпоральные таблицы (System-Versioned Temporal Table), временные локальные и глобальные таблицы.
- Табличные типы и табличные переменные не могут быть объявлены как NODE или EDGE.
- Не поддерживаются запросы между базами данных (cross-database queries).
- Нет прямого способа или какого-то мастера (wizard) для преобразования обычных таблиц в графовые.
- Для отображения графов нет GUI, но можно использовать Power BI.
Читать ещё:
Источник: habr.com
