

Логи — важная часть системы, позволяющая понять, что она работает (либо не работает), как ожидается. В условиях микросервисной архитектуры работа с логами становится отдельной дисциплиной специальной олимпиады. Нужно решить сразу кучу вопросов:
- как писать логи из приложения;
- куда писать логи;
- как доставлять логи для хранения и обработки;
- как обрабатывать и хранить логи.
Применение популярных ныне технологий контейнеризации добавляет песочка поверх граблей на поле вариантов решения задачи.
Как раз об этом расшифровка доклада Юрия Бушмелева «Карта граблей на поле сбора и доставки логов»
Кому интересно, прошу под кат.
Меня зовут Юрий Бушмелев. Я работаю в Lazada. Я сегодня буду рассказывать про то, как мы делали наши логи, как мы их собирали, и что мы туда пишем.

Откуда мы? Кто мы такие? Lazada — это интернет-магазин №1 в шести странах Юго-Восточной Азии. Все эти страны у нас распределены по дата-центрам. Всего дата-центров сейчас 4. Почему это важно? Потому что некоторые решения были обусловлены тем, что между центрами есть очень слабый линк. У нас микросервисная архитектура. Я удивился, обнаружив, что у нас уже 80 микросервисов. Когда я начинал задачу с логами, их было всего 20. Плюс есть довольно большой кусок PHP legacy, с которым тоже приходится жить и мириться. Все это генерирует нам на данный момент более 6 миллионов сообщений в минуту по системе в целом. Дальше я буду показывать, как мы с этим пытаемся жить, и почему это так.

С этими 6 миллионами сообщений надо как-то жить. Что мы с ними должны сделать? 6 миллионов сообщений, которые надо:
- отправить из приложения
- принять для доставки
- доставить для анализа и хранения.
- проанализировать
- как-то хранить.

Когда появилось три миллиона сообщений, у меня был примерно такой же вид. Потому что мы начинали с каких-то копеек. Понятно, что туда пишутся логи приложений. Например, не смог подключиться к базе данных, смог подключиться к базе данных, но не смог что-то прочитать. Но кроме этого, каждый наш микросервис пишет еще и access-лог. Каждый запрос, прилетевший на микросервис, падает в лог. Зачем мы это делаем? Разработчики хотят иметь возможность трейсинга. В каждом access-логе лежит поле traceid, по которому дальше специальный интерфейс раскручивает все цепочку и красиво показывает трейс. Трейс показывает, как проходил запрос, и это помогает нашим разработчикам быстрее справляться со всякой неопознанной фигней.

Как с этим жить? Сейчас я вкратце расскажу поле вариантов — как вообще эта проблема решается. Как решать задачу сбора, передачи и хранения логов.
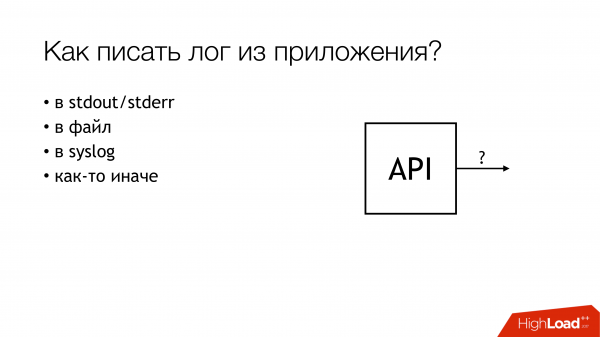
Как писать из приложения? Понятно, что есть разные способы. В частности, есть best practice, как нам рассказывают модные товарищи. Есть old school в двух видах, как рассказывали деды. Есть другие способы.
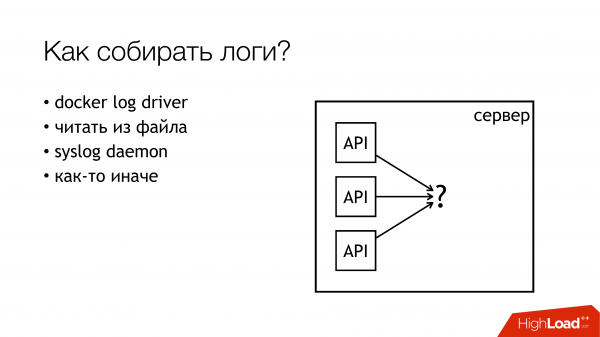
Со сбором логов примерно такая же ситуация. Вариантов решения этой конкретной части не так много. Их уже больше, но ещё не так много.
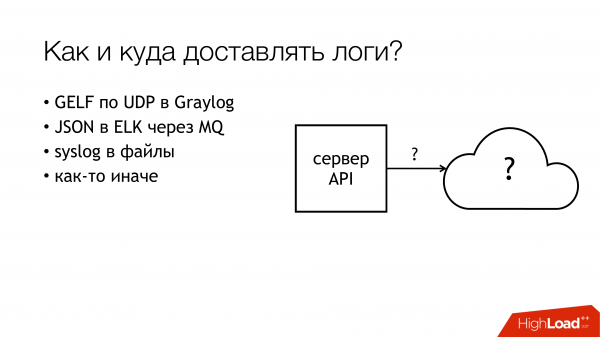
А вот с доставкой и последующим анализом — количество вариаций начинает взрываться. Описывать каждый вариант сейчас не буду. Думаю, основные варианты на слуху у всех, кто интересовался темой.

Я покажу, как мы делали это в Lazada, и как собственно все это начиналось.
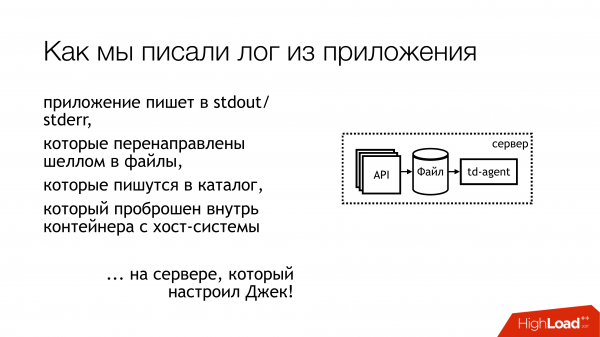
Год назад я пришёл в Лазаду, и меня отправили на проект про логи. Там было примерно вот так. Лог из приложения писался в stdout и stderr. Все сделали по-модному. Но дальше разработчики это выкинули из стандартных потоков, а дальше там как-нибудь специалисты по инфраструктуре разберутся. Между инфраструктурными специалистами и разработчиками есть еще релизеры, которые сказали: «эээ… ну ладно, давайте их в файл завернем просто shell-ом, и все». А поскольку все это в контейнере, то завернули прям в самом контейнере, промапили внутрь каталог и положили это туда. Думаю, что всем примерно очевидно, что из этого получилось.
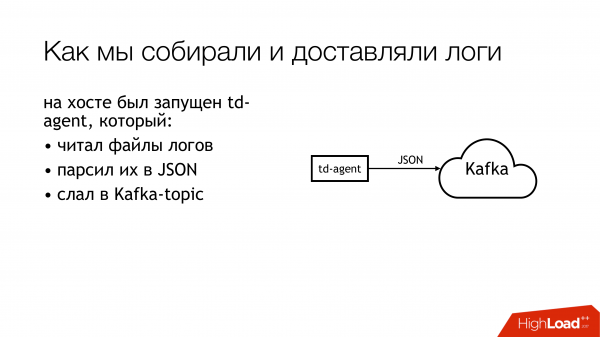
Посмотрим пока чуть подальше. Как мы эти логи доставляли. Кто-то выбрал td-agent, который на самом деле fluentd, но не совсем fluentd. Я так и не понял отношения этих двух проектов, но они, вроде бы, об одном и том же. И вот этот вот fluentd, написанный на Ruby, читал файлы логов, парсил их в JSON по каким-то регуляркам. Потом их отправлял в Kafka. Причем в Kafka на каждую API у нас было 4 отдельных топика. Почему 4? Потому что есть live, есть staging, и потому что есть stdout и stderr. Разработчики их плодят, а инфраструктурщики должны их создавать в Kafka. Причем, Kafka контролировалась другим отделом. Поэтому надо было создавать тикет, чтобы они создали там 4 топика на каждый api. Все про это забывали. В общем был треш и угар.
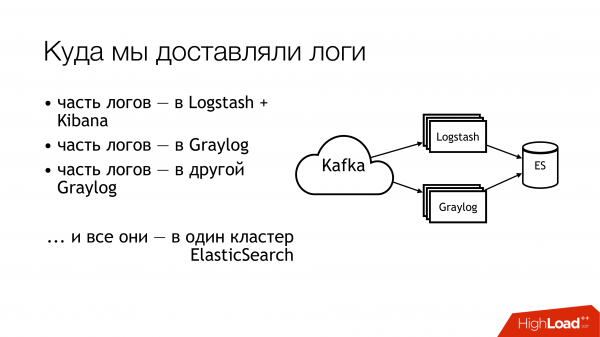
Что мы дальше с этим делали? Мы отправляли это в кафку. Дальше из кафки половина логов улетала в Logstash. Другая половина логов делилась. Часть улетала в один Graylog, часть – в другой Graylog. В итоге всё это улетало в один кластер Elasticsearch. То есть, весь этот бардак падал в итоге туда. Так делать не надо!
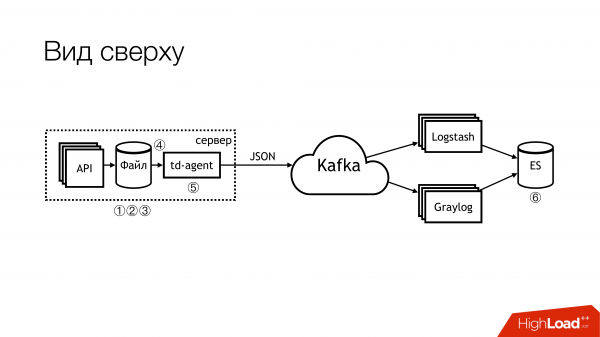
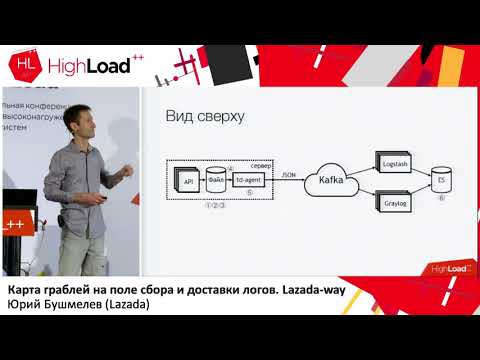
Вот так это выглядит, если отдаленно сверху посмотреть. Не надо так делать! Здесь вот цифрами сразу отмечены проблемные места. Их на самом деле больше, но 6 — это вот прям совсем проблемные, с которыми надо что то делать. Про них я сейчас отдельно расскажу.

Вот здесь (1,2,3) у нас пишутся файлы и, соответственно, здесь сразу три грабли.
Первое (1) — это нам надо их куда-то писать. Не всегда хотелось бы давать API возможность писать прямо в файл. Желательно, чтобы API была изолирована в контейнере, а еще лучше – чтобы она была read-only. Я — сисадмин, поэтому у меня немного альтернативный взгляд на эти вещи.
Второй момент (2,3) — у нас много запросов приходит в API. API пишет много данных в файл. Файлы растут. Нам их надо ротировать. Потому что иначе там никаких дисков не напасешься. Ротировать их плохо, потому что они сделаны редиректом через shell в каталог. Мы никак не можем его отротировать. Нельзя сказать приложению, чтобы оно переоткрыло дескрипторы. Потому что разработчики на тебя посмотрят как на дурака: «Какие дескрипторы? Мы вообще в stdout пишем». Инфраструктурщики сделали copytruncate в logrotate, который делает просто копию файла и транкейтит оригинал. Соответственно, между этими процессами копирования обычно и кончается место на диске.
(4) У нас были разные форматы были в разных API. Они немножко отличались, но regexp надо было писать разные. Поскольку всё это управлялось Puppet, то там была большая вязанка классов со своими тараканами. Плюс еще td-agent большую часть времени мог есть память, тупить, он мог просто делать вид, что он работает, и ничего не делать. Снаружи понять, что он ничего не делает было невозможно. В лучшем случае он упадет, и его кто-нибудь поднимет потом. Точнее, прилетит alert, и кто-нибудь пойдет руками переподнимет.

(6) И самый трэш и угар — это был elasticsearch. Потому что, это была старая версия. Потому что, у нас не было выделенных мастеров на тот момент. У нас были разнородные логи, у которых поля могли пересекаться. Разные логи разных приложений могли писаться с одинаковыми названиями полей, но при этом внутри могли быть разные данные. То есть, один лог приходит с Integer в поле, например, level. Другой лог приходит со String в поле level. В отсутствие статического маппинга получается такая замечательная вещь. Если после ротации индекса в elasticsearch первым прилетело сообщение со строкой, то мы живем нормально. А если вот первым прилетело с Integer, то все последующие сообщения, которые прилетели со String, просто отбрасываются. Потому что не совпадает тип поля.

Мы начали задаваться вот этими вопросами. Мы решили не искать виноватых.

А вот что-то делать надо! Очевидная вещь — надо завести стандарты. Некоторые стандарты у нас уже были. Некоторые мы завели чуть позже. К счастью, единый формат логов для всех API уже утвердили на тот момент. Он прописан прямо в стандарты взаимодействия сервисов. Соответственно, те, кто хочет получать логи, должны писать их в этом формате. Если кто-то не пишет логи в этом формате, значит, мы ничего не гарантируем.
Далее, хотелось бы завести единый стандарт на способы записи, доставки и сбора логов. Собственно, куда их писать, и чем их доставлять. Идеальная ситуация — это когда в проектах используется одна и та же библиотека. Вот есть отдельная библиотека логирования для Go, есть отдельный библиотека для PHP. Все кто у нас есть — все должны их использовать. На данный момент я бы сказал, что процентов на 80 у нас это получается. Но некоторые продолжают есть кактусы.
И вот там вот (на слайде) еле-еле начинает проступать «SLA на доставку логов». Его пока нет, но мы над этим работаем. Потому что это очень удобно, когда инфра говорит, что если вы пишете в таком-то формате в такое-то место и не более N сообщений в секунду, то мы это с вероятностью такой-то доставим туда-то. Это снимает кучу головной боли. Если SLA есть, то это прямо замечательно!

Как мы начали решать проблему? Основная грабля была с td-agent. Было непонятно, куда у нас деваются логи. Доставляются ли они? Собираются ли они? Где они вообще? Поэтому, первым пунктом было решено заменить td-agent. Варианты, на что его заменить, вкратце я здесь набросал.
Fluentd. Во-первых, я с ним сталкивался на предыдущей работе, и он там тоже периодически падал. Во-вторых, это тоже самое, только в профиль.
Filebeat. Чем он был удобен для нас? Тем, что он на Go, а у нас большая экспертиза в Go. Cоответственно, если что, мы могли его под себя как-то дописать. Поэтому мы его и не взяли. Чтобы даже соблазна никакого не было начинать его под себя переписывать.
Очевидным решением для сисадмина остаются всякие сислоги вот в таком вот количестве (syslog-ng/rsyslog/nxlog).
Либо написать что-то свое, но мы это отбросили, равно как и filebeat. Если что-то писать, то лучше писать что-то полезное для бизнеса. Для доставки логов лучше взять что-то готовое.
Поэтому выбор фактически свелся к выбору между syslog-ng и rsyslog. Cклонился в сторону rsyslog просто потому, что у нас в Puppet уже были классы для rsyslog, и я не нашел между ними очевидной разницы. Что там syslog, что тут syslog. Да, у кого-то документация хуже, у кого-то лучше. Тот умеет так, а тот — по-другому.

И немножко про rsyslog. Во-первых, он клёвый, потому что у него есть много модулей. У него человеко-понятный RainerScript (современный язык конфигурации). Офигенный бонус, что мы могли его штатными средствами сэмулировать поведение td-agent, и для приложений ничего не поменялось. То есть, мы меняем td-agent на rsyslog, а все остальнок пока не трогаем. И сразу получаем работающую доставку. Далее, mmnormalize — это офигенная штука в rsyslog. Она позволяет парсить логи, но не с помощью Grok и regexp. Она делает abstract syntax tree. Она парсит логи примерно, как компилятор парсит исходники. Это позволяет работать очень быстро, жрать мало CPU, и, вообще, прям очень клёвая штука. Есть куча других бонусов. Я о них не буду останавливаться.

У rsyslog есть ещё куча недостатков. Они примерно такие же, как и бонусы. Основные проблемы — надо уметь его готовить, и надо подбирать версию.
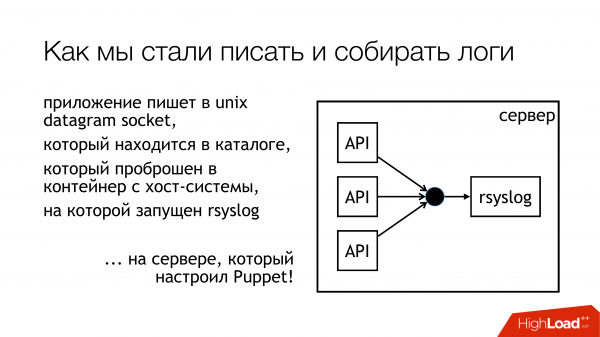
Мы решили что будем писать логи в unix socket. Причем не в /dev/log, потому что там у нас каша из системных логов, там journald в этом pipeline. Поэтому давайте писать в кастомный сокет. Мы его прицепим к отдельному ruleset. Не будем ничего мешать. Будет все прозрачно и понятно. Так мы собственно и сделали. Каталог с этими сокетами стандартизирован и пробрасывается во все контейнеры. Контейнеры могут видеть нужный им socket, открывать и писать него.
Почему не файл? Потому что все читали , которая пыталась пробросить файл в docker, и обнаруживалось, что после рестарта rsyslog меняется file descriptor, и docker теряет этот файл. Он держит открытым что-то другое, но уже не тот сокет куда пишут. Мы решили, что мы обойдем эту проблему, и, заодно, обойдем проблему блокировки.
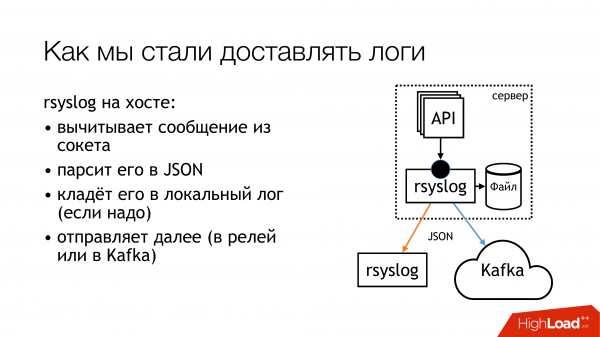
Rsyslog делает действия указанные на слайде и отправляет логи либо в релей, либо в Kafka. Kafka соответствует старому способу. Релей — это я попытался использовать чисто rsyslog для доставки логов. Без Message Queue, стандартными средствами rsyslog. В принципе, это работает.
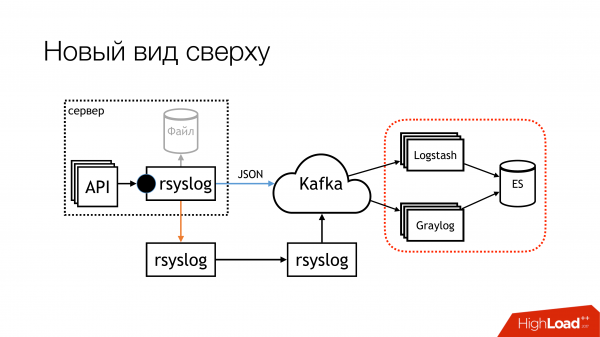
Но есть нюансы с тем, как запихивать их потом в эту часть (Logstash/Graylog/ES). Эта часть (rsyslog-rsyslog) используется между датацентрами. Здесь compressed tcp link, который позволяет сэкономить bandwidth и, соответственно, как-то увеличить вероятность того, что мы получим какие-то логи из другого датацентра в условиях, когда канал забит. Потому что, нас есть Индонезия, в которой все плохо. Вот там эта постоянная проблема.

Мы задумались над тем как нам собственно промониторить, с какой вероятностью логи, которые мы записали из приложения, доезжают до того конца? Мы решили завести метрики. У rsyslog есть свой модуль сбора статистики, в котором есть какие-то счетчики. Например, он может показать вам размер очереди, или сколько сообщений пришло в такой-то action. Из них уже можно что-то взять. Плюс, у него есть кастомные счетчики, которые можно настроить, и он будет вам показывать, например, количество сообщений, который записало какое-то API. Далее, я написал rsyslog_exporter на Python, и мы все это отправили в Prometheus и построили графики. Метрики Graylog очень хотелось, но пока мы не успели их настроить.

С чем возникли проблемы? Проблемы возникли с тем, что у нас обнаружилось (ВНЕЗАПНО!), что наши Live API пишут по 50к сообщений в секунду. Это только Live API без staging. А Graylog нам показывает только 12 тысяч сообщений в секунду. И возник резонный вопрос, а где остатки-то? Из чего мы сделали вывод, что Graylog просто не справляется. Посмотрели, и, действительно, Graylog с Elasticsearch не осиливали этот поток.
Далее, другие открытия, которые мы сделали в процессе.
Запись в socket блокируются. Как это случилось? Когда я использовал rsyslog для доставки, в какой-то момент у нас сломался канал между датацентрами. Встала доставка в одном месте, встала доставка другом месте. Все это докатилась до машины с API, которые пишут в сокет rsyslog. Там заполнилась очередь. Потом заполнилась очередь на запись в unix socket, которая по умолчанию 128 пакетов. И следующий write() в приложении блокируется. Когда мы смотрели в библиотечку, которой пользуемся в приложениях на Go, там было написано, что запись в сокет происходит в неблокирующемся режиме. Мы были уверенны что ничего не блокируется. Потому что мы читали , которая про это написала. Но есть момент. Вокруг этого вызова был еще бесконечный цикл, в котором постоянно происходила попытка запихать сообщение в сокет. Вот его мы не заметили. Пришлось переписать библиотеку. С тех пор она несколько раз менялась, но сейчас мы избавились от блокировок во всех подсистемах. Поэтому, можно останавливать rsyslog, и ничего не упадет.
Нужно мониторить размер очередей, что помогает не наступить на эти грабли. Во-первых, мы можем мониторить, когда мы начинаем терять сообщения. Во-вторых, можем мониторить что у нас в принципе проблемы с доставкой.
И еще неприятный момент — амплификация в 10 раз в микросервисной архитектуре — это очень легко. У нас входящих запросов не так много, но из-за графа, по которому бегают эти сообщения дальше, из-за access-логов, мы реально увеличиваем нагрузку по логам примерно раз в десять. Я к сожалению не успел посчитать точные цифры, но микросервисы — они такие. Это надо иметь в виду. Получается, что на данный момент подсистема сбора логов — самая нагруженная в Lazada.

Как решить проблему elasticsearch? Если надо быстро получить логи в одном месте, чтобы не бегать по всем машинам, и не собирать их там, используйте файловое хранилище. Это гарантированно работает. Оно делается из любого сервера. Надо просто натыкать туда дисков и поставить syslog. После этого у вас гарантированно в одном месте все логи есть. Дальше уже можно будет неспешно настраивать elasticsearch, graylog, что-нибудь еще. Но у вас уже будут все логи, и, причем, вы их можете хранить, насколько хватает дисковых массивов.
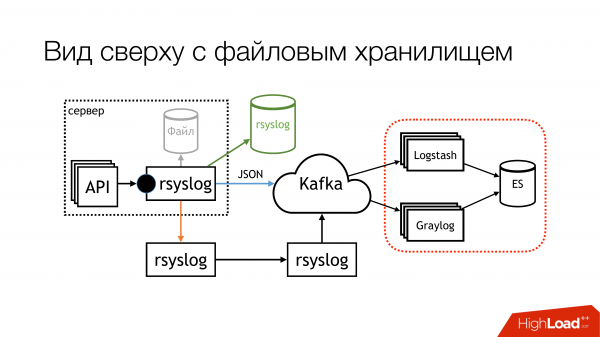
На момент моего доклада схема стала выглядеть вот так. В файл мы практически перестали писать. Сейчас, скорее всего, отлючим остатки. На локальных машинах, на которых запущены API, в файлы мы писать перестанем. Во-первых, есть файловое хранилище, которое работает очень хорошо. Во-вторых, на этих машинах постоянно кончается место, надо его постоянно мониторить.
Вот эта часть с Logstash и Graylog, она реально парит. Поэтому надо от нее избавиться. Надо выбрать что-то одно.

Мы решили выкинуть Logstash и Kibana. Потому что у нас есть отдел безопасности. Какая связь? Связь в том что Kibana без X-Pack и без Shield не позволяет разграничить права доступа к логам. Поэтому взяли Graylog. В нем все это есть. Он мне не нравится, но он работает. Мы купили нового железа, поставили там свежий Graylog и перенесли все логи со строгими форматами в отдельный Graylog. Мы решили проблему с разными типами одинаковых полей организационно.

Что собственно в новый Graylog входит. Мы просто записали все в докер. Взяли кучу серверов, раскатали три инстанса Kafka, 7 серверов Graylog версии 2.3 (потому что хотелось Elasticsearch версии 5). Все это на рейдах из HDD подняли. Увидели indexing rate до 100 тысяч сообщений в секунду. Увидели цифру что 140 терабайт данных в неделю.

И опять грабли! У нас грядут две распродажи. Мы переехали за 6 миллионов сообщений. У нас Graylog не успевает прожевывать. Как-то надо опять выживать.

Выжили мы вот так. Добавили еще немножко серверов и SSD. На данный момент мы живем вот таким способом. Сейчас мы прожёвываем уже 160к сообщений в секунду. Мы еще не уперлись в лимит, поэтому пока непонятно, сколько мы реально сможем вытянуть из этого.

Вот такие у нас планы на будущее. Из них, реально, самое важное, наверное, high availability. У нас его пока нет. Несколько машин настроены одинаково, но едет пока все через одну машину. Надо потратить время, чтобы настроить failover между ними.
Собрать метрики с Graylog.
Сделать rate limit чтобы у нас одна, сошедшая с ума API, не убивала нам bandwidth и все остальное.
И наконец, подписать какой-то SLA c разработчиками, что мы можем обслужить вот столько. Если вы пишете больше, то извините.
И написать документацию.

Кратенько, итоги всего, что мы пережили. Во-первых, стандарты. Во-вторых, syslog — торт. В-третьих, rsyslog работает именно вот так, как написано на слайде. И давайте перейдем к вопросам.
Вопросы.
Вопрос: Почему все-таки решили не брать… (filebeat?)
Ответ: Надо писать в файл. Очень не хотелось. Когда у тебя API пишет тысячи сообщений в секунду, ты даже если раз в час будешь ротировать, то это все равно не вариант. Можно писать в pipe. На что меня разработчики спросили: «А что будет если, процесс в который мы пишем, упадет»? Я просто не нашел, что им ответить, и сказал: «Ну ок, давайте мы не будем так делать».
Вопрос: Почему вы не пишете логи просто в HDFS?
Ответ: Это следующий этап. Мы про него подумали самом начале, но, поскольку, в данный момент нет ресурсов этим заниматься, то он у нас висит в long term solution.
Вопрос: Колоночный формат был бы более подходящий.
Ответ: Я все понимаю. Мы «за» обеими руками.
Вопрос: Вы пишите в rsyslog. Там можно и TCP, и UDP. Но если UDP, то тогда как вы гарантируете доставку?
Ответ: Есть два момента. Первый, я сразу всем говорю, что мы не гарантируем доставку логов. Потому что, когда разработчики приходят и говорят: «А давайте мы туда начнем писать финансовые данные, а вы будете их нам куда-то складывать на случай, если что-то случится», мы им отвечаем «Отлично! Давайте вы начнете блокироваться на записи в сокет, и делать это в транзакциях, чтобы гарантированно вы нам это в сокет положили и убедились, что мы с той стороны это получили.» И в этот момент всем сразу становится не надо. А раз не надо, то какие к нам вопросы? Если вы не хотите гарантировать запись в сокет, то зачем нам гарантировать доставку? Мы делаем best effort. Мы реально стараемся доставить как можно больше и как можно лучше, но мы не даем 100% гарантии. Поэтому не надо писать туда финансовые данные. Для этого есть базы данных с транзакциями.
Вопрос: Когда API генерирует какое-то сообщение в лог и передает управление микросервисам, то не сталкивались ли вы с проблемой, что сообщения от разных микросервисов приходят в неправильном порядке? Из-за этого возникает путаница.
Ответ: Это нормально, что они приходят в разном порядке. К этому надо быть готовым. Потому что любая сетевая доставка вам не гарантирует порядок, или надо тратить специально ресурсы на это. Если возьмем файловые хранилища, то каждая API сохраняет логи в свой файл. Вернее там rsyslog раскладывается их по каталогам. У каждого API там есть свои логи, куда можно пойти и посмотреть, и потом по timestamp в этом логе можно их посопоставлять. Если они идут смотреть в Graylog, то там они отсортируется по timestamp. Там всё будет хорошо.
Вопрос: Timestamp может отличаться на миллисекунды.
Ответ: Timestamp генерит сама API. В этом, собственно, вся фишка. У нас есть NTP. API генерит timestamp уже в самом сообщении. Его не rsyslog добавляет.
Вопрос: Не очень понятно взаимодействие между датацентрами. В рамках датацентра понятно как логи собрали, обработали. Как проиходит взаимодействие между датацентрами? Или каждый датацентр живет своей жизнью?
Ответ: Почти. У нас каждая страна находится в каком-то одном датацентре. У нас нет на данный момент размазывания, чтобы одна страна была размещена по разным датацентрам. Поэтому не надо их объединять. Внутри каждого центра есть Log Relay. Это Rsyslog сервер. На самом деле две менеджмент машины. Они одинаково настроены. Но пока просто трафик идет через одну из них. Она логи все агрегирует. У нее есть дисковая очередь на всякий случай. Она жмет логи, и отправляет их в центральный датацентр (сингапурский), где дальше они уже отравляются в Graylog. И в каждом датацентре есть свой файловый storage. В случае, если у нас пропала связь, мы имеем все логи там. Они там останутся. Они там будут сохранены.
Вопрос: При нештатных ситациях оттуда вы получаете логи?
Ответ: Можно пойти туда (в файловое хранилище) и посмотреть.
Вопрос: Как вы мониторите то, что вы не теряете логи?
Ответ: Мы их теряем на самом деле, и мы это мониторим. Мониторинг запустили месяц назад. В библиотеке, которую используют Go API, есть метрики. Она умеет считать, сколько раз она не смогла записать в socket. Там на данный момент есть хитрая эвристика. Там есть буфер. Он пытается записывать из него сообщение в socket. Если буфер переполнится, он начинает их дропать. И считает сколько он их подроппал. Если там начинает переполняться счетчики, мы об этом узнаем. Они сейчас приезжают также в prometheus, и в Grafana можно посмотреть графики. Можно настроить оповещения. Но пока непонятно, кому их отправлять.
Вопрос: В elasticsearch вы с резервированием храните логи. Сколько у вас реплик?
Ответ: Одна реплика.
Вопрос: Это всего одна реплика?
Ответ: Это мастер и реплика. В двух экземплярах данные хранятся.
Вопрос: Размер буфера rsyslog вы как-то подкручивали?
Ответ: Мы пишем дейтаграммы в кастомный unix socket. Это нам сразу же накладывает ограничение 128 килобайт. Мы не можем записать в него больше. Мы прописали это в стандарт. Кто хочет попадать в стореджи, те пишут 128 килобайт. Библиотеки, причем, обрезают, и ставят флаг, что сообщение обрезано. У нас стандарте самого сообщения есть специальные поле, которое показывает было ли оно обрезано при записи или нет. Так что мы имеем возможность отследить и этот момент.
Вопроc: Пишете ли вы битые JSON?
Ответ: Битый JSON будет отброшен либо во время relay, потому что слишком большой пакет. Либо будет отброшен Graylog, потому что не сможет JSON распарсить. Но здесь есть нюансы, которые надо фиксить, и они большей частью завязаны на rsyslog. Я уже заполнил туда несколько issue, над которыми надо еще работать.
Вопроc: Почему Kafka? Пробовали ли RabbitMQ? Не складывается Graylog при таких нагрузках?
Ответ: У нас с Graylog не складывается. А Graylog у нас складывается. С ним реально проблемно. Он своеобразная штука. И, на самом деле, он не нужен. Я бы предпочел писать из rsyslog напрямую в elasticsearch и смотреть потом Kibana. Но надо утрясти вопрос с безопасниками. Это возможный вариант нашего развития, когда мы выкинем Graylog и будем использовать Kibana. Logstash использовать смысла не будет. Потому что, я могу все это же самое сделать rsyslog. И у него есть модуль для записи в elasticsearch. С Graylog мы пытаемся как-то жить. Мы его даже немножко потюнили. Но там есть еще пространство для улучшений.
Насчет Kafka. Так исторически сложилось. Когда я пришел, она уже была, и в нее уже писали логи. Мы просто подняли наш кластер и переехали в него логами. Мы его менеджим, мы знаем, как он себя чувствует. Насчет RabbitMQ… у нас не складывается c RabbitMQ. А RabbitMQ у нас складывается. У нас продакшне он есть, и с ним были проблемы. Сейчас бы перед распродажей его зашаманили, и он стал нормально работать. Но до этого я был не готов его выпускать в продакшн. Есть еще один момент. Graylog умеет читать версию AMQP 0.9, а rsyslog умеет писать версию AMQP 1.0. И нет ни одного решения, которое посередине умеет и то, и другое. Есть либо то либо другое. Поэтому на данный момент только Kafka. Но там тоже свои нюансы. Потому что omkafka той версии rsyslog, которой мы используем, может потерять вот весь буфер сообщений, которое она выгребла из rsyslog. Пока мы с этим миримся.
Вопроc: Вы используете Kafka потому, что она у вас в была? Больше ни для каких целей не используется?
Ответ: Kafka, которая была, используется командой Data Sсience. Это совсем отдельный проект, про который я, к сожалению, ничего сказать не могу. Я не в курсе. Она была в ведении команды Data Sсience. Когда логи заводили решили использовать ее, чтобы не ставить еще и свою. Сейчас мы обновили Graylog, и у нас потерялась совместимость, потому что там старая версия Kafka. Нам пришлось завести свою. Заодно мы избавились от этих четырех топиков на каждый API. Мы сделали один широкий топик на все live, один широкий широкий топик на все staging и просто все туда пуляем. Graylog все это параллельно выгребает.
Вопроc: Зачем нужно вот это шаманство с сокетами? Пробовали ли использовать log-драйвер syslog для контейнеров.
Ответ: На тот момент когда мы этим вопросом задавались, с докером у нас отношения были напряженные. Это был docker 1.0 или 0.9. Docker сам по себе был странный. Во-вторых, если в него еще и логи пихать… У меня есть непроверенное подозрение, что он пропускает все логи через себя, через демон докера. Если у нас одно API сходит с ума, то остальные API утыкаются в то, что они не могут отправить stdout и stderr. Я не знаю к чему это приведет. У меня есть подозрение на уровне ощущения, что не надо syslog-драйвер докера вот в этом месте использовать. У нашего отдела функционального тестирование есть свой собственный кластерочек Graylog с логами. Они используют log-драйверы докера и у них там вроде бы даже все хорошо. Но они GELF сразу пишут в Graylog. Мы на тот момент, когда все это затевали, нам надо было чтобы оно просто работало. Возможно потом, когда кто-то придет и скажет, что оно уже сто лет работает нормально, мы попробуем.
Вопроc: Вы доставку между датацентрами делаете на rsyslog. Почему не на Kafka?
Ответ: Мы делаем и так, и так на самом деле. По двум причинам. Если канал совсем убитый, то у нас все логи даже в сжатом виде не пролазят него. А кафка позволяет их просто терять в процессе. Мы этим способом избавляемся от залипания вот этих логов. Мы просто используем Kafka в этом случае напрямую. Eсли у нас канал хороший и хочется освободить его, то мы используем их rsyslog. Но на самом деле можно его настроить его так, чтобы он сам дропал то, что не пролезло. На данный момент мы просто где-то используем доставку rsyslog напрямую, где-то Kafka.
Источник: habr.com
