

Прим. перев.: Эта статья входит в состав опубликованных в свободном доступе материалов проекта , обучающего работе с Kubernetes компании и индивидуальных администраторов. В ней Daniele Polencic, руководитель проекта, делится наглядной инструкцией о том, какие шаги стоит предпринимать в случае возникновения проблем общего характера у приложений, запущенных в кластере K8s.
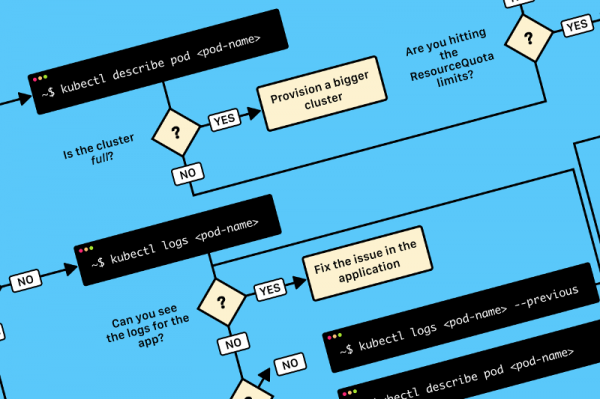
TL;DR: вот схема, которая поможет вам отладить deployment в Kubernetes:
Блок-схема для поиска и исправления ошибок в кластере. В оригинале (на английском) она доступна в и .
При развертывании приложения в Kubernetes обычно необходимо определить три компонента:
- Deployment — это некий рецепт по созданию копий приложения, называемых pod’ами;
- Service — внутренний балансировщик нагрузки, распределяющий трафик по pod’ам;
- Ingress — описание того, как трафик будет попадать из внешнего мира к Service’у.
Вот краткое графическое резюме:
1) В Kubernetes приложения получают трафик из внешнего мира через два слоя балансировщиков нагрузки: внутренний и внешний.
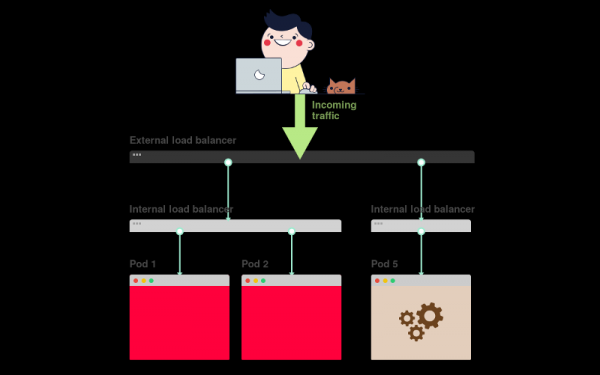
2) Внутренний балансировщик называется Service, внешний – Ingress.
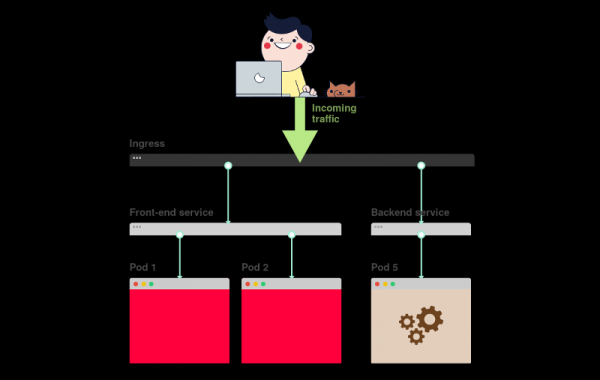
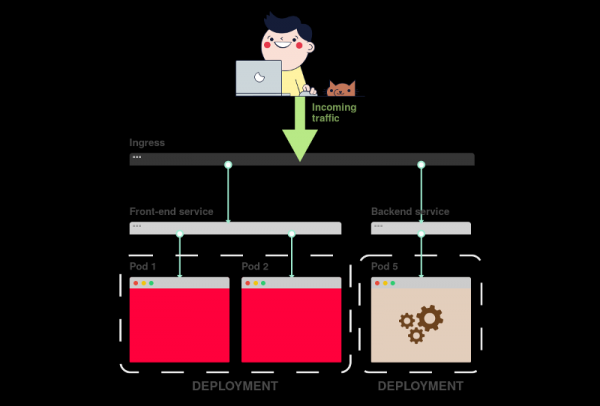
3) Deployment создает pod’ы и следит за ними (они не создаются вручную).
Предположим, вы хотите развернуть простенькое приложение а-ля Hello World. YAML-конфигурация для него будет выглядеть следующим образом:
apiVersion: apps/v1
kind: Deployment # <<<
metadata:
name: my-deployment
labels:
track: canary
spec:
selector:
matchLabels:
any-name: my-app
template:
metadata:
labels:
any-name: my-app
spec:
containers:
- name: cont1
image: learnk8s/app:1.0.0
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service # <<<
metadata:
name: my-service
spec:
ports:
- port: 80
targetPort: 8080
selector:
name: app
---
apiVersion: networking.k8s.io/v1beta1
kind: Ingress # <<<
metadata:
name: my-ingress
spec:
rules:
- http:
paths:
- backend:
serviceName: app
servicePort: 80
path: /Определение довольно длинное, и легко запутаться в том, как компоненты связаны друг с другом.
Например:
- Когда следует использовать порт 80, а когда — 8080?
- Следует ли создавать новый порт для каждого сервиса, чтобы они не конфликтовали?
- Имеют ли значения имена лейблов? Должны ли они быть одинаковыми везде?
Прежде чем сосредоточиться на отладке, давайте вспомним, как три компонента связаны друг с другом. Начнем с Deployment и Service.
Связь Deployment’а и Service’а
Вы удивитесь, но Deployment’ы и Service’ы никак не связаны. Вместо этого Service напрямую указывает на Pod’ы в обход Deployment’а.
Таким образом, нас интересует, как связаны друг с другом Pod’ы и Service’ы. Следует помнить три вещи:
- Селектор (
selector) у Service’а должен соответствовать хотя бы одному лейблу Pod’а. -
targetPortдолжен совпадать сcontainerPortконтейнера внутри Pod’а. -
portService’а может быть любым. Различные сервисы могут использовать один и тот же порт, поскольку у них разные IP-адреса.
Следующая схема представляет все вышеперечисленное в графической форме:
1) Представим, что сервис направляет трафик в некий pod:
2) При создании pod’а необходимо задать containerPort для каждого контейнера в pod’ах:
3) При создании сервиса необходимо указать port и targetPort. Но через какой из них идет подключение к контейнеру?
4) Через targetPort. Он должен совпадать с containerPort.
5) Допустим, в контейнере открыт порт 3000. Тогда значение targetPort должно быть таким же.
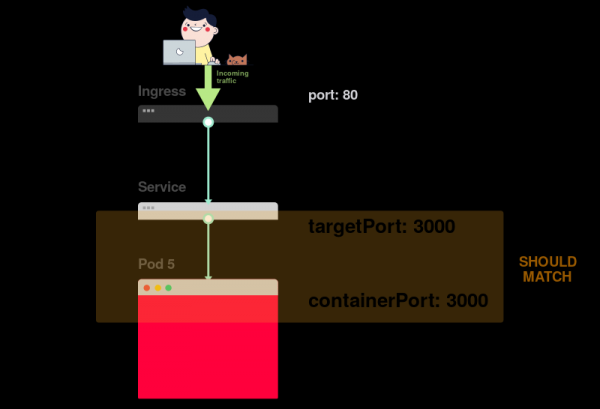
В YAML-файле лейблы и ports / targetPort должны совпадать:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
labels:
track: canary
spec:
selector:
matchLabels:
any-name: my-app
template:
metadata:
labels: # <<<
any-name: my-app # <<<
spec:
containers:
- name: cont1
image: learnk8s/app:1.0.0
ports:
- containerPort: 8080 # <<<
---
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
ports:
- port: 80
targetPort: 8080 # <<<
selector: # <<<
any-name: my-app # <<< А как насчет лейбла track: canary в верхней части раздела Deployment? Должен ли он совпадать?
Этот лейбл относится к развертыванию, и не используется сервисом для маршрутизации трафика. Другими словами, его можно удалить или присвоить другое значение.
А что насчет селектора matchLabels?
Он всегда должен совпадать с лейблами Pod’а, поскольку используется Deployment’ом для отслеживания pod’ов.
Предположим, что вы внесли верные правки. Как их проверить?
Проверить лейбл pod’ов можно следующей командой:
kubectl get pods --show-labelsИли, если pod’ы принадлежат нескольким приложениям:
kubectl get pods --selector any-name=my-app --show-labels Где any-name=my-app — это лейбл any-name: my-app.
Остались сложности?
Можно подключиться к pod’у! Для этого надо использовать команду port-forward в kubectl. Она позволяет подключиться к сервису и проверить соединение.
kubectl port-forward service/<service name> 3000:80Здесь:
-
service/<service name>— имя сервиса; в нашем случае этоmy-service; - 3000 — порт, который требуется открыть на компьютере;
- 80 — порт, прописанный в поле
portсервиса.
Если удалось установить соединение, значит настройки верны.
Если соединение установить не удалось, значит проблема с лейблами или порты не совпадают.
Связь Service’а и Ingress’а
Следующий шаг в обеспечении доступа к приложению связан с настройкой Ingress’а. Ingress должен знать, как отыскать сервис, затем найти pod’ы и направить к ним трафик. Ingress находит нужный сервис по имени и открытому порту.
В описании Ingress и Service должны совпадать два параметра:
-
servicePortв Ingress должен совпадать с параметромportв Service; -
serviceNameв Ingress должно совпадать с полемnameв Service.
Следующая схема подводит итог по подключению портов:
1) Как вы уже знаете, Service слушает некий port:
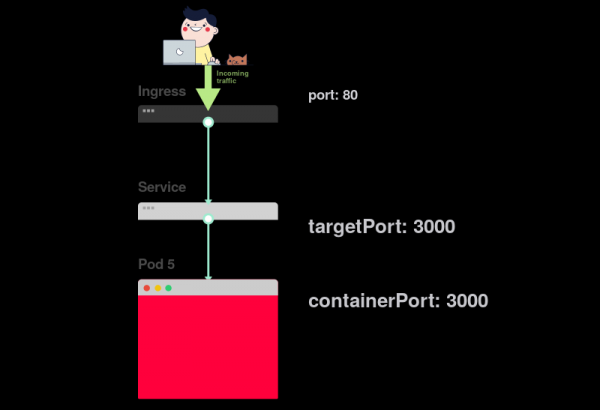
2) У Ingress’а есть параметр, называемый servicePort:
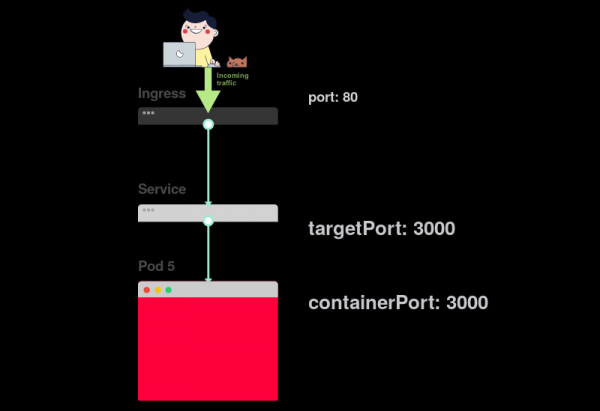
3) Этот параметр (servicePort) всегда должен совпадать с port в определении Service:
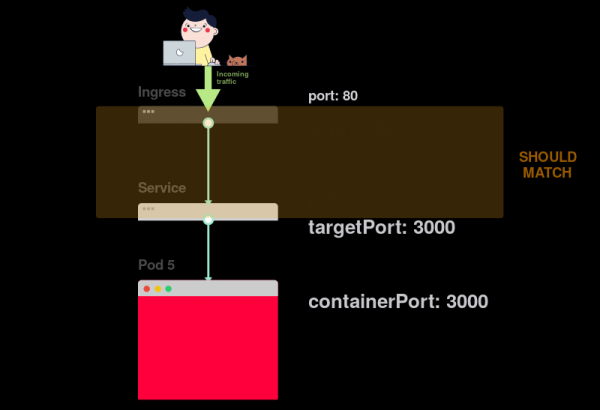
4) Если в Service задан порт 80, то необходимо, чтобы servicePort также был равен 80:
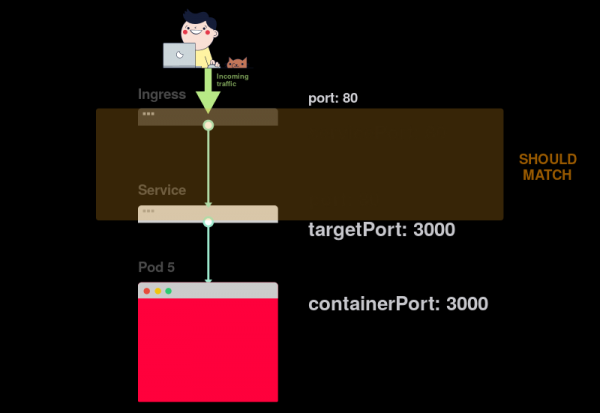
На практике необходимо обращать внимание на следующие строки:
apiVersion: v1
kind: Service
metadata:
name: my-service # <<<
spec:
ports:
- port: 80 # <<<
targetPort: 8080
selector:
any-name: my-app
---
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: my-ingress
spec:
rules:
- http:
paths:
- backend:
serviceName: my-service # <<<
servicePort: 80 # <<<
path: /Как проверить, работает ли Ingress?
Можно воспользоваться методом с kubectl port-forward, но вместо сервиса нужно подключиться к контроллеру Ingress.
Сначала нужно узнать имя pod’а с контроллером Ingress:
kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS
kube-system coredns-5644d7b6d9-jn7cq 1/1 Running
kube-system etcd-minikube 1/1 Running
kube-system kube-apiserver-minikube 1/1 Running
kube-system kube-controller-manager-minikube 1/1 Running
kube-system kube-proxy-zvf2h 1/1 Running
kube-system kube-scheduler-minikube 1/1 Running
kube-system nginx-ingress-controller-6fc5bcc 1/1 Running Найдите pod Ingress’а (он может относиться к другому пространству имен) и выполните команду describe, чтобы узнать номера портов:
kubectl describe pod nginx-ingress-controller-6fc5bcc
--namespace kube-system
| grep Ports
Ports: 80/TCP, 443/TCP, 18080/TCPНаконец, подключитесь к pod’у:
kubectl port-forward nginx-ingress-controller-6fc5bcc 3000:80 --namespace kube-systemТеперь каждый раз, когда вы будете посылать запрос на порт 3000 на компьютере, он будет перенаправляться на порт 80 pod’а с контроллером Ingress. Перейдя на , вы должны будете увидеть страницу, созданную приложением.
Резюме по портам
Давайте еще раз вспомним о том, какие порты и лейблы должны совпадать:
- Селектор в определении Service должен совпадать с лейблом pod’а;
-
targetPortв определении Service должен совпадать сcontainerPortконтейнера внутри pod’а; -
portв определении Service может быть любым. Разные сервисы могут использовать один и тот же порт, поскольку у них разные IP-адреса; -
servicePortIngress’а должен совпадать сportв определении Service; - Название сервиса должно совпадать с полем
serviceNameв Ingress’е.
Увы, недостаточно знать, как правильно структурировать YAML-конфигурацию.
Что случается, когда что-то идет не так?
Возможно, pod не запускается или он падает.
3 шага для диагностики неисправностей в приложениях в Kubernetes
Прежде чем приступать к отладке deployment’а, необходимо иметь хорошее представление о том, как работает Kubernetes.
Поскольку в каждом выкаченном в K8s приложении имеются три компонента, проводить их отладку следует в определенном порядке, начиная с самого низа.
- Сначала надо убедиться, что pod’ы работают, затем…
- Проверить, поставляет ли сервис трафик pod’ам, а потом…
- Проверить, правильно ли настроен Ingress.
Визуальное представление:
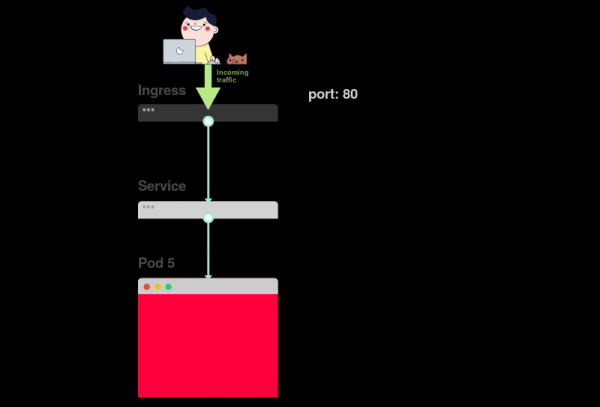
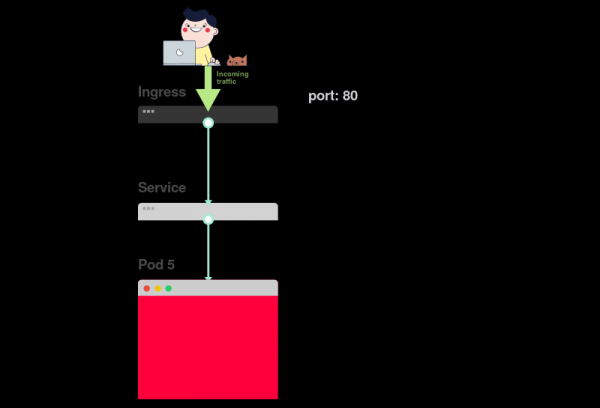
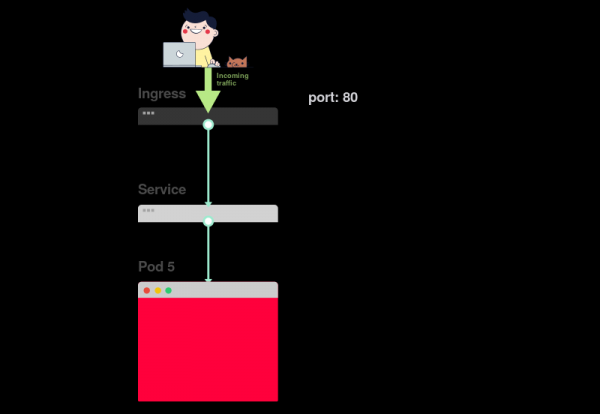
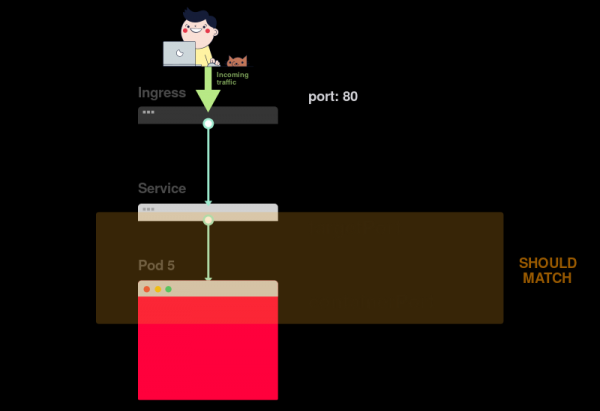
1) Начинать поиск проблем следует с самого низа. Сперва проверьте, что pod’ы имеют статусы Ready и Running:
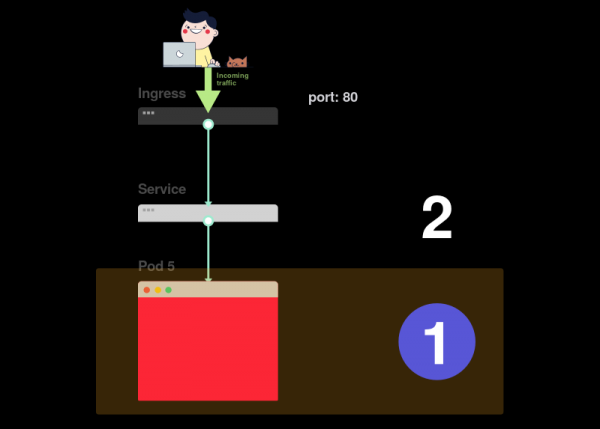
2) Если pod’ы готовы (Ready), следует выяснить, распределяет ли сервис трафик между pod’ами:
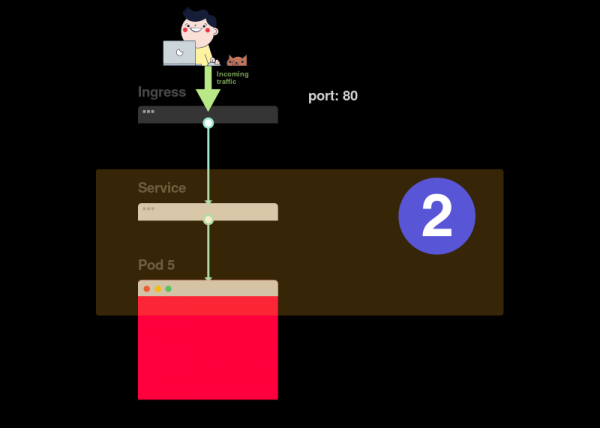
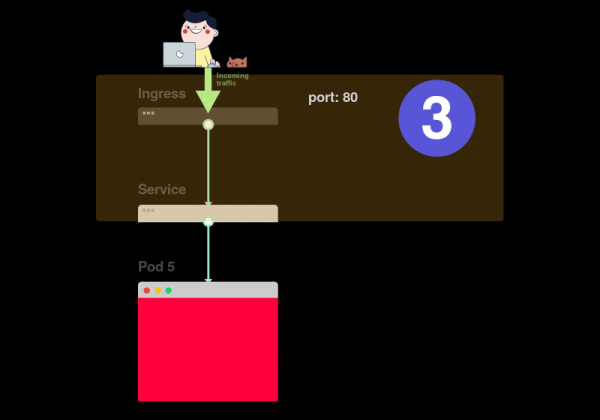
3) Наконец, нужно проанализировать связь сервиса и Ingress’а:
1. Диагностика pod’ов
В большинстве случаев проблема связана с pod’ом. Убедитесь, что pod’ы значатся как Ready и Running. Проверить это можно с помощью команды:
kubectl get pods
NAME READY STATUS RESTARTS AGE
app1 0/1 ImagePullBackOff 0 47h
app2 0/1 Error 0 47h
app3-76f9fcd46b-xbv4k 1/1 Running 1 47h В выводе команды, приведенном выше, последний pod значится как Running и Ready, однако для двух других это не так.
Как понять, что пошло не так?
Есть четыре полезные команды для диагностики pod’ов:
-
kubectl logs <имя pod'а>позволяет извлечь логи из контейнеров в pod’е; -
kubectl describe pod <имя pod'а>позволяет просмотреть список событий, связанных с pod’ом; -
kubectl get pod <имя pod'а>позволяет получить YAML-конфигурацию pod’а, хранящуюся в Kubernetes; -
kubectl exec -ti <имя pod'а> bashпозволяет запустить интерактивную командную оболочку в одном из контейнеров pod’а
Какую из них выбрать?
Дело в том, что нет универсальной команды. Следует использовать их комбинацию.
Типичные проблемы pod’ов
Существует два основных типа ошибок pod’ов: ошибки во время запуска (startup) и ошибки во время работы (runtime).
Ошибки запуска:
-
ImagePullBackoff -
ImageInspectError -
ErrImagePull -
ErrImageNeverPull -
RegistryUnavailable -
InvalidImageName
Runtime-ошибки:
-
CrashLoopBackOff -
RunContainerError -
KillContainerError -
VerifyNonRootError -
RunInitContainerError -
CreatePodSandboxError -
ConfigPodSandboxError -
KillPodSandboxError -
SetupNetworkError -
TeardownNetworkError
Некоторые ошибки встречаются чаще, чем другие. Вот несколько наиболее распространенных ошибок и способы их устранения.
ImagePullBackOff
Эта ошибка появляется, когда Kubernetes не может получить образ для одного из контейнеров pod’а. Вот три самых распространенных причины этого:
- Неверно указано имя образа — например, вы сделали в нем ошибку, или образ не существует;
- Указан несуществующий тег для образа;
- Образ хранится в закрытом реестре, и у Kubernetes нет полномочий для доступа к нему.
Первые две причины устранить легко — достаточно поправить имя образа и тег. В случае последней необходимо внести учетные данные к закрытому реестру в Secret и добавить ссылки на него в pod’ы. В документации Kubernetes того, как это можно сделать.
CrashLoopBackOff
Kubenetes выводит ошибку CrashLoopBackOff, если контейнер не может запуститься. Обычно такое случается, когда:
- В приложении есть ошибка, которая не позволяет его запустить;
- Контейнер ;
- Тест Liveness завершился неудачно слишком много раз.
Необходимо попытаться добраться до логов из контейнера, чтобы выяснить причину его сбоя. Если получить доступ к логам затруднительно, поскольку контейнер слишком быстро перезапускается, можно воспользоваться следующей командой:
kubectl logs <pod-name> --previousОна выводит сообщения об ошибках из предыдущей реинкарнации контейнера.
RunContainerError
Эта ошибка возникает, когда контейнер не в состоянии запуститься. Она соответствует моменту до запуска приложения. Обычно ее причиной является неправильная настройка, например:
- попытка примонтировать несуществующий том, такой как ConfigMap или Secrets;
- попытка примонтировать том типа read-only как read-write.
Для анализа подобных ошибок хорошо подходит команда kubectl describe pod <pod-name>.
Pod’ы в состоянии Pending
После создания pod остается в состоянии Pending.
Почему такое происходит?
Вот возможные причины (я исхожу из предположения, что планировщик работает нормально):
- В кластере недостаточно ресурсов, таких как вычислительная мощность и память, для запуска pod’а.
- В соответствующем пространстве имен установлен объект
ResourceQuotaи создание pod’а приведет к тому, что пространство имен выйдет за пределы квоты. - Pod привязан к Pending
PersistentVolumeClaim.
В этом случае рекомендуется воспользоваться командой kubectl describe и проверить раздел Events:
kubectl describe pod <pod name> В случае ошибок, связанных с ResourceQuotas, рекомендуется просмотреть логи кластера с помощью команды
kubectl get events --sort-by=.metadata.creationTimestampPod’ы не в состоянии Ready
Если pod значится как Running, но не находится в состоянии Ready, значит проверка его готовности (readiness probe) завершается неудачно.
Когда такое происходит, pod не подключается к сервису, и трафик на него не поступает. Сбой теста readiness вызван проблемами в приложении. В этом случае для поиска ошибки необходимо проанализировать раздел Events в выводе команды kubectl describe.
2. Диагностика сервисов
Если pod’ы значатся как Running и Ready, но ответа от приложения по-прежнему нет, следует проверить настройки сервиса.
Сервисы занимаются маршрутизацией трафика к pod’ам в зависимости от их лейблов. Поэтому первое, что нужно сделать — проверить, сколько pod’ов работают с сервисом. Для этого можно проверить endpoint’ы в сервисе:
kubectl describe service <service-name> | grep Endpoints Endpoint — это пара значений вида <IP-адрес:порт>, и в выводе должна присутствовать хотя бы одна такая пара (то есть с сервисом работает хотя бы один pod).
Если раздел Endpoins пуст, возможны два варианта:
- нет ни одного pod’а с правильным лейблом (подсказка: проверьте, правильно ли выбран namespace);
- есть ошибка в лейблах сервиса в селекторе.
Если вы видите список endpoint’ов, но по-прежнему не можете получить доступ к приложению, то вероятным виновником является ошибка в targetPort в описании сервиса.
Как проверить работоспособность сервиса?
Независимо от типа сервиса, можно использовать команду kubectl port-forward для подключения к нему:
kubectl port-forward service/<service-name> 3000:80Здесь:
-
<service-name>— имя сервиса; - 3000 — порт, который вы открываете на компьютере;
- 80 — порт на стороне сервиса.
3. Диагностика Ingress
Если вы дочитали до этого места, то:
- pod’ы значатся как
RunningиReady; - сервис успешно распределяет трафик по pod’ам.
Однако вы по-прежнему не можете «достучаться» до приложения.
Это означает, что, скорее всего, неправильно настроен контроллер Ingress. Поскольку контроллер Ingress является сторонним компонентом в кластере, существуют различные методы отладки в зависимости от его типа.
Но прежде чем прибегнуть к помощи специальных инструментов для настройки Ingress’а, можно сделать нечто совсем простое. Ingress использует serviceName и servicePort для подключения к сервису. Необходимо проверить, правильно ли они настроены. Сделать это можно с помощью команды:
kubectl describe ingress <ingress-name> Если столбец Backend пуст, высока вероятность ошибки в конфигурации. Если бэкэнды на месте, но доступа к приложению по-прежнему нет, то проблема может быть связана с:
- настройками доступности Ingress’а из публичного интернета;
- настройками доступности кластера из публичного интернета.
Выявить проблемы с инфраструктурой можно, подключившись напрямую к pod’у Ingress’а. Для этого сначала найдите pod Ingress-контроллера (он может находиться в другом пространстве имен):
kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS
kube-system coredns-5644d7b6d9-jn7cq 1/1 Running
kube-system etcd-minikube 1/1 Running
kube-system kube-apiserver-minikube 1/1 Running
kube-system kube-controller-manager-minikube 1/1 Running
kube-system kube-proxy-zvf2h 1/1 Running
kube-system kube-scheduler-minikube 1/1 Running
kube-system nginx-ingress-controller-6fc5bcc 1/1 Running Воспользуйтесь командой describe, чтобы установить порт:
kubectl describe pod nginx-ingress-controller-6fc5bcc
--namespace kube-system
| grep PortsНаконец, подключитесь к pod’у:
kubectl port-forward nginx-ingress-controller-6fc5bcc 3000:80 --namespace kube-systemТеперь все запросы на порт 3000 на компьютере будут перенаправляться на порт 80 pod’а.
Работает ли он теперь?
- Если да, то проблема с инфраструктурой. Необходимо выяснить, как именно осуществляется маршрутизация трафика в кластер.
- Если нет, то проблема с контроллером Ingress.
Если не получается заставить работать контроллер Ingress, придется провести его отладку.
Существует много разновидностей контроллеров Ingress. Самыми популярными являются Nginx, HAProxy, Traefik и др. (подробнее о существующих решениях см. в — прим. перев.) Следует воспользоваться руководством по устранению неполадок в документации соответствующего контроллера. Поскольку является самым популярным контроллером Ingress, мы включили в статью несколько советов по решению связанных с ним проблем.
Отладка контроллера Ingress Nginx
У проекта Ingress-nginx имеется официальный . Команду kubectl ingress-nginx можно использовать для:
- анализа логов, бэкэндов, сертификатов и т.д.;
- подключения к Ingress’у;
- изучения текущей конфигурации.
Помогут вам в этом следующие три команды:
-
kubectl ingress-nginx lint— проверяетnginx.conf; -
kubectl ingress-nginx backend— исследует бэкэнд (по аналогии сkubectl describe ingress <ingress-name>); -
kubectl ingress-nginx logs— проверяет логи.
Обратите внимание: в некоторых случаях может потребоваться указать правильное пространство имен для контроллера Ingress с помощью флага --namespace <name>.
Резюме
Диагностика в Kubernetes может оказаться непростой задачей, если не знать, с чего начать. К проблеме всегда следует подходить по принципу «снизу-вверх»: начинайте с pod’ов, а затем переходите к сервису и Ingress’у. Методы отладки, описанные в статье, могут применяться и к другим объектам, таким как:
- неработающие Job’ы и CronJob’ы;
- StatefulSet’ы и DaemonSet’ы.
Выражаю благодарность , и за ценные замечания и дополнения.
P.S. от переводчика
Читайте также в нашем блоге:
- «»;
- «»;
- «»;
- «».
Источник: habr.com
