

Введение
Так получилось, что на моем текущем месте работы мне пришлось познакомиться с данной технологией. Начну с небольшой предыстории. На очередном митинге, нашей команде сказали, что нужно создать интеграцию с известной системой. Под интеграцией подразумевалось, что эта известная система будет нам слать запросы через HTTP на определенный ендпоинт, а мы, как это ни странно, слать обратно ответы в виде SOAP сообщения. Вроде все просто и тривиально. Из этого следует что нужно…
Задача
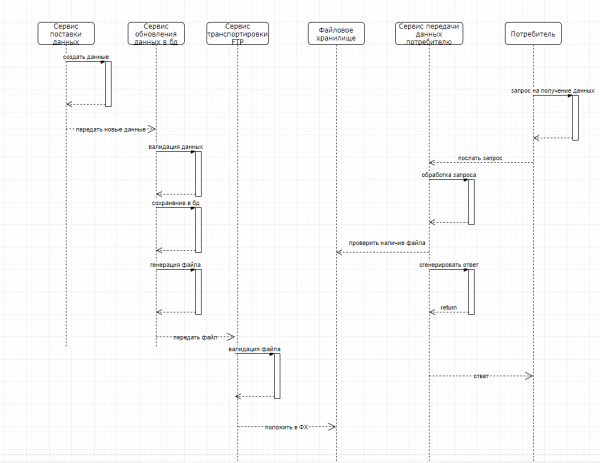
Создать 3 сервиса. Первый из них — Сервис обновления БД. Этот сервис, при поступлении новых данных из сторонней системы, обновляет данные в базе данных и генерирует некий файл в формате CSV, для передачи его в следующую систему. Вызывается ендпоинт второго сервиса — Сервиса транспортировки через FTP, который получает переданный файл, валидирует его, и кладет в файловое хранилище через FTP. Третий сервис — Сервис передачи данных потребителю, работает асинхронно с первыми двумя. Он принимает запрос от сторонней внешней системы, на получение файла о котором шла речь выше, берет готовый файл ответа, модифицирует его (обновляет поля id, description, linkToFile) и посылает ответ в виде SOAP сообщения. Т е в целом картина следующая: первые два сервиса начинают свою работу только тогда, когда пришли данные для обновления. Третий сервис работает постоянно поскольку потребителей информации много, порядка 1000 запросов на получение данных в минуту. Сервисы доступны постоянно и их инстанцы располагаются на разных окружениях, таких как тест, демо, препрод и прод. Ниже представлена схема работы этих сервисов. Сразу поясню, что некоторые детали упрощены для избежания лишней сложности.
Техническое углубление
При планировании решения задачи, сначала решили сделать приложения на java с использованием Spring framework, балансировщиком Nginx, базой данных Postgres и прочими техническими и не очень штуками. Поскольку время на проработку технического решения позволяло рассмотреть другие подходы решения этой задачи, взгляд упал на модную в определенных кругах технологию Apache NIFI. Сразу скажу, что эта технология позволила заметить нам эти 3 сервиса. В этой статье будет описана разработка сервиса транспортировки файла и сервиса передачи данных потребителю, однако если статья зайдет, напишу про сервис обновления данных в БД.
Что это такое
NIFI представляет собой распределенную архитектуру для быстрой параллельной загрузки и обработки данных, большое количество плагинов для источников и преобразований, версионирование конфигураций и многое другое. Приятным бонусом является то, что он очень прост в использовании. Тривиальные процессы, такие как getFile, sendHttpRequest и другие — можно представить в виде квадратов. Каждый квадрат представляет некий процесс, взаимодействие которого можно увидеть на рисунке ниже. Более подробная документация по взаимодействию настройке процессов написана , для тех кому на русском — . В документации отлично расписано как распаковать и запустить NIFI, а так же, как создать процессы, они же квадраты
Идея написать статью родилась после продолжительных поисков и структурирования полученной информации в что-то осознанное, а так же желание немного облегчить жизнь будущим разработчиками..
Пример
Рассмотрен пример того как взаимодействуют квадраты между собой. Общая схема довольно простая: Получаем HTTP запрос (В теории с файлом в теле запроса. Для демонстрации возможностей NIFI, в данном примере запрос стартует процесс получения файла из локального ФХ), далее отсылаем обратно ответ, что запрос получен, параллельно запускается процесс получения файла из ФХ и далее процесс перемещение его через FTP в ФХ. Стоит пояснить, что процессы взаимодействуют между собой посредством так называемого flowFile. Это базовая сущность в NIFI, которая хранит в себе атрибуты и содержимое. Содержимое — данные которые представлены файлом потока. Т е грубо говоря, если вы получили файл из одного квадрата и передаете его в другой, контентом будет ваш файл.
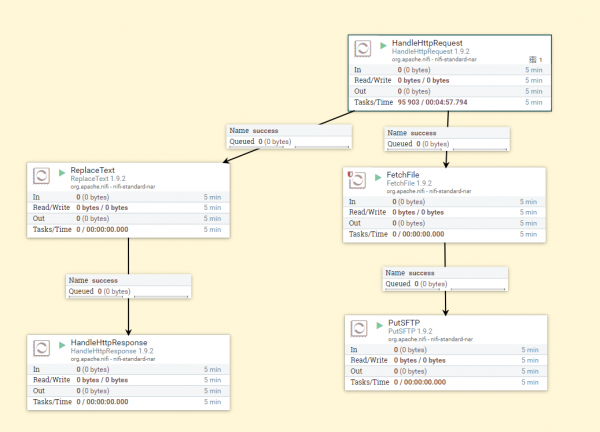
Как вы можете заметить — на этом рисунке изображен общий процесс. HandleHttpRequest — принимает запросы, ReplaceText — генерирует тело ответа, HandleHttpResponse — отдает ответ. FetchFile — получает файл из файлового хранилища передает его квадрату PutSftp — кладет этот файл на FTP, по указанному адресу. Теперь подробнее об этом процессе.
В данном случае — request всему начало. Посмотрим его параметры конфигурации.
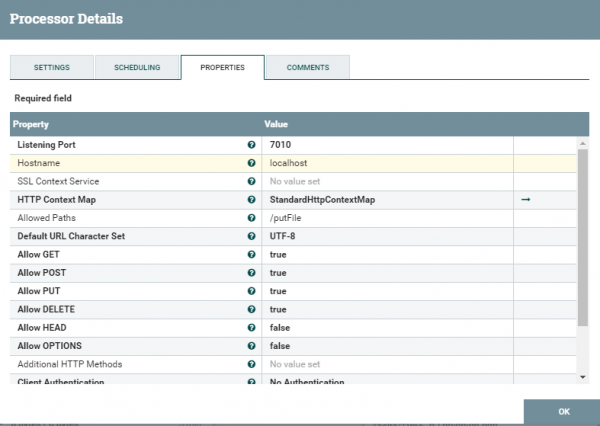
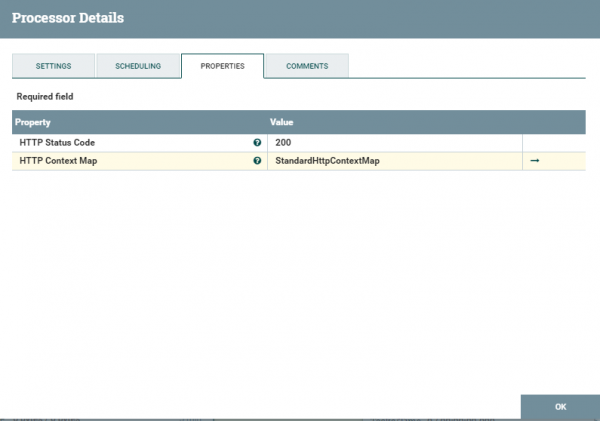
Здесь все довольно тривиально за исключением StandartHttpContextMap — это некий сервис который который позволяет посылать и принимать запросы. Более подробно и даже с примерами можно посмотреть —
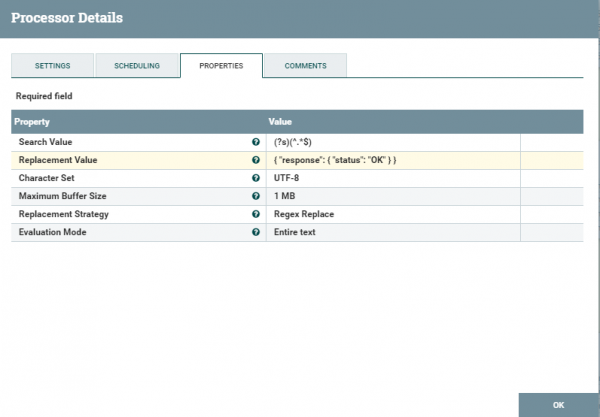
Далее посмотрим параметры конфигурации ReplaceText квадрата. В ней стоит обратить внимание на ReplacementValue — это то, что вернется пользователю в виде ответа. В settings можно регулировать уровень логгирования, логи можно посмотреть {куда распаковали nifi}/nifi-1.9.2/logs там же есть параметры failure/success — основываясь на эти параметры можно регулировать процесс в целом. Т е в случае успешной обработки текста — вызовется процесс отправки ответа пользователю, а в другом случае мы просто залогируем неуспешный процесс.
В свойствах HandleHttpResponse особо ничего интересного нет кроме статуса при успешном создании ответа.
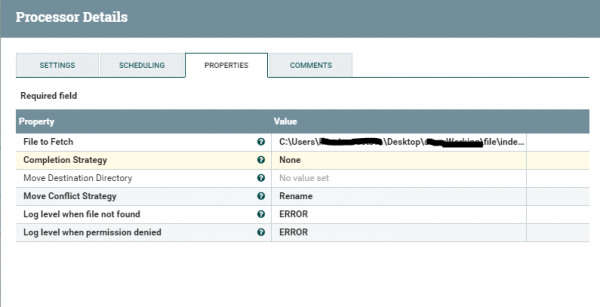
С запросом ответом разобрались — перейдем дальше к получению файла и помещением его на FTP сервер. FetchFile — получает файл по указанному в настройках пути и передает его в следующий процесс.
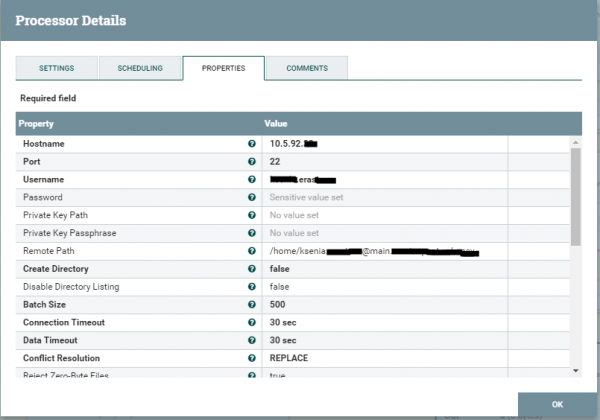
И далее квадрат PutSftp — помещает файл в файловое хранилище. Параметры конфигурации можем увидеть ниже.
Стоит обратить внимание на то, что каждый квадрат — это отдельный процесс, который должен быть запущен. Мы рассмотрели самый простой пример который не требует какой либо сложной кастомизиции. Далее рассмотрим процесс немного сложнее, где немного попишем на грувях.
Более сложный пример
Сервис передачи данных потребителю получился немного сложнее за счет процесса модификации SOAP сообщения. Общий процесс представлен на рисунке ниже.
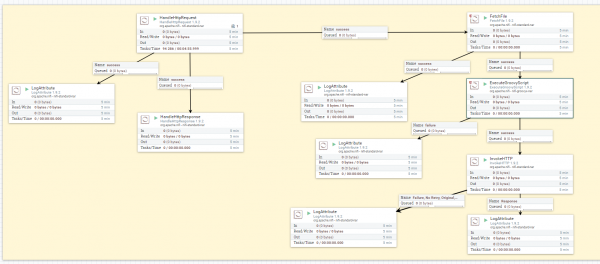
Здесь идея тоже не особо сложная: получили запрос от потребителя, что ему нужны данные, отправили ответ, что получили сообщение, запустили процесс получения файла ответа, далее отредактировали его с определенной логикой, после чего передали файл потребителю в виде SOAP сообщения на сервер.
Думаю не стоит описывать заново те квадраты, которые мы видели выше — перейдем сразу к новым. Если вам необходимо редактировать какой либо файл и обычные квадраты типа ReplaceText не подходят, вам придется писать свой скрипт. Сделать это можно с помощью квадрата ExecuteGroogyScript. Настройки его представлены ниже.
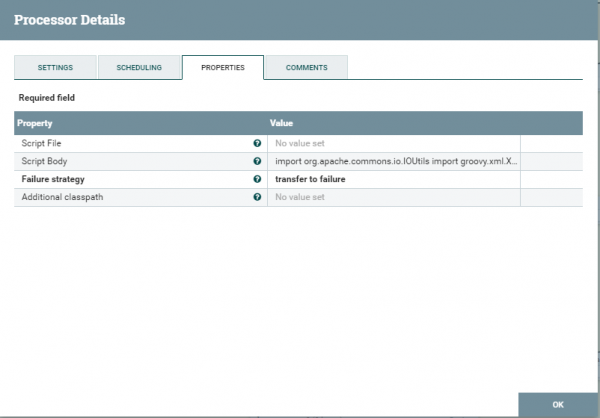
Есть два варианта загрузки скрипта в этот квадрат. Первый — это путем загрузки файла со скриптом. Второй — вставкой скрипта в scriptBody. На сколько я знаю, квадрат executeScript поддерживает несколько ЯП — один из них groovy. Разочарую java разработчиков — на java нельзя писать скрипты в таких квадратах. Для тех кому очень хочется — нужно создать свой кастомный квадрат и подкинуть его в систему NIFI. Вся эта операция сопровождается довольно продолжительными танцами с бубном, которыми мы не будем в рамках этой статьи заниматься. Я выбрала язык groovy. Ниже представлен тестовый скрипт который просто инкрементно обновляет id в SOAP сообщении. Важно отметить. Вы берете файл из flowFile обновляете его, не стоит забывать, что его нужно, обновленный, обратно туда положить. Так же стоит отметить, что не все библиотеки подключены. Может получиться так, что вам все-таки придется импортировать одну из либ. Минусом еще является то, что скрипт в данном квадрате довольно трудно дебажить. Есть способ подключиться к JVM NIFI и начать процесс отладки. Лично я запускала у себя локальное приложение и имитировала получение файла из сессии. Отладкой тоже занималась локально. Ошибки, которые вылезают при загрузке скрипта довольно легко гугляться и пишутся самим NIFI в лог.
import org.apache.commons.io.IOUtils
import groovy.xml.XmlUtil
import java.nio.charset.*
import groovy.xml.StreamingMarkupBuilder
def flowFile = session.get()
if (!flowFile) return
try {
flowFile = session.write(flowFile, { inputStream, outputStream ->
String result = IOUtils.toString(inputStream, "UTF-8");
def recordIn = new XmlSlurper().parseText(result)
def element = recordIn.depthFirst().find {
it.name() == 'id'
}
def newId = Integer.parseInt(element.toString()) + 1
def recordOut = new XmlSlurper().parseText(result)
recordOut.Body.ClientMessage.RequestMessage.RequestContent.content.MessagePrimaryContent.ResponseBody.id = newId
def res = new StreamingMarkupBuilder().bind { mkp.yield recordOut }.toString()
outputStream.write(res.getBytes(StandardCharsets.UTF_8))
} as StreamCallback)
session.transfer(flowFile, REL_SUCCESS)
}
catch(Exception e) {
log.error("Error during processing of validate.groovy", e)
session.transfer(flowFile, REL_FAILURE)
}Собственно на этом кастомизация квадрата заканчивается. Далее обновленный файл передается в квадрат который занимается посылкой файла на сервер. Ниже представлены настройки этого квадрата.
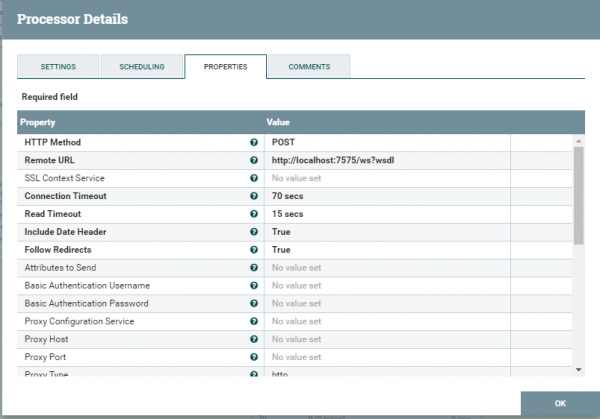
Описываем метод, которым будет передаваться SOAP сообщение. Пишем куда. Далее нужно указать, что это именно SOAP.
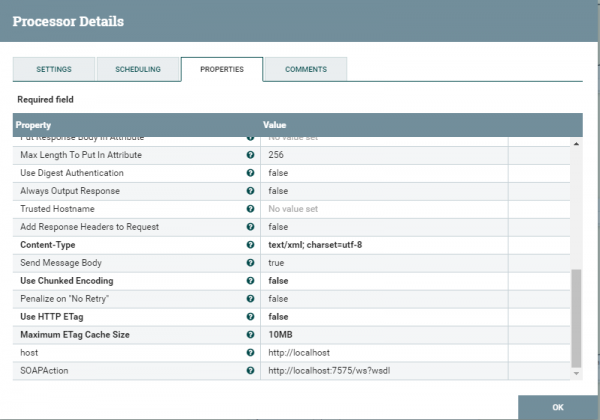
Добавляем несколько свойств таких как хост и действие(soapAction). Сохраняем, проверяем. Более подробно как посылать SOAP запросы можно посмотреть
Мы рассмотрели несколько вариантов использования процессов NIFI. Как они взаимодействуют и какая от них реальная польза. Рассмотренные примеры являются тестовыми и немного отличаются от того, что реально на бою. Надеюсь, эта статья будет немного полезной для разработчиков. Спасибо за внимание. Если есть какие-либо вопросы — пишите. Постараюсь ответить.
Источник: habr.com
