

CAP-теорема является краеугольным камнем теории распределённых систем. Конечно, споры вокруг неё не утихают: и определения в ней не канонические, и строгого доказательства нет… Тем не менее, твёрдо стоя на позициях бытового здравого смысла™, мы интуитивно понимаем, что теорема верна.

Единственное, что не очевидно, так это значение буквы «P». Когда кластер разделился, он решает – то ли не отвечать, пока не будет набран кворум, то ли отдавать те данные, которые есть. В зависимости от результатов этого выбора система классифицируется либо как CP, либо как AP. Cassandra, например, может вести себя и так и так, в зависимости даже не от настроек кластера, а от параметров каждого конкретного запроса. Но если система не «P», и она разделилась, тогда – что?
Ответ на этот вопрос несколько неожиданный: CA-кластер не может разделиться.
Что же это за кластер, который не может разделиться?
Непременный атрибут такого кластера – общая система хранения данных. В подавляющем большинстве случаев это означает подключение через SAN, что ограничивает применение CA-решений крупными предприятиями, способными содержать SAN-инфраструктуру. Для того, чтобы несколько серверов могли работать с одними и теми же данными, необходима кластерная файловая система. Такие файловые системы есть в портфелях HPE (CFS), Veritas (VxCFS) и IBM (GPFS).
Oracle RAC
Опция Real Application Cluster впервые появилась в 2001 году в релизе Oracle 9i. В таком кластере что несколько экземпляров сервера работают с одной и той же базой данных.
Oracle может работать как с кластерной файловой системой, так и с собственным решением – ASM, Automatic Storage Management.
Каждый экземпляр ведёт свой журнал. Транзакция выполняется и фиксируется одним экземпляром. В случае сбоя экземпляра один из выживших узлов кластера (экземпляров) считывает его журнал и восстанавливают потерянные данные – за счёт этого обеспечивается доступность.
Все экземпляры поддерживают собственный кэш, и одни и те же страницы (блоки) могут находиться одновременно в кэшах нескольких экземпляров. Более того, если какая-то страница нужна одному экземпляру, и она есть в кэше другого экземпляра, он может получить его у «соседа» при помощи механизма cache fusion вместо того, чтобы читать с диска.
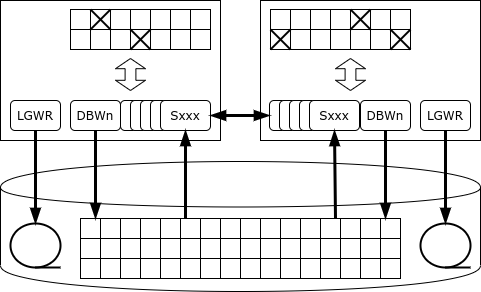
Но что произойдёт, если одному из экземпляров потребуется изменить данные?
Особенность Oracle в том, что у него нет выделенного сервиса блокировок: если сервер хочет заблокировать строку, то запись о блокировке ставится прямо на той странице памяти, где находится блокируемая строка. Благодаря такому подходу Oracle – чемпион по производительности среди монолитных баз: сервис блокировок никогда не становится узким местом. Но в кластерной конфигурации такая архитектура может приводить к интенсивному сетевому обмену и взаимным блокировкам.
Как только запись блокируется, экземпляр оповещает все остальные экземпляры о том, что страница, в которой хранится эта запись, захвачена в монопольном режиме. Если другому экземпляру понадобится изменить запись на той же странице, он должен ждать, пока изменения на странице не будут зафиксированы, т. е. информация об изменении не будет записана в журнал на диске (при этом транзакция может продолжаться). Может случиться и так, что страница будет изменена последовательно несколькими экземплярами, и тогда при записи страницы на диск придётся выяснять, у кого же хранится актуальная версия этой страницы.
Случайное обновление одних и тех же страниц через разные узлы RAC приводит к резкому снижению производительности базы данных – вплоть до того, что производительность кластера может быть ниже, чем производительность единственного экземпляра.
Правильное использование Oracle RAC – физическое деление данных (например, при помощи механизма секционированных таблиц) и обращение к каждому набору секций через выделенный узел. Главным назначением RAC стало не горизонтальное масштабирование, а обеспечение отказоустойчивости.
Если узел перестаёт отвечать на heartbeat, то тот узел, который обнаружил это первым, запускает процедуру голосования на диске. Если и здесь пропавший узел не отметился, то один из узлов берёт на себя обязанности по восстановлению данных:
- «замораживает» все страницы, которые находились в кэше пропавшего узла;
- считывает журналы (redo) пропавшего узла и повторно применяет изменения, записанные в этих журналах, попутно проверяя, нет ли у других узлов более свежих версий изменяемых страниц;
- откатывает незавершённые транзакции.
Чтобы упростить переключение между узлами, в Oracle есть понятие сервиса – виртуального экземпляра. Экземпляр может обслуживать несколько сервисов, а сервис может переезжать между узлами. Экземпляр приложения, обслуживающий определённую часть базы (например, группу клиентов) работает с одним сервисом, а сервис, отвечающий за эту часть базы, при выходе узла из строя переезжает на другой узел.
IBM Pure Data Systems for Transactions
Кластерное решение для СУБД появилось в портфеле Голубого Гиганта в 2009 году. Идеологически оно является наследником кластера Parallel Sysplex, построенным на «обычном» оборудовании. В 2009 году вышел продукт DB2 pureScale, представляющий собой комплект программного обеспечения, а в 2012 года IBM предлагает программно-аппаратный комплект (appliance) под названием Pure Data Systems for Transactions. Не следует путать его с Pure Data Systems for Analytics, которая есть не что иное, как переименованная Netezza.
Архитектура pureScale на первый взгляд похожа на Oracle RAC: точно так же несколько узлов подключены к общей системе хранения данных, и на каждом узле работает свой экземпляр СУБД со своими областями памяти и журналами транзакций. Но, в отличие от Oracle, в DB2 есть выделенный сервис блокировок, представленный набором процессов db2LLM*. В кластерной конфигурации этот сервис выносится на отдельный узел, который в Parallel Sysplex называется coupling facility (CF), а в Pure Data – PowerHA.
PowerHA предоставляет следующие сервисы:
- менеджер блокировок;
- глобальный буферный кэш;
- область межпроцессных коммуникаций.
Для передачи данных от PowerHA к узлам БД и обратно используется удалённый доступ к памяти, поэтому кластерный интерконнект должен поддерживать протокол RDMA. PureScale может использовать как Infiniband, так и RDMA over Ethernet.
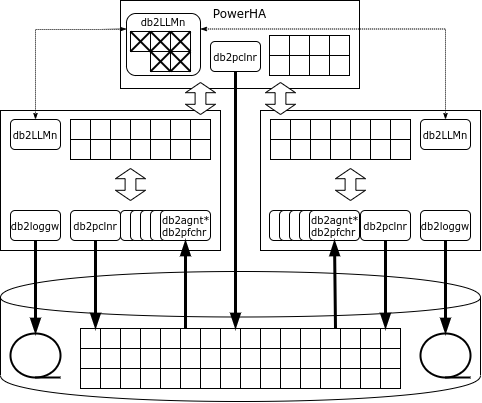
Если узлу нужна страница, и этой страницы нет в кэше, то узел запрашивает страницу в глобальном кэше, и только в том случае, если и там её нет, читает её с диска. В отличие от Oracle, запрос идёт только в PowerHA, а не в соседние узлы.
Если экземпляр собирается менять строку, он блокирует её в эксклюзивном режиме, а страницу, где находится строка, – в разделяемом режиме. Все блокировки регистрируются в глобальном менеджере блокировок. Когда транзакция завершается, узел посылает сообщение менеджеру блокировок, который копирует изменённую страницу в глобальный кэш, снимает блокировки и инвалидирует изменённую страницу в кэшах других узлов.
Если страница, в которой находится изменяемая строка, уже заблокирована, то менеджер блокировок прочитает изменённую страницу из памяти узла, сделавшего изменения, снимет блокировку, инвалидирует изменённую страницу в кэшах других узлов и отдаст блокировку страницы узлу, который её запросил.
«Грязные», то есть изменённые, страницы могут быть записаны на диск как с обычного узла, так и с PowerHA (castout).
При отказе одного из узлов pureScale восстановление ограничено только теми транзакциями, которые в момент сбоя ещё не были завершены: страницы, изменённые этим узлом в завершившихся транзакциях, есть в глобальном кэше на PowerHA. Узел перезапускается в урезанной конфигурации на одном из серверов кластера, откатывает незавершённые транзакции и освобождает блокировки.
PowerHA работает на двух серверах, и основной узел синхронно реплицирует своё состояние. При отказе основного узла PowerHA кластер продолжает работу с резервным узлом.
Разумеется, если обращаться к набору данных через один узел, общая производительность кластера будет выше. PureScale даже может заметить, что некоторая область данных обрабатываются одним узлом, и тогда все блокировки, относящиеся к этой области, будут обрабатываться узлом локально без коммуникаций с PowerHA. Но как только приложение попытается обратиться к этим данным через другой узел, централизованная обработка блокировок будет возобновлена.
Внутренние тесты IBM на нагрузке, состоящей из 90% чтения и 10% записи, что очень похоже на реальную промышленную нагрузку, показывают почти линейное масштабирование до 128 узлов. Условия тестирования, увы, не раскрываются.
HPE NonStop SQL
Своя высокодоступная платформа есть и в портфеле Hewlett-Packard Enterprise. Это платформа NonStop, выпущенная на рынок в 1976 году компанией Tandem Computers. В 1997 году компания была поглощена компанией Compaq, которая, в свою очередь, в 2002 году влилась в Hewlett-Packard.
NonStop используется для построения критичных приложений – например, HLR или процессинга банковских карт. Платформа поставляется в виде программно-аппаратного комплекса (appliance), включающего в себя вычислительные узлы, систему хранения данных и коммуникационное оборудование. Сеть ServerNet (в современных системах – Infiniband) служит как для обмена между узлами, так и для доступа к системе хранения данных.
В ранних версиях системы использовались проприетарные процессоры, которые были синхронизированы друг с другом: все операции исполнялись синхронно несколькими процессорами, и как только один из процессоров ошибался, он отключался, а второй продолжал работу. Позднее система перешла на обычные процессоры (сначала MIPS, затем Itanium и, наконец, x86), а для синхронизации стали использоваться другие механизмы:
- сообщения: у каждого системного процесса есть двойник-«тень», которому активный процесс периодически отправляет сообщения о своём состоянии; при сбое основного процесса теневой процесс начинает работу с момента, определённого последним сообщением;
- голосование: у системы хранения данных есть специальный аппаратный компонент, который принимает несколько одинаковых обращений и выполняет их только в том случае, если обращения совпадают; вместо физической синхронизации процессоры работают асинхронно, а результаты их работы сравниваются только в моменты ввода/вывода.
Начиная с 1987 года на платформе NonStop работает реляционная СУБД – сначала SQL/MP, а позже – SQL/MX.
Вся база данных делится на части, и за каждую часть отвечает свой процесс Data Access Manager (DAM). Он обеспечивает запись данных, кэшировние и механизм блокировок. Обработкой данных занимаются процессы-исполнители (Executor Server Process), работающие на тех же узлах, что и соответствующие менеджеры данных. Планировщик SQL/MX делит задачи между исполнителями и объединяет результаты. При необходимости внести согласованные изменения используется протокол двухфазной фиксации, обеспечиваемый библиотекой TMF (Transaction Management Facility).
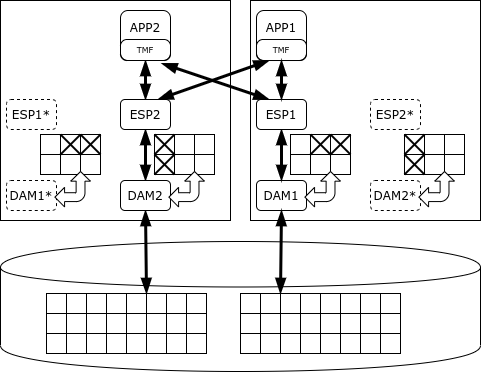
NonStop SQL умеет приоритезировать процессы так, чтобы длинные аналитические запросы не мешали исполнению транзакций. Однако её назначение – именно обработка коротких транзакций, а не аналитика. Разработчик гарантирует доступность кластера NonStop на уровне пять «девяток», то есть простой составляет всего 5 минут в год.
SAP HANA
Первый стабильный релиз СУБД HANA (1.0) состоялся в ноябре 2010 года, а пакет SAP ERP перешёл на HANA с мая 2013 года. Платформа базируется на купленных технологиях: TREX Search Engine (поиска в колоночном хранилище), СУБД P*TIME и MAX DB.
Само слово «HANA» – акроним, High performance ANalytical Appliance. Поставляется эта СУБД в виде кода, который может работать на любых серверах x86, однако промышленные инсталляции допускаются только на оборудовании, прошедшем сертификацию. Имеются решения HP, Lenovo, Cisco, Dell, Fujitsu, Hitachi, NEC. Некоторые конфигурации Lenovo допускают даже эксплуатацию без SAN – роль общей СХД играет кластер GPFS на локальных дисках.
В отличие от перечисленных выше платформ, HANA – СУБД в памяти, т. е. первичный образ данных хранится в оперативной памяти, а на диск записываются только журналы и периодические снимки – для восстановления в случае аварии.
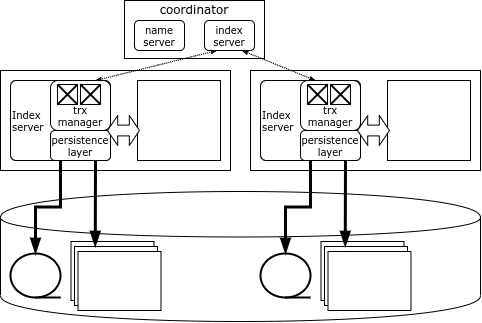
Каждый узел кластера HANA отвечает за свою часть данных, а карта данных хранится в специальном компоненте – Name Server, расположенном на узле-координаторе. Данные между узлами не дублируются. Информация о блокировках также хранится на каждом узле, но в системе есть глобальный детектор взаимных блокировок.
Клиент HANA при соединении с кластером загружает его топологию и в дальнейшем может обращаться напрямую к любому узлу в зависимости от того, какие данные ему нужны. Если транзакция затрагивает данные единственного узла, то она может быть выполнена этим узлом локально, но если изменяются данные нескольких узлов, то узел-инициатор обращается к узлу-координатору, который открывает и координирует распределённую транзакцию, фиксируя её при помощи оптимизированного протокола двухфазной фиксации.
Узел-координатор дублирован, поэтому в случае выхода координатора из строя в работу немедленно вступает резервный узел. А вот если выходит из строя узел с данными, то единственный способ получить доступ к его данным – перезапустить узел. Как правило, в кластерах HANA держат резервный (spare) сервер, чтобы как можно быстрее перезапустить на нём потерянный узел.
Источник: habr.com
