

Часто люди, заходящие в область Data Science, имеют не совсем реалистичные представления о том, что их ждет. Многие думают, что сейчас они будут круто писать нейросети, создавать голосового помощника из Железного Человека или обыгрывать всех на финансовых рынках.
Но работа Data Scientist завязана на данных, и один из важнейших и время затратных моментов — это обработка данных перед тем, как их подавать в нейросеть или анализировать определенным способом.
В этой статье наша команда опишет то, как можно легко и быстро обработать данные с пошаговой инструкцией и кодом. Мы старались сделать так, чтобы код был довольно гибким и его можно было применять для разных датасетов.
Многие профессионалы возможно и не найдут ничего экстраординарного в этой статье, но начинающие смогут подчерпнуть что-то новое, а также каждый, кто давно мечтал сделать себе отдельный notebook для быстрой и структурированной обработки данных может скопировать код и отформатировать его под себя, или
Получили dataset. Что делать дальше?
Итак, стандарт: нужно понять, с чем имеем дело, общую картину. Для этого используем pandas, чтобы просто определить разные типы данных.
import pandas as pd #импортируем pandas
import numpy as np #импортируем numpy
df = pd.read_csv("AB_NYC_2019.csv") #читаем датасет и записываем в переменную df
df.head(3) #смотрим на первые 3 строчки, чтобы понять, как выглядят значения 
df.info() #Демонстрируем информацию о колонках 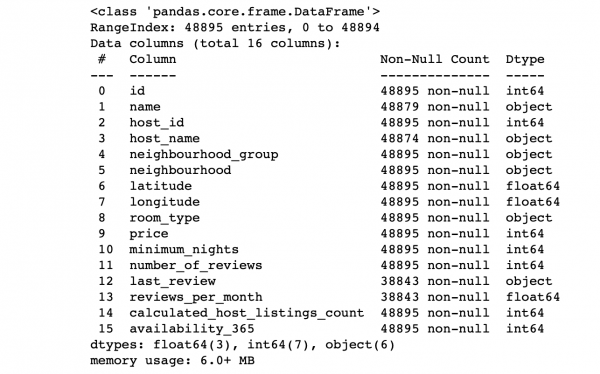
Смотрим на значения колонок:
- Соответсвует ли количество строчек каждой колонки общему количеству строчек?
- Какова суть данных в каждой колонке?
- Какую колонку мы хотим сделать target, чтобы делать предсказания для нее?
Ответы на эти вопросы позволят проанализировать датасет, и примерно нарисовать план ближайших действий.
Также, для более глубокого взгляда на значения в каждой колонке, можем воспользоваться функцией pandas describe(). Правда, недостаток этой функции в том, что она не дает информацию про колонки со значениями string. С ними мы разберемся позже.
df.describe() 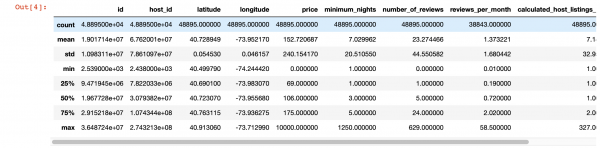
Волшебная визуализация
Посморим на то, где у нас отсутствуют значения вообще:
import seaborn as sns
sns.heatmap(df.isnull(),yticklabels=False,cbar=False,cmap='viridis') 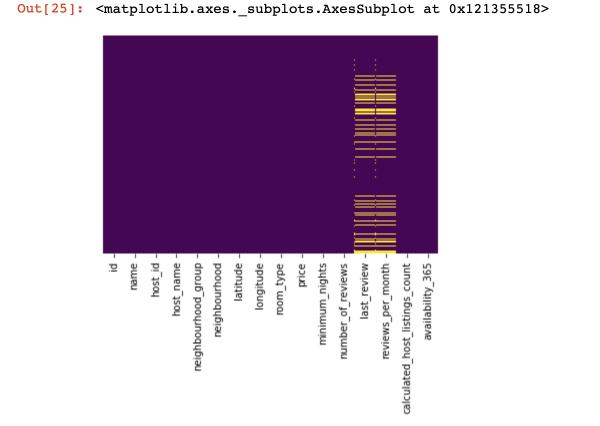
Это был небольшой взгляд сверху, сейчас же мы приступим к более интересным вещам
Попробуем найти и по возможности удалить колонки, в которых есть всего одно значение во всех строчках (они на результат влиять никак не будут):
df = df[[c for c
in list(df)
if len(df[c].unique()) > 1]] #Перезаписываем датасет, оставляя только те колонки, в которых больше одного уникального значенияТеперь предохраняем себя и успех нашего проекта от строк-дубликатов (строк, которые содержат одну и ту же информацию в одном и том же порядке, что и уже одна из существующих строчек):
df.drop_duplicates(inplace=True) #Делаем это, если считаем нужным.
#В некоторых проектах удалять такие данные с самого начала не стоит.Разделяем датасет на два: один с качественными значениями, а другой — с количественными
Здесь нужно сделать небольшое уточнение: если строчки с пропущенными данными у качественных и количественных данных сильно не соотносятся между собой, то нужно будет принять решение, чем мы жертвуем — всеми строчками с пропущенными данными, только их частью или определенными колонками. Если же строчки соотносятся, то мы имеем полное право разделить датасет на два. В противном случае нужно будет сначала разобраться со строчками, в которых не соотносятся пропущенные данные в качественных и количественных, и только потом разделять датасет на два.
df_numerical = df.select_dtypes(include = [np.number])
df_categorical = df.select_dtypes(exclude = [np.number])Мы делаем это, чтобы нам было легче обрабатывать эти два разных типа данных — в последствии мы поймем, насколько это упрощает нам жизнь.
Работаем с количественными данными
Первое, что нам стоит сделать — определить, нет ли «колонок — шпионов» в количественных данных. Мы называем эти колонки так, потому что они выдают себя за количественные данные, а сами работают как качественные.
Как нам их определить? Конечно, все зависит от природы данных, которые Вы анализируете, но в основном такие колонки могут иметь мало уникальных данных (в районе 3-10 уникальных значений).
print(df_numerical.nunique())После того, как мы определимся с колонками-шпионами, мы переместим их из количественных данных в качественные:
spy_columns = df_numerical[['колонка1', 'колока2', 'колонка3']]#выделяем колонки-шпионы и записываем в отдельную dataframe
df_numerical.drop(labels=['колонка1', 'колока2', 'колонка3'], axis=1, inplace = True)#вырезаем эти колонки из количественных данных
df_categorical.insert(1, 'колонка1', spy_columns['колонка1']) #добавляем первую колонку-шпион в качественные данные
df_categorical.insert(1, 'колонка2', spy_columns['колонка2']) #добавляем вторую колонку-шпион в качественные данные
df_categorical.insert(1, 'колонка3', spy_columns['колонка3']) #добавляем третью колонку-шпион в качественные данныеНаконец-то мы полностью отделили количественные данные от качественных и теперь можно с ними как следует поработать. Первое — следует понять, где у нас есть пустые значения (NaN, а в некоторых случаях и 0 будут приниматься как пустые значения).
for i in df_numerical.columns:
print(i, df[i][df[i]==0].count())На этом этапе важно понять, в каких колонках нули могут означать отсутствующие значения: связано ли это с тем, как собирались данные? Или это может быть связано со значениями данных? На эти вопросы нужно отвечать в каждом отдельном случае.
Итак, если мы все-таки решили, что данные у нас могут отсутствовать там, где есть нули, следует заменить нули на NaN, чтобы было легче потом работать с этими утерянными данными:
df_numerical[["колонка 1", "колонка 2"]] = df_numerical[["колонка 1", "колонка 2"]].replace(0, nan)Теперь посмотрим, где у нас пропущены данные:
sns.heatmap(df_numerical.isnull(),yticklabels=False,cbar=False,cmap='viridis') # Можно также воспользоваться df_numerical.info() 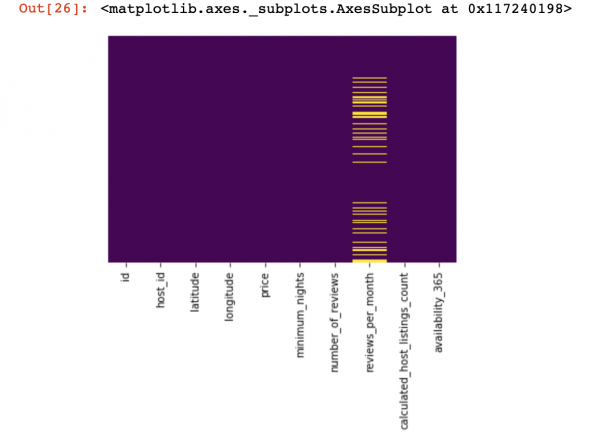
Здесь должны быть отмечены желтым цветом те значения внутри столбцов, которые отсутствуют. И самое интересное начинается теперь — как вести себя с этими значениями? Удалить строчки с этими значениями или столбцы? Или заполнить эти пустые значения какими-нибудь другими?
Вот приблизительная схема, которая может Вам помочь определиться с тем, что можно в принципе сделать с пустыми значениями:
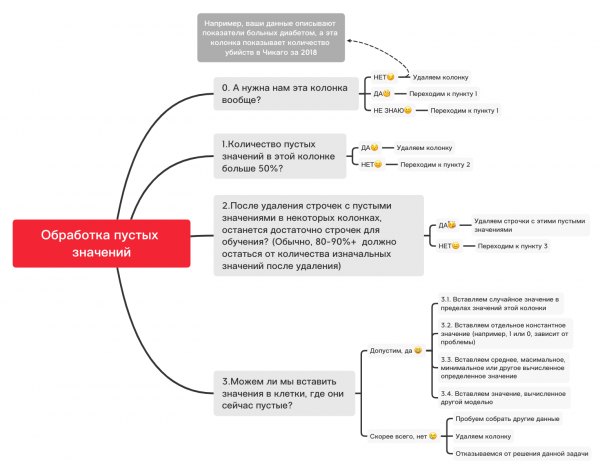
0. Удаляем ненужные колонки
df_numerical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True)1. Количество пустых значений в этой колонке больше 50%?
print(df_numerical.isnull().sum() / df_numerical.shape[0] * 100)df_numerical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True)#Удаляем, если какая-то колонка имеет больше 50 пустых значений2. Удаляем строчки с пустыми значениями
df_numerical.dropna(inplace=True)#Удаляем строчки с пустыми значениями, если потом останется достаточно данных для обучения3.1. Вставляем случайное значение
import random #импортируем random
df_numerical["колонка"].fillna(lambda x: random.choice(df[df[column] != np.nan]["колонка"]), inplace=True) #вставляем рандомные значения в пустые клетки таблицы3.2. Вставляем константное значение
from sklearn.impute import SimpleImputer #импортируем SimpleImputer, который поможет вставить значения
imputer = SimpleImputer(strategy='constant', fill_value="<Ваше значение здесь>") #вставляем определенное значение с помощью SimpleImputer
df_numerical[["новая_колонка1",'новая_колонка2','новая_колонка3']] = imputer.fit_transform(df_numerical[['колонка1', 'колонка2', 'колонка3']]) #Применяем это для нашей таблицы
df_numerical.drop(labels = ["колонка1","колонка2","колонка3"], axis = 1, inplace = True) #Убираем колонки со старыми значениями3.3. Вставляем среднее или макисмально частое значение
from sklearn.impute import SimpleImputer #импортируем SimpleImputer, который поможет вставить значения
imputer = SimpleImputer(strategy='mean', missing_values = np.nan) #вместо mean можно также использовать most_frequent
df_numerical[["новая_колонка1",'новая_колонка2','новая_колонка3']] = imputer.fit_transform(df_numerical[['колонка1', 'колонка2', 'колонка3']]) #Применяем это для нашей таблицы
df_numerical.drop(labels = ["колонка1","колонка2","колонка3"], axis = 1, inplace = True) #Убираем колонки со старыми значениями3.4. Вставляем значение, вычисленное другой моделью
Порой значения можно вычислить с помощью регрессионных моделей, используя модели из библиоткеи sklearn или других похожих библиотек. Наша команда посвятит отдельную статью по тому, как это можно сделать в ближайшем будущем.
Итак, пока повествование о количественных данных прервется, потому что есть множество других нюансов о том, как лучше делать data preparation и preprocessing для разных задач, и базовые вещи для количественных данных были учтены в этой статье, и сейчас самое время вернуться в качественным данным, которые мы отделили несколько шагов назад от количественных. Вы же можете изменять этот notebook так, как Вам угодно, подстраивая его под разные задачи, чтобы data preprocessing проходил очень быстро!
Качественные данные
В основном для качественных данных используется метод One-hot-encoding, для того, чтобы отформатировать их из string (или object) в число. Перед тем как перейти к этому пункту, воспользуемся схемой и кодом сверху, для того, чтобы разобраться с пустыми значениями.
df_categorical.nunique()sns.heatmap(df_categorical.isnull(),yticklabels=False,cbar=False,cmap='viridis') 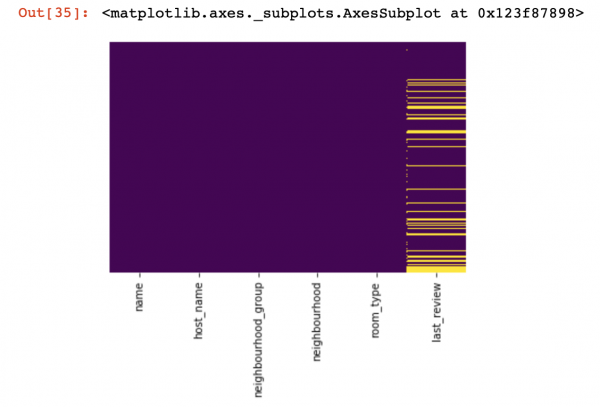
0. Удаляем ненужные колонки
df_categorical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True)1. Количество пустых значений в этой колонке больше 50%?
print(df_categorical.isnull().sum() / df_numerical.shape[0] * 100)df_categorical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True) #Удаляем, если какая-то колонка
#имеет больше 50% пустых значений2. Удаляем строчки с пустыми значениями
df_categorical.dropna(inplace=True)#Удаляем строчки с пустыми значениями,
#если потом останется достаточно данных для обучения3.1. Вставляем случайное значение
import random
df_categorical["колонка"].fillna(lambda x: random.choice(df[df[column] != np.nan]["колонка"]), inplace=True)3.2. Вставляем константное значение
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='constant', fill_value="<Ваше значение здесь>")
df_categorical[["новая_колонка1",'новая_колонка2','новая_колонка3']] = imputer.fit_transform(df_categorical[['колонка1', 'колонка2', 'колонка3']])
df_categorical.drop(labels = ["колонка1","колонка2","колонка3"], axis = 1, inplace = True)Итак, наконец мы разобрались с пустыми значениями в качественнных данных. Теперь время произвести one-hot-encoding для значений, которые есть в вашей базе данных. Этот метод крайне часто используется для того, чтобы Ваш алгоритм мог обучаться с учетом качественных данных.
def encode_and_bind(original_dataframe, feature_to_encode):
dummies = pd.get_dummies(original_dataframe[[feature_to_encode]])
res = pd.concat([original_dataframe, dummies], axis=1)
res = res.drop([feature_to_encode], axis=1)
return(res)features_to_encode = ["колонка1","колонка2","колонка3"]
for feature in features_to_encode:
df_categorical = encode_and_bind(df_categorical, feature))Итак, наконец мы закончили обрабатывать отдельно качественные и количественные данные — время совмещать их обратно
new_df = pd.concat([df_numerical,df_categorical], axis=1)После того, как мы соединили вместе датасеты в один, под конец мы можем использовать трансформацию данных с помощью MinMaxScaler из библиотки sklearn. Это сделает наши значения в пределах от 0 до 1, что поможет при обучении модели в будущем.
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
new_df = min_max_scaler.fit_transform(new_df)Эти данные теперь готовы ко всему — к нейронным сетям, стандартным ML алгоритмам и тд!
В этой статье мы не учли работу с данными, относящимся к временным рядам, так как для таких данных следует использовать немного иные техники их обработки, в зависимости от Вашей задачи. В будущем наша команда посвятит этой теме отдельную статью, и мы надеемся, что она сможет принести в Вашу жизнь что-то интересное, новое и полезное, как и эта.
Источник: habr.com
