

L'editor di Netology ha intervistato il team leader del team BI in Pavel Sayapin riguardo alle sfide che affrontano gli ingegneri dei dati nel suo team, quali strumenti utilizzano per risolverle e come scegliere correttamente gli strumenti per affrontare le questioni legate ai dati, comprese quelle atipiche. Pavel è docente nel corso «».
Cosa fanno gli ingegneri dei dati in Profi.ru
Profi.ru è un servizio che facilita l'incontro tra clienti e specialisti in vari settori. Il database del servizio conta oltre 900.000 specialisti in 700 tipi di servizi: tutor, professionisti del restauro, allenatori, esperti di bellezza, artisti e altri. Ogni giorno vengono registrati oltre 10.000 nuovi ordini, il che genera circa 100 milioni di eventi al giorno. Mantenere ordine in una tale quantità di dati è impossibile senza ingegneri dei dati professionisti.
Idealmente, un Data Engineer sviluppa una cultura del lavoro con i dati, che consente all'azienda di generare profitto aggiuntivo o ridurre i costi. Porta valore all'impresa, lavorando in team e fungendo da anello di congiunzione tra i diversi attori — dagli sviluppatori ai business consumer dei report. Tuttavia, in ogni azienda le attività possono variare, quindi consideriamo il caso di Profi.ru.
Raccolgono dati per decisioni informate e li forniscono all'utente finale — al top manager, al product manager, all'analista.
I dati devono essere chiari per le decisioni e facili da usare. Non è necessario sforzarsi per cercare una descrizione o formulare una complessa query SQL che tenga conto di molti fattori diversi. L'immagine ideale è che l'utente guardi un dashboard e sia completamente soddisfatto. Se mancano dati in un certo aspetto, può accedere alla base e, con una semplice query SQL, ottenere ciò di cui ha bisogno.
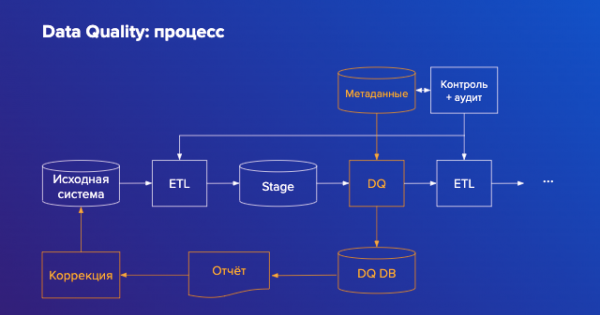
Il ruolo del processo di Data Quality nella struttura generale del data warehouse
Un'importanza fondamentale è attribuita alla documentazione esplicativa sull'uso dei dati. Questo semplifica il lavoro sia per il data engineer (che non viene interrotto da domande) sia per l'utente dei dati (che può trovare autonomamente risposte ai propri quesiti). Su Profi.ru, tali documenti sono raccolti nel forum interno.
Con comodità si intende anche la rapidità di accesso ai dati. Velocità = disponibilità in un solo passaggio, clic — dashboard. Ma nella pratica è tutto più complicato.
Lo stesso Tableau, dal punto di vista dell'utente finale della dashboard, non consente di visualizzare tutte le possibili dimensioni. L'utente si deve accontentare dei filtri creati dal sviluppatore della dashboard. Questo genera due scenari:
- Lo sviluppatore crea molteplici sezioni per la dashboard ⟶ il numero di pagine aumenta notevolmente. Questo riduce la disponibilità dei dati: diventa difficile capire dove si trova cosa.
- Lo sviluppatore crea solo le sezioni chiave. Trovare informazioni diventa più facile, ma per una sezione leggermente non standard si dovrà comunque andare o nel database o dagli analisti. Questo influisce negativamente anche sulla disponibilità.
La disponibilità è un concetto ampio. Si tratta di avere dati nella forma adeguata e della possibilità di accedere alle informazioni sui cruscotti, oltre a disporre del necessario campionamento dei dati.
Accumulano dati da tutte le fonti in un unico posto
Le fonti di dati possono essere interne ed esterne. Ad esempio, un'azienda può dipendere dalle previsioni meteorologiche che devono essere raccolte e archiviate, quindi da fonti esterne.
È fondamentale archiviare le informazioni indicando la fonte e assicurandosi che i dati siano facilmente rintracciabili. Su Profi.ru, questo compito è stato risolto tramite documentazione automatizzata. I file YML vengono utilizzati come documentazione per le fonti di dati interne.
Creano cruscotti
La visualizzazione dei dati è meglio realizzarla con uno strumento professionale, ad esempio Tableau.
La maggior parte delle decisioni viene presa emotivamente, quindi è importante la chiarezza e l'estetica. Excel, ad esempio, non è molto adatto per la visualizzazione in quanto non soddisfa tutte le esigenze degli utenti di dati. Ad esempio, un product manager ama immergersi nei numeri, ma in modo comodo. Questo gli permette di affrontare le sue sfide senza doversi preoccupare di come ottenere informazioni e raccogliere metriche.
Una visualizzazione dei dati di alta qualità permette di prendere decisioni più facilmente e rapidamente.
Più alta è la posizione di una persona, maggiore è la necessità di avere a portata di mano, sul proprio telefono, dati aggregati. I dettagli non interessano ai top manager—è importante controllare la situazione nel suo complesso, e il BI è un buon strumento per farlo.
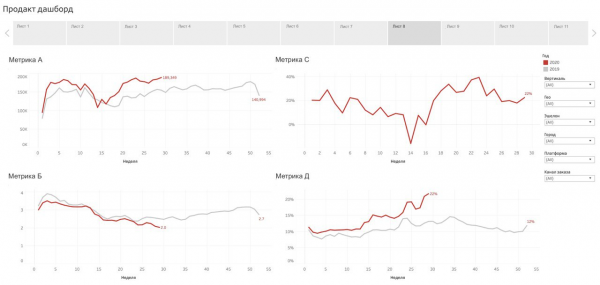
Esempio di product dashboard di Profi.ru (uno dei fogli). Per motivi di riservatezza, i nomi delle metriche e degli assi sono nascosti.
Esempi di compiti reali
Compito 1—trasferire i dati dai sistemi sorgente (operativi) a un data warehouse o ETL.
Uno dei compiti di routine di un data engineer.
Per questo si possono utilizzare:
- script personalizzati eseguiti tramite cron o con un apposito orchestratore come Airflow o Prefect;
- soluzioni ETL open source: Pentaho Data Integration, Talend Data Studio e altre;
- soluzioni proprietarie: Informatica PowerCenter, SSIS e altre;
- soluzioni cloud: Matillion, Panoply e altre.
In forma semplice, il compito si risolve scrivendo un file YML di circa 20 righe. Ci vogliono circa 5 minuti.
Nel caso più complesso, quando è necessario aggiungere una nuova fonte—ad esempio, un nuovo database—può richiedere fino a diversi giorni.
In Profi, this simple task — when the process is well-established — consists of the following steps:
- Determine from the client what data is needed and where it is located.
- Understand if there is access to this data.
- If there is no access, request it from the admins.
- Add a new branch in Git with the code for the task in Jira.
- Create a migration to add data to the anchor model through an interactive Python script.
- Add upload files (YML file describing where the data comes from and into which table it is inserted).
- Test on the staging environment.
- Upload data to the repository.
- Create a pull request.
- Pass the code review.
- After passing the code review, the data is merged into the master branch and automatically deployed to production (CI/CD).
Task 2 — conveniently placing the uploaded data
Another common task is to arrange the uploaded data so that the end user (or BI tool) can work with it conveniently and does not have to perform unnecessary actions to accomplish most tasks. This means building or updating the Dimension Data Store (DDS).
A questo scopo possono essere applicate soluzioni dalla prima attività, poiché si tratta anch'essa di un processo ETL. Nella sua forma più semplice, l'aggiornamento del DDS avviene tramite script SQL.
La terza attività appartiene alla categoria delle attività atipiche.
In Profi sta prendendo forma l'analitica in streaming. Vengono generati un gran numero di eventi dai team di prodotto — li registriamo in ClickHouse. Tuttavia, non è possibile inserire record singolarmente in grande quantità, quindi è necessario raggruppare i record. In altre parole, non si può scrivere direttamente — è necessario un elaboratore intermedio.
Utilizziamo un motore basato su Apache Flink. Al momento, le operazioni procedono così: il motore elabora il flusso di eventi in entrata ⟶ li raggruppa in pacchetti in ClickHouse ⟶ calcola in tempo reale il numero di eventi negli ultimi 15 minuti ⟶ li invia a un servizio che determina se ci sono anomalie — confrontando con i valori degli stessi 15 minuti di 3 mesi fa ⟶ se ci sono anomalie, manda un avviso su Slack.
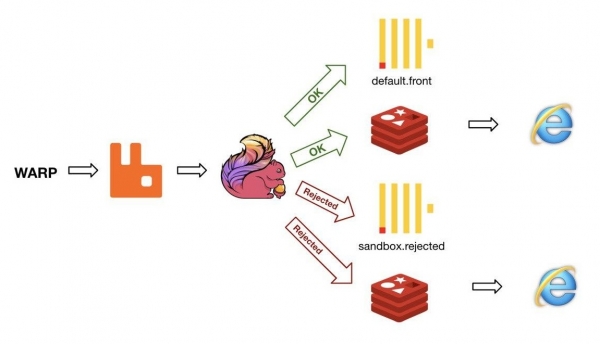
Schema per l'analitica front-end (parte del caricamento)
Il framework Apache Flink garantisce una consegna almeno una volta. Tuttavia, esiste la possibilità di duplicati. Nel caso di RabbitMQ, questo può essere risolto utilizzando il Correlation ID. In questo modo si garantisce una consegna univoca ⟶ integrità dei dati.
Contiamo il numero di eventi ancora una volta con Apache Flink, mostrando i risultati attraverso un dashboard personalizzato, scritto in NodeJS, e un frontend in ReactJS. La ricerca rapida non ha restituito soluzioni simili. Inoltre, il codice è risultato semplice — la scrittura non ha richiesto molto tempo.
Il monitoraggio è piuttosto tecnico. Analizziamo le anomalie per prevenire problemi nelle fasi iniziali. Alcune metriche aziendali significative non sono ancora incluse nel monitoraggio, poiché il settore dell'analisi in streaming è ancora in fase di sviluppo.
Strumenti principali dei data engineer
Le mansioni degli ingegneri dei dati sono piuttosto chiare, ora parliamo degli strumenti utilizzati per affrontarle. Naturalmente, gli strumenti possono (e devono) differire da un'azienda all'altra — tutto dipende dal volume dei dati, dalla loro velocità di arrivo e dalla loro eterogeneità. Può anche dipendere dalla preferenza del professionista per un particolare strumento, solo perché lo ha già utilizzato e lo conosce bene. Noi di Profi.ru abbiamo optato per le seguenti opzioni →
Per la visualizzazione dei dati — Tableau, Metabase
Abbiamo scelto Tableau già da tempo. Questo sistema consente di analizzare rapidamente grandi volumi di dati, senza la necessità di un'implementazione costosa. Per noi è comodo, bello e familiare — lo utilizziamo spesso.
Pochi conoscono Metabase, ma è eccellente per il prototipaggio.
Tra gli strumenti di visualizzazione, vale la pena menzionare Superset di Airbnb. La sua caratteristica principale è la possibilità di connettersi a più database e avere diverse opzioni di visualizzazione. Tuttavia, per l'utente medio è meno intuitivo rispetto a Metabase — non permette di unire tabelle, è necessario creare viste separate.
In Metabase, you can join tables, and moreover, the service does this automatically, considering the database schema. The interface of Metabase is also simpler and more pleasant.
There are many tools available — just find the one that suits you.
For data storage — ClickHouse, Vertica.
ClickHouse is a free and fast tool for storing product events. Analysts can conduct their own analytics (if they have enough data), or data engineers take aggregates and load them into Vertica for building dashboards.
Vertica is a cool and convenient product for displaying final dashboards.
For managing data streams and performing computations — Airflow.
We load data through console tools. For example, using the client that comes with MySQL — this way is faster.
The advantage of console tools is speed. Data is not processed through the memory of the same Python process. On the downside, there's less control over the data that transit between databases.
The primary programming language is Python.
Python ha una soglia di accesso molto più bassa e in azienda abbiamo competenze su questo linguaggio. Un altro motivo è che i DAG di Airflow sono scritti in Python. Questi script sono semplicemente un'interfaccia per i caricamenti, mentre il lavoro principale avviene tramite script da console.
Utilizziamo Java per lo sviluppo di analisi in tempo reale.
L'approccio alla scelta degli strumenti per i dati è come evitare di creare uno zoo tecnologico.
Sul mercato ci sono molti strumenti per lavorare con i dati in ogni fase: dalla loro creazione fino alla visualizzazione nei dashboard per il consiglio di amministrazione. Non sorprende che alcune aziende possano avere una serie di soluzioni non collegate, il cosiddetto zoo tecnologico.
Uno zoo tecnologico è costituito da strumenti che svolgono le stesse funzioni. Ad esempio, Kafka e RabbitMQ per lo scambio di messaggi o Grafana e Zeppelin per la visualizzazione.

— si può notare quanto possano essere numerose le soluzioni duplicate
Molti utenti possono utilizzare vari strumenti ETL per scopi personali. Proprio in Profi si verifica questa situazione. L'ETL principale è su Airflow, ma alcuni utilizzano Pentaho per carichi personali. Testano le ipotesi, e non hanno bisogno di passare questi dati attraverso ingegneri. Principalmente, gli strumenti di "self-service" sono utilizzati da specialisti abbastanza esperti, che si dedicano alla ricerca - esplorano nuove strade per lo sviluppo del prodotto. Il loro insieme di dati per l'analisi è interessante principalmente per loro, e per di più, cambia costantemente. Di conseguenza, non ha senso inserire questi caricamenti nella piattaforma principale.
Tornando allo zoo. Spesso l'uso di tecnologie duplicate è legato al fattore umano. I team interni isolati si sono abituati a lavorare con uno strumento specifico che un altro team potrebbe non utilizzare affatto. E a volte l'autonomia è l'unico modo per affrontare compiti particolari. Ad esempio, un team R&D ha bisogno di testare qualcosa utilizzando uno strumento specifico — è semplicemente comodo, qualcuno nel team lo ha già utilizzato o c'è un'altra ragione. Aspettare che un amministratore di sistema si occupi dell'installazione e della configurazione di questo strumento richiede troppo tempo. Inoltre, gli amministratori attenti e scrupolosi devono ancora dimostrare che sia davvero necessario. Così il team installa lo strumento sulle proprie macchine virtuali e affronta le proprie sfide specifiche.
Uno zoo di soluzioni non è un problema, a patto che non richieda un significativo dispendio di lavoro da parte dell'amministratore per mantenere lo strumento. È importante considerare come l'uso di uno strumento influisce sulle risorse di supporto.
Un'altra comune motivazione per adottare nuovi strumenti è il desiderio di esplorare prodotti sconosciuti in un campo relativamente nuovo, dove gli standard non sono ancora stati definiti o mancano raccomandazioni consolidate. Un data engineer, proprio come uno sviluppatore, deve sempre esaminare nuovi strumenti nella speranza di trovare soluzioni più efficaci per le sfide attuali o per rimanere aggiornato su ciò che offre il mercato.
La tentazione di provare nuovi strumenti è davvero forte. Tuttavia, per fare una scelta consapevole, è soprattutto necessaria la disciplina personale. Questa aiuterà a non lasciarsi trasportare completamente dagli impulsi esplorativi, ma a considerare le capacità dell'azienda di supportare l'infrastruttura per il nuovo strumento.
Non bisogna utilizzare le tecnologie solo per il gusto di farlo. È meglio affrontare la questione in modo pragmatico: compito ⟶ insieme di strumenti che possono risolvere quel compito.
E poi valutare ognuno di essi e scegliere il migliore. Ad esempio, questo strumento può risolvere il compito in modo più efficace, ma non ci sono competenze a riguardo, mentre questo è leggermente meno efficace, ma in azienda ci sono persone che sanno come utilizzarlo. Questo strumento è a pagamento, ma semplice da mantenere e utilizzare, mentre questo è un open source alla moda, ma per supportarlo è necessario avere un team di amministratori. Nascono così delle dicotomie, per risolvere le quali serve un approccio razionale.
La scelta dello strumento è per metà un salto nel vuoto e per metà un'esperienza personale. Non c'è certezza che lo strumento sia adatto.
Ad esempio, in Profi abbiamo iniziato con Pentaho, poiché avevamo competenza su questo strumento, ma alla fine si è rivelata una decisione errata. Il repository interno di Pentaho, man mano che il progetto cresceva, ha cominciato a rallentare significativamente. Il salvataggio dei dati, per dire, richiedeva un minuto, e se si ha l'abitudine di salvare frequentemente, il tempo semplicemente sfuggiva. A questo si aggiungevano avvii complessi e task programmati, il computer si bloccava.
La sofferenza è finita dopo il passaggio a Airflow, uno strumento popolare che ha una grande comunità.
La disponibilità di una community per il servizio, uno strumento utile per affrontare sfide complesse — è possibile chiedere consiglio ai colleghi.
Se l'azienda è matura e dispone di risorse, ha senso considerare l'acquisto del supporto tecnico. Questo aiuterà a risolvere rapidamente i problemi e a ricevere raccomandazioni sull'utilizzo del prodotto.
Parlando dell'approccio alla scelta, in Profi seguiamo i seguenti principi:
- Non decidere da soli. Quando una persona fa una scelta, è automaticamente convinta della sua correttezza. La vera sfida è convincere gli altri, quando è necessario portare argomenti solidi a favore. Questo aiuta anche a identificare i punti deboli dello strumento.
- Consultare il chief data officer (dialogo verticale). Può essere il chief data engineer, il responsabile del team BI. I vertici vedono la situazione in modo più ampio.
- Comunicare con altri team (dialogo orizzontale). Quali strumenti utilizzano e con quanto successo. È possibile che lo strumento dei colleghi possa risolvere anche i vostri problemi, evitando così di creare un 'zoo' di soluzioni.
Competenze interne come una valida alternativa a un fornitore esterno di servizi
Un approccio alla scelta degli strumenti può includere l'utilizzo delle competenze interne dell'azienda.
Spesso si presentano situazioni in cui un'azienda ha un compito complesso, ma non ha i fondi necessari per realizzarlo. Il compito è ampio e importante, e idealmente sarebbe meglio coinvolgere un fornitore di servizi esterno con l'esperienza adeguata. Tuttavia, poiché non ci sono risorse finanziarie disponibili, il compito viene assegnato al team interno. Inoltre, di solito le aziende si fidano di più dei propri dipendenti, se questi hanno già dimostrato la loro efficacia.
Tra gli esempi di compiti in cui una nuova area di business è sviluppata dalle forze interne, ci sono i test di carico e la creazione di un data warehouse. Soprattutto il data warehouse, poiché è una storia unica per ogni azienda. Un data warehouse non può essere acquistato, si possono solo assumere specialisti esterni che lo costruiscano con il supporto del team interno.
A proposito, man mano che la nuova area di business si sviluppa, il team può rendersi conto che non è più necessaria la presenza di un fornitore di servizi esterno.
In Profi, the implementation of BI was done in-house. The main challenge was that the business wanted to launch BI quickly. However, building such a project required time: developing competencies, loading data, creating a convenient storage scheme, selecting tools, and mastering them.
The main — crucial — phase, when everything was built and crystallized, lasted about a year. The project is still evolving.
When building a corporate data warehouse, it is important to adhere to high standards, defend your position, and not cut corners for the sake of the business.
With great difficulty, we had to redo a large part of the project that we had to execute quickly at the time.
But sometimes the 'quick fix' approach is justified. In product development, it can even be the only correct choice. We need to move forward quickly, test product hypotheses, and more. However, the storage must be based on solid architecture; otherwise, it won't adapt quickly to a growing business and the project will stagnate.
In questo progetto complesso, il nostro responsabile ci ha aiutato molto, sostenendo il progresso del lavoro, spiegando alla direzione cosa stiamo facendo, assicurandosi le risorse e semplicemente proteggendoci. Senza un supporto del genere, non sono sicuro che saremmo riusciti a lanciare il progetto.
In queste storie, un ruolo importante è giocato dai cosiddetti early adopters — coloro che sono pronti a provare il nuovo — tra i top manager, analisti e product manager. Per far decollare un argomento ancora grezzo, servono i pionieri che confermino che tutto funziona ed è facile da usare.
Se qualcuno vuole condividere la soluzione del terzo problema descritto sopra — benvenuti 🙂
Fonte: habr.com
