

Мы живем в удивительное время, когда можно быстро и просто состыковать несколько готовых открытых инструментов, настроить их с «отключенным сознанием» по советам stackoverflow, не вникая в «многобукв», запустить в коммерческую эксплуатацию. А когда нужно будет обновляться/расширяться или кто-то случайно перезагрузит пару машин — осознать, что начался какой-то навязчивый дурной сон наяву, все резко усложнилось до неузнаваемости, пути назад нет, будущее туманно и безопаснее, вместо программирования, разводить пчел и делать сыр.
Не зря же, более опытные коллеги, с посыпанной багами и от этого уже седой головой, созерцая неправдоподобно быстрое развертывание пачек «контейнеров» в «кубиках» на десятках серверов на «модных языках» со встроенной поддержкой асинхронно-неблокирующего ввода-вывода — скромно улыбаются. И молча продолжают перечитывать «man ps», вникают до кровоточения из глаз в исходники «nginx» и пишут-пишут-пишут юнит-тесты. Коллеги знают, что самое интересное будет впереди, когда «всё это» однажды станет ночью колом под Новый год. И им поможет только глубокое понимание природы unix, заученной таблицы состояний TCP/IP и базовых алгоритмов сортировки-поиска. Чтобы под бой курантов возвращать систему к жизни.
Ах да, немного отвлекся, но состояние предвкушения, надеюсь, получилось передать.
Сегодня я хочу поделиться нашим опытом развертывания удобного и недорогого стека для DataLake, решающего большинство аналитических задач в компании для совершенно разных структурных подразделений.
Некоторое время назад мы пришли к пониманию, что компании все сильнее и сильнее нужны плоды как продуктовой, так и технической аналитики (не говоря уже о вишенках на торте в виде machine learning) и для понимания трендов и рисков — нужно собирать и анализировать все больше и больше метрик.
Базовая техническая аналитика в «Битрикс24»
Несколько лет назад, одновременно с запуском сервиса «Битрикс24», мы активно инвестировали время и ресурсы в создание простой и надежной аналитической платформы, которая бы помогала быстро увидеть проблемы в инфраструктуре и спланировать ближайший шаг. Разумеется, инструменты желательно было взять готовые и максимально простые и понятные. В результате был выбран nagios для мониторинга и munin для аналитики и визуализации. Теперь у нас тысячи проверок в nagios, сотни графиков в munin и коллеги ежедневно и успешно ими пользуются. Метрики понятны, графики ясны, система работает надежно уже несколько лет и в нее регулярно добавляются новые тесты и графики: вводим новый сервис в эксплуатацию — добавляем несколько тестов и графиков. В добрый путь.
Рука на пульсе — расширенная техническая аналитика
Желание получать информацию о проблемах «как можно быстрее» привело нас к активным экспериментам с простыми и понятными инструментами — pinba и xhprof.
Pinba отправляла нам в UDP-пакетиках статистику о скорости работы частей веб-страниц на PHP и можно было в режиме онлайн видеть в хранилище MySQL (c pinba идет свой движок MySQL для быстрой аналитики событий) короткий список проблем и реагировать на них. А xhprof в автоматическом режиме позволял собирать графы выполнения наиболее медленных PHP-страниц у клиентов и анализировать, что к этому могло привести — спокойно, налив чай или чего-нибудь покрепче.
Некоторое время назад инструментарий был пополнен еще одним довольно простым и понятным движком на основе алгоритма обратной индексации, отлично реализованном в легендарной библиотеке Lucene — Elastic/Kibana. Простая идея многопоточной записи документов в инверсный индекс Lucene на базе событий в логах и быстрый поиск по ним с использованием фасетного деления — оказалась, и правда, полезна.
Несмотря на довольно технический вид визуализаций в Kibana с «протекающими вверх» низкоуровневыми концепциями типа «bucket» и заново изобретенный язык совсем еще не забытой реляционной алгебры — инструмент стал хорошо нам помогать в следующих задачах:
- Сколько было ошибок PHP у клиента Битрикс24 на портале p1 за последний час и каких? Понять, простить и быстро исправить.
- Сколько было совершено видео-звонков на порталах в Германии за предыдущие 24 часа, с каким качеством и были ли сложности с каналом/сетью?
- Насколько хорошо работает системный функционал (наше расширение на C для PHP), скомпилированный из исходников в последнем обновлении сервиса и раскатанный клиентам? Нет ли segfaults?
- Помещаются ли данные клиентов в память PHP? Нет ли ошибок превышения выделенной процессам памяти: «out of memory»? Найти и обезвредить.
Вот конкретный пример. Несмотря на тщательное и многоуровневое тестирование, у клиента, при очень нестандартном кейсе и поврежденных входных данных появилась досадная и неожиданная ошибка, зазвучала сирена и начался процесс ее быстрого исправления:
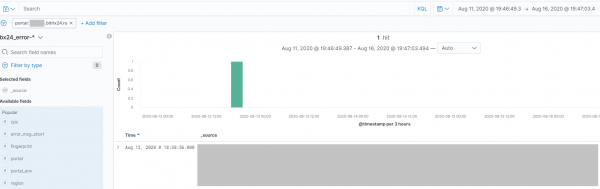
Дополнительно, kibana позволяет организовать оповещение по указанным событиям и за короткое время инструментом в компании стали пользоваться десятки сотрудников из разных подразделений — от техподдержки и разработки до QA.
Активность любого подразделения внутри компании стало удобно отслеживать и измерять — вместо ручного анализа логов на серверах, достаточно один раз настроить парсинг логов и их отправку в кластер elastic, чтобы наслаждаться, например, созерцанием в дашборде kibana числа проданных двухголовых котят, напечатанных на 3-d принтере за прошлый лунный месяц.
Базовая бизнес-аналитика
Все знают, что часто бизнес-аналитика в компаниях начинается с экстремально активного использования, да, да, Excel. Но, главное, чтобы она в нем не заканчивалась. Масло в огонь еще хорошо подливает облачный Google Analytics — к хорошему начинаешь быстро привыкать.
В нашей, гармонично развивающейся компании, стали то тут, то там, появляться «пророки» более интенсивной работы с более крупными данными. Регулярно стали появляться потребности в более глубоких и многогранных отчетах и усилиями ребят из разных подразделений некоторое время назад было организовано простое и практичное решение — связка ClickHouse и PowerBI.
Довольно долгое время это гибкое решение отлично помогало, но постепенно стало приходить понимание, что ClickHouse — не резиновый и нельзя над ним так издеваться.
Тут важно хорошо понять, что ClickHouse, как и Druid, как и Vertica, как и Amazon RedShift (который на базе postgres), это аналитические движки, оптимизированные на довольно удобную аналитику (суммы, агрегации, минимум-максимум по колонке и немножно можно джойнов), т.к. организованы для эффективного хранения колонок реляционных таблиц, в отличие от известного нам MySQL и других (row-oriented) баз данных.
По сути, ClickHouse лишь более вместимая «базка» данных, с не очень удобной точечной вставкой (так задумано, все ок), но приятной аналитикой и набором интересных мощных функций по работе с данными. Да, можно даже создать кластер — но, вы понимаете, что забивать гвозди микроскопом не совсем правильно и мы начали искать другие решения.
Спрос на python и аналитиков
В нашей компании много разработчиков, которые пишут код почти каждый день на протяжении 10-20 лет на PHP, JavaScript, C#, C/С++, Java, Go, Rust, Python, Bash. Также много опытных системных администраторов, переживших не одну совершенно невероятную катастрофу, не вписывающуюся в законы статистики (например, когда уничтожается большинство дисков в raid-10 при сильном ударе молнии). В таких условиях долгое время было непонятно, что такое «аналитик на python». Python же как PHP, только название чуть длиннее и следов веществ, изменяющих сознание, в исходном коде интерпретатора немного поменьше. Однако, по мере создания все новых и новых аналитических отчетов опытные разработчики все глубже стали осознавать важность узкой специализации в инструментах типа numpy, pandas, matplotlib, seaborn.
Решающую роль, скорее всего, сыграли внезапные обмороки сотрудников от сочетания слов «логистическая регрессия» и демонстрация эффективного построения отчетов на объемных данных с помощью да, да, pyspark.
Apache Spark, его функциональная парадигма, на которую отлично ложится реляционная алгебра и возможности произвели такое впечатление на разработчиков, привыкших к MySQL, что необходимость укрепления боевых рядов опытными аналитиками стала ясной, как день.
Дальнейшие попытки Apache Spark/Hadoop взлететь и что пошло не совсем по сценарию
Однако, вскоре стало понятно, что со Spark, видимо, что-то системно не совсем так или нужно просто лучше мыть руки. Если стек Hadoop/MapReduce/Lucene делали достаточно опытные программисты, что очевидно, если с пристрастием посмотреть исходники на Java или идеи Дуга Каттинга в Lucene, то Spark, внезапно, написан на очень спорном с точки зрения практичности и сейчас не развивающемся экзотическом языке Scala. А регулярное падение вычислений на кластере Spark из-за нелогичной и не очень прозрачной работы с выделением памяти под операции reduce (прилетает сразу много ключей) — создало вокруг него ореол чего-то, которому есть куда расти. Дополнительно ситуацию усугубляло большое количество странных открытых портов, временных файлов, растущих в самых непонятных местах и ад jar-зависимостей — что вызывало у системных администраторов одно и хорошо знакомое с детства чувство: лютую ненависть (а может нужно было мыть руки с мылом).
Мы, в результате, «пережили» несколько внутренних аналитических проектов, активно использующих Apache Spark (в т.ч. Spark Streaming, Spark SQL) и экосистему Hadoop (и прочая и прочая). Несмотря на то, что со временем научились «это» неплохо готовить и мониторить и «оно» практически перестало внезапно падать из-за изменения характера данных и дизбалансировки равномерного хэширования RDD, желание взять что-то уже готовое, обновляемое и администрируемое где-то в облаке усиливалось все сильнее и сильнее. Именно в это время мы попробовали использовать готовую облачную сборку Amazon Web Services — и, в последствии, старались решать задачи уже на ней. EMR это приготовленный амазоном Apache Spark с дополнительным софтом из экосистемы, примерно как Cloudera/Hortonworks сборки.
«Резиновое» файловое хранилище для аналитики — острая потребность
Опыт «приготовления» Hadoop/Spark с ожогами разных частей тела не прошел даром. Стала все четче вырисовываться необходимость создания единого недорогого и надежного файлового хранилища, которое было бы устойчиво к аппаратным авариям и в котором можно было бы хранить файлы в разном формате из разных систем и делать по этим данным эффективные и в разумное время выполняемые выборки для отчетов.
Также хотелось, чтобы обновление софта этой платформы не превращалось в новогодний ночной кошмар с чтением 20-страничных Java трейсов и анализ километровых подробных логов работы кластера с помощью Spark History Server и лупы с подсветкой. Хотелось иметь простой и прозрачный инструмент, который не требует регулярного ныряния под капот, если у разработчика перестал выполняться стандартный MapReduce запрос при выпадении из памяти воркера reduce-данных при не очень удачно выбранном алгоритме партиционирования исходных данных.
Amazon S3 — кандидат на DataLake?
Опыт работы с Hadoop/MapReduce научил тому, что нужна и масштабируемая надежная файловая система и над ней масштабируемые воркеры, «приходящие» поближе к данным, чтобы не гонять данные по сети. Воркеры должны уметь читать данные в разных форматах, но, желательно, не читать лишнюю информацию и чтобы можно было заранее хранить данные в удобных для воркеров форматах.
Еще раз — основная идея. Нет желания «заливать» большие данные в единый кластерный аналитический движок, который все равно рано или поздно захлебнется и придется его некрасиво шардить. Хочется хранить файлы, просто файлы, в понятном формате и выполнять по ним эффективные аналитические запросы разными, но понятными инструментами. И файлов в разных форматах будет все больше и больше. И лучше шардить не движок, а исходные данные. Нам нужен расширяемый и универсальный DataLake, решили мы…
А что если хранить файлы в привычном и многим известном масштабируемом облачном хранилище Amazon S3, не занимаясь собственным приготовлением отбивных из Hadoop?
Понятно, персданные «низя», но другие данные если туда вынести и «эффективно погонять»?
Кластерно-бигдата-аналитическая экосистема Amazon Web Services — очень простыми словами
Судя по нашему опыту работы с AWS, там давно и активно используется под разными соусами Apache Hadoop/MapReduce, например в сервисе DataPipeline (завидую коллегам, вот научились же его правильно готовить). Вот тут мы настроили бэкапы из разных сервисов из таблиц DynamoDB:
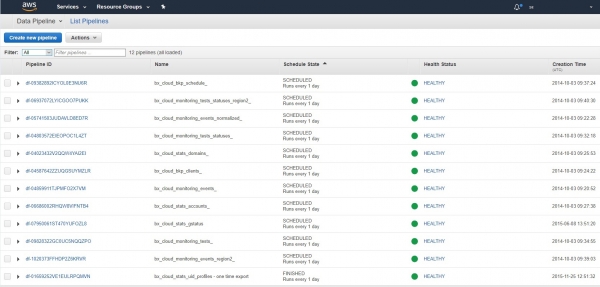
И они регулярно выполняются на встроенных кластерах Hadoop/MapReduce как часы уже несколько лет. «Настроил и забыл»:
Также, можно эффективно заниматься датасатанизмом, подняв для аналитиков Jupiter-ноутбуки в облаке и использовать для обучения и деплоинга AI-моделей в бой сервис AWS SageMaker. Вот как это выглядит у нас:
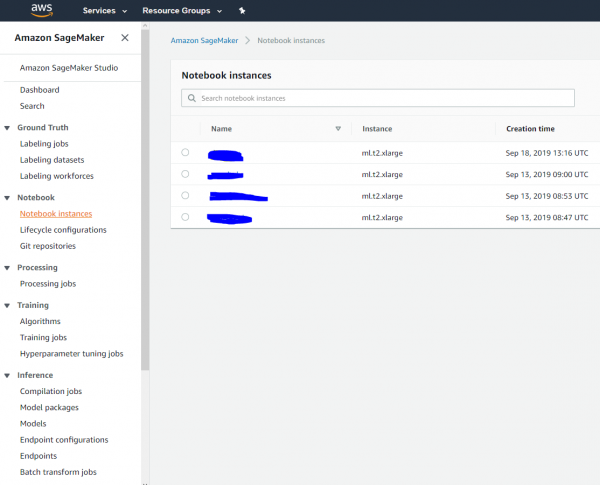
И да, можно поднять себе или аналитику ноутбук в облаке и прицепить его к Hadoop/Spark кластеру, посчитать и все потом «прибить»:
Действительно удобно для отдельных аналитических проектов и для некоторых мы успешно использовали сервис EMR для масштабных обсчетов и аналитики. А что насчет системного решения для DataLake, получится ли? В этот момент мы были на грани надежды и отчаяния и продолжали поиск.
AWS Glue — аккуратно упакованный Apache Spark «на стероидах»
Оказалось, что в AWS есть «своя» версия стека «Hive/Pig/Spark». Роль Hive, т.е. каталог файлов и их типов в DataLake выполняет сервис «Data catalog», который и не скрывает о своей совместимости с форматом Apache Hive. В этот сервис нужно добавить информацию о том, где лежат ваши файлы и в каком они формате. Данные могут быть не только в s3, но и в базе данных, но об этом не в этом посте. Вот как каталог данных DataLake организован у нас:
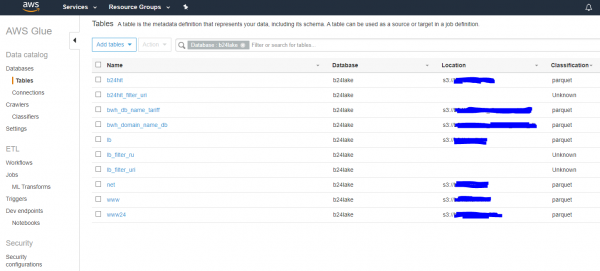
Файлы зарегистрированы, отлично. Если файлы обновились — запускаем либо руками либо по расписанию crawlers, которые обновят о них из озера информацию и сохранят. Дальше данные из озера можно обрабатывать и результаты куда-то выгружать. В самом простом случае — выгружаем тоже в s3. Обработку данных можно делать где угодно, но предлагается настроить процесс обработки на кластере Apache Spark с использованием расширенных возможностей через API AWS Glue. По сути, можно взять старый добрый и привычный код на python с использованием библиотечки pyspark и настроить его выполнение на N нодах кластера какой-то мощности с мониторингом, без копания в потрохах Hadoop и таскания докер-мокер контейнеров и устранения конфликтов зависимостей.
Еще раз — простая идея. Не нужно настраивать Apache Spark, нужно лишь написать код на python для pyspark, протестировать его локально на рабочем столе и затем запустить на большом кластере в облаке, указав где лежат исходные данные и куда положить результат. Иногда это нужно и полезно и вот как это настроено у нас:
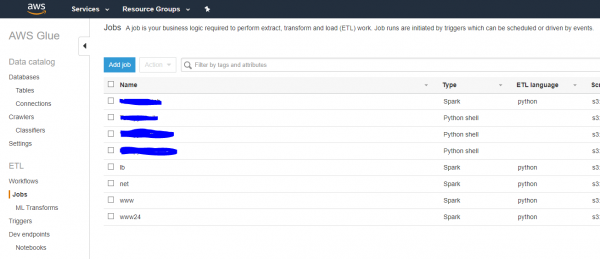
Таким образом, если нужно что-то обсчитать на Spark-кластере на данных в s3 — пишем на python/pyspark код, тестируем и в добрый путь в облако.
А что с оркестровкой? А если задание упало и пропало? Да, предлагается сделать красивый пайплайн в стиле Apache Pig и мы даже попробовали их, но решили пока использовать свою глубоко кастомизированную оркестровку на PHP и JavaScript (я понимаю, возникает когнитивный диссонанс, но работает, годами и без ошибок).
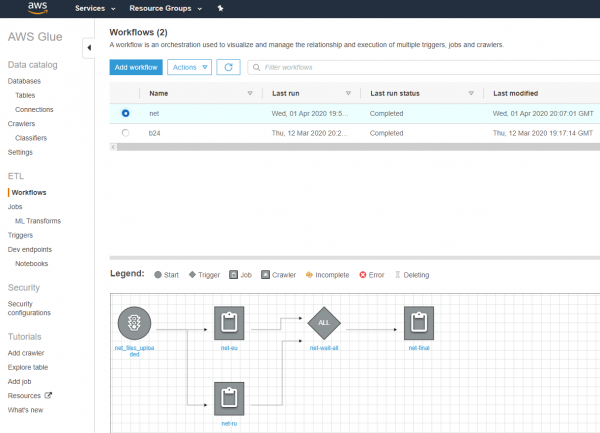
Формат хранимых в озере файлов — ключ к производительности
Очень, очень важно понять еще два ключевых момента. Чтобы запросы по данным файлов в озере выполнялись максимально быстро и производительность не деградировала при добавлении новой информации, нужно:
- Колонки файлов хранить отдельно (чтобы не нужно было прочитать все строки, чтобы понять, что в колонках). Для этого мы взяли формат parquet с сжатием
- Очень важно шардировать файлы по папочкам в духе: язык, год, месяц, день, неделя. Движки, понимающие этот тип шардирования, будут смотреть только в нужные папочки, не перелопачивая через себя все данные подряд.
По сути, таким способом, вы выкладываете в наиболее эффективном виде исходные данные для навешиваемых сверху аналитических движков, которые и в шардированные папочки умеют избирательно заходить и читать из файлов только нужные колонки. Не нужно никуда, получатся, «заливать» данные (хранилище же просто лопнет) — просто сразу разумно их положите в файловую систему в правильном формате. Разумеется, тут должно быть понятно, что хранить в DataLake огромный csv-файл, который нужно сначала весь построчно прочитать кластером, чтобы извлечь колонки — не очень целесообразно. Подумайте над двумя вышеуказанными пунктами еще раз, если пока непонятно зачем все это.
AWS Athena — «черт» из табакерки
И тут, создавая озеро, мы, как-то мимоходом, наткнулись на Amazon Athena. Внезапно оказалось, что аккуратно сложив по шардам-папочкам в правильном (parquet) колоночном формате наши файлы огромных логов — можно очень быстро по ним делать крайне информативные выборки и строить отчеты БЕЗ, без Apache Spark/Glue кластера.
Движок Athena, работающий на данных в s3, основан на легендарном — представителе семейства MPP (massive parallel processing) подходов к обработке данных, берущий данные там, где они лежат, от s3 и Hadoop до Cassandra и обычных текстовых файликов. Нужно просто попросить Athena выполнить SQL-запрос, а дальше все «работает быстро и само». Важно отметить, что Athena «умная», ходит только в нужные шардированные папочки и считывает только нужные в запросе колонки.
Тарифицируются запросы к Athena тоже интересно. Мы платим за . Т.е. не за число машин в кластере поминутно, а… за реально просканированные на 100-500 машинах только необходимые для выполнения запроса данные.
А запрашивая только нужные колонки из правильно шардированных папочек, оказалось, что сервис Athena нам обходится в десятки долларов месяц. Ну прекрасно же, почти бесплатно, по сравнению с аналитикой на кластерах!
Вот, кстати, как мы шардируем свои данные в s3:
В результате, за короткое время, в компании совершенно разные подразделения, от информационной безопасности до аналитики, стали активно делать запросы к Athena и быстро, за секунды, получать полезные ответы из «больших» данных за довольно большие периоды: месяцы, полугодие и т.п.
Но мы пошли дальше и стали ходить за ответами в облако : аналитик в привычной консоли пишет SQL-запрос, который на 100-500 машинах «за копейки» шерстит данные в s3 и возвращает ответ обычно за единицы секунд. Удобно. И быстро. До сих пор не верится.
В итоге, приняв решение хранить данные в s3, в эффективном колоночном формате и с разумным шардированием данных по папочкам… мы получили DataLake и быстрый и дешевый аналитический движок — бесплатно. И он стал очень популярным в компании, т.к. понимает SQL и работает на порядки быстрее, чем через запуски/остановки/настройки кластеров. «А если результат одинаковый, зачем платить больше?»
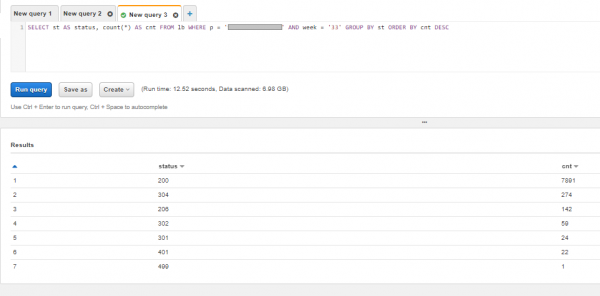
Запрос к Athena выглядит примерно так. При желании, конечно, можно сформировать достаточно , но мы ограничимся простой группировкой. Посмотрим, какие коды ответов были у клиента несколько недель назад в логах работы веб-сервера и убедимся, что ошибок нет:
Выводы
Пройдя, не сказать что долгий, но болезненный путь, постоянно адекватно оценивая риски и уровень сложности и стоимость поддержки, мы нашли решение для DataLake и аналитики, которое нас не перестает радовать как скоростью, так и стоимостью владения.
Оказалось, что построить эффективное, быстрое и дешевое в эксплуатации DataLake для нужд совершенно разных подразделений компании — совершенно по силам даже опытным разработчикам, никогда не работающим архитекторами и не умеющим рисовать квадратики на квадратиках со стрелочками и знающим 50 терминов из экосистемы Hadoop.
В начале пути голова раскалывалась от множества дичайших зоопарков открытого и закрытого софта и понимания груза ответственности перед потомками. Просто начинайте строить свой DataLake от простых инструментов: nagios/munin -> elastic/kibana -> Hadoop/Spark/s3 …, собирая обратную связь и глубоко понимая физику происходящих процессов. Все сложное и мутное — отдавайте врагам и конкурентам.
Если вы не хотите в облако и любите поддерживать, обновлять и патчить открытые проекты, можно построить аналогичную нашей схему локально, на офисных недорогих машинках с Hadoop и Presto сверху. Главное — не останавливаться и идти вперед, считать, искать простые и ясные решения и все обязательно получится! Удачи всем и до новых встреч!
Источник: habr.com
