

Рассказываю из личного опыта, что где и когда пригодилось. Обзорно и тезисно, чтобы понятно было, что и куда можно копать дальше — но тут у меня исключительно субъективный личный опыт, у вас, может быть, все совсем по-другому.
Почему важно знать и уметь обращаться с языками запросов? По своей сути в Data Science есть несколько важнейших этапов работы и самый первый и важнейший (без него уж точно ничего работать не будет!) — это получение или извлечение данных. Чаще всего данные в каком-то виде где-то сидят и их нужно оттуда «достать».
Языки запросов как раз и позволяют эти самые данные извлечь! И сегодня я расскажу, о тех языках запросов, которые мне пригодились и расскажу-покажу, где и как именно — зачем оно нужно для изучения.
Всего будет три основных блока типов запросов к данным, которые мы разберем в данной статье:
- «Стандартные» языки запросов — то, что обычно понимают, когда говорят о языке запросов, как, например, реляционная алгебра или SQL.
- Скриптовые языки запросов: например, питоновские штучки pandas, numpy или shell scripting.
- Языки запросов к графам знаний и графовым базам данных.
Все написанное здесь — это просто персональный опыт, что пригодилось, с описанием ситуаций и «зачем оно было нужно» — каждый может примерить, насколько подобные ситуации могут встретиться вам и попробовать подготовиться к ним заранее, разобравшись с этими языками до того, как придется их в (срочном порядке) применять на проекте или вообще попасть на проект, где они нужны.
«Стандартные» языки запросов
Стандартные языки запросов именно в том плане, что обычно мы именно о них и думаем, когда говорим про запросы.
Реляционная алгебра
Зачем сегодня нужна реляционная алгебра? Для того чтобы иметь хорошее представление, почему языки запросов устроены определенным образом и осознанно их использовать нужно разобраться с ядром, лежащим в основе.
Что такое реляционная алгебра?
Формальное определение такое: реляционная алгебра — замкнутая система операций над отношениями в реляционной модели данных. Если чуть более по-человечески, это система операций над таблицами, такая что результатом тоже всегда является таблица.
См. все реляционные операции в статье с Хабра — здесь же мы описываем, зачем нужно знать и где пригождается.
Зачем?
Начинаешь понимать, на что вообще складываются языки запросов и какие операции стоят за выражениями конкретных языков запросов — часто дает более глубокое понимание того, что и как работает в языках запросов.
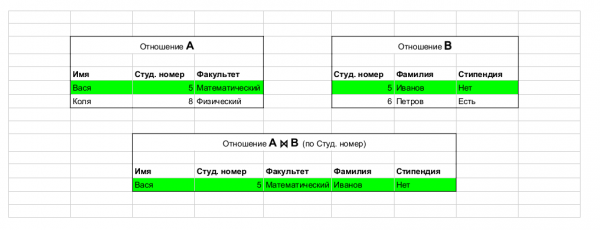
Взято из статьи. Пример операции: join, который объединяет таблицы.
Материалы для изучения:
. Вообще, материалов по реляционной алгебре и теории очень много — Сoursera, Udacity. Есть также огромное количество материалов онлайн, в том числе хороших . Мой персональный совет: надо понимать реляционную алгебру очень хорошо — это основа основ.
SQL

Взято из статьи.
SQL — это, по сути, имплементация реляционной алгебры — с важной оговоркой, SQL — декларативен! То есть записывая запрос на языке реляционной алгебры, вы фактически говорите, как нужно считать — а вот с SQL вы задаете, что хотите извлечь, а дальше СУБД уже генерирует (эффективное) выражения на языке реляционной алгебры (их эквивалентность известна нам под ).
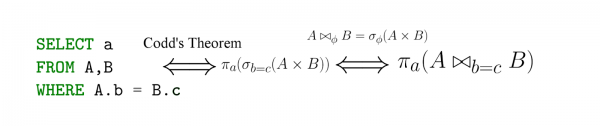
Взято из статьи.
Зачем?
Реляционные СУБД: Oracle, Postgres, SQL Server, etc — по-прежнему фактически повсюду и невероятно велик шанс того, что вам придется с ними взаимодействовать, а это означает, что придется либо читать SQL (что очень вероятно), либо писать на нем (тоже не маловероятно).
Что читать и изучать
По тем же ссылкам выше (про реляционную алгебру), есть невероятное количество материала, например, .
Кстати, а что такое NoSQL?
«Стоит еще раз подчеркнуть, что термин «NoSQL» имеет абсолютно стихийное происхождение и не имеет общепризнанного определения или научного учреждения за спиной.» Соответствующая на Хабре.
По сути, люди поняли, что полная реляционная модель не нужна для решения многих задач, особенно для тех, где, например, принципиальна производительность и доминируют определенные простые запросы с агрегацией — там критично быстро считать метрики и писать их в базу, а большинство фич реляционной оказались не только не нужны, но и вредны — зачем нормализовывать что-то, если это будет портить самое важное для нас (для некоторой конкретной задачи) — производительность?
Также часто нужные гибкие схемы вместо фиксированных математических схем классической реляционной модели — и это невероятно упрощает разработку приложений, когда критично развернуть систему и начать работать быстро, обрабатывая результаты — или схема и типы хранимых данных не так уж и важны.
Например, мы создаем экспертную систему и хотим хранить информацию по определенному домену вместе с некоторой метаинформацией — мы можем и не знать всех полей и банально хранить JSON для каждой записи — это дает нам очень гибкую среду для расширения модели данных и быстрого итерирования — поэтому в таком случае NoSQL будет даже предпочтительнее и читаемее. Пример записи (из одного моего проекта, где NoSQL был прям там, где нужно).
{"en_wikipedia_url":"https://en.wikipedia.org/wiki/Johnny_Cash",
"ru_wikipedia_url":"https://ru.wikipedia.org/wiki/?curid=301643",
"ru_wiki_pagecount":149616,
"entity":[42775,"Джонни Кэш","ru"],
"en_wiki_pagecount":2338861}
Подробнее можно прочитать про NoSQL.
Что изучать?
Тут скорее нужно быть просто хорошо проанализировать свою задачу, какие у нее свойства и какие имеются NoSQL системы, который бы подходили под это описание — и уже заниматься изучением данной системы.
Скриптовые языки запросов
Сначала, кажется, причем тут вообще Python — это язык программирования, а не про запросы вовсе.

- Pandas — это прям швейцарский нож Data Science, огромное количество трансформации данных, агрегации и тд происходит в нем.
- Numpy — векторные вычисления, матрицы и линейная алгебра там.
- Scipy — много математики в пакете этом, особенно статы.
- Jupyter lab — много exploratory data analysis хорошо вписывается в ноутбуки — полезно уметь.
- Requests — работа с сетью.
- Pyspark — очень популярны среди инженеров данных, скорее всего, вам придется взаимодействовать с этой либо и спарком, просто в силу их популярности.
- *Selenium — очень полезен для сбора данных сайтов и ресурсов, иногда просто по-другому данные никак не получить.
Мой главный совет: учите Python!
Pandas
Возьмем в качестве примера следующий код:
import pandas as pd
df = pd.read_csv(“data/dataset.csv”)
# Calculate and rename aggregations
all_together = (df[df[‘trip_type’] == “return”]
.groupby(['start_station_name','end_station_name'])
.agg({'trip_duration_seconds': [np.size, np.mean, np.min, np.max]})
.rename(columns={'size': 'num_trips',
'mean': 'avg_duration_seconds',
'amin': min_duration_seconds',
‘amax': 'max_duration_seconds'}))По сути, мы видим, что код вписывается в классический SQL паттерн.
SELECT start_station_name, end_station_name, count(trip_duration_seconds) as size, …..
FROM dataset
WHERE trip_type = ‘return’
GROUPBY start_station_name, end_station_nameНо важная часть — этот код является часть скрипта и пайплайна, фактически мы встраиваем запросы в Питоновский пайплайн. В данной ситуации язык запросов к нам приходит из библиотек, таких как Pandas или pySpark.
В целом в pySpark мы видим схожий тип трансформации данных через язык запросов в духе:
df.filter(df.trip_type = “return”)
.groupby(“day”)
.agg({duration: 'mean'})
.sort()Где и что почитать
По самому питону вообще найти материалы для изучения. В сети огромное количество тьюториалов по , и курсов по (а также по самому ). В целом тут материалы великолепно гуглятся и если бы мне нужно было выбрать один пакет, на котором стоит сфокусироваться — то это был бы pandas, конечно. По связке DS+Python материалов тоже .
Shell как язык запросов
Немало проектов по обработке и анализу данных, с которыми мне приходилось работать — это, по сути, shell скрипты, которые вызывают код на питоне, на java и собственно сами shell команды. Поэтому в целом можно рассматривать пайплайны в баше/zsh/etc, как некоторый высокоуровневый запрос (можно туда, конечно, и циклы запихать, но это нетипично для DS кода на шелл языках), приведем простой пример — мне нужно было сделать маппинг QID викидаты и полной ссылки на русскую и английскую вики, для этого я написал простой запрос из команд в баше и для вывода написал простой скприт на питоне, которые я собрал вместе вот так:
pv “data/latest-all.json.gz” |
unpigz -c |
jq --stream $JQ_QUERY |
python3 scripts/post_process.py "output.csv"
где
JQ_QUERY = 'select((.[0][1] == "sitelinks" and (.[0][2]=="enwiki" or .[0][2] =="ruwiki") and .[0][3] =="title") or .[0][1] == "id")' Это был, по сути, весь пайплайн, который создавал нужный mapping, как мы видим все, работало в режиме потока:
- pv filepath — дает прогресс бар на основе размера файла и передает его содержимое дальше
- unpigz -c читал часть архива и отдавал jq
- jq с ключом — stream сразу выдавал результат и передавал его постпроцессору (так же как и с самым первым примером) на питоне
- внутри постпроцессор — это простая машина состояний, которая форматировала вывод
Итого сложный пайплайн работающий в режиме потока на больших данных (0.5TB), без существенных ресурсов и сделан из простого пайплайна и пары тулзов.
Еще один важный совет: умейте хорошо и эффективно работать в терминале и писать на bash/zsh/etc.
Где пригодится? Да почти везде — материалов для изучения опять же ОЧЕНЬ много в сети. В частности, вот моя предыдущая статья.
R scripting
Опять же читатель может воскликнуть — ну это же целый язык программирования! И конечно же, будет прав. Однако, обычно мне приходилось сталкиваться с R всегда в таком контексте, что, по сути, это было очень похоже на язык запросов.
R — это среда статистических вычислений и язык статических вычислений и визуализации (согласно ).
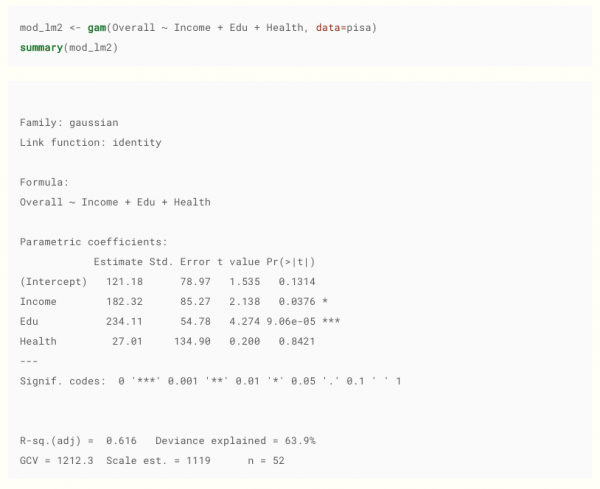
Взято . Кстати, рекомендую, неплохой материал.
Зачем дата саентисту знать R? По крайней мере, потому что есть огромный пласт людей не из IT, которые занимаются анализом данных на R. Мне встречалось в следующих местах:
- Фармацевтический сектор.
- Биологи.
- Финансовый сектор.
- Люди с чисто математическим образованием, занимающихся статами.
- Специализированные статистические модели и модели машинного обучения (которые часто можно найти только в авторской версии в виде R пакета).
Почему это фактически язык запросов? В том виде, в котором он часто встречается — это фактически запрос на создание модели, включая чтение данных и фиксирование параметров запроса (модели), а также визуализация данных в таких пакетах как ggplot2 — это тоже форма написания запросов.
Пример запросов для визуализации
ggplot(data = beav,
aes(x = id, y = temp,
group = activ, color = activ)) +
geom_line() +
geom_point() +
scale_color_manual(values = c("red", "blue"))В целом многие идеи из R перекочевали в пакеты python, такие как pandas, numpy или scipy, как датафреймы и векторизация данных — поэтому в целом очень многие вещи в R покажутся вам знакомыми и удобными.
Источников для изучения много, например, .
Графы знаний (Knowledge graph)
Тут у меня чуть необычный опыт, потому что мне таки довольно часто приходится работать с графами знаний и языки запросов к графам. Поэтому лишь кратко пройдемся по основам, так эта часть чуть более экзотическая.
В классических реляционных базах у нас фиксированная схема — здесь же схема гибкая, каждый предикат — это фактически «колонка» и даже больше.
Представьте, что вы бы моделировали человека и хотели описать ключевые вещи, для примера возьмем конкретного человека Дугласа Адамса, за основу возьмем вот это описание.
Если бы мы использовали реляционную базу, нам бы пришлось создать огромную таблицу или таблицы с огромным количеством колонок, большая часть из которых бы была NULL или заполнена каким-то дефолтным False значением, например, вряд ли у многих из нас есть запись в национальной корейской библиотеке — конечно, мы могли бы выносить их в отдельные таблицы, но это бы в конечном итоге была бы попытка смоделировать гибкую логическую схему с предикатами, с помощью фиксированной реляционной.
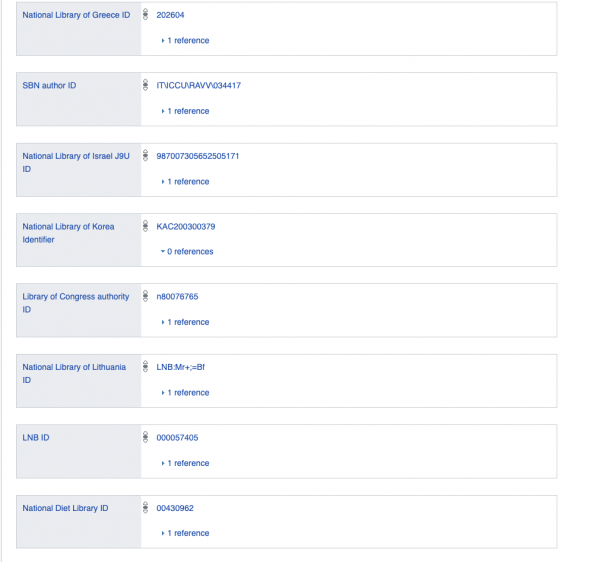
Поэтому представьте себе, что все данные хранятся в виде графа или в виде бинарных и унарных логических выражений.
Где вы вообще можете с таким столкнуться? Во-первых, работая с , да и с любыми графовыми базами данных или связными данными.
Далее следуют основные языки запросов, которые мне приходилось применять и с которыми приходилось работать.
SPARQL
Wiki:
SPARQL ( от SPARQL Protocol and RDF Query Language) — , представленным по модели , а также для передачи этих запросов и ответов на них. SPARQL является рекомендацией и одной из технологий .
А реально это язык запросов к логическим унарным и бинарным предикатам. Вы просто условно указывается, что является фиксированным в логическом выражении, а что нет (очень упрощенно).
Сама база RDF (Resource Description Framework), над которой выполняются SPARQL запросы — это тройка object, predicate, subject — и запрос выбирает нужные тройки по указанным ограничениям в духе: найти такой X, что p_55(X, q_33) верно — где, разумеется, p_55 — это какое-то отношение с айди 55, а q_33 — это объект с айди 33 (вот и весь сказ, опять же опуская всевозможные детали).
Пример представления данных:
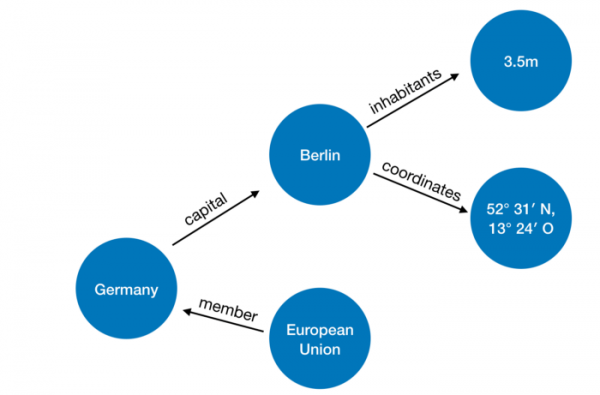
Картинки и пример со странами вот .
Пример базового запроса

Фактически мы хотим найти значение переменной ?country, такой что для предиката
member_of, верно, что member_of(?country,q458), а q458 — это ID европейского союза.
Пример реального запроса SPARQL внутри движка python:
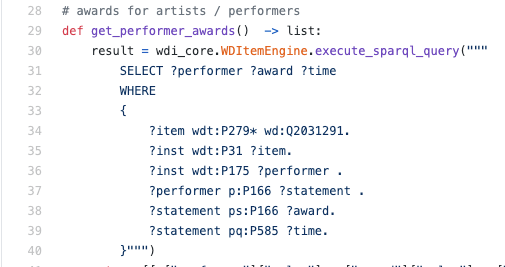
Как правило, мне приходилось читать SPARQL, а не писать — в такой ситуации, скорее всего, это будет полезным навыком понимать язык хотя бы на базовом уровне, чтобы понять, как именно извлекаются данные.
Онлайн много материалов для изучения: например, вот и . Сам обычно гуглю конкретные конструкции и примеры и пока хватает.
Логические языки запросов
Подробнее по теме можно прочитать в моей статье . А здесь, мы лишь кратко разберем, почему логические языки хорошо подходят для написания запросов. По сути, RDF это просто набор вида логических утверждений вида p(X) и h(X,Y), а логический запрос имеет следующий вид:
output(X) :- country(X), member_of(X,“EU”).
Тут мы говорим, о создании нового предиката output/1 (/1 — значит унарный), при условии, что для X верно, что country(X) — т.е., Х — это страна и также member_of(X,“EU”).
То есть у нас и данные, и правила в таком случае представлены вообще одинаково, что позволяет очень легко и хорошо моделировать задачи.
Где встречались в индустрии: целый большой проект с компанией, которая пишет на таком языке запросы, а также на текущем проекте в ядре системы — казалось бы, вещь довольно экзотическая, однако иногда встречается.
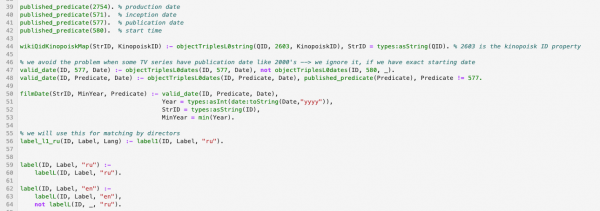
Пример фрагмента кода на логическом языке, обрабатывающем wikidata:
Материалы: приведу тут парочку ссылок на современный логический язык программирования Answer Set Programming — рекомендую изучать именно его:
Источник: habr.com
