

Продолжая тему конкурсов по машинному обучению на хабре, хотим познакомить читателей еще с двумя платформами. Они конечно не такие огромные как kaggle, но внимания определенно заслуживают.

Лично мне kaggle не слишком нравится по нескольким причинам:
- во-первых, соревнования там часто длятся по несколько месяцев, и для активного участия приходится тратить уйму сил;
- во-вторых, public kernels (публичные решения). Адепты kaggle советуют к ним относиться со спокойствием тибетских монахов, но в реальности довольно обидно, когда то, до чего ты шел месяц или два, вдруг оказывается выложенным на блюдечке всем подряд.
К счастью, соревнования по машинному обучению проводятся и на других платформах, и о паре таких соревнований и пойдет речь.
| Официальный язык: английский, организаторы: Яндекс, Сбербанк, ВШЭ | Официальный язык: русский, организаторы: Mail.ru Group |
| Online Round: Jan 15 — Feb 11, 2019; On-Site Final: Apr 4-6, 2019 | онлайн — с 7 февраля по 15 марта; офлайн — с 30 марта по 1 апреля. |
| По некоторому набору данных о частице в большом адронном коллайдере (о траектории, импульсе, и других довольно сложных физических параметрах) определить мюон это или нет Из этой постановки было выделено 2 задачи: — в одной надо было просто отправить свое предсказание, — а в другой — полный код и модель для предсказания, и на выполнение накладывались довольно жесткие ограничения на время работы и использование памяти | Для соревнования SNA Hackathon были собраны логи показов контента из открытых групп в новостных лентах пользователей за февраль-март 2018 года. В тестовое множество спрятаны последние полторы недели марта. Каждая запись в логе содержит информацию о том, что и кому было показано, а также о том, как отреагировал пользователь на этот контент: поставил «класс», прокомментировал, проигнорировал или скрыл из ленты. Суть задач SNA Hackathon в том, чтобы для каждого пользователя социальной сети Одноклассники отранжировать его ленту, как можно выше поднимая те посты, которые получат «класс». На онлайн этапе задача была разбита на 3 части: 1. отранжировать посты по разнообразным коллаборативным признакам 2. отранжировать посты по содержащимся в них изображениям 3. отранжировать посты по содержащемуся в них тексту |
| Cложная кастомная метрика, что-то вроде ROC-AUC | Cредний ROC-AUC по пользователям |
| Призы за первый этап — футболки за N мест, проход во второй этап, где оплачивались проживание и питание во время конкурса Второй этап — ??? (Я по определенным причинам на церемонии награждения не присутствовал и выведать, что в итоге были за призы не смог). Обещали ноутбуки всем членам команды-победителей | Призы за первый этап — футболки 100 лучшим участникам, проход во второй этап, где оплачивались проезд до Москвы, проживание и питание во время конкурса. Также ближе к концу первого этапа объявили о призах лучшим по 3 задачам на 1 этапе: каждый выиграл по видеокарте RTX 2080 TI! Второй этап — командный, в командах было от 2 до 5 человек, призы: 1 место — 300 000 рублей 2 место — 200 000 рублей 3 место — 100 000 рублей приз жюри — 100 000 рублей |
| Официальная группа в telegram, ~190 участников, общение на английском, на вопросы приходилось ждать ответа по несколько дней | Официальная группа в telegram, ~1500 участников, активное обсуждение задач между участниками и организаторами |
| Организаторы предоставили два базовых решения, простое и продвинутое. Простое требовало менее 16 Гб оперативной памяти, а продвинутое в 16 уже не влазило. При этом, забегая немного вперед, у участников не удалось значительно превзойти продвинутое решение. Сложностей по запуску этих решений не было. Следует отметить, что в продвинутом примере присутствовал комментарий с подсказкой с чего начать улучшение решения. | Предоставлялись базовые примитивные решения для каждой из задач, легко превосходились участниками. В первые дни конкурса участники столкнулись с несколькими сложностями: во-первых, данные были даны в формате Apache Parquet, и не все комбинации Python и пакета parquet работали без ошибок. Второй сложностью стало выкачивание картинок из облака mail, на данный момент нет простого способа скачать большой объем данных за раз. В итоге эти проблемы задержали участников на пару дней. |
IDAO. Первый этап
Задачей было классификация частиц мюон / не мюон по их характеристикам. Ключевой особенностью данной задачи было наличие в тренировочных данных колонки weight, которую сами организаторы трактовали как уверенность в ответе для этой строки. Проблема состояла в том, что довольно много строк содержали отрицательные веса.
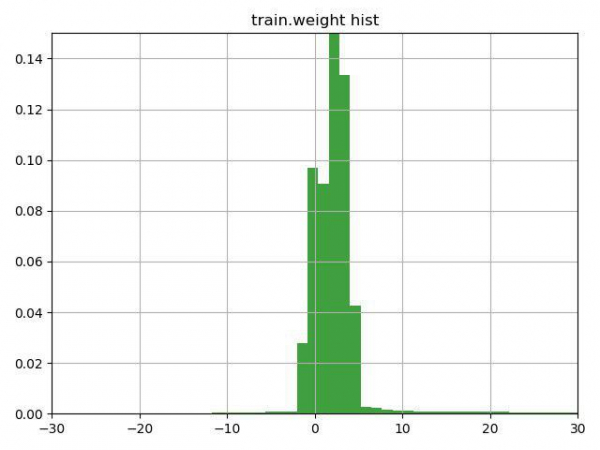
Подумав несколько минут над строчкой с подсказкой (подсказка просто обращала внимание на эту особенность колонки weight) и построив этот график, мы решили проверить 3 варианта:
1) инвертировать таргет у строк с отрицательным весом (и веса соответственно)
2) сдвинуть веса на минимальное значение, так чтобы они начинались с 0
3) не использовать веса для строк
Третий вариант оказался самым худшим, а вот первые два улучшали результат, лучшим оказался вариант №1, который сразу нас вывел на текущее второе место по первой задаче и на первое во второй.

Следующим нашим шагом был просмотр данных на предмет пропущенных значений. Организаторы дали нам уже причесанные данные, где пропущенных значений было довольно мало, и они были заменены на -9999.
Мы обнаружили пропущенные значения в колонках MatchedHit_{X,Y,Z}[N] и MatchedHit_D{X,Y,Z}[N], причем только когда N=2 или 3. Как мы поняли, некоторые частицы не пролетали все 4 детектора, и останавливались или на 3 или на 4 пластине. В данных также присутствовали колонки Lextra_{X,Y}[N], которые видимо описывают то же самое, что и MatchedHit_{X,Y,Z}[N], но используя какую-то экстраполяцию. Эти скудные догадки позволили предположить, что вместо пропущенных значений в MatchedHit_{X,Y,Z}[N] можно подставить Lextra_{X,Y}[N] (только для X и Y координат). MatchedHit_Z[N] хорошо заполнялась медианой. Эти манипуляции позволили нам выйти на 1 промежуточное место по обоим задачам.

Учитывая, что за победу в первом этапе ничего не давали, можно бы было остановиться на этом, но мы продолжили, нарисовали несколько красивых картинок и придумали новые фичи.
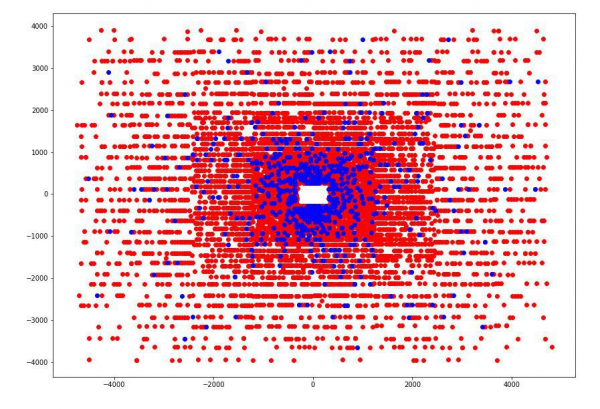
Например, мы обнаружили, что если построить точки пересечений частицы с каждой из четырех пластин детекторов, то можно заметить, что точки на каждой из пластин группируются в 5 прямоугольников с соотношением сторон 4 к 5 и центром в точке (0,0), и в первом прямоугольнике точек нет.
| № пластины / размеры прямоугольников | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Пластина 1 | 500х625 | 1000х1250 | 2000х2500 | 4000х5000 | 8000х10000 |
| Пластина 2 | 520х650 | 1040х1300 | 2080х2600 | 4160х5200 | 8320х10400 |
| Пластина 3 | 560х700 | 1120х1400 | 2240х2800 | 4480х5600 | 8960х11200 |
| Пластина 4 | 600х750 | 1200х1500 | 2400х3000 | 4800х6000 | 9600х12000 |
Определив эти размеры, мы добавили для каждой частицы 4 новые категориальные фичи — номер прямоугольника, в котором она пересекают каждую пластину.
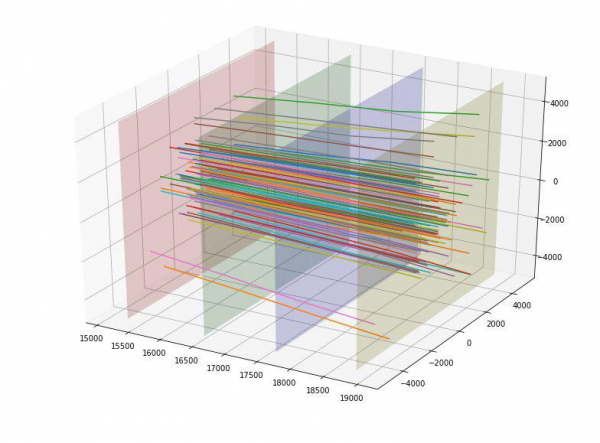
Также мы заметили, что частицы как бы разлетаются в стороны от центра и появилась идея как-то оценить «качество» этого разлета. В идеале, наверное, можно было бы придумать какую-то «идеальную» параболу в зависимости от точки влёта и оценить от нее отклонение, но мы ограничились «идеальной» прямой. Построив такие идеальные прямые для каждой точки влета, мы смогли посчитать средне-квадратичное отклонение траектории каждой частицы от этой прямой. Поскольку среднее отклонение для target = 1 оказалось 152, а для target = 0 получилось 390, мы предварительно оценили данную фичу как хорошую. И действительно, данная фича сразу попала в топ самых полезных.
Мы обрадовались, и добавили отклонение всех 4 точек пересечения для каждой частицы от идеальной прямой как дополнительные 4 фичи (и они тоже неплохо работали).
Ссылки на научные статьи по теме конкурса, данные нам организаторами, натолкнули на мысль, что мы далеко не первые, кто решает данную задачу и, возможно, существует какой-то специализированный софт. Обнаружив на github репозиторий, где были реализованы методы IsMuonSimple, IsMuon, IsMuonLoose, мы перенесли их к себе с небольшими модификациями. Сами методы были очень просты: например, если энергия меньше какого-то порога — то это не мюон, иначе мюон. Настолько простые признаки очевидно не могли дать прироста в случае использования градиентного бустинга, поэтому мы добавили еще знаковое «расстояние» до порога. Эти фичи тоже немного улучшили. Возможно, проанализировав существующие методики более основательно, можно было найти и более сильные методы и добавить их в признаки.
Под конец конкурса мы немного потюнили «быстрое» решение для второй задачи, в итоге оно отличалось от baseline по следующим пунктам:
- В строках с отрицательным весом был инвертирован target
- Заполнили пропущенные значения в MatchedHit_{X,Y,Z}[N]
- Уменьшили глубину до 7
- Уменьшили learning rate до 0.1 (было 0.19)
В итоге мы пробовали еще фичи (не особо удачно), подобрали параметры и обучили catboost, lightgbm и xgboost, попробовали разные блендинги предсказаний и перед открытием привата уверенно выигрывали по второй задаче, а по первой были среди лидеров.
После открытия привата мы оказались на 10 месте по 1 задаче и на 3 по второй. Все лидеры перемешались, и скор на привате оказался выше чем на либерборде. Кажется, что данные были плохо стратифицированы (или например, в привате не было строк с отрицательными весами) и это немного расстроило.
SNA Hackathon 2019 — Тексты. Первый этап
Задачей было отранжировать посты пользователя в социальной сети Одноклассники по содержащемуся в них тексту, кроме текста было еще немного характеристик поста (язык, владелец, дата и время создания, дата и время просмотра).
В качестве классических подходов к работе с текстом я бы выделил два варианта:
- Отображение каждого слова в n-мерное векторное пространство, такое чтобы у похожих слов были похожие вектора (подробнее можно прочитать в ), затем или нахождение среднего слова для текста или использование механизмов, которые учтут взаимное расположение слов (CNN, LSTM/GRU).
- Использование моделей, которые сразу умеют работать с целыми предложениями. Например, Bert. В теории этот подход должен работать лучше.
Поскольку это был мой первый опыт работы с текстами, будет неправильно учить кого-то, поэтому я буду учить себя. Вот такие советы я бы дал себе на начало конкурса:
- Прежде чем бежать что-то обучать, посмотри на данные! Помимо непосредственно текстов в данных было несколько колонок и из них можно было выжать гораздо больше, чем сделал я. Самое простое — сделать mean target encoding для части колонок.
- Не учись на всех данных! Данных было очень много (примерно 17 млн строк) и для проверки гипотез было совершенно необязательно использовать их все. Обучение и предобработка были весьма медленны, и я явно бы успел проверить больше интересных гипотез.
- <Спорный совет> Не надо искать киллер-модель. Я долго разбирался с Elmo и Bert, надеясь, что они сразу меня выведут на высокое место, а в результате использовал предобученные эмбеддинги FastText для русского языка. С Elmo не получилось достичь лучшего скора, а с Bert так и не успел разобраться.
- <Спорный совет> Не надо искать одну киллер-фичу. Посмотрев на данные, я заметил, что в районе 1 процента текстов не содержат, собственно, текста! Но зато там были ссылки на какие-то ресурсы, и я написал простенький парсер, который открывал сайт и вытаскивал название и описание. Вроде хорошая идея, но потом я увлекся, решил распарсить все ссылки для всех текстов и опять потерял много времени. Значительного улучшения итогового результата всё это не дало (хотя разобрался со стеммингом, например).
- Классические фичи работают. Гуглим, например, «text features kaggle», читаем и всё добавляем. TF-IDF давало улучшение, статистические фичи, вроде длины текста, слова, количества пунктуации — тоже.
- Если есть DateTime колонки, стоит их разобрать на несколько отдельных фич (часы, дни недели и т.д). Какие именно фичи выделить, стоит проанализировать графиками/какими-то метриками. Здесь я по наитию сделал всё правильно и нужные фичи выделил, но нормальный анализ бы не помешал (например, как мы сделали на финале).
По итогу конкурса я обучил одну keras модель со сверткой по словам, и еще одну — на основе LSTM и GRU. И там и там использовались предобученные FastText эмбеддинги для русского языка (я попробовал и ряд других эмбеддингов, но именно эти работали лучше всего). Усреднив предсказания, я занял итоговое 7 место из 76 участников.
Уже после первого этапа была опубликована , занявшего второе место (он участвовал вне конкурса), и его решение до какого-то этапа повторяло моё, но он ушел дальше за счет механизма query-key-value attention.
Второй этап OK & IDAO
Вторые этапы конкурсов проходили почти подряд, так что я решил рассмотреть их вместе.
Сначала я с новоприобретенной командой попал в впечатляющий офис компании Mail.ru, где нашей задачей было объединить модели трех треков из первого этапа — текста, картинки и коллаб. На это было отведено чуть больше 2 суток, что оказалось очень мало. По сути, мы смогли только повторить свои результаты первого этапа, не получив никакого выигрыша от объединения. В итоге мы заняли 5 место, но текстовую модель использовать не удалось. Посмотрев на решения других участников, кажется, что стоило попробовать кластеризовать тексты и добавить их к модели коллаба. Побочным эффектом этого этапа стали новые впечатления, знакомства и общение с крутыми участниками и организаторами, а также сильный недосып, который возможно сказался и на результате финального этапа IDAO.
Задачей на очном этапе IDAO 2019 Final было предсказание времени ожидания заказа для яндекс-таксистов в аэропорту. На 2 этапе были выделены 3 задачи = 3 аэропорта. Для каждого аэропорта даны поминутные данные о количестве заказов такси за полгода. А в качестве тестовых данных был дан следующий месяц и поминутные данные о заказах за прошлые 2 недели. Времени было мало (1,5 дня), задача была довольно специфической, из команды на конкурс приехал только один человек — и как итог печальное место ближе к концу. Из интересных идей были попытки использовать внешних данных: о погоде, пробках и статистике заказов яндекс-такси. Хотя организаторы и не сказали, что это за аэропорты, многие участники предположили, что это были Шереметьево, Домодедово и Внуково. Хотя после конкурса это предположение было опровергнуто, фичи, например, с погодных данных Москвы улучшали результат и на валидации и на лидерборде.
Заключение
- ML-конкурсы это круто и интересно! Тут найдется применение умениям и по анализу данных, и по хитрым моделям и техникам, да и просто здравый смысл приветствуется.
- ML — это уже огромный пласт знаний, который кажется что растет экспоненциально. Я поставил себе цель познакомиться с разными областями (сигналы, картинки, таблицы, текст) и уже понял, как много всего надо изучить. Например, после этих конкурсов я решил изучать: алгоритмы кластеризации, продвинутые техники работы с библиотеками градиентного бустинга (в частности поработать с CatBoost на GPU), капсульные сети, механизм query-key-value attention.
- Не kaggle’ом единым! Есть много других конкурсов, где хотя бы футболку получить проще, да и на другие призы больше шансов.
- Общайтесь! В области машинного обучения и анализа данных уже большое community, есть тематические группы в telegram, slack, и серьезные люди из Mail.ru, Яндекса и других компаний отвечают на вопросы и помогают начинающим и продолжающим свой путь в этой области знаний.
- Всем, кто проникся предыдущим пунктом, советую посетить — крупную бесплатную конференцию в Москве, которая пройдет уже 10-11 мая.
Источник: habr.com
