

Или как мы писали клиентскую C++ библиотеку для ZooKeeper, etcd и Consul KV
В мире распределённых систем существует ряд типовых задач: хранение информации о составе кластера, управление конфигурацией узлов, детекция сбойных узлов, выбор лидера . Для решения этих задач созданы специальные распределённые системы — сервисы координации. Сейчас нас будут интересовать три из них: ZooKeeper, etcd и Consul. Из всей богатой функциональности Consul мы сосредоточимся на Consul KV.

По сути все эти системы представляют собой отказоустойчивые линеаризуемые key-value хранилища. Хотя их модели данных и имеют существенные отличия, о чём мы поговорим позднее, они позволяют решать одни и те же практические проблемы. Очевидно, каждое приложение, использующее сервис координации, завязывается на один из них, что может приводить к необходимости поддерживать в одном датацентре несколько систем, решающих одинаковые задачи, для разных приложений.
Идея, призванная решить эту проблему, зародилась в одном австралийском консалтинговом агентстве, а нам – небольшой команде студентов – выпало её реализовывать, о чём я и собираюсь рассказать.
Нам удалось создать библиотеку, предоставляющую общий интерфейс для работы с ZooKeeper, etcd и Consul KV. Библиотека написана на C++, но есть планы по портированию на другие языки.
Модели данных
Чтобы разработать общий интерфейс для трёх разных систем, надо понять, что же у них общего, и чем они различаются. Давайте разбираться.
ZooKeeper
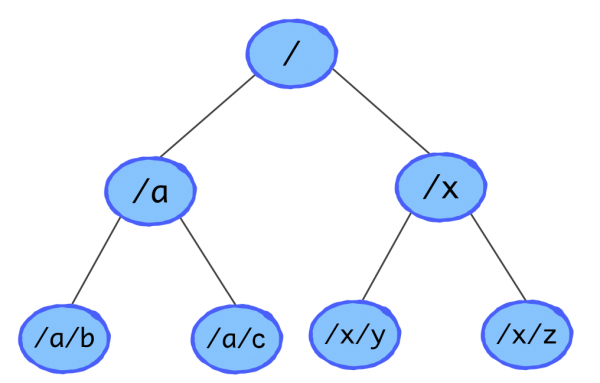
Ключи организованы в дерево и называются узлами (znodes). Соответственно, для узла можно получить список его детей. Операции создания znode (create) и изменения значения (setData) разделены: читать и изменять значения можно только у существующих ключей. К операциям проверки существования узла, чтения значения и получения детей можно привязывать watches. Watch — это одноразовый триггер, который срабатывает, когда версия соответствующих данных на сервере изменяется. Для обнаружения отказов служат эфемерные узлы. Они привязываются к сессии создавшего их клиента. Когда клиент закрывает сессию или перестаёт оповещать ZooKeeper о своём существовании, эти узлы автоматически удаляются. Поддерживаются простые транзакции – набор операций, которые либо все успешно выполняются, либо не выполняются, если хотя бы для одной из них это невозможно.
etcd
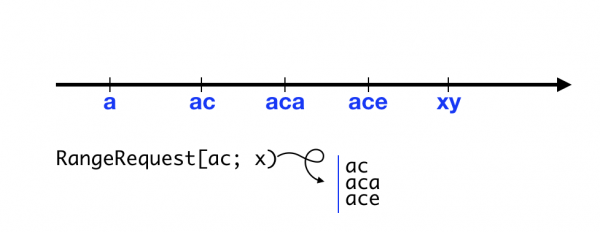
Разработчики этой системы явно вдохновлялись ZooKeeper’ом, и потому сделали всё иначе. Иерархии ключей здесь нет, но они образуют лексикографически упорядоченный набор. Можно получить или удалить все ключи, принадлежащие некоторому диапазону. Такая структура может показаться странной, но на самом деле она очень выразительна, и иерархический вид через неё легко эмулируется.
В etcd нет стандартной операции compare-and-set, но есть кое-что получше — транзакции. Конечно, они есть во всех трёх системах, но в etcd транзакции особенно хороши. Они состоят из трёх блоков: check, success, failure. Первый блок содержит набор условий, второй и третий – операции. Транзакция выполняется атомарно. Если все условия верны, то выполняется блок success, иначе – failure. В версии API 3.3 блоки success и failure могут содержать вложенные транзакции. То есть можно атомарно исполнять условные конструкции почти произвольного уровня вложенности. Подробнее узнать о том, какие существуют проверки и операции, можно из .
Watches здесь тоже существуют, хотя они устроены немного сложнее и являются многоразовыми. То есть после установки watch’а на диапазон ключей вы будете получать все обновления в этом диапазоне, пока не отмените watch, а не только первое. В etcd аналогом клиентских сессий ZooKeeper являются leases.
Consul KV
Здесь тоже нет строгой иерархической структуры, но Consul умеет создавать видимость, что она есть: можно получать и удалять все ключи с указанным префиксом, то есть работать с «поддеревом» ключа. Такие запросы называются рекурсивными. Помимо этого Consul умеет выбирать лишь ключи, не содержащие указанный символ после префикса, что соответствует получению непосредственных «детей». Но стоит помнить, что это именно видимость иерархической структуры: вполне можно создать ключ, если его родитель не существует или удалить ключ, у которого есть дети, при этом дети продолжат храниться в системе.
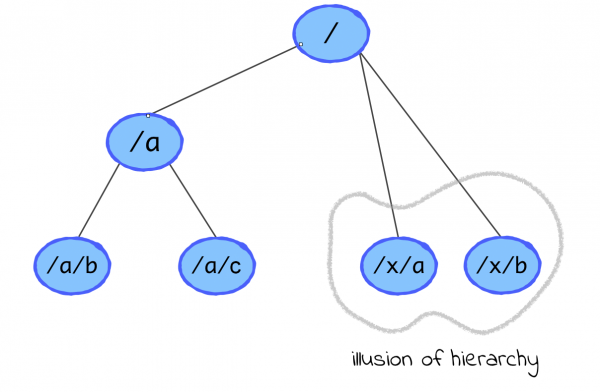
Вместо watch’ей в Consul существуют блокирующие HTTP запросы. По сути это обычные вызовы метода чтения данных, для которых наряду с остальными параметрами указывается последняя известная версия данных. Если текущая версия соответствующих данных на сервере больше указанной, ответ возвращается сразу, иначе – когда значение изменится. Здесь также есть сессии, которые в любой момент можно прикреплять к ключам. Стоит заметить, что в отличие от etcd и ZooKeeper, где удаление сессий приводит к удалению связанных ключей, здесь есть режим, при котором сессия просто от них открепляется. Доступны , без ветвлений, но со всевозможными проверками.
Сводим всё воедино
Самой строгой моделью данных обладает ZooKeeper. Выразительные запросы на диапазоны, доступные в etcd, невозможно эффективно эмулировать ни в ZooKeeper, ни в Consul. Пытаясь вобрать всё лучшее от всех сервисов, мы получили интерфейс почти эквивалентный интерфейсу ZooKeeper со следующими существенными исключениями:
- не поддерживаются
- ACL не поддерживаются
- метод set создаёт ключ, если он не существовал (в ZK setData возвращает ошибку в этом случае)
- методы set и cas разделены (в ZK это по сути одно и то же)
- метод erase удаляет вершину вместе с поддеревом (в ZK delete возвращает ошибку, если у вершины есть дети)
- для каждого ключа существует только одна версия – версия значения (в ZK )
Отказ от sequential узлов связан с тем, что в etcd и Consul для них нет встроенной поддержки, а поверх получившегося интерфейса библиотеки они могут быть легко реализованы пользователем.
Реализация аналогичного ZooKeeper поведения при удалении вершины потребовала бы поддержания в etcd и Consul для каждого ключа отдельного счётчика детей. Поскольку мы старались избегать хранения метаинформации, было решено удалять всё поддерево.
Тонкости реализации
Рассмотрим подробнее некоторые аспекты реализации интерфейса библиотеки в разных системах.
Иерархия в etcd
Поддержание иерархического вида в etcd оказалось одной из самых интересных задач. Запросы на диапазоны позволяют легко получить список ключей с указанным префиксом. Например, если вам нужно всё, что начинается с "/foo", вы запрашиваете диапазон ["/foo", "/fop"). Но это возвращало бы целиком всё поддерево ключа, что может быть неприемлемо, если поддерево большое. Сначала мы планировали использовать механизм преобразования ключей, . Он предполагает добавление в начало ключа одного байта, равного глубине узла в дереве. Приведу пример.
"/foo" -> "u01/foo"
"/foo/bar" -> "u02/foo/bar" Тогда получить всех непосредственных детей ключа "/foo" можно, запросив диапазон ["u02/foo/", "u02/foo0"). Да, в ASCII "0" стоит сразу после "/".
Но как в таком случае реализовать удаление вершины? Получается, нужно удалить все диапазоны вида ["uXX/foo/", "uXX/foo0") для XX от 01 до FF. И тут мы упёрлись в внутри одной транзакции.
В итоге была придумана простая система преобразования ключей, которая позволила эффективно реализовать и удаление ключа, и получение списка детей. Достаточно дописывать спецсимвол перед последним токеном. Например:
"/very" -> "/u00very"
"/very/long" -> "/very/u00long"
"/very/long/path" -> "/very/long/u00path" Тогда удаление ключа "/very" превращается в удаление "/u00very" и диапазона ["/very/", "/very0"), а получение всех детей – в запрос ключей из диапазона ["/very/u00", "/very/u01").
Удаление ключа в ZooKeeper
Как я уже упомянул, в ZooKeeper нельзя удалить узел, если у него есть дети. Мы же хотим удалять ключ вместе с поддеревом. Как быть? Мы делаем это оптимистично. Сначала рекурсивно обходим поддерево, получая детей каждой вершины отдельным запросом. Затем строим транзакцию, которая пытается удалить все узлы поддерева в правильном порядке. Разумеется, между чтением поддерева и удалением в нём могут произойти изменения. В таком случае транзакция провалится. Более того, поддерево может измениться ещё в процессе чтения. Запрос детей очередного узла может вернуть ошибку, если, например, эта вершина уже была удалена. В обоих случаях мы повторяем весь процесс заново.
Такой подход делает удаление ключа весьма неэффективным, если у него есть дети и тем более если приложение продолжает работать с поддеревом, удаляя и создавая ключи. Однако, это позволило не усложнять реализацию других методов в etcd и Consul.
set в ZooKeeper
В ZooKeeper отдельно существуют методы, которые работают со структурой дерева (create, delete, getChildren) и которые работают с данными в узлах (setData, getData).При этом все методы имеют строгие предусловия: create вернёт ошибку, если узел уже создан, delete или setData – если его ещё не существует. Нам же был нужен метод set, который можно вызывать, не задумываясь о наличии ключа.
Один из вариантов – применить оптимистичный подход, как при удалении. Проверить, существует ли узел. Если существует, вызвать setData, иначе – create. Если последний метод вернул ошибку, повторить всё сначала. Первое, что стоит заметить, – это бессмысленность проверки на существование. Можно сразу вызвать create. Успешное завершение будет означать, что узла не существовало и он был создан. В противном случае create вернёт соответствующую ошибку, после чего нужно вызвать setData. Конечно, между вызовами вершина может быть удалена конкурирующим вызовом, и setData тоже вернёт ошибку. В этом случае можно повторить всё заново, но стоит ли?
Если оба метода вернули ошибку, то мы точно знаем, что имело место конкурирующее удаление. Представим, что это удаление произошло после вызова set. Тогда какое бы значение мы не пытались установить, оно уже стёрто. Значит можно считать, что set выполнился успешно, даже если на самом деле ничего записать не удалось.
Более технические тонкости
В этом разделе мы отвлечёмся от распределённых систем и поговорим про кодинг.
Одним из основных требований заказчика была кроссплатформенность: в Linux, MacOS и Windows должен поддерживаться хотя бы один из сервисов. Изначально мы вели разработку только под Linux, а в остальных системах начали тестировать позже. Это вызвало массу проблем, к которым некоторое время было совершенно непонятно как подступиться. В итоге сейчас в Linux и MacOS поддерживаются все три сервиса координации, а в Windows – только Consul KV.
С самого начала для доступа к сервисам мы старались использовать готовые библиотеки. В случае с ZooKeeper выбор пал на , который в итоге так и не удалось скомпилировать в Windows. Это, впрочем, неудивительно: библиотека позиционируется как linux-only. Для Consul единственным вариантом оказался . В него пришлось добавить поддержку и . Для etcd полноценной библиотеки, поддерживающей последнюю версию протокола, так и не нашлось, поэтому мы просто .
Вдохновившись асинхронным интерфейсом библиотеки ZooKeeper C++, мы решили тоже реализовать асинхронный интерфейс. В ZooKeeper C++ для этого используются примитивы future/promise. В STL они, к сожалению, реализованы весьма скромно. Например, нет , который применяет переданную функцию к результату future, когда он становится доступен. В нашем случае такой метод необходим для преобразования результата в формат нашей библиотеки. Чтобы обойти эту проблему, пришлось реализовать свой простой пул потоков, поскольку по требованию заказчика мы не могли использовать тяжёлые сторонние библиотеки, такие как Boost.
Наша реализация then работает следующим образом. При вызове создаётся дополнительная пара promise/future. Новый future возвращается, а переданный помещается вместе с соответствующей функцией и дополнительным promise в очередь. Поток из пула выбирает из очереди несколько futures и опрашивает их, используя wait_for. Когда результат становится доступным, вызывается соответствующая функция, и её возвращаемое значение передаётся в promise.
Этот же пул потоков мы использовали для выполнения запросов к etcd и Consul. Это означает, что с нижележащими библиотеками могут работать несколько разных потоков. ppconsul не является потокобезопасным, поэтому обращения к нему защищены блокировками.
С grpc можно работать из нескольких потоков, но есть тонкости. В etcd watches реализованы через grpc streams. Это такие двунаправленные каналы для сообщений определённого типа. Библиотека создаёт единственный stream для всех watches и единственный поток, который обрабатывает поступающие сообщения. Так вот grpc запрещает производить параллельные записи в stream. Это значит, что при инициализации или удалении watch’а нужно дождаться, пока завершиться отправка предыдущего запроса, перед тем как посылать следующий. Мы используем для синхронизации .
Итог
Смотрите сами: .
Наша команда: , , , , .
Источник: habr.com
