

Сегодня мы начнем изучение маршрутизации по протоколу OSPF. Эта тема, как и рассмотрение протокола EIGRP, является важнейшей во всем курсе CCNA. Как видите, раздел 2.4 называется «Настройка, проверка и неполадки единичной зоны и мультизоны OSPFv2 для протокола IPv4 (за исключением аутентификации, фильтрации, ручного суммирования маршрутов, перераспределения, тупиковой области, виртуальной сети и LSA)».

Тема OSPF достаточно обширна, поэтому она займет 2, возможно, 3 видеоурока. Сегодняшний урок будет посвящен теоретической стороне вопроса, я расскажу вам, что представляет собой этот протокол в общих чертах и как он работает. В следующем видео мы перейдем к режиму конфигурации OSPF с помощью Packet Tracer.
Итак, на этом уроке мы рассмотрим три вещи: что такое OSPF, как он работает и что такое зоны OSPF. На предыдущем уроке мы говорили, что OSPF – это протокол маршрутизации типа Link State, исследующий каналы связи между маршрутизаторами и принимающий решения на основе скорости этих каналов. Длинный канал с большей скоростью, то есть с большей пропускной способностью будет в приоритете по сравнению с коротким каналом с меньшей пропускной способностью.
Протокол RIP, являясь дистанционно-векторным, выберет путь в один хоп, даже если этот канал имеет низкую скорость, а протокол OSPF выберет длинный маршрут из нескольких хопов, если суммарная скорость на этом маршруте будет выше, чем скорость трафика на коротком маршруте.
Позже мы рассмотрим алгоритм принятия решений, пока что вы должны запомнить, что OSPF является протоколом состояния каналов Link State. Этот открытый стандарт был создан в 1988 году, так что им мог воспользоваться каждый производитель сетевого оборудования и любой сетевой провайдер. Поэтому OSPF намного популярнее, чем EIGRP.
Протокол OSPF версии 2 поддерживает только протокол IPv4, а годом позже, в 1989, разработчики объявили о выпуске 3 версии, которая поддерживает IPv6. Однако полнофункциональная третья версия OSPF для IPv6 появилась только в 2008 году. Почему выбрали именно OSPF? На последнем уроке мы узнали, что этот протокол внутреннего шлюза выполняет конвергенцию маршрутов намного быстрее, чем RIP. Это бесклассовый протокол.
Если вы помните, RIP является классовым протоколом, то есть он не отправляет информацию о маске подсети, и если ему повстречается IP-адрес класса А/24, он его не примет. Например, если вы представите ему IP-адрес вида 10.1.1.0/24, то он воспримет его как сеть 10.0.0.0, потому что не понимает, когда сеть разделяется на подсети с использованием более чем одной маски подсети.
OSPF является безопасным протоколом. Например, если два роутера обмениваются OSPF — информацией, вы можете настроить аутентификацию таким образом, что поделиться информацией с соседним роутером можно будет только после ввода пароля. Как мы уже сказали, это открытый стандарт, поэтому OSPF используют многие производители сетевого оборудования.
В глобальном смысле OSPF представляет собой механизм обмена объявлениями о состоянии канала Link State Advertisemen, или LSA. Сообщения LSA генерируются роутером и содержат в себе много информации: уникальный идентификатор роутера router-id, данные о сетях, известных роутеру, данные об их стоимости и так далее. Вся эта информация нужна роутеру для принятия решения о маршрутизации.
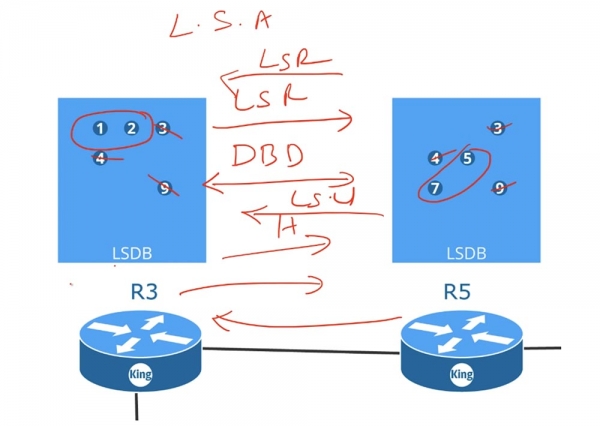
Роутер R3 посылает свою информацию LSA роутеру R5, а роутер R5 делится своей LSA-информацией с R3. Эти LSA представляют собой структуру данных, формирующих базу данных состояния каналов Link State Data Base, или LSDB. Роутер собирает все полученные LSA и помещает их в свою LSDB. После того, как оба роутера создали свои базы данных, они обмениваются сообщениями Hello, которые служат для обнаружения соседей, и приступают к процедуре сравнения своих LSDB.
Роутер R3 высылает роутеру R5 сообщение DBD, или «описание базы данных», а R5 отсылает своё DBD роутеру R3. Эти сообщения содержат индексы LSA, которые имеются в базах каждого роутера. Получив DBD, роутер R3 посылает запрос состояния сети LSR роутеру R5, в котором говорится: «у меня уже есть сообщения 3,4 и 9, так что пришлите мне только 5 и 7».
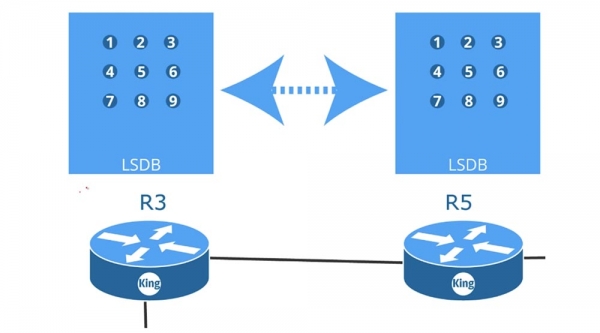
Точно так же поступает R5, сообщая третьему роутеру: «у меня есть информация 3,4 и 9, так что пришлите мне 1 и 2». Получив запросы LSR, роутеры отсылают обратно пакеты обновлений состояния сети LSU, то есть в ответ на свой LSR третий роутер получает LSU от роутера R5. После того, как роутеры обновят свои базы данных, то все они, даже если у вас имеется 100 роутеров, будут иметь одинаковые базы LSDB. Как только в роутерах будут созданы базы данных LSDB, каждый из них будет знать обо всей сети в целом. Протокол OSPF задействует алгоритм Shortest Path First для создания таблицы маршрутизации, поэтому важнейшим условием его корректной работы является синхронизация LSDB всех устройств в сети.
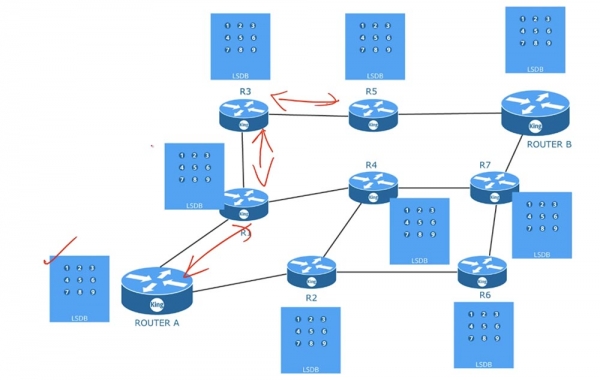
На приведенной схеме размещены 9 роутеров, каждый из которых обменивается с соседями сообщениями LSR, LSU и так далее. Все они соединены друг с другом по типу p2p, или «точка-точка» интерфейсами, поддерживающими работу по протоколу OSPF, и взаимодействуют друг с другом с целью создания одинаковых LSDB.
Как только базы будут синхронизированы, каждый роутер, используя алгоритм наикратчайшего пути, формирует свою таблицу маршрутизации. У разных роутеров эти таблицы будут разными. То есть все роутеры используют одинаковые LSDB, но создают таблицы маршрутизации, исходя из собственных соображений о наикратчайших маршрутах. Для использования этого алгоритма OSPF нуждается в регулярном обновлении базы LSDB.
Итак, для собственного функционирования OSPF должен сначала обеспечить 3 условия: найти соседей, создать и обновить LSDB и сформировать таблицу маршрутизации. Для выполнения первого условия сетевому администратору, возможно, понадобится вручную настроить router-id, тайминги или wildcard mask. В следующем видео мы рассмотрим настройку устройства для работы с OSPF, пока что вы должны знать, что этот протокол использует обратную маску, и если она не совпадает, если не совпадают ваши подсети, или не совпадает аутентификация, соседство роутеров не сможет образоваться. Поэтому при устранении неполадок работы OSPF вы должны выяснить, почему это самое соседство не образуется, то есть проверить совпадение вышеуказанных параметров.
Как администратор сети, вы не участвуете в процессе создания LSDB. Обновление баз данных происходит автоматически после создания соседства роутеров, как и построение таблиц маршрутизации. Все это выполняет само устройство, настроенное на работу с протоколом OSPF.
Давайте рассмотрим пример. У нас имеются 2 роутера, которым я для упрощения присвоил идентификаторы RID 1.1.1.1 и 2.2.2.2. Как только мы соединим их, канал link сразу же перейдет в состояние up, потому что сначала я настроил эти роутеры на работу с OSPF. Как только будет образован канал связи, роутер А немедленно оправит второму пакет Hello. В этом пакете будет содержаться информация, что данный роутер еще никого не «видел» на этом канале, потому что отсылает Hello впервые, а также его собственный идентификатор, данные о подсоединенной к нему сети и другая информация, которой он может поделиться с соседом.
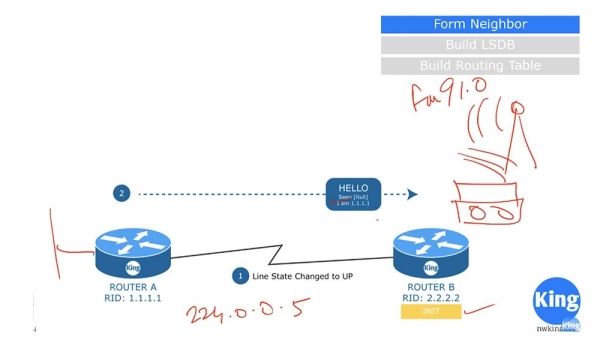
Получив этот пакет, роутер В скажет: «я вижу, что на данном канале связи имеется потенциальный кандидат на соседство по протоколу OSPF» и перейдет в состояние инициализации Init state. Пакет Hello — это не юникастовое или бродкастовое сообщение, это мультикастовый пакет, отсылаемый на мультикастовый OSPF IP-адрес 224.0.0.5. Некоторые люди спрашивают, какова маска подсети для мультикаста. Дело в том, что мультикаст не имеет маски подсети, он распространяется как радиосигнал, который слышат все устройства, настроенные на его частоту. Например, если вы хотите услышать FM-радио, вещающее на частоте 91,0, то настраиваете свой радиоприемник на эту частоту.
Точно так же роутер В настроен на прием сообщений для мультикастового адреса 224.0.0.5. Слушая этот канал, он принимает пакет Hello, который отослал роутер А, и отвечает ему своим сообщением.
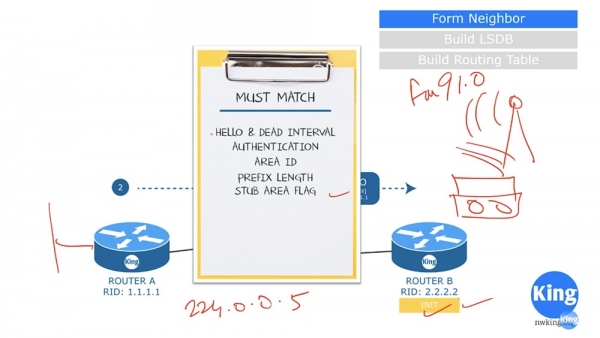
При этом соседство может быть установлено только в том случае, если ответ В удовлетворяет набору критериев. Первый критерий – частота отправки сообщений Hello и интервал ожидания ответа на это сообщение Dead Interval должны совпадать у обоих роутеров. Обычно Dead Interval равен нескольким значениям таймера Hello. Таким образом, если Hello Timer роутера А составляет 10 с, а роутер В отправит ему сообщение через 30 с при том что Dead Interval равен 20с, соседство не состоится.
Второй критерий – оба роутера должны использовать одинаковый тип аутентификации. Соответственно, пароли аутентификации также должны совпадать.
Третий критерий — это совпадение идентификаторов зоны Arial ID, четвертый – совпадение длины префикса сети. Если роутер А сообщает префикс /24, то роутер В также должен иметь префикс сети /24. В следующем видео мы рассмотрим это подробнее, пока что замечу, что это не маска подсети, здесь роутеры используют обратную маску Wildcard mask. И конечно, флаги тупиковой зоны Stub area так же должны совпадать, если роутеры находятся в этой зоне.
После проверки этих критериев в случае их совпадения роутер В отправляет роутеру А свой Hello-пакет. В отличие от сообщения А, роутер В сообщает, что он увидел роутер А, и представляется сам.
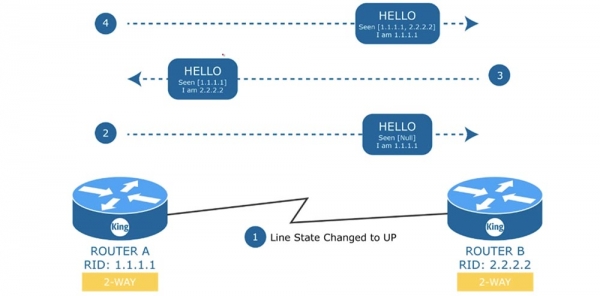
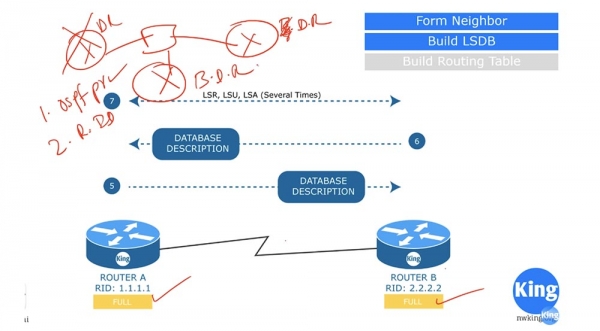
В ответ на это сообщение роутер А снова посылает Hello роутеру В, в котором подтверждает, что тоже увидел роутер В, канал связи между ними состоит из устройств 1.1.1.1 и 2.2.2.2, а сам он является устройством 1.1.1.1. Это очень важная стадия установления соседства. В данном случае используется двустороннее соединение 2-WAY, но что произойдет, если у нас имеется свитч с распределенной сетью из 4-х роутеров? В такой «расшаренной» среде один из роутеров должен играть роль выделенного маршрутизатора Designated router D.R, а второй – резервного выделенного маршрутизатора Backup designated router, B.D.R.
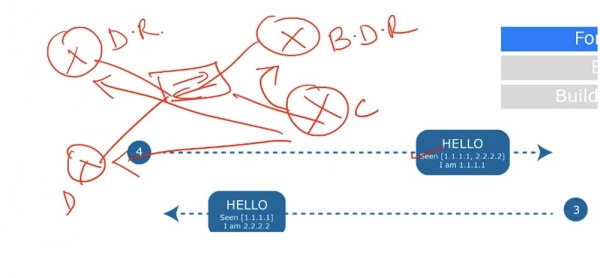
Каждое из этих устройств сформирует Full connection, или состояние полной смежности, позже мы рассмотрим, что это такое, однако соединение этого типа будет установлено только с D.R. и B.D.R, друг с другом два нижних роутера D и В все равно будут общаться по схеме двустороннего соединения «point-to-point».
То есть с D.R. и B.D.R все роутеры устанавливают отношение полного соседства, а друг с другом – соединение типа point-to-point. Это очень важно, потому что при двустороннем соединении смежных устройств все параметры пакета Hello должны совпадать. В нашем случае все совпадает, поэтому устройства без проблем образуют соседство.
Как только двусторонняя связь будет установлена, роутер А отсылает роутеру В пакет Database Description, или «описание базы данных», и переходит в состояние ExStart — начало обмена, или ожидание загрузки. Database Descriptor представляет собой информацию, аналогичную оглавлению книги – это перечисление всего, что имеется в базе данных маршрутизации. В ответ роутер В высылает свое описание базы данных роутеру А и переходит в состояние обмена данными о каналах Exchange. Если в состоянии Exchange роутер обнаружил, что в его базе данных отсутствует какая-то информация, то он перейдет в состояние загрузки LOADING и начнет обмениваться с соседом сообщениями LSR, LSU и LSA.
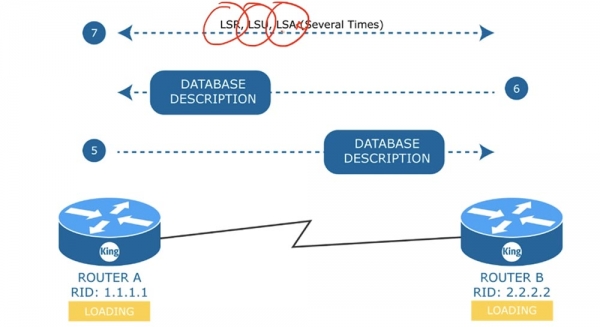
Так, роутер А пошлет соседу LSR, тот ответит ему пакетом LSU, на что роутер А ответит роутеру В сообщением LSA. Этот обмен произойдет столько раз, сколько раз устройства захотят обменяться сообщениями LSA. Состояние LOADING означает, что полного обновления базы данных LSA еще не произошло. После загрузки всех данных оба устройства перейдут в состояние полной смежности FULL.
Замечу, что при двустороннем соединении устройства находится просто в состоянии соседства, а состояние полной смежности возможно только между маршрутизаторами, D.R. и B.D.R. Это означает, что каждый роутер сообщает D.R. об изменениях в сети, и все роутеры узнают об этих изменениях от D.R.
Выбор D.R. и B.D.R является важным вопросом. Рассмотрим, как происходит выбор D.R в общей среде. Предположим, в нашей схеме имеется три роутера и свитч. Сначала устройства OSPF сравнивают приоритет в Hello-сообщениях, затем сравнивают Router ID.
Устройство с наивысшим приоритетом становится D.R. Если приоритеты двух устройств совпадают, то из них двоих выбирается устройство с наивысшим Router ID, которое и становится D.R.
Резервным выделенным маршрутизатором B.D.R становится устройство со вторым по значимости приоритетом или со вторым по значимости Router ID.Если D.R. выйдет из строя, его немедленно заменит B.D.R. Он начнет играть роль D.R, а система выберет другой B.D.R.
Надеюсь, что вы разобрались с выбором D.R. и B.D.R, ели нет, то я еще вернусь к этому вопросу в одном из следующих видео и объясню этот процесс.
Итак, мы рассмотрели, что представляют собой Hello, описание базы данных Database Descriptor и сообщения LSR, LSU и LSA. Прежде чем перейти к следующей теме, давайте немного поговорим о стоимости OSPF.

В Cisco стоимость маршрута высчитывается по формуле отношения пропускной способности Reference bandwidth, которая по умолчанию принята равной 100 мбит/с, к стоимости канала. Например, при соединении устройств через серийный порт скорость равна 1.544 мбит/с, а стоимость будет равна 64. При использовании Ethernet-соединения со скоростью 10 мбит/с стоимость равна 10, а стоимость соединения FastEthernet со скоростью 100 мбит/с будет равняться 1.
При использовании Gigabit Ethernet мы имеем скорость 1000 мбит/с, однако в данном случае скорость всегда принимается равной 1. Таким образом, если у вас в сети есть Gigabit Ethernet, вы должны изменить значение по умолчанию Ref. BW на 1000. В этом случае стоимость составит 1, а вся таблица будет пересчитана с увеличением значений стоимости в 10 раз. После того, как мы сформировали соседство и построили базу данных LSDB, мы переходим к построению таблицы маршрутизации.
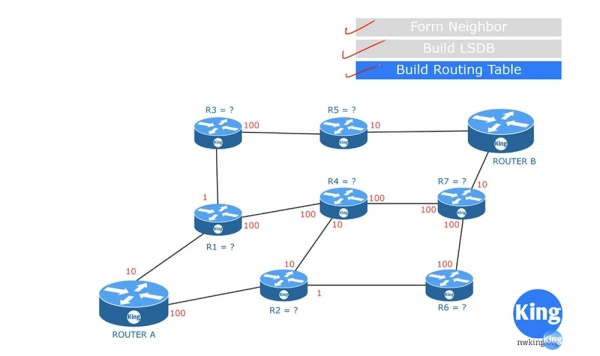
После получения LSDB каждый из роутеров самостоятельно приступает к формированию списка маршрутов с помощью алгоритма SPF. В нашей схеме роутер А будет создавать такую таблицу для самого себя. Например, он подсчитывает стоимость маршрута А-R1 и определяет её равной 10. Чтобы упростить понимание схемы, предположим, что роутер А определяет оптимальный маршрут к роутеру В. Стоимость соединения А-R1 равна 10, соединения А-R2 равна 100, а стоимость маршрута А-R3 равна 11, то есть сумме маршрута А-R1(10) и R1-R3(1).
Если роутер А захочет добраться до роутера R4, он может это сделать либо по маршруту А-R1-R4, либо по маршруту А-R2-R4, причем в обоих случаях стоимость маршрутов будет одинакова: 10+100 =100+10=110. Маршрут А-R6 будет стоить 100+1= 101, что уже лучше. Далее рассматривается путь к роутеру R5 по маршруту А-R1-R3-R5, стоимость которого составит 10+1+100 = 111.
Путь к роутеру R7 можно проложить по двум маршрутам: А-R1-R4-R7 или А-R2-R6-R7. Стоимость первого составит 210, второго – 201, значит, следует выбрать 201. Итак, чтобы достичь роутер В, роутер А может использовать 4 маршрута.
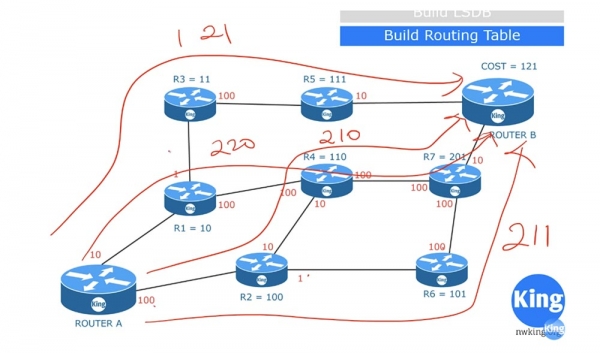
Стоимость маршрута А-R1-R3-R5-B составит 121. Маршрут А-R1-R4-R7-B будет стоить 220. Маршрут А-R2-R4-R7-B стоит 210, а А-R2-R6-R7-B имеет стоимость 211. Исходя из этого, роутер А выберет маршрут с наименьшей стоимостью, равной 121, и поместит в таблицу маршрутизации именно его. Это очень упрощенная схема того, как работает алгоритм SPF. В действительности в таблицу помещается не только обозначения роутеров, через который пролегает оптимальный маршрут, но и обозначения связывающих их портов и вся остальная необходимая информация.
Рассмотрим еще одну тему, которая касается зон маршрутизации. Обычно при настройке OSPF устройств компании все они находятся в одной общей зоне.
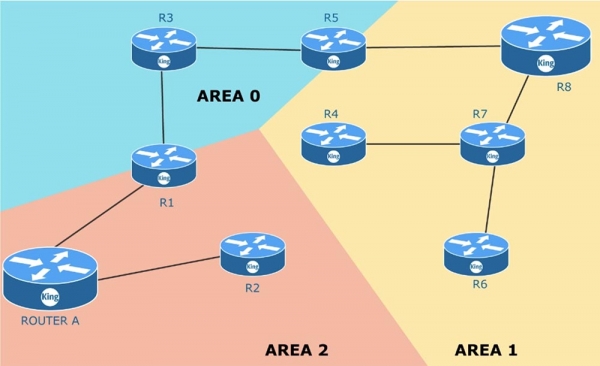
Что произойдет, если устройство, соединенное с роутером R3, внезапно выйдет из строя? Роутер R3 тут же начнет рассылать в адрес роутеров R5 и R1 сообщение о том, что канал с данным устройством больше не работает, и все роутеры начнут обмениваться обновлениями об этом событии.
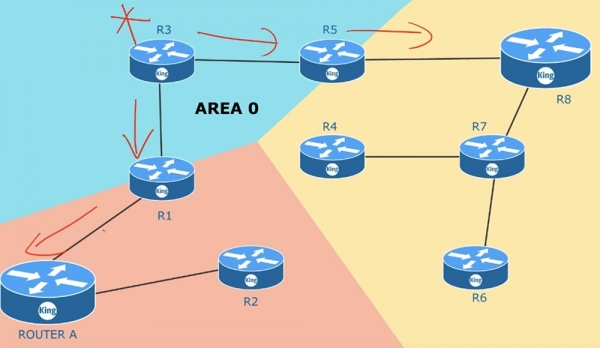
Если у вас имеется 100 роутеров, то все они обновят информацию о состоянии каналов, потому что находятся в одной общей зоне. То же самое произойдет при выходе из строя одного из соседних роутеров – все устройства в зоне обменяются обновлениями LSA. После обмена такими сообщениями изменится сама топология сети. Как только это произойдет, SPF пересчитает таблицы маршрутизации в соответствии с изменившимися условиями. Это очень объемный процесс, и если у вас в одной зоне расположена тысяча устройств, вам нужно контролировать размер памяти роутеров, чтобы он был достаточным для хранения всех LSA и огромной базы данных состояния каналов LSDB. Как только в какой-то части зоны происходят изменения, алгоритм SPF тут же производит пересчет маршрутов. По умолчанию LSA обновляется каждые 30 минут. Этот процесс происходит на всех устройствах не одновременно, однако в любом случае обновления выполняются каждым роутером с периодичностью 30 мин. Чем больше сетевых устройств. Тем больше требуется памяти и времени на обновление LSDB.
Решить эту проблему можно, если разделить одну общую зону на несколько отдельных зон, то есть использовать мультизонирование. Для этого у вас должен быть план или схема всей сети, которой вы управляете. Нулевая зона AREA 0 является вашей главной зоной Main area. Это то место, где осуществляется соединение с внешней сетью, например, выход в Интернет. При создании новых зон вы должны руководствоваться правилом: в каждой зоне должен располагаться один пограничный маршрутизатор ABR, Area Border Router. Пограничный роутер имеет один интерфейс в одной зоне, а второй интерфейс – в другой зоне. Например, роутер R5 имеет интерфейсы в зоне 1 и зоне 0. Как я сказал, каждая из зон должна быть соединена с нулевой зоной, то есть иметь пограничный роутер, один из интерфейсов которого соединен с AREA 0.
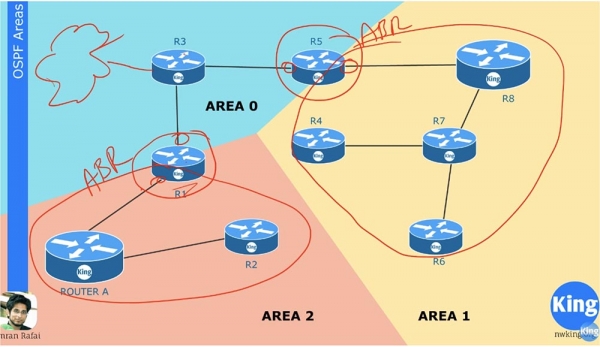
Предположим, что соединение R6-R7 вышло из строя. При этом обновление LSA распространится только по зоне AREA 1 и будет касаться только этой зоны. Устройства в зоне 2 и в зоне 0 даже не будут об этом знать. Пограничный роутер R5 выполняет суммирование информации о том, что происходит в его зоне, и отправляет в главную зону AREA 0 суммарную информацию о состоянии сети. Устройствам в одной зоне не нужно знать обо всех изменениях LSA внутри других зон, потому что роутер ABR будет пересылать суммарную информацию о маршрутах из одной зоны в другую.
Если вы не совсем разобрались с концепцией зон, то сможете узнать больше на следующих уроках, когда мы займемся настройкой маршрутизации OSPF и рассмотрим несколько примеров.

Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас оформив заказ или порекомендовав знакомым, 30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас: (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле? Только у нас в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том
Источник: habr.com
