

В этом исследовании я хотел посмотреть, какие улучшения производительности можно получить, используя источник данных ClickHouse, а не PostgreSQL. Я знаю, какие преимущества производительности при использовании ClickHouse я получаю. Будут ли эти преимущества сохранены, если я получу доступ к ClickHouse из PostgreSQL с помощью внешней оболочки данных (FDW)?
Исследуемыми средами баз данных являются PostgreSQL v11, clickhousedb_fdw и база данных ClickHouse. В конечном счете, из PostgreSQL v11 мы будем запускать различные SQL-запросы, маршрутизируемые через наш clickhousedb_fdw в базу данных ClickHouse. Затем мы увидим, как производительность FDW сравнивается с теми же запросами, выполняемыми в нативном PostgreSQL и нативном ClickHouse.
База данных Clickhouse
ClickHouse — это система управления базами данных на основе колонок с открытым исходным кодом, которая может достигать производительности в 100-1000 раз быстрее, чем традиционные подходы к базам данных, способная обрабатывать более миллиарда строк менее чем за секунду.
Clickhousedb_fdw
clickhousedb_fdw — оболочка внешних данных базы данных ClickHouse, или FDW, является проектом с открытым исходным кодом от Percona. .
.
Как вы увидите, это обеспечивает FDW для ClickHouse, который позволяет SELECT from, и INSERT INTO, базу данных ClickHouse с сервера PostgreSQL v11.
FDW поддерживает расширенные функции, такие как aggregate и join. Это значительно повышает производительность за счет использования ресурсов удаленного сервера для этих ресурсоемких операций.
Benchmark environment
- Supermicro server:
- Intel® Xeon® CPU E5-2683 v3 @ 2.00GHz
- 2 sockets / 28 cores / 56 threads
- Memory: 256GB of RAM
- Storage: Samsung SM863 1.9TB Enterprise SSD
- Filesystem: ext4/xfs
- OS: Linux smblade01 4.15.0-42-generic #45~16.04.1-Ubuntu
- PostgreSQL: version 11
Benchmark tests
Вместо того, чтобы использовать какой-то набор данных, сгенерированный машиной, для этого теста, мы использовали данные «Производительность по времени, сообщаемая о времени работы оператора» с 1987 по 2018 год. Вы можете получить доступ к данным .
Размер базы данных составляет 85 ГБ, обеспечивая одну таблицу из 109 столбцов.
Benchmark Queries
Вот запросы, которые я использовал для сравнения ClickHouse, clickhousedb_fdw и PostgreSQL.
Q#
Query Contains Aggregates and Group By
Q1
SELECT DayOfWeek, count(*) AS c FROM ontime WHERE Year >= 2000 AND Year <= 2008 GROUP BY DayOfWeek ORDER BY c DESC;
Q2
SELECT DayOfWeek, count(*) AS c FROM ontime WHERE DepDelay>10 AND Year >= 2000 AND Year <= 2008 GROUP BY DayOfWeek ORDER BY c DESC;
Q3
SELECT Origin, count(*) AS c FROM ontime WHERE DepDelay>10 AND Year >= 2000 AND Year <= 2008 GROUP BY Origin ORDER BY c DESC LIMIT 10;
Q4
SELECT Carrier, count() FROM ontime WHERE DepDelay>10 AND Year = 2007 GROUP BY Carrier ORDER BY count() DESC;
Q5
SELECT a.Carrier, c, c2, c1000/c2 as c3 FROM ( SELECT Carrier, count() AS c FROM ontime WHERE DepDelay>10 AND Year=2007 GROUP BY Carrier ) a INNER JOIN ( SELECT Carrier,count(*) AS c2 FROM ontime WHERE Year=2007 GROUP BY Carrier)b on a.Carrier=b.Carrier ORDER BY c3 DESC;
Q6
SELECT a.Carrier, c, c2, c1000/c2 as c3 FROM ( SELECT Carrier, count() AS c FROM ontime WHERE DepDelay>10 AND Year >= 2000 AND Year <= 2008 GROUP BY Carrier) a INNER JOIN ( SELECT Carrier, count(*) AS c2 FROM ontime WHERE Year >= 2000 AND Year <= 2008 GROUP BY Carrier ) b on a.Carrier=b.Carrier ORDER BY c3 DESC;
Q7
SELECT Carrier, avg(DepDelay) * 1000 AS c3 FROM ontime WHERE Year >= 2000 AND Year <= 2008 GROUP BY Carrier;
Q8
SELECT Year, avg(DepDelay) FROM ontime GROUP BY Year;
Q9
select Year, count(*) as c1 from ontime group by Year;
Q10
SELECT avg(cnt) FROM (SELECT Year,Month,count(*) AS cnt FROM ontime WHERE DepDel15=1 GROUP BY Year,Month) a;
Q11
select avg(c1) from (select Year,Month,count(*) as c1 from ontime group by Year,Month) a;
Q12
SELECT OriginCityName, DestCityName, count(*) AS c FROM ontime GROUP BY OriginCityName, DestCityName ORDER BY c DESC LIMIT 10;
Q13
SELECT OriginCityName, count(*) AS c FROM ontime GROUP BY OriginCityName ORDER BY c DESC LIMIT 10;
Query Contains Joins
Q14
SELECT a.Year, c1/c2 FROM ( select Year, count()1000 as c1 from ontime WHERE DepDelay>10 GROUP BY Year) a INNER JOIN (select Year, count(*) as c2 from ontime GROUP BY Year ) b on a.Year=b.Year ORDER BY a.Year;
Q15
SELECT a.”Year”, c1/c2 FROM ( select “Year”, count()1000 as c1 FROM fontime WHERE “DepDelay”>10 GROUP BY “Year”) a INNER JOIN (select “Year”, count(*) as c2 FROM fontime GROUP BY “Year” ) b on a.”Year”=b.”Year”;
Table-1: Queries used in benchmark
Query executions
Вот результаты каждого из запросов при выполнении в разных настройках базы данных: PostgreSQL с индексами и без них, собственный ClickHouse и clickhousedb_fdw. Время показывается в миллисекундах.
Q#
PostgreSQL
PostgreSQL (Indexed)
ClickHouse
clickhousedb_fdw
Q1
27920
19634
23
57
Q2
35124
17301
50
80
Q3
34046
15618
67
115
Q4
31632
7667
25
37
Q5
47220
8976
27
60
Q6
58233
24368
55
153
Q7
30566
13256
52
91
Q8
38309
60511
112
179
Q9
20674
37979
31
81
Q10
34990
20102
56
148
Q11
30489
51658
37
155
Q12
39357
33742
186
1333
Q13
29912
30709
101
384
Q14
54126
39913
124
1364212
Q15
97258
30211
245
259
Table-1: Time taken to execute the queries used in benchmark
Просмотр результатов
График показывает время выполнения запроса в миллисекундах, ось X показывает номер запроса из таблиц выше, а ось Y показывает время выполнения в миллисекундах. Результаты ClickHouse и данные, полученные из postgres с помощью clickhousedb_fdw, показаны. Из таблицы видно, что существует огромная разница между PostgreSQL и ClickHouse, но минимальная разница между ClickHouse и clickhousedb_fdw.
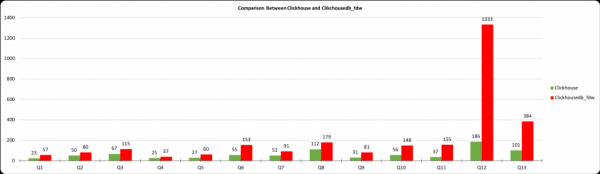
Этот график показывает разницу между ClickhouseDB и clickhousedb_fdw. В большинстве запросов накладные расходы FDW не так велики и едва ли значительны, кроме Q12. Этот запрос включает в себя объединения и предложение ORDER BY. Из-за предложения ORDER BY GROUP/BY и ORDER BY не опускаются до ClickHouse.
В таблице 2 мы видим скачок времени в запросах Q12 и Q13. Повторюсь, это вызвано предложением ORDER BY. Чтобы подтвердить это, я выполнил запросы Q-14 и Q-15 с предложением ORDER BY и без него. Без предложения ORDER BY время завершения составляет 259 мс, а с предложением ORDER BY — 1364212. Для отладки этого запроса я объясняю оба запроса, а здесь приведены результаты объяснения.
Q15: Without ORDER BY Clause
bm=# EXPLAIN VERBOSE SELECT a."Year", c1/c2
FROM (SELECT "Year", count(*)*1000 AS c1 FROM fontime WHERE "DepDelay" > 10 GROUP BY "Year") a
INNER JOIN(SELECT "Year", count(*) AS c2 FROM fontime GROUP BY "Year") b ON a."Year"=b."Year";Q15: Query Without ORDER BY Clause
QUERY PLAN
Hash Join (cost=2250.00..128516.06 rows=50000000 width=12)
Output: fontime."Year", (((count(*) * 1000)) / b.c2)
Inner Unique: true Hash Cond: (fontime."Year" = b."Year")
-> Foreign Scan (cost=1.00..-1.00 rows=100000 width=12)
Output: fontime."Year", ((count(*) * 1000))
Relations: Aggregate on (fontime)
Remote SQL: SELECT "Year", (count(*) * 1000) FROM "default".ontime WHERE (("DepDelay" > 10)) GROUP BY "Year"
-> Hash (cost=999.00..999.00 rows=100000 width=12)
Output: b.c2, b."Year"
-> Subquery Scan on b (cost=1.00..999.00 rows=100000 width=12)
Output: b.c2, b."Year"
-> Foreign Scan (cost=1.00..-1.00 rows=100000 width=12)
Output: fontime_1."Year", (count(*))
Relations: Aggregate on (fontime)
Remote SQL: SELECT "Year", count(*) FROM "default".ontime GROUP BY "Year"(16 rows)Q14: Query With ORDER BY Clause
bm=# EXPLAIN VERBOSE SELECT a."Year", c1/c2 FROM(SELECT "Year", count(*)*1000 AS c1 FROM fontime WHERE "DepDelay" > 10 GROUP BY "Year") a
INNER JOIN(SELECT "Year", count(*) as c2 FROM fontime GROUP BY "Year") b ON a."Year"= b."Year"
ORDER BY a."Year";Q14: Query Plan with ORDER BY Clause
QUERY PLAN
Merge Join (cost=2.00..628498.02 rows=50000000 width=12)
Output: fontime."Year", (((count(*) * 1000)) / (count(*)))
Inner Unique: true Merge Cond: (fontime."Year" = fontime_1."Year")
-> GroupAggregate (cost=1.00..499.01 rows=1 width=12)
Output: fontime."Year", (count(*) * 1000)
Group Key: fontime."Year"
-> Foreign Scan on public.fontime (cost=1.00..-1.00 rows=100000 width=4)
Remote SQL: SELECT "Year" FROM "default".ontime WHERE (("DepDelay" > 10))
ORDER BY "Year" ASC
-> GroupAggregate (cost=1.00..499.01 rows=1 width=12)
Output: fontime_1."Year", count(*) Group Key: fontime_1."Year"
-> Foreign Scan on public.fontime fontime_1 (cost=1.00..-1.00 rows=100000 width=4)
Remote SQL: SELECT "Year" FROM "default".ontime ORDER BY "Year" ASC(16 rows)Вывод
Результаты этих экспериментов показывают, что ClickHouse предлагает действительно хорошую производительность, а clickhousedb_fdw предлагает преимущества производительности ClickHouse из PostgreSQL. Хотя при использовании clickhousedb_fdw есть некоторые накладные расходы, они незначительны и сопоставимы с производительностью, достигнутой при естественном запуске в базе данных ClickHouse. Это также подтверждает, что fdw в PostgreSQL обеспечивает замечательные результаты.
Телеграм чат по Clickhouse
Телеграм чат по PostgreSQL
Источник: habr.com
