

Легитимный трафик в сети DDoS-Guard недавно превысил сотню гигабит в секунду. Сейчас 50% всего нашего трафика генерируют веб-сервисы клиентов. Это многие десятки тысяч доменов, очень разных и в большинстве случаев требующих индивидуального подхода.
Под катом — как мы управляем фронт-нодами и выдаем SSL-сертификаты для сотен тысяч сайтов.
Настроить фронт для одного сайта, пусть даже очень большого, — это просто. Берём nginx или haproxy или lighttpd, настраиваем по гайдам и забываем. Если надо что-то поменять — делаем reload и опять забываем.
Всё меняется, когда вы на лету обрабатываете большие объемы трафика, оцениваете легитимность запросов, сжимаете и кэшируете пользовательский контент, и при этом изменяете параметры несколько раз в секунду. Пользователь хочет видеть результат на всех внешних нодах сразу после того, как он поменял настройки в личном кабинете. А еще пользователь может загрузить по API несколько тысяч (а иногда и десятков тысяч) доменов с индивидуальными параметрами обработки трафика. Все это тоже должно заработать сразу и в Америке, и в Европе, и в Азии — задача не самая тривиальная, учитывая, что в одной только Москве несколько физически разнесенных узлов фильтрации.
Зачем много больших надежных узлов по всему миру?
- Качество обслуживания клиентского трафика — запросы из США нужно обрабатывать именно в США (в том числе на предмет атак, парсинга и прочих аномалий), а не тянуть в Москву или Европу, непредсказуемо увеличивая задержку обработки.
- Атакующий трафик надо локализовывать — транзитные операторы могут деградировать во время атак, объем которых часто превышает 1Тbps. Транспортировать атакующий трафик по трансатлантическим или трансазиатским линкам — не лучшая идея. У нас были реальные кейсы, когда Tier-1 операторы говорили: «Объемы атак, которые вы принимаете, для нас опасны». Именно поэтому мы принимаем входящие потоки как можно ближе к их источникам.
- Жесткие требования непрерывности обслуживания — центры очистки не должны зависеть ни друг от друга, ни от локальных событий нашего стремительно меняющегося мира. Обесточили на неделю все 11 этажей ММТС-9? — не беда. Не пострадает ни один клиент, не имеющий физического включения именно в этой локации, а веб-сервисы не пострадают ни при каких обстоятельствах.
Как всем этим управлять?
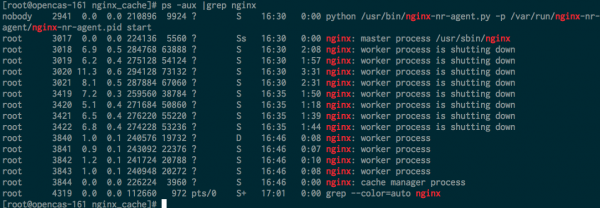
Конфигурации сервисов должны как можно быстрее (в идеале мгновенно) распространяться на всех фронт-нодах. Нельзя просто брать и перестраивать текстовые конфиги и делать перезагрузки демонов на каждом изменении — тот же nginx держит завершающиеся процессы (worker shutting down) еще несколько минут (а может и часов если там долгие websocket-сессии).
При перезагрузке конфигурации nginx вполне нормальна следующая картина:
По утилизации памяти:
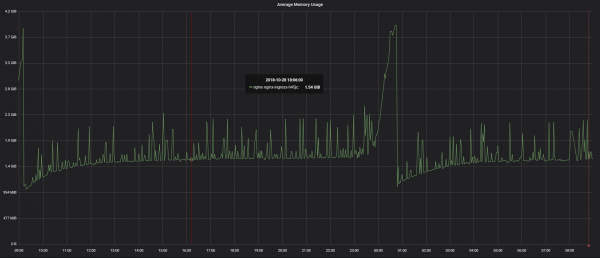
Старые воркеры кушают память, в том числе, не зависящую линейно от числа соединений, — это нормально. Когда клиентские соединения закроются, эта память освободится.
Почему это не было проблемой, когда nginx только начинал развиваться? Не было ни HTTP/2, ни WebSocket, ни массовых длинных keep-alive соединений. 70% нашего веб-трафика — HTTP/2, а это очень долгие соединения.
Решение простое — не использовать nginx, не управлять фронтами на основе текстовых файлов, и уж точно не гонять зипованные текстовые конфигурации по транстихоокеанским каналам. Каналы, конечно, гарантированные и резервированные, но от этого не менее трансконтинентальные.
У нас собственный фронт-сервер-балансер, о внутренностях которого я расскажу в следующих статьях. Главное, что он умеет — применять тысячи изменений конфигураций в секунду на лету, без рестартов, релоадов, скачкообразного роста потребления памяти и вот этого всего. Это очень похоже на Hot Code Reload, например в Erlang. Данные хранятся в геораспределенной key-value базе и вычитываются сразу исполнительными механизмами фронтов. Т.е. вы загрузили SSL-сертификат через веб-интерфейс или API в Москве, а через несколько секунд он уже готов к работе в нашем центре очистки в Лос-Анжелесе. Если вдруг случится мировая война, и пропадет интернет во всем мире, наши ноды продолжат работать автономно и починят split-brain, как только станет доступен один из выделенных каналов Лос-Анжелес-Амстердам-Москва, Москва-Амстердам-Гон-Конг-Лос-Анжелес или хотя бы один из резервных оверлейных GRE.
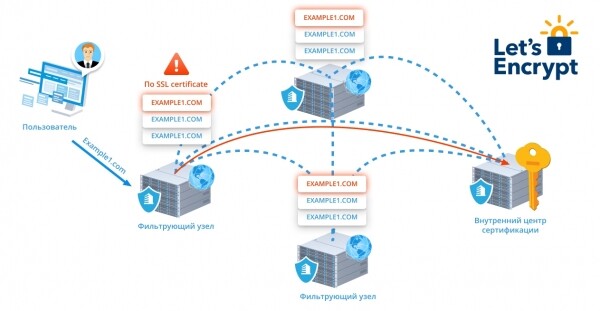
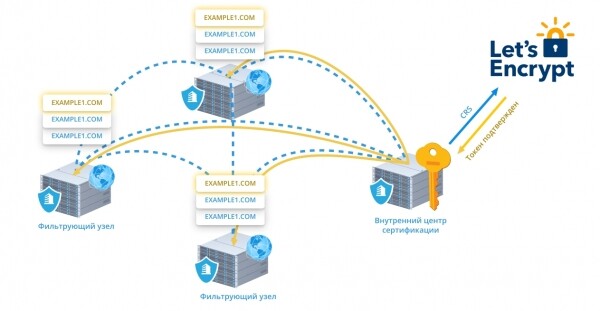
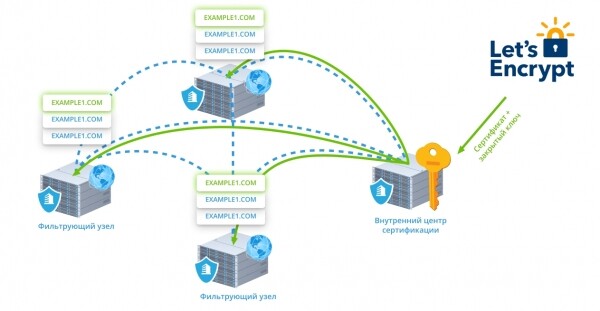
Этот же механизм позволяет нам мгновенно выпускать и продлевать сертификаты Let’s Encrypt. Очень упрощенно это работает так:
- Как только мы видим хотя бы один HTTPS-запрос для домена нашего клиента без сертификата (или с просроченным сертификатом), внешняя нода, принявшая запрос, сообщает об этом внутреннему центру сертификации.

- Если пользователь не запретил выдачу Let’s Encrypt, центр сертификации формирует CSR, получает у LE токен подтверждения и рассылает его на все фронты по шифрованному каналу. Теперь любая нода может подтвердить валидирующий запрос от LE.
- Через несколько мгновений мы получим корректный сертификат и приватный ключ и точно так же разошлем фронтам. Опять же без перезагрузки демонов
- За 7 дней до даты экспирации инициируется процедура переполучения сертификата
Прямо сейчас мы в реалтайме ротируем 350к сертификатов совершенно прозрачно для пользователей.
В следующих статьях цикла расскажу о других особенностях реалтаймовой обработки большого веб-трафика — например, об анализе RTT по неполным данным для улучшения качества обслуживания транзитных клиентов и вообще о защите транзитного трафика от терабитных атак, о доставке и агрегации информации о трафике, о WAF, почти неограниченной CDN и множестве механизмов оптимизации отдачи контента.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
О чем вы хотели бы узнать в первую очередь?
- 14,3%Алгоритмах кластеризации и анализа качества веб-трафика<3
- 33,3%Внутренностях балансеров DDoS-Guard7
- 9,5%Защите транзитного L3/L4-трафика2
- 0,0%Защите веб-сайтов на транзитном трафике0
- 14,3%Web Application Firewall3
- 28,6%Защите от парсинга и скликивания6
Проголосовал 21 пользователь. Воздержались 6 пользователей.
Источник: habr.com
