


Когда-нибудь в далёком будущем автоматическое удаление ненужных данных будет одной из важных задач СУБД [1]. Пока же нам самим нужно заботиться об удалении или перемещении ненужных данных на менее дорогие системы хранения. Допустим, вы решили удалить несколько миллионов строк. Довольно простая задача, особенно если известно условие и есть подходящий индекс. "DELETE FROM table1 WHERE col1 = :value" — что может быть проще, да?
Видео:


Я в программном комитете Highload с первого года, т. е. с 2007-го.
И с Postgres я с 2005-го года. Использовал его во многих проектах.
Группа с RuPostges тоже с 2007-го года.
Мы на Meetup доросли до 2100+ участников. Это второе место в мире после Нью-Йорка, обогнали Сан-Франциско уже давно.
Несколько лет я живу в Калифорнии. Занимаюсь больше американскими компаниями, в том числе крупными. Они активные пользователи Postgres. И там возникают всякие интересные штуки.

– это моя компания. Мы занимаемся тем, что автоматизируем задачи, которые устраняют замедление разработки.
Если вы что-то делаете, то иногда вокруг Postgres возникают какие-то затыки. Допустим, вам нужно подождать, пока админ поднимет вам тестовый стенд, либо вам нужно подождать, пока DBA на вас отреагирует. И мы находим такие узкие места в процессе разработки, тестирования и администрирования и стараемся их устранить с помощью автоматизации и новых подходов.
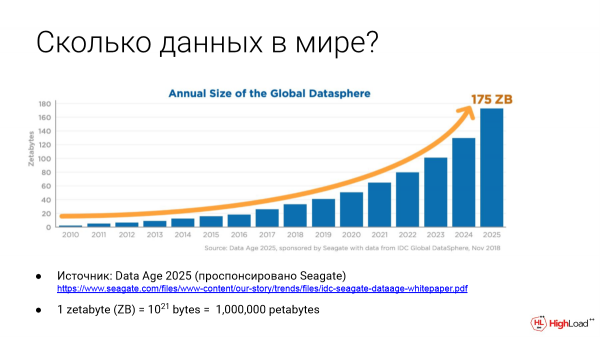
Я был недавно на VLDB в Лос-Анджелесе. Это самая большая конференция по базам данных. И там был доклад о том, что в будущем СУБД будут не только хранить, а еще и автоматически удалять данные. Это новая тема.
Данных все больше в мире зетабайт – это 1 000 000 петабайт. И сейчас уже оценивается, что у нас больше 100 зетабайт данных в мире хранится. И их становится все больше и больше.

И что с этим делать? Понятно, что надо удалять. Вот ссылка на этот интересный доклад. Но пока что в СУБД это не реализовано.
Те, кто умеют считать деньги, хотят двух вещей. Они хотят, чтобы мы удаляли, поэтому технически мы должны уметь это делать.

То, что дальше я буду рассказывать, это некоторая абстрактная ситуация, которая включает в себя кучу реальных ситуаций, т. е. некая компеляция того, что происходило на самом деле со мной и окружающими базами данных много раз, много лет. Грабли везде и на них всё время все наступают.

Допустим у нас есть база или несколько баз, которые растут. И некоторые записи – это очевидный мусор. Например, пользователь что-то там начал делать, не закончил. И через какое-то время мы знаем, что это незаконченное можно уже не хранить. Т. е. какие-то мусорные вещи мы хотели бы почистить, чтобы сэкономить место, улучшить производительность и т. д.

В общем, ставится задача автоматизировать удаление конкретных вещей, конкретных строчек в какой-то таблице.

И у нас есть такой запрос, о котором мы будем сегодня говорить, т. е. про удаление мусора.

Попросили опытного разработчика это сделать. Он взял этот запрос, проверил у себя – все работает. Протестировал на staging – все хорошо. Выкатили – все работает. Раз в сутки мы запускаем это – все хорошо.

БД растет и растет. Ежесуточный DELETE немножко медленней работать начинает.

Потом мы понимаем, что у нас сейчас маркетинговая компания и трафик будет в несколько раз больше, поэтому решаем лишние вещи временно на паузу поставить. И забываем вернуть.

Через несколько месяцев вспомнили. А тот разработчик уволился или занят чем-то другим, поручили другому вернуть.
Он проверил на dev, на staging – все Ок. Естественно, нужно еще почистить то, что накопилось. Он проверил, все работает.

Что случается дальше? Дальше у нас все роняется. Роняется так, что у нас в какой-то момент все ложится. Все в шоке, никто не понимает, что происходит. И потом выясняется, что дело в этом DELETE было.

Что пошло не так? Вот здесь дан список того, что могло пойти не так. Что из этого самое важное?
Например, не было review, т. е. DBA-эксперт не посмотрел. Он бы опытным взглядом сразу нашел бы проблему, к тому же у него есть доступ к prod, где накопилось несколько миллионов строчек.
Может быть, проверяли как-то не так.
Может быть железо устарело и нужно апгрейд для этой базы делать.
Или что-то с сомой базой данных не так, и нам с Postgres на MySQL надо переехать.
Или, может быть, с операцией что-то не так.
Может быть, какие ошибки в организации работы и нужно кого-то уволить, а нанять лучших людей?

Не было проверки DBA. Если DBA был бы, он увидел бы эти несколько миллионов строчек и даже без всяких экспериментов сказал бы: «Так не делают». Допустим, если бы этот код был в GitLab, GitHub и был бы процесс code review и не было такого, что без утверждения DBA эта операция пройдет на prod, то очевидно DBA сказал бы: «Так нельзя делать».

И он бы сказал, что у вас с disk IO будут проблемы и все процессы взбесятся, могут быть локи, а также вы заблокируете автовакуум на кучу минут, поэтому это не хорошо.

Вторая ошибка – проверяли не там. Мы постфактум увидели, что мусорных данных накопилось на prod много, а у разработчика не было в этой базе накопленных данных, да и на staging особо никто этот мусор не создавал. Соответственно, там было 1 000 строчек, которые быстро отработали.
Мы понимаем, что наши тесты слабые, т. е. процесс, который выстроен, не ловит проблемы. Не проводили адекватный БД-эксперимент.
Идеальный эксперимент желательно проводить на таком же оборудовании. На таком же оборудовании не всегда получается это сделать, но очень важно, чтобы это была полноразмерная копия базы данных. Это то, что я проповедаю уже несколько лет. И год назад я об этом говорил, можете в YouTube это все посмотреть.
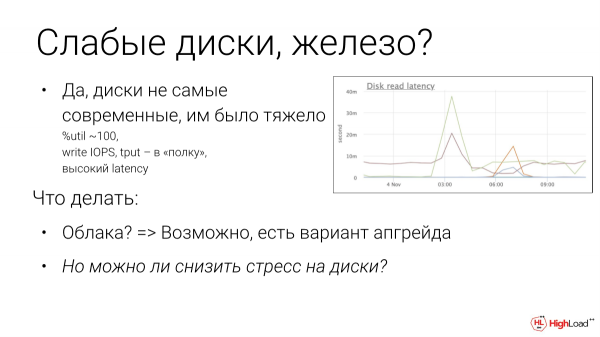
Может быть, у нас оборудование плохое? Если посмотреть, то latency подскочило. Мы увидели, что утилизация 100 %. Конечно, если это были бы современные NVMe диски, то, наверное, нам было бы намного легче. И, возможно, мы бы не легли от этого.
Если у вас облака, то там апгрейд легко делается. Подняли новые реплики на новом железе. Switchover. И все хорошо. Довольно легко.
А можно ли как-то поменьше диски трогать? И тут как раз с помощью DBA мы ныряем в некоторую тему, которая называется checkpoint tuning. Выясняется, что у нас не был проведен checkpoint tuning.
Что такое checkpoint? Это есть в любой СУБД. Когда у вас данные в памяти меняются, они не сразу записываются на диски. Информация о том, что данные изменились, сначала записывается в опережающий журнал, в write-ahead log. И в какой-то момент СУБД решает, что пора уже реальные страницы на диск скинуть, чтобы, если у нас будет сбой, поменьше делать REDO. Это как в игрушке. Если нас убьют, мы будем начинать игру с последнего checkpoint. И все СУБД это реализуют.
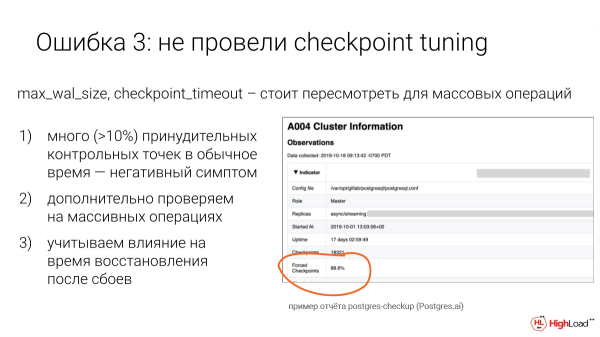
Настройки в Postgres отстают. Они рассчитана на 10-15-летней давности объемы данных и операций. И checkpoint – не исключение.
Вот эта информация из нашего отчета c Postgres check-up, т. е. автоматическая проверка здоровья. И вот какая-то база в несколько терабайт. И видно хорошо, что принудительные checkpoints почти в 90 % случаев.
Это что значит? Там есть две настройки. Checkpoint может по timeout наступить, например, в 10 минут. Или он может наступить, когда наполнилось довольно много данных.
И по умолчанию max_wal_saze выставлен в 1 гигабайт. По факту, это реально случается в Postgres через 300-400 мегабайт. Вы поменяли столько данных и у вас checkpoint случается.
И если это никто не тюнил, а сервис вырос, и компания зарабатывает кучу денег, у нее много транзакций, то checkpoint наступает раз в минуту, иногда и раз в 30 секунд, а иногда даже и накладываются друг на друга. Это совсем уже плохо.
И нам нужно сделать так, чтобы он наступал пореже. Т. е. мы можем поднять max_wal_size. И он будет наступать реже.
Но мы разработали у себя целую методологию, как это сделать более правильно, т. е. как принимать решение о выборе настроек, четко опираясь на конкретные данные.

Соответственно, мы делаем две серии экспериментов над базами данных.
Первая серия – мы меняем max_wal_size. И проводим массовую операцию. Сначала делаем ее на дефолтной настройке в 1 гигабайт. И делаем массовый DELETE многих миллионов строчек.
Видно, как нам тяжело. Смотрим, что disk IO очень плох. Смотрим, сколько WAL мы сгенерировали, т. к. это очень важно. Смотрим, сколько раз checkpoint случился. И видим, что нехорошо.
Дальше мы увеличиваем max_wal_size. Повторяем. Увеличиваем, повторяем. И так много раз. В принципе, 10 точек – это хорошо, где 1, 2, 4, 8 гигабайт. И смотрим поведение конкретной системы. Понятно, что здесь оборудование должно быть как на prod. У вас должны быть те же диски, сколько же памяти и настройки Postgres такие же.
И таким образом мы обменяем нашу систему, и знаем, как будет себя вести СУБД при плохом массовом DELETE, как будет она checkpoint’иться.
Checkpoint по-русски – это контрольные точки.
Пример: DELETE несколько млн строк по индексу, строки «разбросаны» по страницам.
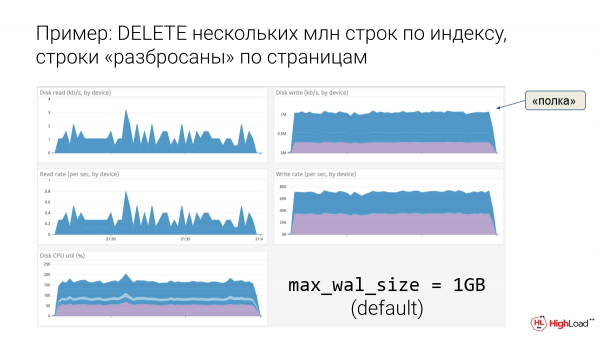
Вот пример. Это некоторая база. И при дефолтной настройке в 1 гигабайт для max_wal_size очень хорошо видно, что у нас диски на запись идут в полку. Вот такая картинка – это типичный симптом очень больного пациента, т. е. ему реально было плохо. И тут была одна единственная операция, тут был как раз DELETE нескольких миллионов строчек.
Если такую операцию пускать в prod, то как раз мы и ляжем, потому что видно, что один DELETE убивает нас в полку.
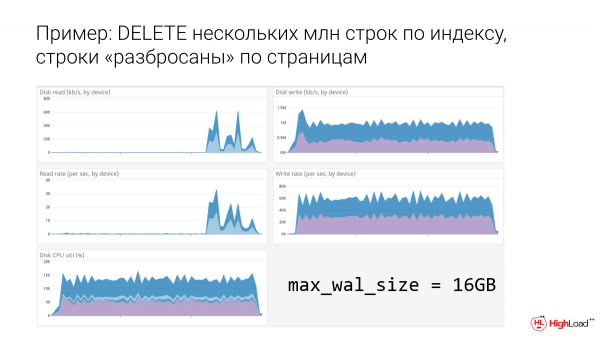
Дальше, где 16 гигабайт, видно, что уже зубчики пошли. Зубчики – это уже лучше, т. е. мы стучимся о потолок, но уже не так плохо. Небольшая свобода там появилась. Справа – это запись. И количество операций – второй график. И видно, что мы уже немного полегче задышали, когда 16 гигабайт.
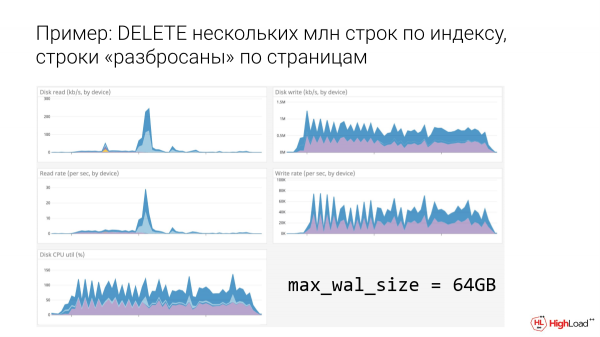
А где 64 гигабайт видно, что совсем лучше стало. Уже зубчики ярко выраженные, появляется больше возможностей, чтобы выжить другим операциям и что-то сделать с диском.
Почему так?

Я буду немножко окунаться в подробности, но эта тема, как проводить checkpoint tuning, может вылиться в целый доклад, поэтому я не буду сильно грузить, но немножко обозначу, какие там сложности есть.
Если checkpoint слишком часто случается, и мы обновляем наши строчки не последовательно, а находим по индексу, что хорошо, потому что мы не всю таблицу удаляет, то может случится так, что сначала мы первую страничку потрогали, потом тысячную, а потом вернулись к первой. И если между этими заходами в первую страничку checkpoint ее уже на диск сохранил, то он еще раз будет ее сохранять, потому что мы ее второй раз попачкали.
И мы будем заставлять checkpoint ее много раз сохранять. Как бы возникают избыточные операции для него.

Но это еще не все. В Postgres странички весят 8 килобайт, а в Linux 4 килобайт. И есть настройка full_page_writes. По умолчанию она включена. И это правильно, потому что, если мы ее выключим, то есть опасность, что при сбое только половинка странички сохранится.
Поведение записи в WAL опережающего журнала такое, что, когда у нас checkpoint случился и мы страничку в первый раз меняем, то в опережающий журнал попадает вся страница целиком, т. е. все 8 килобайт, хотя мы меняли только строчку, которая весит 100 байт. И мы вынуждены целиком страницу записать.
В последующих изменениях будут уже только конкретный кортеж, но в первый раз всю записываем.
И, соответственно, если checkpoint еще раз случился, то мы должны снова с нуля все начинать и всю страничку запихивать. При частых checkpoints, когда мы гуляем по одним и тем же страничкам, full_page_writes = on будет больше, чем могло бы быть, т. е. мы больше WAL генерируем. Больше отправляется на реплики, в архив, на диск.
И, соответственно, две избыточности у нас возникают.

Если мы увеличиваем max_wal_size, получается, что мы облегчаем работу и checkpoint, и wal writer. И это классно.
Давайте поставим терабайт и будем с этим жить. Что в этом плохого? Это плохо, потому что в случае сбоя мы будем подниматься часами, потому что checkpoint был давно и уже многое изменилось. И нам на все это REDO надо сделать. И поэтому мы делаем вторую серию экспериментов.
Мы делаем операцию и смотрим, когда checkpoint близок к тому, чтобы завершится, мы делаем kill -9 Postgres специально.
И после этого стартуем его заново, и смотрим, как долго он будет подниматься на этом оборудовании, т. е. сколько он будет делать REDO в этой плохой ситуации.
Дважды отмечу, что ситуация плохая. Во-первых, мы упали прямо перед завершением checkpoint, соответственно, нам проигрывать много надо. И, во-вторых, у нас была массивная операция. И если бы checkpoints были по тайм-ауту, то, скорее всего, меньше WAL сгенерировалось бы с момента последнего checkpoint. Т. е. это дважды неудачник.
Мы замеряем такую ситуацию для разного размера max_wal_size и понимаем, что, если max_wal_size 64 гигабайта, то в двойной худшей ситуации мы будем подниматься 10 минут. И думаем – устраивает нас это или нет. Это бизнес-вопрос. Мы должны показать эту картину тем, кто отвечает за бизнес-решения и спросить: «Сколько мы можем пролежать максимум в случае проблемы? Можем ли мы полежать в худшей ситуации 3-5 минут?». И принимаете решение.
И тут есть интересный момент. У нас на конференции есть пара докладов про Patroni. И, возможно, вы его используете. Это autofailover для Postgres. GitLab и Data Egret об этом рассказывали.
И если у вас есть autofailover, который наступит через 30 секунд, то может быть мы и 10 минут можем пролежать? Потому что мы к этому моменту переключимся на реплику, и все будет хорошо. Это вопрос спорный. Я не знаю четкого ответа. Я только ощущаю, что не только вокруг восстановления после сбоя эта тема.
Если у нас долгое восстановление после сбоя, то нам будет неудобно во многих других ситуациях. Например, в тех же экспериментах, когда мы что-то делаем и вынуждены иногда ждать по 10 минут.
Я бы все-таки не ходил слишком далеко, даже если у нас есть autofailover. Как правило, такие значения, как 64, 100 гигабайт – это хорошие значения. Иногда даже стоит меньше выбрать. В общем, это тонкая наука.

Вам, чтобы итерации делать, например, max_wal_size =1, 8, нужно повторять массовую операцию много раз. Вы ее сделали. И на той же базе хотите ее еще раз сделать, но вы же уже все удалили. Что делать?
Я попозже расскажу про наше решение, что мы делаем для того, чтобы итерировать в таких ситуациях. И это самый правильный подход.
Но в данном случае нам повезло. Если, как здесь написано «BEGIN, DELETE, ROLLBACK», то мы можем DELETE повторять. Т. е. если мы его отменили сами, то мы можем его повторять. И физически у вас данные будут там же лежать. У вас даже bloat никакого не образуется. Вы можете итерировать на таких DELETE.
Такой DELETE c ROLLBACK идеальный для checkpoint tuning, даже если у вас нет нормально развернутой database labs.

Мы сделали табличку с одной колонкой «i». У Postgres есть служебные колонки. Они невидимые, если их специально не попросить. Это: ctid, xmid, xmax.
Ctid – это физический адрес. Нулевая страница, первый кортеж в странице.
Видно, что после ROOLBACK кортеж остался на том же месте. Т. е. мы можем еще раз попробовать, оно будет себя вести так же. Это главное.
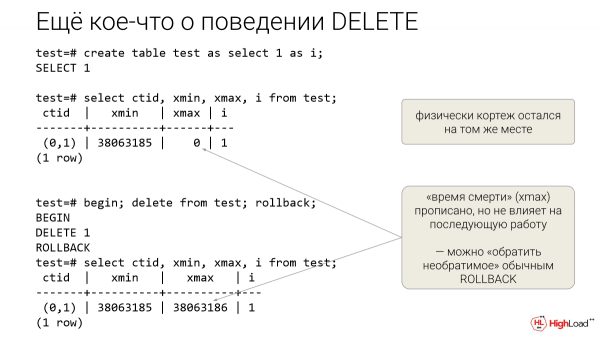
Xmax – это время смерти кортежа. Он проставился, но Postgres знает, что эта транзакция была откачена, поэтому, что 0, что откаченная транзакция – неважно. Это говорит о том, что по DELETE можно итерировать и проверять массовые операции поведения системы. Можно сделать database labs для бедных.

Это уже про программистов. Про DBA тоже, они всегда за это программистов ругают: «Зачем вы делаете такие долгие и тяжелые операции?». Это совершенно другая перпендикулярная тема. Раньше было администрирование, а сейчас будет разработка.
Очевидно, что мы не разбили на части. Это понятно. Нельзя такой DELETE для кучи миллионов строк не разбивать на части. Он будет делаться 20 минут, и все будет лежать. Но, к сожалению, ошибки совершают даже опытные разработчики, даже в очень крупных компаниях.
Почему важно разбивать?
Если мы видим, что диску тяжело, то давайте замедлим. И если у нас разбито, то мы можем паузы добавить, можем замедлить throttling.
И мы других не будем блокировать надолго. В некоторых случаях это неважно, если вы удаляете реальный мусор, с которым никто не работает, то, скорее всего, вы никого не заблокируете, кроме работы autovacuum, потому что он будет ждать, когда транзакция завершится. Но если вы удаляете то, что кто-то может еще запросить, то они будут блокироваться, пойдет какая-то цепная реакция. На сайтах и в мобильных приложениях нужно избегать долгих транзакций.

Это интересно. Я часто встречаю, что разработчики спрашивают: «Какой размер пачки выбрать?».
Понятно, чем больше размер пачки, тем меньше transaction overhead, т. е. дополнительные накладные расходы от транзакций. Но при этом время увеличивается у этой транзакции.
У меня есть очень простое правило: возьмите как можно больше, но не превышайте выполнения в секунду.
Почему секунду? Объяснение очень простое и понятное всем, даже не техническим людям. Мы видим реакцию. Возьмем 50 миллисекунд. Если что-то изменилось, то глаз наш среагирует. Если меньше, то сложнее. Если что-то отвечает через 100 миллисекунд, например, вы мышкой нажали, и оно вам через 100 миллисекунд ответило, вы уже чувствуете эту небольшую задержку. Секунда уже воспринимается как тормоза.
Соответственно, если мы наши массовые операции разобьем на 10-ти секундные пачки, то у нас есть риск, что мы кого-то заблочим. И он будет работать несколько секунд, и это люди уже заметят. Поэтому я предпочитаю больше секунды не делать. Но в то же время и совсем мелко не разбивать, потому что transaction overhead будет заметен. Базе будет тяжелее, могут возникнуть еще другие разные проблемы.
Мы подбираем размер пачки. В каждом случае можем по-разному это делать. Можно автоматизировать. И убеждаемся в эффективности работы обработки одной пачки. Т. е. мы делаем DELETE одной пачки или UPDATE.
Кстати, все, что я рассказываю, это не только про DELETE. Как вы догадались, это любые массовые операции над данными.
И мы смотрим, что план отличный. Видно index scan, еще лучше index only scan. И у нас небольшое количество данных задействовано. И все меньше секунды отрабатывает. Супер.
И мы еще должны убедиться, что деградации нет. Бывает, что первые пачки быстро отрабатывают, а потом все хуже-хуже и хуже. Процесс такой, что надо много тестировать. Для этого как раз и нужна database labs.
И мы еще должны подготовить что-то, чтобы это нам позволило в production за этим правильно следить. Например, мы можем в логе писать время, можем писать, где мы сейчас и кого мы сейчас удалили. И это нам позволит потом понимать, что происходит. И в случае, если что-то пойдет не так, быстро найти эту проблему.
Если нам нужно проверить эффективность запросов и нам нужно итерировать много раз, то как раз есть такая штука, как товарищ бот. Он уже готов. Он используется десятками разработчиками ежедневно. И он умеет огромную терабайтную базу дать по запросу за 30 секунд, вашу собственную копию. И вы можете что-то там удалить и сказать RESET, и еще раз удалить. Вы можете с ним экспериментировать таким образом. Я вижу за этой штукой будущее. И мы это уже делаем.

Какие есть стратегии разбиения? Я вижу 3 разные стратегии разбиения, которые используют разработчики на пачке.
Первая очень простая. У нас есть айдишник числовой. И давайте мы разобьем на разные интервалы, и будем работать с этим. Минус понятен. В первом отрезке у нас реального мусора может попасть 100 строчек, во втором 5 строчек или вообще не попасть, или все 1 000 строчек окажутся мусором. Очень неравномерная работа, но зато разбивать легко. Взяли максимальный ID и разбили. Это наивный подход.
Вторая стратегия – это сбалансированный подход. Он используется в Gitlab. Взяли и просканировали таблицу. Обнаружили границы пачек ID так, чтобы каждая пачка была ровно по 10 000 записей. И засунули в какую-то очередь. И дальше обрабатываем. Можно это делать в несколько потоков.
В первой стратегии тоже, кстати, можно это делать в несколько потоков. Это не сложно.

Но есть более классный и оптимальный подход. Это третья стратегия. И когда это возможно, то лучше ее выбирать. Мы на основе специального индекса это делаем. В данном случае это будет, скорее всего, индекс по нашему условию мусора и ID. Мы включим ID, чтобы это был index only scan, чтобы мы в heap не ходили.
Как правило, index only scan – это быстрее, чем index scan.
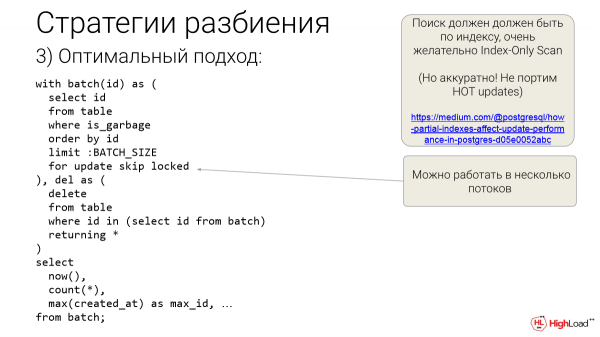
И мы быстро находим наши айдишники, которые мы хотим удалить. BATCH_SIZE мы подбираем заранее. И мы их не только получаем, мы их получаем специальным образом и тут же лочим. Но так лочим, что, если они уже залочены, мы их не лочим, а едем дальше и берем следующие. Это for update skip locked. Эта суперфича Postgres нам позволяет в несколько потоков работать, если мы хотим. Можно в один поток. И тут есть CTE – это один запрос. И у нас во втором этаже этого CTE происходит реальное удаление – returning *. Можно returning id, но лучше *, если у вас данных немного в каждой строчке.

Зачем нам это нужно? Этом нам нужно для того, чтобы отчитаться. Мы сейчас удалили столько строчек по факту. И у нас границы по ID или по created_at вот такие-то. Можно min, max сделать. Еще что-то можно сделать. Тут можно многое запихать. И это для мониторинга очень удобно.
Насчет индекса есть еще одно замечание. Если мы решили, что нам именно для этой задачи нужен специальный индекс, то нужно убедиться, что он не испортит heap only tuples updates. Т. е. в Postgres есть такая статистика. Это можно посмотреть в pg_stat_user_tables для вашей таблицы. Вы можете посмотреть – используется ли hot updates или нет.
Бывают ситуации, когда ваш новый индекс может их просто обрубить. И у вас все другие updates, которые уже работают, замедлятся. Не просто потому что индекс появился (каждый индекс чуть-чуть замедляет updates, но чуть-чуть), а тут он еще испортит. И специальную оптимизацию сделать для этой таблицы невозможно. Такое иногда бывает. Это такая тонкость, про которую мало кто помнит. И на эти грабли легко наступить. Иногда бывает, что нужно подход с другой стороны найти и все-таки обойтись без этого нового индекса, либо сделать другой индекс, либо еще как-нибудь, например, можно использовать второй метод.
Но это самая оптимальная стратегия, как разбивать на batches и одним запросом стрелять по пачкам, удалять по чуть-чуть и т. д.

Долгие транзакции —
Blocked autovacuum —
Blocking issue —
Ошибка № 5 большая. Николай из Okmeter рассказывал про мониторинг Postgres. Идеального мониторинга Postgres, к сожалению, не существует. Кто-то ближе, кто-то дальше. Okmeter – достаточно близок к тому, чтобы быть идеальным, но много чего не хватает и нужно добавлять. К этому нужно быть готовым.
Например, dead tuples лучше мониторить. Если у вас много мертвечины в таблице, то тут что-то не так. Лучше реагировать сейчас, а то там может быть деградация, и мы можем лечь. Такое бывает.
Если большое IO, то понятно, что это нехорошо.
Долгие транзакции тоже. На OLTP долгие транзакции не стоит пускать. И вот здесь ссылка на сниппет, которая позволяет взять этот сниппет и уже сделать некоторое слежение за долгими транзакциями.
Почему долгие транзакции – это плохо? Потому что все локи отпустятся только в конце. И мы лочим всех. Плюс мы блокируем работу autovacuum для всех таблиц. Это вообще не хорошо. Даже если на реплике у вас hot standby включен, это все равно плохо. В общем, нигде лучше не допускать долгих транзакций.
Если у нас много таблиц не вакуумятся, то нужно alert иметь. Тут возможна такая ситуация как раз. Мы косвенно можем повлиять на работу autovacuum. Это сниппет от Avito, который я немножко улучшил. И получился интересный инструмент, чтобы посмотреть, что у нас с autovacuum. Например, там ждут какие-то таблицы и не дождутся своей очереди. Тоже надо засунуть в мониторинг и alert иметь.
И блоки issues. Лес деревьев блокировок. Я люблю у кого-то что-то взять и улучшить. Здесь от Data Egret взял классный рекурсивный CTE, который показывает лес деревьев блокировок. Это хорошая штука для диагностики. И на ее основе тоже можно соорудить мониторинг. Но это надо аккуратно делать. Нужно самому себе statement_timeout маленький сделать. И lock_timeout желательно.

Иногда все эти ошибки встречается в сумме.
На мой взгляд, самая главная ошибка здесь – это организационная. Она организационная, потому что техника не тянет. Это номер 2 – проверяли не там.
Мы проверяли не там, потому что у нас не было клона production, на котором легко проверить. У разработчика вообще может не быть доступа к production.
И мы проверяли не там. Если бы проверяли там, там мы сами бы это увидели. Разработчик и без DBA это все увидел, если он проверял это в хорошем окружении, где данных столько же и идентичное расположение. Он бы всю эту деградацию увидел бы и ему стыдно было бы.
Еще про автовакуум. После того, как мы сделали массивную зачистку нескольких миллионов строчек, еще нужно REPACK сделать. Особенно для индексов это важно. Им будет плохо после того, как мы там все почистили.
И если вы хотите вернуть ежедневную работу по зачистке, то я бы предложил это делать чаще, но мельче. Можно раз в минут или еще чаще по чуть-чуть. И нужно наладить мониторинг двух вещей: что ошибок нет у этой штучки и что она не отстает. Тот трюк, который я показывал как раз позволит это решить.
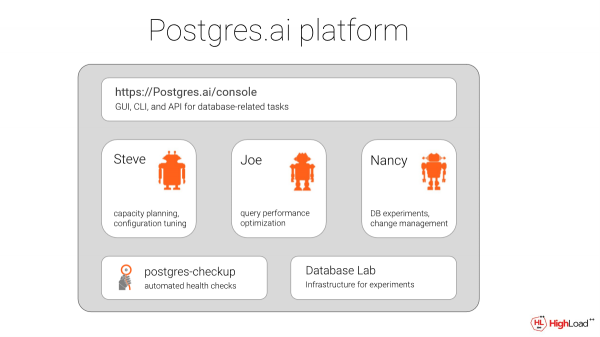
То, что мы делаем, это open source. Это выложено на GitLab. И мы делаем так, чтобы люди могли проверять даже без DBA. Мы делаем database lab, т. е. мы так называем базовый компонент, на котором сейчас работает Joe. И вы можете взять копию production. Сейчас есть реализация Joe для slack, вы можете там сказать: «explain такой-то запрос» и тут же получить результат для вашей копии базы. Вы можете там даже DELETE сделать, и никто этого не заметит.
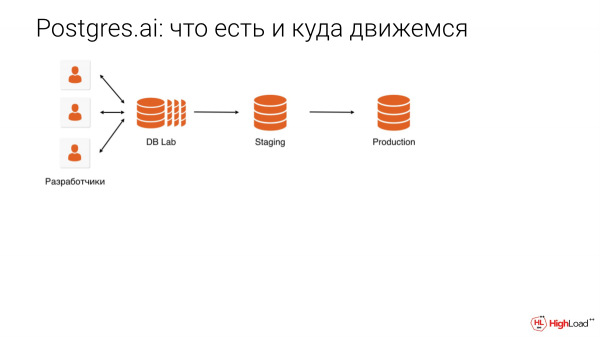
Допустим, у вас 10 терабайта, мы делаем database lab тоже 10 терабайт. И с одновременными 10-ти терабайтными базами могут работать одновременно 10 разработчиков. Каждый может делать то, что хочет. Может удалять, дропать и т. д. Вот такая фантастика. Об этом мы завтра будем говорить.
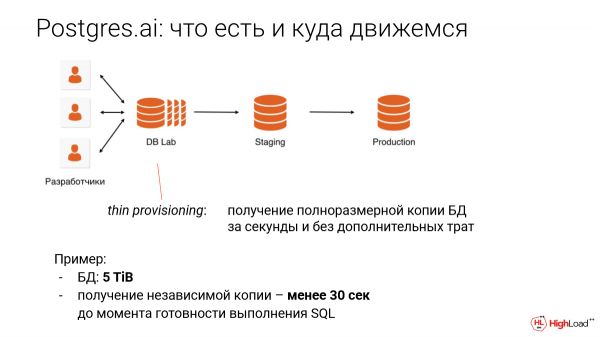
Это называется thin provisioning. Это тонкий провижинг. Это такая некоторая фантастика, которая сильно убирает задержки в разработке, в тестировании и делает мир лучше в этом плане. Т. е. как раз позволяет вам избегать проблем с массовыми операциями.
Пример: база данных в 5 терабайт, получение копии менее, чем за 30 секунд. И от размера это даже не зависит, т. е. неважно, сколько терабайт.
Уже сегодня вы можете зайти на и покопаться в наших инструментах. Вы можете зарегистрироваться, посмотреть, что там есть. Можете поставить себе этого бота. Он бесплатный. Пишите.
Вопросы
Очень часто в реальных ситуациях получается так, что данные, которые должны остаться в таблице, их гораздо меньше, чем нужно удалить. Т. е. в такой ситуации часто легче осуществить такой подход, когда проще создать новый объект, скопировать туда только нужные данные и затранкейтить старую таблицу. Понятно, что нужен программный подход для этого момента, пока у вас будет происходить переключение. Как такой подход?
Это очень хороший подход и очень хорошая задача. Она очень похожа на то, что делает pg_repack, она очень похожа на то, что вам приходится делать, когда вы айдишники сделали 4-х байтными. Многие фреймворки это делали несколько лет назад, и как раз таблички подросли, и их нужно конвертировать на 8 байт.
Эта задача довольно трудная. Мы это делали. И вам нужно быть очень аккуратными. Там локи и т. д. Но это делается. Т. е. стандартный подход поход на pg_repack. Вы объявляете такую табличку. И прежде чем в нее начать заливать данные снапшотом, вы еще объявляете одну табличку, которая все изменения отслеживает. Там есть хитрость, что некоторые изменения вы можете даже не отслеживать. Есть тонкости. И потом вы переключаетесь, накатив изменения. Там будет недолгая пауза, когда мы всех залочим, но в целом это делается.
Если вы pg_repack на GitHub посмотрите, то там, когда была задача конвертировать айдишник с int 4 на int 8, то была идея сам pg_repack использовать. Это тоже возможно, но это немножко хакерский метод, но он тоже для этого подойдет. Вы можете вмешаться в триггер, который использует pg_repack и там сказать: «Нам эти данные не нужны», т. е. мы переливаем только то, что нам нужно. И потом он просто переключится и все.
При таком подходе мы еще получаем вторую копию таблицы, в которой данные уже индексированы и уложены очень ровно с красивыми индексами.
Bloat нет, это хороший подход. Но я знаю, что есть попытки разработать автоматизацию для этого, т. е. сделать универсальное решение. Я могу вас свести с этой автоматизацией. Она написана на Python, хорошая штука.
Я просто немножко из мира MySQL, поэтому я пришел послушать. И мы пользуемся таким подходом.
Но он только, если у нас 90 %. Если у нас 5 %, то не очень хорошо его применять.
Спасибо за доклад! Если нет ресурсов сделать полную копию prod, есть ли какой-то алгоритм или формула для того, чтобы просчитать нагрузку или размер?
Хороший вопрос. Пока что у нас получается многотерабайтные базы найти. Пусть даже там железо не такое же будет, например, поменьше памяти, поменьше процессора и диски не совсем такие же, но все-таки мы делаем это. Если совсем негде, то надо подумать. Давайте я до завтра подумаю, вы приходили, мы пообщаемся, это хороший вопрос.
Спасибо за доклад! Вы вначале начали про то, что есть крутой Postgres, у которого вот такие-то ограничения, но он развивается. А это все костыль по большему счету. Не идет ли это все в противоречие с развитием самого Postgres, в котором какой-нибудь DELETE deferent появится или что-нибудь еще, что должно поддерживать на низком уровне то, что мы пытаемся здесь обмазать какими-то своими странными средствами?
Если мы в SQL сказали удалить или проапдейтить много записей в одной транзакции, то как там Postgres может это распределить? Мы физически ограничены в операциях. Мы все равно будем это делать долго. И мы будем лочить в это время и т. д.
С индексами же сделали.
Я могу предположить, что тот же checkpoint tuning можно было автоматизировать. Когда-нибудь это, возможно, будет. Но я тогда вопрос не очень понимаю.
Вопрос в том, что нет ли такого вектора развития, который идет вот там вот, а здесь идет параллельно ваш? Т.е. там пока что про это не думают?
Я рассказал про принципы, которые можно использовать сейчас. Есть другой бот , с помощью этого можно сделать автоматизированный checkpoint tuning. Будет ли это когда-то в Postgres? Не знаю, это пока что даже не обсуждается. Мы пока далеки от этого. Но есть ученые, которые делают новые системы. И они нас пихают в автоматические индексы. Есть разработки. Например, auto tuning можете посмотреть. Он подбирает параметры автоматически. Но он вам checkpoint tuning пока не сделает. Т. е. он подберет для performance, shell buffer и т. д.
А для checkpoint tuning можно сделать такую штуку: если у вас тысяча кластеров и разные железки, разные виртуальные машины в cloud, вы можете с помощью нашего бота автоматизацию сделать. И будет подбираться max_wal_size по вашим целевым установкам автоматически. Но пока этого в ядре даже близко нет, к сожалению.
Добрый день! Вы говорили о вреде долгих транзакций. Вы говорили, что блокируются autovacuum в случае удалений. Чем еще нам это вредит? Потому что мы больше говорим об освобождении места и возможности его использовать. Что еще мы теряем?
Autovacuum – это, может быть, не самая большая проблема здесь. А то, что долгая транзакция может залочить другие транзакции, эта возможность более опасная. Она может встретиться, а может и не встретиться. Если она встретилась, то очень плохо может быть. И с autovacuum – это тоже проблема. Тут две проблемы с долгими транзакциями в OLTP: локи и autovacuum. И если у вас hot standby feedback включен на реплике, то вам еще блокировка autovacuum прилетит на мастер, она прилетит с реплики. Но, по крайней мере, там локов не будет. А здесь будут локи. Мы говорим об изменениях данных, поэтому локи – это важный здесь момент. И если это все долго-долго, то все больше транзакций лочится. Они могут лочить другие. И появляются деревья локов. Я приводил ссылку на сниппет. И эта проблема быстрее становится заметней, чем проблема с autovacuum, который может только накапливаться.
Спасибо за доклад! Вы начали свой доклад с того, что неправильно тестировали. Продолжили свою идею, что нужно взять оборудование одинаковое, с базой точно так же. Допустим, мы дали разработчику базу. И он выполнил запрос. И у него вроде бы все хорошо. Но он же не проверяет на live, а на live, например, у нас нагрузке на 60-70 %. И даже если мы используем этот тюнинг, получается не очень
Иметь в команде эксперта и пользоваться экспертам DBA, которые могут прогноз сделать, что будет при реальной фоновой нагрузке, — это важно. Когда мы просто чистые наши изменения прогнали, мы видим картину. Но более продвинутый подход, когда мы еще раз то же самое сделали, но еще со симулированной с production нагрузкой. Это совсем классно. До этого надо еще дорасти. Это по-взрослому. Мы и чисто посмотрели, что есть и еще посмотрели – хватает ли нам ресурсов. Это хороший вопрос.
Когда мы уже делаем garbage select и у нас есть, к примеру, deleted flag
Это то, что autovacuum делает автоматически в Postgres.
А, он это делает?
Autovacuum это и есть garbage collector.
Спасибо!
Спасибо за доклад! Есть ли вариант сразу проектировать базу данных с партицированием таким, чтобы весь мусор отпачковывался от основной таблицы куда-нибудь в сторону?
Конечно, есть.
Можно ли тогда обезопасить себя, если мы залочили таблицу, которая не должна использоваться?
Конечно, есть. Но это вопрос как про курицу и яйцо. Если мы все знаем, что будет в будущем, то, конечно, мы все сделаем классно. Но бизнес меняется, там появляются новые колонки, новые запросы. А потом – опа, мы хотим это удалить. Но эта идеальная ситуация, в жизни она встречается, но не всегда. Но в целом это хорошая идея. Просто truncate и все.
Источник: habr.com
