

Дорогие читатели, доброго дня. Сегодня поговорим немного про Apache Spark и его перспективы развития.

В современном мире Big Data Apache Spark является де факто стандартом при разработке задач пакетной обработки данных. Помимо этого, он также используется для создания стриминговых приложений, работающих в концепции micro batch, обрабатывающих и отгружающих данные маленькими порциями (Spark Structured Streaming). И традиционно он являлся частью общего стека Hadoop, используя в качестве менеджера ресурсов YARN (или, в некоторых случаях, Apache Mesos). К 2020 году его использование в традиционном виде для большинства компаний находится под большим вопросом в виду отсутствия приличных дистрибутивов Hadoop — развитие HDP и CDH остановлено, CDH недостаточно проработан и имеет высокую стоимость, а остальные поставщики Hadoop либо прекратили своё существование, либо имеют туманное будущее. Поэтому всё больший интерес у сообщества и крупных компаний вызывает запуск Apache Spark с помощью Kubernetes — став стандартом в оркестрации контейнеров и управлении ресурсами в приватных и публичных облаках, он решает проблему с неудобным планированием ресурсов задач Spark на YARN и предоставляет стабильно развивающуюся платформу с множеством коммерческих и открытых дистрибутивов для компаний всех размеров и мастей. К тому же на волне популярности большинство уже успело обзавестись парой-тройкой своих инсталляций и нарастить экспертизу в его использовании, что упрощает переезд.
Начиная с версии 2.3.0 Apache Spark обзавёлся официальной поддержкой запуска задач в кластере Kubernetes и сегодня, мы поговорим о текущей зрелости данного подхода, различных вариантах его использования и подводных камнях, с которыми предстоит столкнуться при внедрении.
Прежде всего, рассмотрим процесс разработки задач и приложений на базе Apache Spark и выделим типовые случаи, в которых требуется запустить задачу на кластере Kubernetes. При подготовке данного поста в качестве дистрибутива используется OpenShift и будут приведены команды, актуальные для его утилиты командной строки (oc). Для других дистрибутивов Kubernetes могут быть использованы соответствующие команды стандартной утилиты командной строки Kubernetes (kubectl) либо их аналоги (например, для oc adm policy).
Первый вариант использования — spark-submit
В процессе разработки задач и приложений разработчику требуется запускать задачи для отладки трансформации данных. Теоретически для этих целей могут быть использованы заглушки, но разработка с участием реальных (пусть и тестовых) экземпляров конечных систем, показала себя в этом классе задач быстрее и качественнее. В том случае, когда мы производим отладку на реальных экземплярах конечных систем, возможны два сценария работы:
- разработчик запускает задачу Spark локально в режиме standalone;

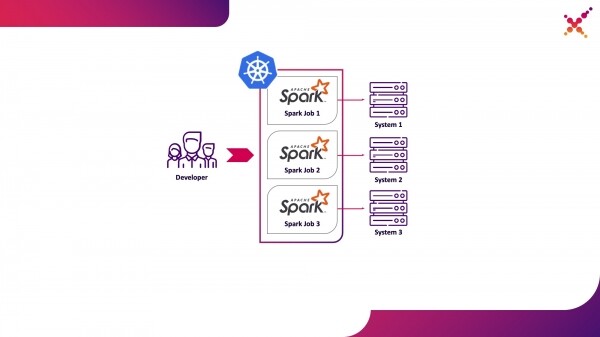
- разработчик запускает задачу Spark на кластере Kubernetes в тестовом контуре.
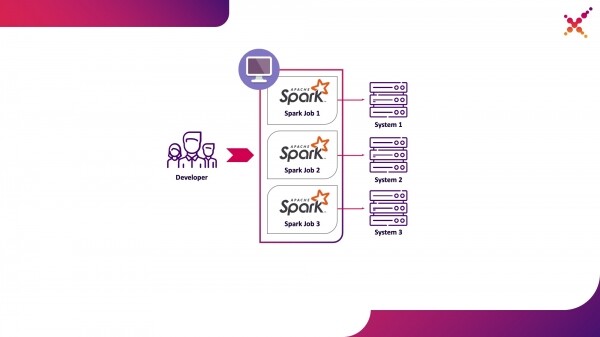
Первый вариант имеет право на существование, но влечёт за собой ряд недостатков:
- для каждого разработчика требуется обеспечить доступ с рабочего места до всех необходимых ему экземпляров конечных систем;
- на рабочей машине требуется достаточное количество ресурсов для запуска разрабатываемой задачи.
Второй вариант лишён данных недостатков, поскольку использование кластера Kubernetes позволяет выделить необходимый пул ресурсов для запуска задач и обеспечить для него необходимые доступы к экземплярам конечных систем, гибко предоставляя к нему доступ с помощью ролевой модели Kubernetes для всех членов команды разработки. Выделим его в качестве первого варианта использования — запуск задач Spark с локальной машины разработчика на кластере Kubernetes в тестовом контуре.
Расскажем подробнее о процессе настройки Spark для локального запуска. Чтобы начать пользоваться Spark его требуется установить:
mkdir /opt/spark
cd /opt/spark
wget http://mirror.linux-ia64.org/apache/spark/spark-2.4.5/spark-2.4.5.tgz
tar zxvf spark-2.4.5.tgz
rm -f spark-2.4.5.tgz
Собираем необходимые пакеты для работы с Kubernetes:
cd spark-2.4.5/
./build/mvn -Pkubernetes -DskipTests clean package
Полная сборка занимает много времени, а для создания образов Docker и их запуска на кластере Kubernetes в реальности нужны только jar файлы из директории «assembly/», поэтому можно собрать только данный подпроект:
./build/mvn -f ./assembly/pom.xml -Pkubernetes -DskipTests clean package
Для запуска задач Spark в Kubernetes требуется создать образ Docker, который будет использоваться в качестве базового. Здесь возможны 2 подхода:
- Созданный образ Docker включает в себя исполняемый код задачи Spark;
- Созданный образ включает в себя только Spark и необходимые зависимости, исполняемый код размещается удалённо (например, в HDFS).
Для начала соберём образ Docker, содержащий тестовый пример задачи Spark. Для создания образов Docker у Spark есть соответствующая утилита под названием «docker-image-tool». Изучим по ней справку:
./bin/docker-image-tool.sh --help
С её помощью можно создавать образы Docker и осуществлять их загрузку в удалённые реестры, но по умолчанию она имеет ряд недостатков:
- в обязательном порядке создаёт сразу 3 образа Docker — под Spark, PySpark и R;
- не позволяет указать имя образа.
Поэтому мы будем использовать модифицированный вариант данной утилиты, приведённый ниже:
vi bin/docker-image-tool-upd.sh
#!/usr/bin/env bash
function error {
echo "$@" 1>&2
exit 1
}
if [ -z "${SPARK_HOME}" ]; then
SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
fi
. "${SPARK_HOME}/bin/load-spark-env.sh"
function image_ref {
local image="$1"
local add_repo="${2:-1}"
if [ $add_repo = 1 ] && [ -n "$REPO" ]; then
image="$REPO/$image"
fi
if [ -n "$TAG" ]; then
image="$image:$TAG"
fi
echo "$image"
}
function build {
local BUILD_ARGS
local IMG_PATH
if [ ! -f "$SPARK_HOME/RELEASE" ]; then
IMG_PATH=$BASEDOCKERFILE
BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
img_path=$IMG_PATH
--build-arg
datagram_jars=datagram/runtimelibs
--build-arg
spark_jars=assembly/target/scala-$SPARK_SCALA_VERSION/jars
)
else
IMG_PATH="kubernetes/dockerfiles"
BUILD_ARGS=(${BUILD_PARAMS})
fi
if [ -z "$IMG_PATH" ]; then
error "Cannot find docker image. This script must be run from a runnable distribution of Apache Spark."
fi
if [ -z "$IMAGE_REF" ]; then
error "Cannot find docker image reference. Please add -i arg."
fi
local BINDING_BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
base_img=$(image_ref $IMAGE_REF)
)
local BASEDOCKERFILE=${BASEDOCKERFILE:-"$IMG_PATH/spark/docker/Dockerfile"}
docker build $NOCACHEARG "${BUILD_ARGS[@]}"
-t $(image_ref $IMAGE_REF)
-f "$BASEDOCKERFILE" .
}
function push {
docker push "$(image_ref $IMAGE_REF)"
}
function usage {
cat <<EOF
Usage: $0 [options] [command]
Builds or pushes the built-in Spark Docker image.
Commands:
build Build image. Requires a repository address to be provided if the image will be
pushed to a different registry.
push Push a pre-built image to a registry. Requires a repository address to be provided.
Options:
-f file Dockerfile to build for JVM based Jobs. By default builds the Dockerfile shipped with Spark.
-p file Dockerfile to build for PySpark Jobs. Builds Python dependencies and ships with Spark.
-R file Dockerfile to build for SparkR Jobs. Builds R dependencies and ships with Spark.
-r repo Repository address.
-i name Image name to apply to the built image, or to identify the image to be pushed.
-t tag Tag to apply to the built image, or to identify the image to be pushed.
-m Use minikube's Docker daemon.
-n Build docker image with --no-cache
-b arg Build arg to build or push the image. For multiple build args, this option needs to
be used separately for each build arg.
Using minikube when building images will do so directly into minikube's Docker daemon.
There is no need to push the images into minikube in that case, they'll be automatically
available when running applications inside the minikube cluster.
Check the following documentation for more information on using the minikube Docker daemon:
https://kubernetes.io/docs/getting-started-guides/minikube/#reusing-the-docker-daemon
Examples:
- Build image in minikube with tag "testing"
$0 -m -t testing build
- Build and push image with tag "v2.3.0" to docker.io/myrepo
$0 -r docker.io/myrepo -t v2.3.0 build
$0 -r docker.io/myrepo -t v2.3.0 push
EOF
}
if [[ "$@" = *--help ]] || [[ "$@" = *-h ]]; then
usage
exit 0
fi
REPO=
TAG=
BASEDOCKERFILE=
NOCACHEARG=
BUILD_PARAMS=
IMAGE_REF=
while getopts f:mr:t:nb:i: option
do
case "${option}"
in
f) BASEDOCKERFILE=${OPTARG};;
r) REPO=${OPTARG};;
t) TAG=${OPTARG};;
n) NOCACHEARG="--no-cache";;
i) IMAGE_REF=${OPTARG};;
b) BUILD_PARAMS=${BUILD_PARAMS}" --build-arg "${OPTARG};;
esac
done
case "${@: -1}" in
build)
build
;;
push)
if [ -z "$REPO" ]; then
usage
exit 1
fi
push
;;
*)
usage
exit 1
;;
esac
С её помощью собираем базовый образ Spark, содержащий в себе тестовую задачу для вычисления числа Pi с помощью Spark (здесь {docker-registry-url} — URL вашего реестра образов Docker, {repo} — имя репозитория внутри реестра, совпадающее с проектом в OpenShift, {image-name} — имя образа (если используется трёхуровневое разделение образов, например, как в интегрированном реестре образов Red Hat OpenShift), {tag} — тег данной версии образа):
./bin/docker-image-tool-upd.sh -f resource-managers/kubernetes/docker/src/main/dockerfiles/spark/Dockerfile -r {docker-registry-url}/{repo} -i {image-name} -t {tag} build
Авторизуемся в кластере OKD с помощью консольной утилиты (здесь {OKD-API-URL} — URL API кластера OKD):
oc login {OKD-API-URL}
Получим токен текущего пользователя для авторизации в Docker Registry:
oc whoami -t
Авторизуемся во внутреннем Docker Registry кластера OKD (в качестве пароля используем токен, полученный с помощью предыдущей команды):
docker login {docker-registry-url}
Загрузим собранный образ Docker в Docker Registry OKD:
./bin/docker-image-tool-upd.sh -r {docker-registry-url}/{repo} -i {image-name} -t {tag} push
Проверим, что собранный образ доступен в OKD. Для этого откроем в браузере URL со списком образов соответствующего проекта (здесь {project} — имя проекта внутри кластера OpenShift, {OKD-WEBUI-URL} — URL Web консоли OpenShift) — https://{OKD-WEBUI-URL}/console/project/{project}/browse/images/{image-name}.
Для запуска задач должен быть создан сервисный аккаунт с привилегиями запуска подов под root (в дальнейшем обсудим этот момент):
oc create sa spark -n {project}
oc adm policy add-scc-to-user anyuid -z spark -n {project}
Выполним команду spark-submit для публикации задачи Spark в кластере OKD, указав созданный сервисный аккаунт и образ Docker:
/opt/spark/bin/spark-submit --name spark-test --class org.apache.spark.examples.SparkPi --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar
Здесь:
—name — имя задачи, которое будет участвовать в формировании имени подов Kubernetes;
—class — класс исполняемого файла, вызываемый при запуске задачи;
—conf — конфигурационные параметры Spark;
spark.executor.instances — количество запускаемых экзекьюторов Spark;
spark.kubernetes.authenticate.driver.serviceAccountName — имя служебной учётной записи Kubernetes, используемой при запуске подов (для определения контекста безопасности и возможностей при взаимодействии с API Kubernetes);
spark.kubernetes.namespace — пространство имён Kubernetes, в котором будут запускаться поды драйвера и экзекьютеров;
spark.submit.deployMode — способ запуска Spark (для стандартного spark-submit используется «cluster», для Spark Operator и более поздних версий Spark «client»);
spark.kubernetes.container.image — образ Docker, используемый для запуска подов;
spark.master — URL API Kubernetes (указывается внешний так обращение происходит с локальной машины);
local:// — путь до исполняемого файла Spark внутри образа Docker.
Переходим в соответствующий проект OKD и изучаем созданные поды — https://{OKD-WEBUI-URL}/console/project/{project}/browse/pods.
Для упрощения процесса разработки может быть использован ещё один вариант, при котором создаётся общий базовый образ Spark, используемый всеми задачами для запуска, а снэпшоты исполняемых файлов публикуются во внешнее хранилище (например, Hadoop) и указываются при вызове spark-submit в виде ссылки. В этом случае можно запускать различные версии задач Spark без пересборки образов Docker, используя для публикации образов, например, WebHDFS. Отправляем запрос на создание файла (здесь {host} — хост сервиса WebHDFS, {port} — порт сервиса WebHDFS, {path-to-file-on-hdfs} — желаемый путь к файлу на HDFS):
curl -i -X PUT "http://{host}:{port}/webhdfs/v1/{path-to-file-on-hdfs}?op=CREATE
При этом будет получен ответ вида (здесь {location} — это URL, который нужно использовать для загрузки файла):
HTTP/1.1 307 TEMPORARY_REDIRECT
Location: {location}
Content-Length: 0
Загружаем исполняемый файл Spark в HDFS (здесь {path-to-local-file} — путь к исполняемому файлу Spark на текущем хосте):
curl -i -X PUT -T {path-to-local-file} "{location}"
После этого можем делать spark-submit с использованием файла Spark, загруженного на HDFS (здесь {class-name} — имя класса, который требуется запустить для выполнения задачи):
/opt/spark/bin/spark-submit --name spark-test --class {class-name} --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} hdfs://{host}:{port}/{path-to-file-on-hdfs}
При этом надо заметить, что для доступа к HDFS и обеспечения работы задачи может потребоваться изменить Dockerfile и скрипт entrypoint.sh — добавить в Dockerfile директиву для копирования зависимых библиотек в директорию /opt/spark/jars и включить файл конфигурации HDFS в SPARK_CLASSPATH в entrypoint.sh.
Второй вариант использования — Apache Livy
Далее, когда задача разработана и требуется протестировать полученный результат, возникает вопрос её запуска в рамках процесса CI/CD и отслеживания статусов её выполнения. Конечно, можно запускать её и с помощью локального вызова spark-submit, но это усложняет инфраструктуру CI/CD поскольку требует установку и конфигурацию Spark на агентах/раннерах CI сервера и настройки доступа к API Kubernetes. Для данного случая целевой реализацией выбрано использование Apache Livy в качестве REST API для запуска задач Spark, размещённого внутри кластера Kubernetes. С его помощью можно запускать задачи Spark на кластере Kubernetes используя обычные cURL запросы, что легко реализуемо на базе любого CI решения, а его размещение внутри кластера Kubernetes решает вопрос аутентификации при взаимодействии с API Kubernetes.
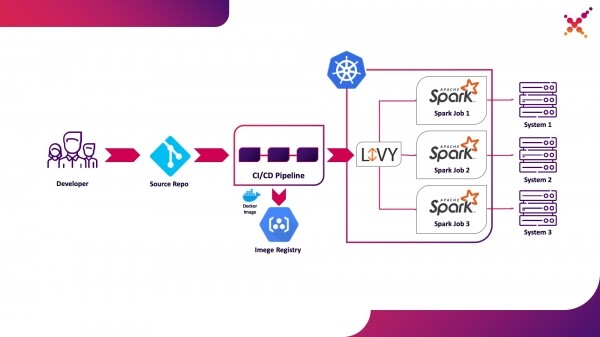
Выделим его в качестве второго варианта использования — запуск задач Spark в рамках процесса CI/CD на кластере Kubernetes в тестовом контуре.
Немного про Apache Livy — он работает как HTTP сервер, предоставляющий Web интерфейс и RESTful API, позволяющий удалённо запустить spark-submit, передав необходимые параметры. Традиционно он поставлялся в составе дистрибутива HDP, но также может быть развёрнут в OKD или любой другой инсталляции Kubernetes с помощью соответствующего манифеста и набора образов Docker, например, этого — . Для нашего случая был собран аналогичный образ Docker, включающий в себя Spark версии 2.4.5 из следующего Dockerfile:
FROM java:8-alpine
ENV SPARK_HOME=/opt/spark
ENV LIVY_HOME=/opt/livy
ENV HADOOP_CONF_DIR=/etc/hadoop/conf
ENV SPARK_USER=spark
WORKDIR /opt
RUN apk add --update openssl wget bash &&
wget -P /opt https://downloads.apache.org/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz &&
tar xvzf spark-2.4.5-bin-hadoop2.7.tgz &&
rm spark-2.4.5-bin-hadoop2.7.tgz &&
ln -s /opt/spark-2.4.5-bin-hadoop2.7 /opt/spark
RUN wget http://mirror.its.dal.ca/apache/incubator/livy/0.7.0-incubating/apache-livy-0.7.0-incubating-bin.zip &&
unzip apache-livy-0.7.0-incubating-bin.zip &&
rm apache-livy-0.7.0-incubating-bin.zip &&
ln -s /opt/apache-livy-0.7.0-incubating-bin /opt/livy &&
mkdir /var/log/livy &&
ln -s /var/log/livy /opt/livy/logs &&
cp /opt/livy/conf/log4j.properties.template /opt/livy/conf/log4j.properties
ADD livy.conf /opt/livy/conf
ADD spark-defaults.conf /opt/spark/conf/spark-defaults.conf
ADD entrypoint.sh /entrypoint.sh
ENV PATH="/opt/livy/bin:${PATH}"
EXPOSE 8998
ENTRYPOINT ["/entrypoint.sh"]
CMD ["livy-server"]
Созданный образ может быть собран и загружен в имеющийся у вас репозиторий Docker, например, внутренний репозиторий OKD. Для его развёртывания используется следующий манифест ({registry-url} — URL реестра образов Docker, {image-name} — имя образа Docker, {tag} — тег образа Docker, {livy-url} — желаемый URL, по которому будет доступен сервер Livy; манифест «Route» применяется в случае, если в качестве дистрибутива Kubernetes используется Red Hat OpenShift, в противном случае используется соответствующий манифест Ingress или Service типа NodePort):
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
component: livy
name: livy
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
component: livy
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
component: livy
spec:
containers:
- command:
- livy-server
env:
- name: K8S_API_HOST
value: localhost
- name: SPARK_KUBERNETES_IMAGE
value: 'gnut3ll4/spark:v1.0.14'
image: '{registry-url}/{image-name}:{tag}'
imagePullPolicy: Always
name: livy
ports:
- containerPort: 8998
name: livy-rest
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/log/livy
name: livy-log
- mountPath: /opt/.livy-sessions/
name: livy-sessions
- mountPath: /opt/livy/conf/livy.conf
name: livy-config
subPath: livy.conf
- mountPath: /opt/spark/conf/spark-defaults.conf
name: spark-config
subPath: spark-defaults.conf
- command:
- /usr/local/bin/kubectl
- proxy
- '--port'
- '8443'
image: 'gnut3ll4/kubectl-sidecar:latest'
imagePullPolicy: Always
name: kubectl
ports:
- containerPort: 8443
name: k8s-api
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: spark
serviceAccountName: spark
terminationGracePeriodSeconds: 30
volumes:
- emptyDir: {}
name: livy-log
- emptyDir: {}
name: livy-sessions
- configMap:
defaultMode: 420
items:
- key: livy.conf
path: livy.conf
name: livy-config
name: livy-config
- configMap:
defaultMode: 420
items:
- key: spark-defaults.conf
path: spark-defaults.conf
name: livy-config
name: spark-config
---
apiVersion: v1
kind: ConfigMap
metadata:
name: livy-config
data:
livy.conf: |-
livy.spark.deploy-mode=cluster
livy.file.local-dir-whitelist=/opt/.livy-sessions/
livy.spark.master=k8s://http://localhost:8443
livy.server.session.state-retain.sec = 8h
spark-defaults.conf: 'spark.kubernetes.container.image "gnut3ll4/spark:v1.0.14"'
---
apiVersion: v1
kind: Service
metadata:
labels:
app: livy
name: livy
spec:
ports:
- name: livy-rest
port: 8998
protocol: TCP
targetPort: 8998
selector:
component: livy
sessionAffinity: None
type: ClusterIP
---
apiVersion: route.openshift.io/v1
kind: Route
metadata:
labels:
app: livy
name: livy
spec:
host: {livy-url}
port:
targetPort: livy-rest
to:
kind: Service
name: livy
weight: 100
wildcardPolicy: None
После его применения и успешного запуска пода графический интерфейс Livy доступен по ссылке: http://{livy-url}/ui. С помощью Livy мы можем опубликовать нашу задачу Spark, используя REST запрос, например, из Postman. Пример коллекции с запросами представлен ниже (в массиве «args» могут быть переданы конфигурационные аргументы с переменными, необходимыми для работы запускаемой задачи):
{
"info": {
"_postman_id": "be135198-d2ff-47b6-a33e-0d27b9dba4c8",
"name": "Spark Livy",
"schema": "https://schema.getpostman.com/json/collection/v2.1.0/collection.json"
},
"item": [
{
"name": "1 Submit job with jar",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{nt"file": "local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar", nt"className": "org.apache.spark.examples.SparkPi",nt"numExecutors":1,nt"name": "spark-test-1",nt"conf": {ntt"spark.jars.ivy": "/tmp/.ivy",ntt"spark.kubernetes.authenticate.driver.serviceAccountName": "spark",ntt"spark.kubernetes.namespace": "{project}",ntt"spark.kubernetes.container.image": "{docker-registry-url}/{repo}/{image-name}:{tag}"nt}n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
},
{
"name": "2 Submit job without jar",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{nt"file": "hdfs://{host}:{port}/{path-to-file-on-hdfs}", nt"className": "{class-name}",nt"numExecutors":1,nt"name": "spark-test-2",nt"proxyUser": "0",nt"conf": {ntt"spark.jars.ivy": "/tmp/.ivy",ntt"spark.kubernetes.authenticate.driver.serviceAccountName": "spark",ntt"spark.kubernetes.namespace": "{project}",ntt"spark.kubernetes.container.image": "{docker-registry-url}/{repo}/{image-name}:{tag}"nt},nt"args": [ntt"HADOOP_CONF_DIR=/opt/spark/hadoop-conf",ntt"MASTER=k8s://https://kubernetes.default.svc:8443"nt]n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
}
],
"event": [
{
"listen": "prerequest",
"script": {
"id": "41bea1d0-278c-40c9-ad42-bf2e6268897d",
"type": "text/javascript",
"exec": [
""
]
}
},
{
"listen": "test",
"script": {
"id": "3cdd7736-a885-4a2d-9668-bd75798f4560",
"type": "text/javascript",
"exec": [
""
]
}
}
],
"protocolProfileBehavior": {}
}
Выполним первый запрос из коллекции, перейдём в интерфейс OKD и проверим, что задача успешно запущена — https://{OKD-WEBUI-URL}/console/project/{project}/browse/pods. При этом в интерфейсе Livy (http://{livy-url}/ui) появится сессия, в рамках которой с помощью API Livy или графического интерфейса можно отслеживать ход выполнения задачи и изучать логи сессии.
Теперь покажем механизм работы Livy. Для этого изучим журналы контейнера Livy внутри пода с сервером Livy — https://{OKD-WEBUI-URL}/console/project/{project}/browse/pods/{livy-pod-name}?tab=logs. Из них видно, что при вызове REST API Livy в контейнере с именем «livy» выполняется spark-submit, аналогичный используемому нами выше (здесь {livy-pod-name} — имя созданного пода с сервером Livy). В коллекции также представлен второй запрос, позволяющий запускать задачи с удалённым размещением исполняемого файла Spark с помощью сервера Livy.
Третий вариант использования — Spark Operator
Теперь, когда задача протестирована, встаёт вопрос её регулярного запуска. Нативным способом для регулярного запуска задач в кластере Kubernetes является сущность CronJob и можно использовать её, но в данный момент большую популярность имеет использование операторов для управления приложениями в Kubernetes и для Spark существует достаточно зрелый оператор, который, в том числе, используется в решениях Enterprise уровня (например, Lightbend FastData Platform). Мы рекомендуем использовать его — текущая стабильная версия Spark (2.4.5) имеет достаточно ограниченные возможности по конфигурации запуска задач Spark в Kubernetes, при этом в следующей мажорной версии (3.0.0) заявлена полноценная поддержка Kubernetes, но дата её выхода остаётся неизвестной. Spark Operator компенсирует этот недостаток, добавляя важные параметры конфигурации (например, монтирование ConfigMap с конфигурацией доступа к Hadoop в поды Spark) и возможность регулярного запуска задачи по расписанию.
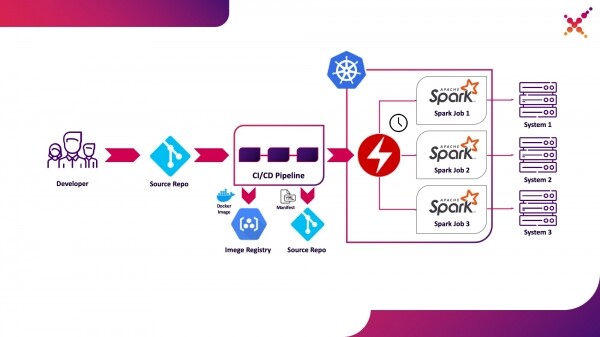
Выделим его в качестве третьего варианта использования — регулярный запуск задач Spark на кластере Kubernetes в продуктивном контуре.
Spark Operator имеет открытый исходный код и разрабатывается в рамках Google Cloud Platform — . Его установка может быть произведена 3 способами:
- В рамках установки Lightbend FastData Platform/Cloudflow;
- С помощью Helm:
helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator helm install incubator/sparkoperator --namespace spark-operator - Применением манифестов из официального репозитория (https://github.com/GoogleCloudPlatform/spark-on-k8s-operator/tree/master/manifest). При этом стоит отметить следующее — в состав Cloudflow входит оператор с версией API v1beta1. Если используется данный тип установки, то описания манифестов приложений Spark должны строиться на основе примеров из тегов в Git с соответствующей версией API, например, «v1beta1-0.9.0-2.4.0». Версию оператора можно посмотреть в описании CRD, входящего в состав оператора в словаре «versions»:
oc get crd sparkapplications.sparkoperator.k8s.io -o yaml
Если оператор установлен корректно, то в соответствующем проекте появится активный под с оператором Spark (например, cloudflow-fdp-sparkoperator в пространстве Cloudflow для установки Cloudflow) и появится соответствующий тип ресурсов Kubernetes с именем «sparkapplications». Изучить имеющиеся приложений Spark можно следующей командой:
oc get sparkapplications -n {project}
Для запуска задач с помощью Spark Operator требуется сделать 3 вещи:
- создать образ Docker, включающий в себя все необходимые библиотеки, а также конфигурационные и исполняемые файлы. В целевой картине это образ, созданный на этапе CI/CD и протестированный на тестовом кластере;
- опубликовать образ Docker в реестр, доступный из кластера Kubernetes;
- сформировать манифест с типом «SparkApplication» и описанием запускаемой задачи. Примеры манифестов доступны в официальном репозитории (например, ). Стоит отметить важные моменты касательно манифеста:
- в словаре «apiVersion» должна быть указана версия API, соответствующая версии оператора;
- в словаре «metadata.namespace» должно быть указано пространство имён, в котором будет запущено приложение;
- в словаре «spec.image» должен быть указан адрес созданного образа Docker в доступном реестре;
- в словаре «spec.mainClass» должен быть указан класс задачи Spark, который требуется запустить при запуске процесса;
- в словаре «spec.mainApplicationFile» должен быть указан путь к исполняемому jar файлу;
- в словаре «spec.sparkVersion» должна быть указана используемая версия Spark;
- в словаре «spec.driver.serviceAccount» должна быть указана сервисная учётная запись внутри соответствующего пространства имён Kubernetes, которая будет использована для запуска приложения;
- в словаре «spec.executor» должно быть указано количество ресурсов, выделяемых приложению;
- в словаре «spec.volumeMounts» должна быть указана локальная директория, в которой будут создаваться локальные файлы задачи Spark.
Пример формирования манифеста (здесь {spark-service-account} — сервисный аккаунт внутри кластера Kubernetes для запуска задач Spark):
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 0.1
coreLimit: "200m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: {spark-service-account}
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
В данном манифесте указана сервисная учётная запись, для которой требуется до публикации манифеста создать необходимые привязки ролей, предоставляющие необходимые права доступа для взаимодействия приложения Spark с API Kubernetes (если нужно). В нашем случае приложению нужны права на создание Pod’ов. Создадим необходимую привязку роли:
oc adm policy add-role-to-user edit system:serviceaccount:{project}:{spark-service-account} -n {project}
Также стоит отметить, что в спецификации данного манифеста может быть указан параметр «hadoopConfigMap», который позволяет указать ConfigMap с конфигурацией Hadoop без необходимости предварительного помещения соответствующего файла в образ Docker. Также он подходит для регулярного запуска задач — с помощью параметра «schedule» может быть указано расписание запуска данной задачи.
После этого сохраняем наш манифест в файл spark-pi.yaml и применяем его к нашему кластеру Kubernetes:
oc apply -f spark-pi.yaml
При этом создастся объект типа «sparkapplications»:
oc get sparkapplications -n {project}
> NAME AGE
> spark-pi 22h
При этом будет создан под с приложением, статус которого будет отображаться в созданном «sparkapplications». Его можно посмотреть следующей командой:
oc get sparkapplications spark-pi -o yaml -n {project}
По завершении задачи POD перейдёт в статус «Completed», который также обновится в «sparkapplications». Логи приложения можно посмотреть в браузере или с помощью следующей команды (здесь {sparkapplications-pod-name} — имя пода запущенной задачи):
oc logs {sparkapplications-pod-name} -n {project}
Также управление задачами Spark может быть осуществлено с помощью специализированной утилиты sparkctl. Для её установки клонируем репозиторий с её исходным кодом, установим Go и соберём данную утилиту:
git clone https://github.com/GoogleCloudPlatform/spark-on-k8s-operator.git
cd spark-on-k8s-operator/
wget https://dl.google.com/go/go1.13.3.linux-amd64.tar.gz
tar -xzf go1.13.3.linux-amd64.tar.gz
sudo mv go /usr/local
mkdir $HOME/Projects
export GOROOT=/usr/local/go
export GOPATH=$HOME/Projects
export PATH=$GOPATH/bin:$GOROOT/bin:$PATH
go -version
cd sparkctl
go build -o sparkctl
sudo mv sparkctl /usr/local/bin
Изучим список запущенных задач Spark:
sparkctl list -n {project}
Создадим описание для задачи Spark:
vi spark-app.yaml
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 1
coreLimit: "1000m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: spark
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
Запустим описанную задачу с помощью sparkctl:
sparkctl create spark-app.yaml -n {project}
Изучим список запущенных задач Spark:
sparkctl list -n {project}
Изучим список событий запущенной задачи Spark:
sparkctl event spark-pi -n {project} -f
Изучим статус запущенной задачи Spark:
sparkctl status spark-pi -n {project}
В заключение хотелось бы рассмотреть обнаруженные минусы эксплуатации текущей стабильной версии Spark (2.4.5) в Kubernetes:
- Первый и, пожалуй, главный минус — это отсутствие Data Locality. Несмотря на все недостатки YARN были и плюсы в его использовании, например, принцип доставки кода к данным (а не данных к коду). Благодаря ему задачи Spark выполнялись на узлах, где располагались данные, участвующие в вычислениях, и заметно уменьшалось время на доставку данных по сети. При использовании Kubernetes мы сталкиваемся с необходимостью перемещения по сети данных, задействованных в работе задачи. В случае, если они достаточно большие, то время выполнения задачи может существенно увеличиться, а также потребоваться достаточно большой объём дискового пространства, выделенного экземплярам задачи Spark для их временного хранения. Данный недостаток может быть снижен за счёт использования специализированных программных средств, обеспечивающих локальность данных в Kubernetes (например, Alluxio), но это фактически означает необходимость хранения полной копии данных на узлах кластера Kubernetes.
- Второй важный минус — это безопасность. По умолчанию функции, связанные с обеспечением безопасности касательно запуска задач Spark отключены, вариант использования Kerberos в официальной документации не охвачен (хотя соответствующие параметры появились в версии 3.0.0, что потребует дополнительной проработки), а в документации по обеспечению безопасности при использовании Spark (https://spark.apache.org/docs/2.4.5/security.html) в качестве хранилищ ключей фигурируют только YARN, Mesos и Standalone Cluster. При этом пользователь, под которым запускаются задачи Spark, не может быть указан напрямую — мы лишь задаём сервисную учётную запись, под которой будет работать под, а пользователь выбирается исходя из настроенных политик безопасности. В связи с этим либо используется пользователь root, что не безопасно в продуктивном окружении, либо пользователь с случайным UID, что неудобно при распределении прав доступа к данным (решаемо созданием PodSecurityPolicies и их привязкой к соответствующим служебным учётным записям). На текущий момент решается либо помещением всех необходимых файлов непосредственно в образ Docker, либо модификацией скрипта запуска Spark для использования механизма хранения и получения секретов, принятого в Вашей организации.
- Запуск задач Spark с помощью Kubernetes официально до сих пор находится в экспериментальном режиме и в будущем возможны значительные изменения в используемых артефактах (конфигурационных файлах, базовых образов Docker и скриптах запуска). И действительно — при подготовке материала тестировались версии 2.3.0 и 2.4.5, поведение существенно отличалось.
Будем ждать обновлений — недавно вышла свежая версия Spark (3.0.0), принёсшая ощутимые изменения в работу Spark на Kubernetes, но сохранившая экспериментальный статус поддержки данного менеджера ресурсов. Возможно, следующие обновления действительно позволят в полной мере рекомендовать отказаться от YARN и запускать задачи Spark на Kubernetes, не опасаясь за безопасность Вашей системы и без необходимости самостоятельной доработки функциональных компонентов.
Fin.
Источник: habr.com
