

Сегодня существует 100500 курсов по Data Science и давно известно, что больше всего денег в Data Science можно заработать именно курсами по Data Science (зачем копать, когда можно продавать лопаты?). Основной минус этих курсов в том, что они не имеют ничего общего с реальной работой: никто не даст вам чистые, обработанные данные в нужном формате. И когда вы выходите с курсов и начинаете решать настоящую задачу — всплывает много нюансов.
Поэтому мы начинаем серию заметок «Что может пойти не так с Data Science», основанных на реальных событиях случившихся со мной, моими товарищами и коллегами. Будем разбирать на реальных примерах типичные задачи по Data Science: как это на самом деле происходит. Начнем сегодня с задачи сбора данных.
И первое обо что спотыкаются люди, начав работать с реальными данными — это собственно сбор этих самых релевантных нам данных. Ключевой посыл этой статьи:
Мы систематически недооцениваем время, ресурсы и усилия на сбор, очистку и подготовку данных.
А главное, обсудим, что делать, чтобы этого не допустить.
По разным оценкам, очистка, трансформация, data processing, feature engineering и тд занимают 80-90% времени, а анализ 10-20%, в то время как практически весь учебный материал фокусируется исключительно на анализе.
Давайте разберем как типичный пример простую аналитическую задачу в трех вариантах и увидим, какими бывают «отягчающие обстоятельства».
И для примера опять же, мы рассмотрим подобные вариации задачи сбора данных и сравнения сообществ для:
- Двух сабреддитов Reddit
- Двух разделов Хабра
- Двух групп Одноклассников
Условный подход в теории
Открыть сайт и почитать примеры, если понятно, заложить несколько часов на чтение, несколько часов на код по примерам и отладку. Добавить несколько часов на сбор. Накинуть несколько часов про запас (умножить на два и прибавить N часов).
Ключевой момент: временная оценка основана на предположениях и догадках о том, сколько это займет времени.
Начать анализ времени необходимо с оценки следующих параметров для условной задачи, описанной выше:
- Какой размер данных и сколько его нужно физически собирать (*см ниже*).
- Какое время сбора одной записи и сколько нужно ждать, прежде чем можно собрать вторую.
- Заложить написание кода сохраняющего состояние и начинающего рестарт, когда (а не если) все упадет.
- Разобраться, нужна ли нам авторизация и заложить время получения доступа по API.
- Заложить количество ошибок, как функцию сложности данных — оценить по конкретной задаче: структура, сколько преобразований, что и как экстрактим.
- Заложить ошибки сети и проблемы с нестандартным поведением проекта.
- Оценить, если нужные функции в документации и если нет, то как и сколько нужно для a workaround.
Самое важное, что для оценки времени — вам фактически необходимо потратить время и усилия для «разведки боем» — только тогда ваше планирование будет адекватным. Поэтому как бы вас не пушили сказать «а сколько времени нужно для сбора данных» — выбейте себе времени на предварительный анализ и аргументируйте тем насколько время будет варьироваться в зависимости от реальных параметров задачи.
И сейчас мы продемонстрируем конкретные примеры, где такие параметры и будут меняться.
Ключевой момент: оценка основана на анализе ключевых факторов, влияющих на объем и сложность работы.
Оценка, основанная на догадках — это хороший подход, когда функциональные элементы достаточно небольшие и не так много факторов, которые могут существенно повлиять на структуру задачи. Но в случае ряда задач Data Science таких факторов становится крайне много и подобный подход становится неадекватным.
Сравнение сообществ Reddit
Начнем с самого простого случая (как потом окажется). Вообще, если совсем честно, перед нами практически идеальный случай, проверим наш чеклист сложности:
- Имеется аккуратный, понятный и документированный API.
- Крайне просто и главное автоматически получается токен.
- Есть — с кучей примеров.
- Сообщество которое занимается анализом и сбором данных на реддите (вплоть до youtube роликов объясняющих, как использовать python wrapper) .
- Нужные нам методы скорее всего существуют в API. Более того, код выглядит компактно и чисто, ниже пример функции собирающей комментарии к посту.
def get_comments(submission_id):
reddit = Reddit(check_for_updates=False, user_agent=AGENT)
submission = reddit.submission(id=submission_id)
more_comments = submission.comments.replace_more()
if more_comments:
skipped_comments = sum(x.count for x in more_comments)
logger.debug('Skipped %d MoreComments (%d comments)',
len(more_comments), skipped_comments)
return submission.comments.list()
Взято из подборки удобных утилит для обертки.
Несмотря на то что перед нами самый лучший случай здесь все же стоит учесть ряд важных факторов из реальной жизни:
- Лимиты API — мы вынуждены брать данные батчами (спать между запросами и тд).
- Время сбора — для полного анализа и сравнения придется заложить существенное время просто для паука пройтись по сабреддиту.
- Бот должен крутиться на сервере — вы не можете просто запустить его на ноуте, сложить в рюкзак и поехать по делам. Поэтому я запустил все на VPS. По промокоду habrahabr10 можно сэкономить еще 10% стоимости.
- Физическая недоступность некоторых данных (они видны админам или слишком сложно собираются) — это надо учесть, не все данные в принципе можно собрать за адекватное время.
- Ошибки работы сети: работа с сетью — это боль.
- Это живые настоящие данные — они чистыми не бывают.
Конечно, необходимо заложить в разработку указанные нюансы. Конкретные часы/дни зависят от опыта разработки или опыта работы над подобными задачами, тем не менее мы видим, что здесь задача исключительно инженерная и не требует дополнительных телодвижений для решения — можно все очень хорошо оценить, расписать и сделать.
Сравнение разделов Хабра
Переходим к более интересному и нетривиальному случаю сравнению потоков и/или разделов Хабра.
Проверим наш чеклист сложности — здесь, чтобы понять каждый пункт уже придется немного потыкаться в саму задачу и поэкспериментировать.
- Сначала вы думаете, что есть API, но его нет. Да-да, у Хабра есть API, но только он недоступен для пользователей (а может и совсем не работает).
- Потом просто начинаете парсить html — «import requests», что может пойти не так?
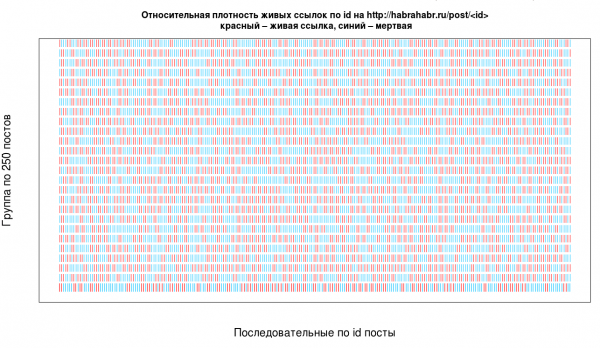
- А как вообще парсить? Самый простой и часто используемый подход — итерировать по ID, отметим, что не самый эффективный и придется обрабатывать разные случаи — вот для примера плотность реальных ID среди всех существующих.

Взято из статьи. - Сырые данные, завернутые в HTML поверх сети — это боль. Например, вы хотите собрать и сохранить рейтинг статьи: выдрали score из html и решили сохранить его как число для дальнейшей обработки:
1) int(score) кидает ошибку: так как на Хабре минус, как, например в строке "–5" — это короткое тире, а не знак минуса (неожиданно, да?), поэтому в какой-то момент пришлось поднимать парсер к жизни вот с таким ужасным фиксом.
try: score_txt = post.find(class_="score").text.replace(u"–","-").replace(u"+","+") score = int(score_txt) if check_date(date): post_score += scoreДаты, плюсов и минусов может вообще не быть (как мы видим выше по функции check_date и такое было).
2) Неэкранированные спецсимволы — они придут, нужно быть готовым.
3) Структура меняется в зависимости от типа поста.
4) Старые посты могут иметь **странную структуру**.
- По сути обработку ошибок и что может или не может произойти придется обрабатывать и нельзя предугадать наверняка, что пойдет не так и как еще может быть структура и что где отвалится — придется просто пробовать и учитывать ошибки, которые бросает парсер.
- Потом вы понимаете, что нужно парсить в несколько потоков иначе парс в один потом займет 30+ часов (это чисто время выполнения уже рабочего однопоточного парсера, который спит и не попадает ни под какие баны). В статье, это привело в какой-то момент к подобной схеме:
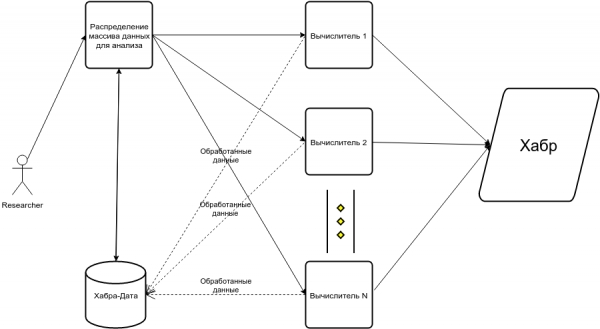
Итого чеклист по сложности:
- Работа с сетью и парсом html с итерацией и перебором по ID.
- Документы неоднородной структуры.
- Много мест, где код может легко упасть.
- Необходимо писать || код.
- Отсутствует нужная документация, примеры кода и/или сообщество.
Условная оценка времени для данной задачи будет в 3-5 раз выше, чем для сбора данных с Реддита.
Сравнение групп Одноклассников
Перейдем к самому технически интересному случаю из описанных. Для меня он был интересен именно тем, что на первый взгляд, он выглядит достаточно тривиальным, но совсем таким не оказывается — как только вы ткнете в него палочкой.
Начнет с нашего чеклиста сложности и отметим, что многие из них окажутся куда сложнее, чем выглядят вначале:
- API есть, но в нем почти полностью отсутствуют нужные функции.
- К определенным функциям нужно просить доступ по почте, то есть выдача доступа не мгновенная.
- Он ужасно документирован (начнем с того, что всюду мешаются русские и английские термины, причем абсолютно непоследовательно — иногда вам нужно просто угадать, что от вас где-то хотят) и, более того, не подходит по дизайну для получения данных, например, .
- Требует сессии в документации, а на деле ее не использует — и нет никакого способа разобраться во всех тонкостях режимов API, кроме как тыкаться и надеяться, что что-то будет работать.
- Отсутствуют примеры и сообщество, единственная точка опоры в сборе информации — небольшой на питоне (без большого количества примеров использования).
- Наиболее рабочим вариантов выглядит Selenium, так как многие нужные данные под замком.
1) То есть идет авторизация через фиктивного пользователя (и регистрация ручками).2) Однако c Selenium никаких гарантий по корректной и повторяемой работе (по крайней в случае с ok.ru точно).
3) Сайт Ок.ру содержит ошибки JavaScript и иногда странно и непоследовательно себя ведет.
4) Нужно заниматься пагинацией, подгрузкой элементов и тд…
5) Ошибки API, которые отдает wrapper придется костыльно обрабатывать, например, вот так (кусочек экспериментального кода):
def get_comments(args, context, discussions): pause = 1 if args.extract_comments: all_comments = set() #makes sense to keep track of already processed discussions for discussion in tqdm(discussions): try: comments = get_comments_from_discussion_via_api(context, discussion) except odnoklassniki.api.OdnoklassnikiError as e: if "NOT_FOUND" in str(e): comments = set() else: print(e) bp() pass all_comments |= comments time.sleep(pause) return all_commentsМоя любимая ошибка была:
OdnoklassnikiError("Error(code: 'None', description: 'HTTP error', method: 'discussions.getComments', params: …)”)6) В конечном итоге вариант Selenium + API выглядит наиболее рациональным вариантом.
- Необходимо сохранение состояния и рестарта системы, обработка множества ошибок, в том числе непоследовательного поведения сайта — причем эти ошибки, которые довольно сложно себе представить (если вы не профессионально пишите парсеры, разумеется).
Условная оценка времени для данной задачи будет в 3-5 раз выше, чем для сбора данных с Хабра. Несмотря на то что в случае с Хабром мы используем лобовой подход с парсом HTML, а в случае с ОК мы можем в критичных местах работать с API.
Выводы
Как бы с вас не требовали оценку сроков «на месте» (у нас же сегодня планирование!) объемного модуля пайплана обработки данных, время выполнения практически никогда невозможно оценить даже качественно без анализа параметров задачи.
Если говорить чуть более философски, то стратегии оценки в agile неплохо подходят для инженерных задач, но с задачами более экспериментальными и, в некотором смысле, «творческими» и исследовательскими, т.е., менее предсказуемыми, возникают трудности, как в примерах подобных тем, что мы разобрали здесь.
Конечно, сбор данных является просто ярким иллюстративным примером — обычно это задача кажется невероятно простой и технически несложной, и именно в деталях здесь чаще всего и таится дьявол. И именно на этой задаче получается показать весь спектр возможных вариантов того, что может пойти не так и насколько именно может затянуться работа.
Если пробежаться краем глаза по характеристикам задачи без дополнительных экспериментов, то Reddit и ОК выглядят похоже: есть API, python wrapper, но по сути, разница огромна. Если судить по этим параметрам, то парс Хабра выглядит сложнее, чем ОК — а на практике это совсем наоборот и именно это можно выяснить, проведя простые эксперименты по анализу параметров задачи.
По моему опыту наиболее эффективным подходом является примерная оценка времени, которая вам потребуется на сам предварительный анализ и простые первые эксперименты, чтение документации — они-то и позволят вам дать точную оценку для всей работы. В терминах популярной методологии agile — я прошу завести мне тикет под “оценку параметров задачи”, на основе которого я могу дать оценку того, что возможно выполнить в рамках “спринта” и дать более точную оценку по каждой задаче.
Поэтому наиболее эффективным, кажется аргумент, который бы показал «нетехническому» специалисту, как сильно будет варьироваться время и ресурсы в зависимости от параметров, которые еще предстоит оценить.
Источник: habr.com
