


В Linux есть большое количество инструментов для отладки ядра и приложений. Большинство из них негативно сказываются на производительности приложений и не могут быть использованы в продакшене.
Пару лет назад был — eBPF. Он дает возможность трассировать ядро и пользовательские приложения с низким оверхедом и без необходимости пересборки программ и загрузки сторонних модулей в ядро.
Сейчас уже существует множество прикладных утилит, которые используют eBPF, и в этой статье мы рассмотрим, как написать собственную утилиту для профилирования на основе библиотеки . Статья основана на реальных событиях. Мы пройдем путь от появления проблемы и до её исправления, чтобы показать, как могут быть использованы уже существующие утилиты в конкретных ситуациях.
Ceph Is Slow
В кластер Ceph добавили новый хост. После миграции части данных на него мы заметили, что скорость обработки запросов на запись им гораздо ниже, чем на других серверах.
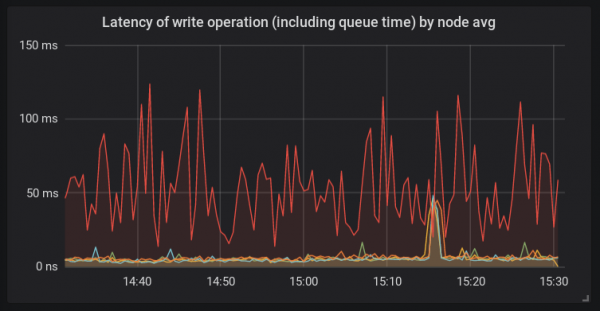
В отличие от других платформ, на этом хосте использовался bcache и новое ядро linux 4.15. Хост такой конфигурации использовался здесь впервые. И на тот момент было ясно, что корнем проблемы теоретически могло быть что угодно.
Investigating the Host
Начнем с того, что посмотрим, что происходит внутри процесса ceph-osd. Для этого воспользуемся и (подробнее о которых можно прочитать ):

Картинка говорит нам о том, что функция fdatasync() потратила много времени при отправке запроса в функции generic_make_request(). Значит, что скорее всего, причина проблем где-то вне самого демона osd. Это может быть либо ядро, либо диски. Вывод iostat показывал высокую задержку обработки запросов bcache-дисками.
При проверке хоста мы обнаружили, что демон systemd-udevd потребляет большое количество времени CPU — около 20% на нескольких ядрах. Это странное поведение, так что нужно выяснить его причину. Так как Systemd-udevd работает с uevent’ами, мы решили посмотреть на них через udevadm monitor. Оказывается, генерировалось большое количество change-событий для каждого блочного устройства в системе. Это довольно необычно, поэтому нужно будет посмотреть, что генерирует все эти ивенты.
Using the BCC Toolkit
Как мы уже выяснили, ядро (и демон ceph в системном вызове) тратит много времени в generic_make_request(). Попробуем замерить скорость работы этой функции. В уже есть замечательная утилита — funclatency. Мы будем трассировать демон по его PID с интервалом между выводами информации в 1 секунду и выводить результат в миллисекундах.
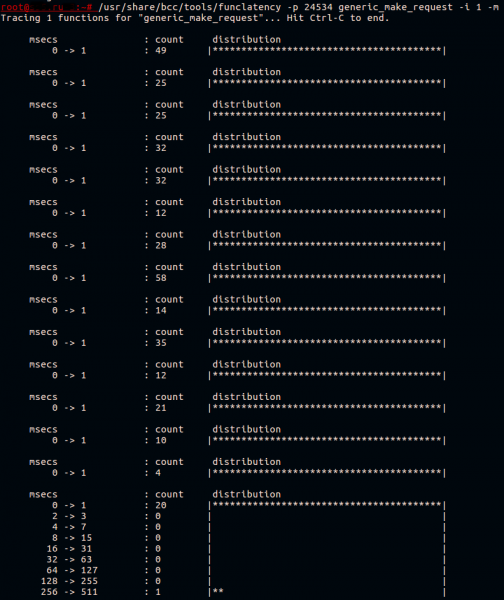
Обычно эта функция работает быстро. Все, что она делает — передает запрос в очередь драйвера устройства.
Bcache — это сложное устройство, которое на самом деле состоит из трех дисков:
- backing device (кешируемый диск), в данном случае это медленный HDD;
- caching device (кеширующий диск), здесь это один раздел NVMe устройства;
- виртуальный девайс bcache, с которым работает приложение.
Мы знаем, что передача запроса тормозит, но для какого из этих устройств? Разберемся с этим чуть позже.
Сейчас мы знаем, что uevent’ы, вероятно, приводят к проблемам. Найти, что именно вызывает их генерацию, не так просто. Предположим, что это какой-то софт, запускаемый периодически. Посмотрим, что за софт запускается в системе, с помощью скрипта execsnoop из того же . Запустим его и направим вывод в файл.
Например вот так:
/usr/share/bcc/tools/execsnoop | tee ./execdump
Не будем здесь приводить полный вывод execsnoop, но одна интересующая нас строка выглядела вот так:
sh 1764905 5802 0 sudo arcconf getconfig 1 AD | grep Temperature | awk -F '[:/]' '{print $2}' | sed 's/^ ([0-9]*) C.*/1/'
Третья колонка это PPID (parent PID) процесса. Процессом с PID 5802 оказался один из потоков нашей системы мониторинга. При проверке конфигурации системы мониторинга были найдены ошибочно заданные параметры. Температура HBA-адаптера снималась раз в 30 секунд, что гораздо чаще, чем необходимо. После изменения интервала проверки на более длительный, мы обнаружили, что задержка обработки запросов на этом хосте перестала выделятся на фоне остальных хостов.
Но всё ещё непонятно, почему bcache-устройство так тормозило. Мы подготовили тестовую платформу с идентичной конфигурацией и попробовали воспроизвести проблему, запустив fio на bcache, периодически запуская udevadm trigger для генерации uevents.
Writing BCC-Based Tools
Попробуем написать простую утилиту для трассировки и вывода на экран наиболее медленных вызовов generic_make_request(). Нас также интересует имя диска, для которого была вызвана эта функция.
План прост:
- Регистрируем kprobe на generic_make_request():
- Сохраняем в память имя диска, доступное через аргумент функции;
- Сохраняем метку времени.
- Регистрируем kretprobe на возврат из generic_make_request():
- Получаем текущую метку времени;
- Ищем сохраненную метку времени и сравниваем с текущей;
- Если результат больше заданного, то находим сохраненное имя диска и выводим на терминал.
Kprobes и kretprobes используют механизм точек останова для изменения кода функций на лету. Вы можете прочитать и статью на эту тему. Если взглянуть на код различных утилит в , то можно заметить, что у них идентичная структура. Так что в этой статье мы опустим парсинг аргументов скрипта и перейдем к самой BPF программе.
Текст eBPF внутри python-скрипта выглядит следующим образом:
bpf_text = “”” # Here will be the bpf program code “””
Для обмена данными между функциями, eBPF программы используют . Так поступим и мы. В качестве ключа будем использовать PID процесса, а в качестве значения определим структуру:
struct data_t {
u64 pid;
u64 ts;
char comm[TASK_COMM_LEN];
u64 lat;
char disk[DISK_NAME_LEN];
};
BPF_HASH(p, u64, struct data_t);
BPF_PERF_OUTPUT(events);
Здесь мы регистрируем хэш-таблицу, которая называется p, с ключом типа u64 и значением типа struct data_t. Таблица будет доступна в контексте нашей BPF-программы. Макрос BPF_PERF_OUTPUT регистрирует другую таблицу, называемую events, которая используется для в пространство пользователя.
При измерении задержек между вызовом функции и возвратом из нее, либо между вызовами разных функций, нужно учитывать, что полученные данные должны принадлежать одному контексту. Другими словами, нужно помнить о возможном параллельном запуске функций. У нас есть возможность измерить задержку между вызовом функции в контексте одного процесса и возвратом из этой функции в контексте другого процесса, но это, скорее всего, бесполезно. Хорошим примером здесь может служить , где в качестве ключа хэш-таблицы задается указатель на struct request, которая отражает один запрос к диску.
Далее нам нужно написать код, который будет запускаться при вызове исследуемой функции:
void start(struct pt_regs *ctx, struct bio *bio) {
u64 pid = bpf_get_current_pid_tgid();
struct data_t data = {};
u64 ts = bpf_ktime_get_ns();
data.pid = pid;
data.ts = ts;
bpf_probe_read_str(&data.disk, sizeof(data.disk), (void*)bio->bi_disk->disk_name);
p.update(&pid, &data);
}
Здесь в качестве второго аргумента будет подставлен первый аргумент вызванной функции . После этого мы получаем PID процесса, в контексте которого работаем, и текущую временную метку в наносекундах. Записываем это всё в свежевыделенную struct data_t data. Имя диска мы получаем из структуры bio, которая передается при вызове generic_make_request(), и сохраняем его в ту же структуру data. Последним шагом добавляем запись в хэш-таблицу, о которой было сказано ранее.
Следующая функция будет вызываться на возврате из generic_make_request():
void stop(struct pt_regs *ctx) {
u64 pid = bpf_get_current_pid_tgid();
u64 ts = bpf_ktime_get_ns();
struct data_t* data = p.lookup(&pid);
if (data != 0 && data->ts > 0) {
bpf_get_current_comm(&data->comm, sizeof(data->comm));
data->lat = (ts - data->ts)/1000;
if (data->lat > MIN_US) {
FACTOR
data->pid >>= 32;
events.perf_submit(ctx, data, sizeof(struct data_t));
}
p.delete(&pid);
}
}
Эта функция схожа с предыдущей: узнаем PID процесса и временную метку, но не выделяем память под новую структуру data. Вместо этого мы ищем в хэш-таблице уже существующую структуру по ключу == текущий PID. Если структура нашлась, то мы узнаем имя запущенного процесса и добавляем его в неё.
Бинарный сдвиг, который мы здесь используем, нужен для того, чтобы получить thread GID. т.е. PID основного процесса, который запустил поток, в контексте которого мы работаем. Вызываемая нами функция возвращает как GID треда, так и его PID в одном 64-битном значении.
При выводе в терминал нас сейчас не интересует поток, но интересует основной процесс. После сравнения полученной задержки с заданным порогом, мы передаем нашу структуру data в пространство пользователя через таблицу events, после чего удаляем запись из p.
В python-скрипте, который будет загружать данный код, нам необходимо заменить MIN_US и FACTOR на пороги задержки и единицы времени, которые мы передадим через аргументы:
bpf_text = bpf_text.replace('MIN_US',str(min_usec))
if args.milliseconds:
bpf_text = bpf_text.replace('FACTOR','data->lat /= 1000;')
label = "msec"
else:
bpf_text = bpf_text.replace('FACTOR','')
label = "usec"
Теперь нам нужно подготовить BPF программу через и зарегистрировать пробы:
b = BPF(text=bpf_text)
b.attach_kprobe(event="generic_make_request",fn_name="start")
b.attach_kretprobe(event="generic_make_request",fn_name="stop")
Также нам придется определить struct data_t в нашем скрипте, иначе ничего не получится прочесть:
TASK_COMM_LEN = 16 # linux/sched.h
DISK_NAME_LEN = 32 # linux/genhd.h
class Data(ct.Structure):
_fields_ = [("pid", ct.c_ulonglong),
("ts", ct.c_ulonglong),
("comm", ct.c_char * TASK_COMM_LEN),
("lat", ct.c_ulonglong),
("disk",ct.c_char * DISK_NAME_LEN)]
Последний шаг — вывод данных на терминал:
def print_event(cpu, data, size):
global start
event = ct.cast(data, ct.POINTER(Data)).contents
if start == 0:
start = event.ts
time_s = (float(event.ts - start)) / 1000000000
print("%-18.9f %-16s %-6d %-1s %s %s" % (time_s, event.comm, event.pid, event.lat, label, event.disk))
b["events"].open_perf_buffer(print_event)
# format output
start = 0
while 1:
try:
b.perf_buffer_poll()
except KeyboardInterrupt:
exit()
Сам скрипт доступен на . Попробуем запустить его на тестовой платформе, где запущен fio, пишущий на bcache, и вызвать udevadm monitor:
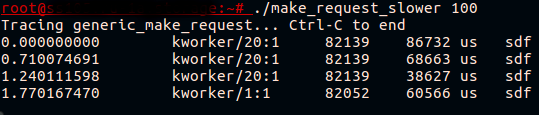
Наконец-то! Теперь мы видим, что то, что выглядело как тормозящее bcache-устройство, на самом деле — тормозящий вызов generic_make_request() для кэшируемого диска.
Dig into the Kernel
Что именно тормозит во время передачи запроса? Мы видим, что задержка возникает даже до момента начала аккаунтинга запроса, т.е. учет конкретного запроса для дальнейшего вывода статистики по нему (/proc/diskstats или iostat) ещё не начался. Это легко проверить, запустив iostat во время воспроизведения проблемы, либо , который основывается на начале и окончании аккаунтинга запросов. Ни одна из этих утилит не покажет проблем для запросов к кешируемому диску.
Если мы взглянем на функцию generic_make_request(), то мы увидим, что до начала аккаунтинга запроса вызываются ещё две функции. Первая — generic_make_request_checks(), выполняет проверки легитимности запроса относительно настроек диска. Вторая — , в которой есть интересный вызов :
ret = wait_event_interruptible(q->mq_freeze_wq,
(atomic_read(&q->mq_freeze_depth) == 0 &&
(preempt || !blk_queue_preempt_only(q))) ||
blk_queue_dying(q));
В нем ядро ожидает разморозки очереди. Замерим задержку blk_queue_enter():
~# /usr/share/bcc/tools/funclatency blk_queue_enter -i 1 -m
Tracing 1 functions for "blk_queue_enter"... Hit Ctrl-C to end.
msecs : count distribution
0 -> 1 : 341 |****************************************|
msecs : count distribution
0 -> 1 : 316 |****************************************|
msecs : count distribution
0 -> 1 : 255 |****************************************|
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 1 | |
Похоже, что мы близки к разгадке. Функции, используемые для «заморозки/разморозки» очереди — это и . Они используются тогда, когда необходимо изменить настройки очереди запросов, потенциально опасные для запросов, находящихся в этой очереди. При вызове blk_mq_freeze_queue() функцией инкрементируется счетчик q->mq_freeze_depth. После этого ядро дожидается опустошения очереди в .
Время ожидания очистки этой очереди эквивалентно задержке диска, так как ядро ждет завершения выполнения всех поставленных в очередь операций. Как только очередь пустеет, применяются изменения настроек. После чего вызывается , декрементирующая счетчик freeze_depth.
Теперь мы знаем достаточно, чтобы исправить ситуацию. Команда udevadm trigger в результате ведет к применению настроек для блочного устройства. Эти настройки описаны в правилах udev. Мы можем найти, какие именно настройки «замораживают» очередь, попробовав изменить их через sysfs либо посмотрев исходный код ядра. А ещё мы можем попробовать утилиту BCC , которая выведет на терминал трейсы стека ядра и пользовательского пространства для каждого вызова blk_freeze_queue, например:
~# /usr/share/bcc/tools/trace blk_freeze_queue -K -U
PID TID COMM FUNC
3809642 3809642 systemd-udevd blk_freeze_queue
blk_freeze_queue+0x1 [kernel]
elevator_switch+0x29 [kernel]
elv_iosched_store+0x197 [kernel]
queue_attr_store+0x5c [kernel]
sysfs_kf_write+0x3c [kernel]
kernfs_fop_write+0x125 [kernel]
__vfs_write+0x1b [kernel]
vfs_write+0xb8 [kernel]
sys_write+0x55 [kernel]
do_syscall_64+0x73 [kernel]
entry_SYSCALL_64_after_hwframe+0x3d [kernel]
__write_nocancel+0x7 [libc-2.23.so]
[unknown]
3809631 3809631 systemd-udevd blk_freeze_queue
blk_freeze_queue+0x1 [kernel]
queue_requests_store+0xb6 [kernel]
queue_attr_store+0x5c [kernel]
sysfs_kf_write+0x3c [kernel]
kernfs_fop_write+0x125 [kernel]
__vfs_write+0x1b [kernel]
vfs_write+0xb8 [kernel]
sys_write+0x55 [kernel]
do_syscall_64+0x73 [kernel]
entry_SYSCALL_64_after_hwframe+0x3d [kernel]
__write_nocancel+0x7 [libc-2.23.so]
[unknown]
Udev-правила меняются довольно редко и обычно это происходит подконтрольно. Так что мы видим, что даже применение уже заданных значений вызывает всплеск задержки передачи запроса от приложения диску. Конечно, генерировать udev-события, когда нет никаких изменений в конфигурации дисков (например, устройство не подключается/отключается), не очень хорошая практика. Тем не менее, мы можем помочь ядру не делать бесполезной работы и не «замораживать» очередь запросов, если в этом нет никакой необходимости. исправляют ситуацию.
Conclusion
eBPF — это очень гибкий и мощный инструмент. В статье мы рассмотрели один практический кейс и продемонстрировали малую часть того, что возможно сделать. Если вам интересна разработка BCC-утилит, стоит взглянуть на , который хорошо описывает основы работы.
Есть и другие интересные инструменты для отладки и профилирования, основанные на eBPF. Один из них — , позволяющий писать мощные однострочники и маленькие программки на awk-like языке. Другой — , позволяет собирать низкоуровневые метрики высокого разрешения прямо в ваш prometheus сервер, с возможностью в дальнейшем получить красивую визуализацию и даже алерты.
Источник: habr.com
