


Несмотря на то, что данных сейчас много почти везде, аналитические БД все еще довольно экзотичны. Их плохо знают и еще хуже умеют эффективно использовать. Многие продолжают "есть кактус" с MySQL или PostgreSQL, которые спроектированы под другие сценарии, мучиться с NoSQL или переплачивать за коммерческие решения. ClickHouse меняет правила игры и значительно снижает порог вхождения в мир аналитических DBMS.
Доклад с BackEnd Conf 2018г и он опубликован с разрешения докладчика.


Кто я такой и почему я рассказываю о ClickHouse? Я директор по разработке в компании LifeStreet, которая использует ClickHouse. Кроме того, я основатель Altinity. Это партнер Яндекса, который продвигает ClickHouse и помогает Яндексу сделать ClickHouse более успешным. Также готов делиться знаниями о ClickHouse.

И еще я не брат Пети Зайцева. Меня часто об этом спрашивают. Нет, мы не братья.

«Всем известно», что ClickHouse:
- Очень быстрый,
- Очень удобный,
- Используется в Яндексе.
Чуть менее известно, в каких компаниях и как он используется.

Я вам расскажу, для чего, где и как используется ClickHouse, кроме Яндекса.
Расскажу, как конкретные задачи решаются при помощи ClickHouse в разных компаниях, какие средства ClickHouse вы можете использовать для своих задач, и как они были использованы в разных компаниях.
Я подобрал три примера, которые показывают ClickHouse с разных сторон. Я думаю, это будет интересно.

Первый вопрос: «Зачем нужен ClickHouse?». Вроде бы вопрос достаточно очевидный, но ответов на него больше, чем один.

- Первый ответ – ради производительности. ClickHouse очень быстрый. Аналитика на ClickHouse тоже очень быстрая. Его часто можно использовать там, где что-то другое работает очень медленно или очень плохо.
- Второй ответ – это стоимость. И в первую очередь стоимость масштабирования. Например, Vertica – совершенно отличная база данных. Она очень хорошо работает, если у вас не очень много терабайт данных. Но когда речь идет о сотнях терабайтах или о петабайтах, то стоимость лицензии и поддержки выходит в достаточно существенную сумму. И это дорого. А ClickHouse бесплатный.
- Третий ответ – это операционная стоимость. Это подход чуть-чуть с другой стороны. RedShift – отличный аналог. На RedShift можно очень быстро сделать решение. Оно будет хорошо работать, но при этом каждый час, каждый день и каждый месяц вы будете достаточно дорого платить Amazon, потому что это существенно дорогой сервис. Google BigQuery тоже. Если им кто-то пользовался, то он знает, что там можно запустить несколько запросов и получить счет на сотни долларов внезапно.
В ClickHouse этих проблем нет.

Где используется ClickHouse сейчас? Кроме Яндекса ClickHouse используется в куче разных бизнесов и компаний.
- В первую очередь это аналитика веб-приложений, т. е. это use case, который пришел из Яндекса.
- Много AdTech компаний используют ClickHouse.
- Многочисленные компании, которым нужно анализировать операционные логи с разных источников.
- Несколько компаний используют ClickHouse для мониторинга логов безопасности. Они их загружают в ClickHouse, делают отчеты, получают нужные им результаты.
- Компании начинают его использовать в финансовом анализе, т. е. постепенно большой бизнес тоже подбирается к ClickHouse.
- CloudFlare. Если кто-то за ClickHouse следит, то наверняка слышал название этой компании. Это один из существенных контрибуторов из community. И у них очень серьезная ClickHouse-инсталляция. Например, они сделали Kafka Engine для ClickHouse.
- Телекоммуникационные компании начали использовать. Несколько компаний ClickHouse используют либо как proof on concept, либо уже в production.
- Одна компания использует ClickHouse для мониторинга производственных процессов. Они тестируют микросхемы, списывают кучу параметров, там порядка 2 000 характеристик. И дальше анализируют – хорошая партия или плохая.
- Блокчейн-аналитика. Есть такая российская компания, как Bloxy.info. Это анализ ethereum-сети. Это они тоже сделали на ClickHouse.

Причем размер не имеет значения. Есть много компаний, которые используют один маленький сервер. И он им позволяет решить их проблемы. И еще больше компаний используют большие кластера из многих серверов или десятков серверов.
И если смотреть за рекордами, то:
- Яндекс: 500+ серверов, 25 миллиардов записей в день они там сохраняют.
- LifeStreet: 60 серверов, примерно 75 миллиардов записей в день. Серверов меньше, записей больше, чем в Яндексе.
- CloudFlare: 36 серверов, 200 миллиардов записей в день они сохраняют. У них еще меньше серверов и еще больше данных они сохраняют.
- Bloomberg: 102 сервера, примерно триллион записей в день. Рекордсмен по записям.
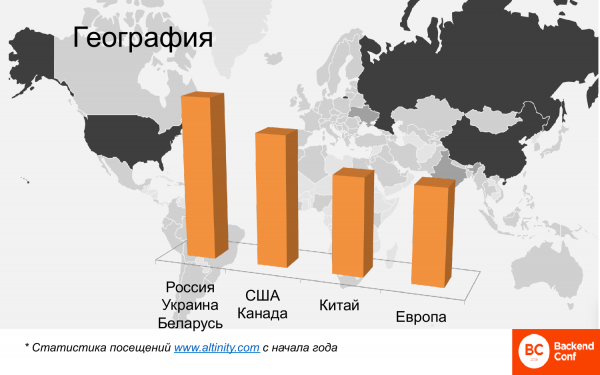
Географически – это тоже много. Вот эта карта показывает heatmap, где ClickHouse используется в мире. Тут ярко выделяется Россия, Китай, Америка. Европейских стран мало. И можно выделить 4 кластера.
Это сравнительный анализ, тут не надо искать абсолютных цифр. Это анализ посетителей, которые читают англоязычные материалы на сайте Altinity, потому что русскоязычных там нет. И Россия, Украина, Беларусь, т. е. русскоязычная часть сообщества, это самые многочисленные пользователи. Потом идет США и Канада. Очень сильно догоняет Китай. Там полгода назад Китая почти не было, сейчас Китай уже обогнал Европу и продолжает расти. Старушка Европа тоже не отстает, причем лидер использования ClickHouse – это, как ни странно, Франция.

Зачем я все это рассказываю? Для того чтобы показать, что ClickHouse становится стандартным решением для анализа больших данных и уже очень много где используется. Если вы его используете, вы в правильном тренде. Если вы еще его не используете, то можно не бояться, что вы останетесь одни и вам никто не поможет, поэтому что уже многие этим занимаются.

Это примеры реального использования ClickHouse в нескольких компаниях.
- Первый пример – это рекламная сеть: миграция с Vertica на ClickHouse. И я знаю несколько компаний, которые с Vertica перешли или находятся в процессе перехода.
- Второй пример – транзакционное хранилище на ClickHouse. Это пример построенный на антипаттернах. Все, что не надо делать в ClickHouse по советам разработчиков, здесь сделано. И при этом сделано настолько эффективно, что это работает. И работает гораздо лучше, чем типичное транзакционное решение.
- Третий пример – это распределенные вычисления на ClickHouse. Был вопрос про то, как можно ClickHouse интегрировать в Hadoop экосистему. Я покажу пример, как компания сделала на ClickHouse что-то типа аналога map reduce контейнера, следя за локализацией данных и т. д, чтобы посчитать очень нетривиальную задачу.

- LifeStreet – Это Ad Tech компания, у которой есть все технологии, сопутствующие рекламной сети.
- Занимается она оптимизацией объявлений, programmatic bidding.
- Много данных: порядка 10 миллиардов событий в день. При этом там события могут на несколько подсобытий делиться.
- Много клиентов этих данных, причем это не только люди, гораздо больше – это различные алгоритмы, которые занимаются programmatic bidding.

Компания прошла долгий и тернистый путь. И я о нем рассказывал на HighLoad. Сначала LifeStreet перешла с MySQL (с небольшой остановкой на Oracle) в Vertica. И можно об этом найти рассказ.
И все было очень хорошо, но достаточно быстро стало понятно, что данные растут и Vertica – это дорого. Поэтому искались различные альтернативы. Некоторые из них здесь перечислены. И на самом деле мы сделали proof of concept или иногда performance testing почти всех баз данных, которые с 13-го по 16-ый год были доступны на рынке и примерно подходили по функциональности. И о части из них я тоже рассказал на HighLoad.

Стояла задача – мигрировать с Vertica в первую очередь, потому что данные росли. И росли они экспоненциально несколько лет. Потом они вышли на полку, но тем не менее. И прогнозируя этот рост, требования бизнеса на объем данных, по которым нужно делать какую-то аналитику, было понятно, что скоро пойдет разговор о петабайтах. А за петабайты платить уже очень дорого, поэтому искали альтернативу, куда уходить.
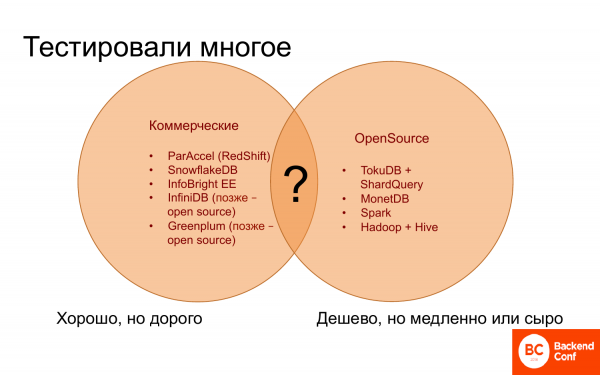
Куда уходить? И долгое время было совершенно не понятно, куда уходить, потому что с одной стороны есть коммерческие базы данных, они вроде бы неплохо работают. Некоторые работают почти так же хорошо, как Vertica, некоторые похуже. Но они все дорогие, ничего дешевле и лучше найти не удавалось.
С другой стороны, есть open source решения, которых не очень много, т. е. для аналитики их можно пересчитать по пальцам. И они бесплатные или дешевые, но работают медленно. И в них часто не хватает нужной и полезной функциональности.
И того, чтобы совмещало то хорошее, что есть в коммерческих базах данных и все то бесплатное, что есть в open source, — ничего не было.

Ничего не было до тех пор, пока неожиданно Яндекс не вытащил, как кролика фокусник из шапки, ClickHouse. И это было решение неожиданное, до сих пор задают вопрос: «Зачем?», но тем не менее.
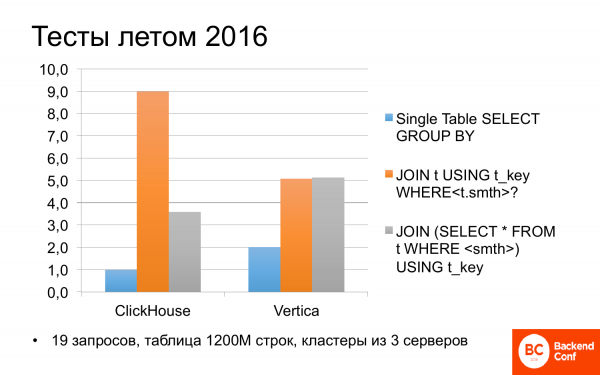
И сразу летом 2016-го года мы стали смотреть, что такое ClickHouse. И оказалось, что он иногда может быть быстрее Vertica. Мы тестировали разные сценарии на разных запросах. И если запрос использовал только одну таблицу, т. е. без всяких джойны (join), то ClickHouse был быстрее Vertica в два раза.
Я не поленился и посмотрел еще тесты Яндекса на днях. Там то же самое: в два раза ClickHouse быстрее Vertica, поэтому они часто об этом говорят.
Но если в запросах есть джойны (join), то все получается не очень однозначно. И ClickHouse может быть медленнее Vertica в два раза. А если чуть-чуть запрос подправить и переписать, то примерно равные. Неплохо. И бесплатно.

И получив результаты тестов, и посмотрев с разных сторон на это, LifeStreet поехал на ClickHouse.

Это 16-ый год, напоминаю. Это было как в анекдоте про мышей, которые плакали и кололись, но продолжали есть кактус. И об этом было подробно рассказано, есть об этом видео и т. д.

Я поэтому не буду подробно об этом рассказывать, расскажу только о результатах и о нескольких интересных вещах, о которых я не рассказывал тогда.
Результаты – это:
- Успешная миграция и более года система уже работает в продакшене.
- Производительность и гибкость выросли. Из 10 миллиардов записей, которые мы могли позволить себе хранить в день и то недолго, теперь LifeStreet хранит 75 миллиардов записей в день и может это делать 3 месяца и больше. Если посчитать в пике, то это до миллиона событий в секунду сохраняется. Больше миллиона SQL-запросов в день прилетают в эту систему, в основном от разных роботов.
- Несмотря на то, что для ClickHouse стали использовать больше серверов, чем для Vertica, экономия и на железе получилась, потому что в Вертике использовались достаточно дорогие SAS-диски. В ClickHouse использовались SATA. А почему? Потому что в Vertica insert синхронный. И синхронизация требует, чтобы диски не очень сильно тормозили, а также, чтобы сеть не очень тормозила, т. е. достаточно дорогая операция. А в ClickHouse insert асинхронный. Более того, можно все локально всегда писать, никаких дополнительных затрат на это нет, поэтому данные в ClickHouse можно вставлять гораздо быстрее, чем в Вертику даже на не самых быстрых дисках. А на чтение примерно одинаково. Чтение на SATA, если они в RAID сидят, то это все достаточно быстро.
- Не ограничены лицензией, т. е. 3 петабайта данных в 60 серверов (20 серверов – это одна реплика) и 6 триллионов записей в фактах и агрегатах. Ничего подобного на Vertica позволить себе не могли.

Сейчас я перехожу к практическим вещам в данном примере.
- Первое – это эффективная схема. От схемы зависит очень многое.
- Второе – это генерация эффективного SQL.
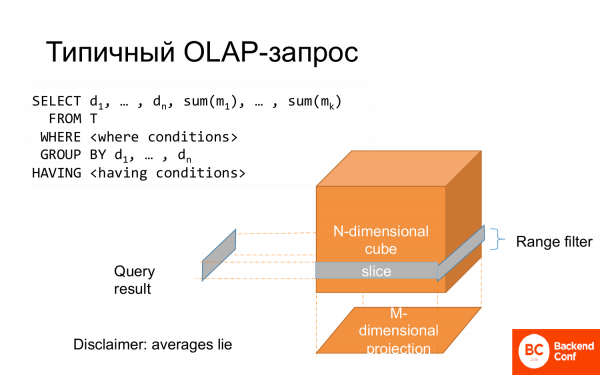
Типичный OLAP-запрос – это select. Часть колонок идет в group by, часть колонок идет в агрегатные функции. Есть where, которую можно представить как срез куба. Весь group by можно представить как проекцию. И поэтому это называется многомерным анализом данных.

И часто это моделируется в виде star-схемы, когда есть центральный факт и характеристики этого факта по сторонам, по лучам.

И с точки зрения физического дизайна, того, как это ложится на таблицу, то обычно делают нормализованное представление. Можете денормализовать, но это дорого по диску и не очень эффективно по запросам. Поэтому обычно делают нормализованное представление, т. е. таблица фактов и много-много таблиц измерений.
Но в ClickHouse это работает плохо. Есть две причины:
- Первая – это потому что в ClickHouse не очень хорошие джойны (join), т. е. джойны (join) есть, но они плохие. Пока плохие.
- Вторая – это то, что таблицы не обновляются. Обычно в этих табличках, которые вокруг star-схемы, нужно что-то менять. Например, название клиента, название компании и прочее. И это не работает.
И выход из этого в ClickHouse есть. даже целых два:
- Первый – это использование словарей. External Dictionaries – это то, что помогает на 99 % решить проблему со star-схемой, с апдейтами и прочим.
- Второй – это использование массивов. Массивы тоже помогают избавиться от джойны (join) и от проблем с нормализацией.

- Не нужен джойны (join).
- Обновляемые. С марта 2018-го года появилась недокументированная возможность (в документации вы об этом не найдете) обновлять словари частично, т. е. те записи, которые поменялись. Практически – это как таблица.
- Всегда в памяти, поэтому джойны (join) со словарем работают быстрее, чем, если бы это была таблица, которая лежит на диске и еще не факт, что она в кэше, скорее всего, что нет.

- Тоже не нужен джойны (join).
- Это компактное представление 1 ко многим.
- И на мой взгляд, массивы сделаны для гиков. Это лямбда-функции и прочее.
Это не для красного словца. Это очень мощная функциональность, которая позволяет делать многие вещи очень просто и элегантно.

Типичные примеры, которые помогают решать массивы. Эти примеры простые и достаточно наглядные:
- Поиск по тегам. Если у вас там есть хештеги и вы хотите найти какие-то записи по хештегу.
- Поиск по key-value парам. Тоже есть какие-то атрибуты со значением.
- Хранение списков ключей, которые вам нужно перевести во что-то другое.
Все эти задачи можно решить без массивов. Теги можно в какую-то строчку положить и регулярным выражением выбирать или в отдельную таблицу, но тогда придется делать джойны (join).

А в ClickHouse ничего не нужно делать, достаточно описать массив string для хештегов или сделать вложенную структуру для систем типа key-value.
Вложенная структура – это, может быть, не самое удачное название. Это два массива, которые имеют общую часть в названии и некоторые связанные характеристики.
И по тегу искать очень просто. Есть функция has, которая проверяет, что в массиве есть элемент. Все, нашли все записи, которые относятся к нашей конференции.
Поиск по subid чуть-чуть посложнее. Надо нам сначала найти индекс ключа, а потом уже взять элемент с этим индексом и проверить, что это значение такое, какое нам нужно. Но тем не менее очень просто и компактно.
Регулярное выражение, которое вы бы захотели написать, если бы вы все это хранили в одной строчке, оно было бы, во-первых, корявым. А, во-вторых, работало гораздо дольше, чем два массива.

Другой пример. У вас есть массив, в котором вы храните ID. И вы можете перевести их в имена. Функция arrayMap. Это типичная лямбда-функция. Вы передаете туда лямбда-выражения. И она каждому ID из словаря вытаскивает значение имени.
Аналогичным образом можно сделать и поиск. Передается функция предикат, которая проверяет чему соответствуют элементы.

Вот эти вещи сильно упрощают схему и решают кучу проблем.
Но следующая проблема, с которой мы столкнулись и о которой я хотел бы упомянуть, это эффективные запросы.
- В ClickHouse нет планировщика запросов. Вообще нет.
- Но тем не менее сложные запросы все равно планировать надо. В каких случаях?
- Если в запросе есть несколько джойны (join), которые вы заворачиваете в подселекты. И порядок, в котором они выполняются, имеет значение.
- И второе – если запрос распределенный. Потому что в распределенном запросе только самый внутренний подселект выполняется распределенно, а все остальное передается на один сервер, к которому вы подключились и выполняется там. Поэтому если у вас распределенные запросы со многими джойны (join), то нужно выбирать порядок.
И даже в более простых случаях тоже иногда следует выполнять работу планировщика и запросы чуть-чуть переписывать.

Вот пример. В левой части запрос, который показывает топ-5 стран. И он выполняется 2,5 секунды, по-моему. А в правой части тот же запрос, но чуть-чуть переписанный. Мы вместо того, чтобы группировать по строке, стали группировать по ключу (int). И это быстрее. А потом мы к результату подключили словарь. Вместо 2,5 секунд запрос выполняется 1,5 секунды. Это хорошо.

Похожий пример с переписыванием фильтров. Здесь запрос по России. Он выполняется 5 секунд. Если мы его перепишем таким образом, что будем сравнивать снова не строку, а числа с каким-то сетом тех ключей, которые относятся к России, то это будет гораздо быстрее.

Таких трюков много. И они позволяют существенно ускорить запросы, которые вам кажется, что уже работают быстро, или, наоборот, работают медленно. Их можно сделать еще быстрее.

- Максимум работы в распределенном режиме.
- Сортировка по минимальным типам, как я это делал по интам.
- Если есть какие-то джойны (join), словари, то их лучше делать в самую последнюю очередь, когда у вас уже данные хотя бы частично сгруппированные, тогда операция джойны (join) или вызов словаря будет меньше раз вызываться и это будет быстрее.
- Замена фильтров.
Есть еще другие техники, а не только те, которые я продемонстрировал. И все они позволяют иногда существенно ускорить выполнение запросов.

Переходим к следующему примеру. Компания Х из США. Что она делает?
Была задача:
- Офлайн-связывание транзакций рекламы.
- Моделирование разных моделей связывания.

В чем состоит сценарий?
Обычный посетитель заходит на сайт, например, 20 раз в месяц с разных объявлений или просто так иногда приходит без всяких объявлений, потому что помнит этот сайт. Смотрит какие-то продукты, кладет их в корзину, вынимает их из корзины. И, в конце концов, что-то покупает.
Резонные вопросы: «Кому надо заплатить за рекламу, если надо?» и «Какая реклама на него повлияла, если повлияла?». Т. е. почему он купил и как сделать так, чтобы люди, похожие на этого человека, тоже покупали?
Для того чтобы эту задачу решить, нужно связывать события, которые происходят на веб-сайте правильным образом, т. е. как-то между ними выстраивать связь. Потом их передавать для анализа в DWH. И на основании этого анализа строить модели, кому и какую рекламу показывать.

Рекламная транзакция – это набор связанных событий пользователя, которые начинаются от показа объявления, дальше что-то происходит, потом, может быть, покупка, а потом могут быть покупки в покупке. Например, если это мобильное приложение или мобильная игра, то обычно установка приложения бесплатно происходит, а если там что-то дальше делается, то на это могут потребоваться денежки. И чем больше человек потратит в приложении, тем он ценнее. Но для этого надо все связать.

Есть много моделей связывания.
Самые популярные – это:
- Last Interaction, где interaction – это либо клик, либо показ.
- First Interaction, т. е. первое, что привело человека на сайт.
- Линейная комбинация – всем поровну.
- Затухание.
- И прочее.
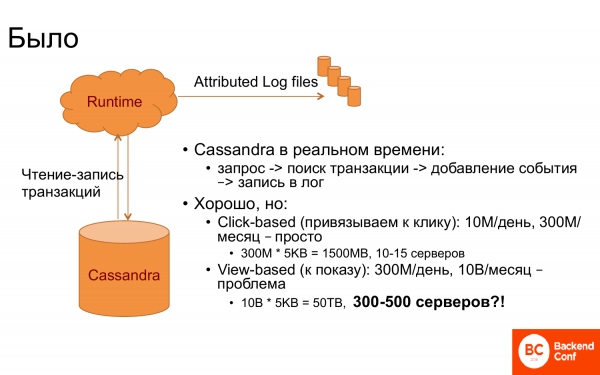
И как это все работало изначально? Был Runtime и Cassandra. Cassandra использовалась как transaction storage, т. е. в ней хранились все связанные транзакции. И когда приходит какое-то событие в Runtime, например, показ какой-то страницы или что-то еще, то делался запрос в Cassandra – есть такой человек или нет. Потом доставались транзакции, которые к нему относятся. И производилось связывание.
И если повезло, что в запросе есть transaction id, то это легко. Но обычно не везет. Поэтому надо было найти последнюю транзакцию или транзакцию с последним кликом и т. д.
И это все очень хорошо работало, пока связывание было к последнему клику. Потому что кликов, скажем, 10 миллионов в день, 300 миллионов в месяц, если на месяц ставить окно. И поскольку в Cassandra это должно быть все в памяти для того, чтобы работало быстро, потому что требуется Runtime ответить быстро, то требовалось примерно 10-15 серверов.
А когда захотели к показу привязывать транзакцию, то сразу получилось не так весело. А почему? Видно, что в 30 раз больше событий надо хранить. И, соответственно, нужно в 30 раз больше серверов. И получается, что это какая-то астрономическая цифра. Держать до 500 серверов для того, чтобы делать связывание, притом, что в Runtime серверов существенно меньше, то это какая-то неправильная цифра. И стали думать, что делать.

И вышли на ClickHouse. А как это делать на ClickHouse? На первый взгляд кажется, что это набор антипаттернов.
- Транзакция растет, мы к ней подцепляем все новые и новые ивенты, т. е. она mutable, а ClickHouse не очень хорошо работает с mutable-объектами.
- Когда к нам приходит посетитель, то нам нужно вытащить его транзакции по ключу, по его visit id. Это тоже point query, в ClickHouse так не делают. Обычно в ClickHouse большие …сканы, а тут нам нужно достать несколько записей. Тоже антипаттерн.
- Кроме того, транзакция была в json, но переписывать не хотели, поэтому хотели хранить json не структурированно, а если надо, то из него что-то вытаскивать. И это тоже антипаттерн.
Т. е. набор антипаттернов.
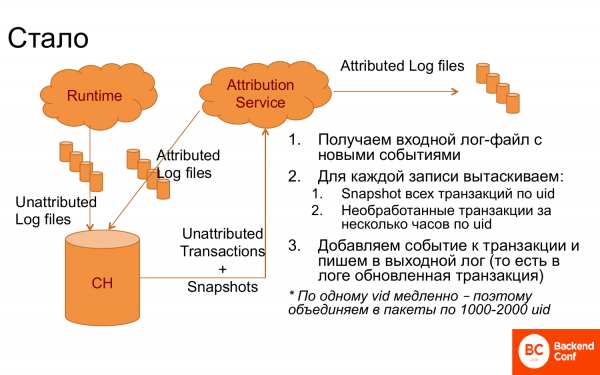
Но тем не менее получилось сделать систему, которая очень хороша работала.
Что было сделано? Появился ClickHouse, в который забрасывались логи, разбитые на записи. Появился attributed сервис, который получал из ClickHouse логи. После этого для каждой записи по visit id получал транзакции, которые могли быть еще не дообработанные и плюс снапшоты, т. е. транзакции уже связанные, а именно результат предыдущей работы. Из них уже делал логику, выбирал правильную транзакцию, подсоединял новые события. Снова записывал в лог. Лог уходил обратно в ClickHouse, т. е. это постоянно цикличная система. И кроме того, уходил в DWH, чтобы там это анализировать.
Именно в таком виде это работало не очень хорошо. И чтобы ClickHouse было проще, когда шел запрос по visit id, то группировали эти запросы в блоки по 1 000-2 000 visit id и вытаскивали для 1 000-2 000 человек все транзакции. И тогда все это заработало.
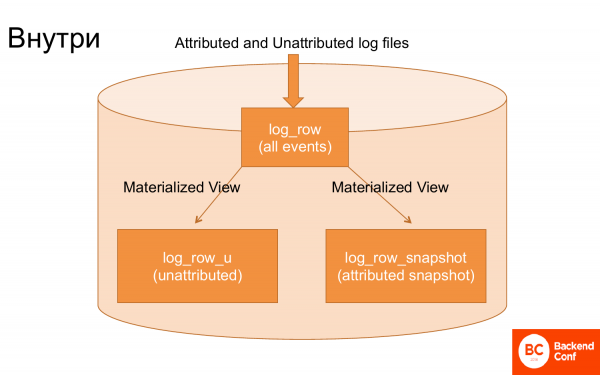
Если посмотреть вовнутрь ClickHouse, то там всего 3 основных таблиц, которые все это обслуживают.
Первая таблица, в которую заливаются логи, причем логи заливаются практически без обработки.
Вторая таблица. Через materialized view из этих логов выкусывались, которые еще не attributed ивенты, т. е. несвязанные. И через materialized view из этих логов вытаскивались транзакции для построения снапшота. Т. е. специальным materialized view строил снапшот, а именно последнее накопленное состояние транзакции.
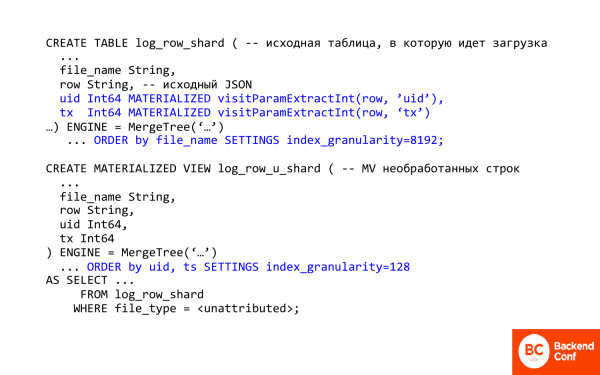
Вот здесь написан текст на SQL. Я бы хотел прокомментировать в нем несколько важных вещей.
Первая важная вещь – это возможность в ClickHouse из json вытаскивать колонки, поля. Т. е. в ClickHouse есть некоторые методы для работы с json. Они очень-очень примитивные.
visitParamExtractInt позволяет из json вытаскивать атрибуты, т. е. первое попадание срабатывает. И таким образом можно вытащить transaction id или visit id. Это раз.
Второе – здесь использовано хитрое materialized поле. Что это значит? Это значит, что вы его в таблицу вставить не можете, т. е. оно не вставляется, оно вычисляется и хранится при вставке. При вставке ClickHouse делает за вас работу. И уже вытаскивается из json то, что вам потом понадобится.
В данном случае materialized view – это для необработанных строк. И как раз используется первая таблица с практически сырыми логами. И что делает? Во-первых, меняет сортировку, т. е. сортировка теперь идет по visit id, потому что нам нужно быстро вытаскивать именно по конкретному человеку его транзакцию.
Вторая важная вещь – это index_granularity. Если вы видели MergeTree, то обычно по дефолту 8 192 стоит index_granularity. Что это такое? Это параметр разреженности индекса. В ClickHouse индекс разреженный, он никогда не индексирует каждую запись. Он это делает через каждые 8 192. И это хорошо, когда требуется много данных подсчитать, но плохо, когда немножко, потому что большой overhead. И если уменьшать index granularity, то мы уменьшаем overhead. Уменьшить до единицы нельзя, потому что может памяти не хватить. Индекс всегда в памяти хранится.

А снапшот использует еще некоторые интересные функции ClickHouse.
Во-первых, это AggregatingMergeTree. И в AggregatingMergeTree хранится argMax, т. е. это состояние транзакции, соответствующее последнему timestamp. Транзакции все время новые генерируются для данного посетителя. И в самое последнее состояние этой транзакции мы добавили ивент и у нас появилось новое состояние. Оно снова попало в ClickHouse. И через argMax в этом материализованном представлении мы всегда можем получить актуальное состояние.

- Связывание «отвязано» от Runtime.
- Хранится и обрабатывается до 3 миллиардов транзакций в месяц. Это на порядок больше, чем было в Cassandra, т. е. в типичной транзакционной системе.
- Кластер 2х5 серверов ClickHouse. 5 серверов и каждый сервер имеет реплику. Это даже меньше, чем было в Cassandra для того, чтобы сделать click based атрибуцию, а здесь у нас impression based. Т. е. вместо того, чтобы увеличивать количество серверов в 30 раз, их удалось уменьшить.

И последний пример – это финансовая компания Y, которая анализировала корреляции изменений котировок акций.
И задача стояла такая:
- Есть примерно 5 000 акций.
- Котировки каждые 100 миллисекунды известны.
- Данные накопились за 10 лет. Видимо, для некоторых компаний побольше, для некоторых поменьше.
- Всего примерно 100 миллиардов строк.
И нужно было посчитать корреляцию изменений.
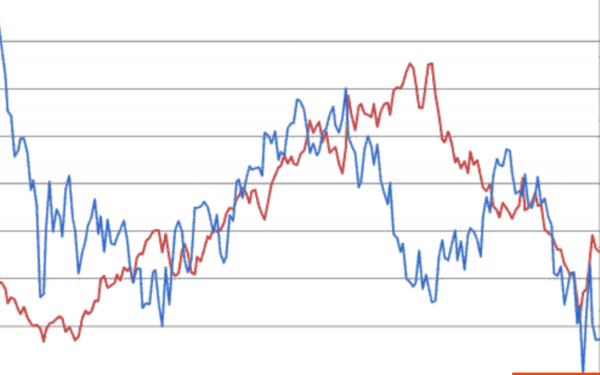
Здесь есть две акции и их котировки. Если одна идет вверх, и вторая идет вверх, то это положительная корреляция, т. е. одна растет, и вторая растет. Если одна идет вверх, как в конце графика, а вторая вниз, то это отрицательная корреляция, т. е. когда одна растет, другая падает.
Анализируя эти взаимные изменения можно делать предсказания на финансовом рынке.

Но задача сложная. Что для этого делается? У нас есть 100 миллиардов записей, в которых есть: время, акция и цена. Нам нужно посчитать сначала 100 миллиардов раз runningDifference от алгоритма цены. RunningDifference – это функция в ClickHouse, которая разницу между двумя строчками последовательно вычисляет.
А после этого надо посчитать корреляцию, причем корреляцию надо посчитать для каждой пары. Для 5 000 акций пар 12,5 миллионов. И это много, т. е. 12,5 раз надо вычислять вот такую функцию корреляции.
И если кто-то забыл, то ͞x и ͞y – это мат. ожидание по выборке. Т. е. нужно не только корни и суммы посчитать, а еще внутри этих сумм еще одни суммы. Кучу-кучу вычислений нужно произвести 12,5 миллионов раз, да еще и сгруппировать по часам надо. А часов у нас тоже немало. И успеть надо за 60 секунд. Это шутка.

Надо было успеть хоть как-то, потому что все это работало очень-очень медленно, прежде, чем пришел ClickHouse.

Они пробовали на Hadoop это посчитать, на Spark, на Greenplum. И все это было очень медленно или дорого. Т. е. можно было как-то посчитать, но потом это было дорого.
А потом пришел ClickHouse и все стало гораздо лучше.
Напоминаю, проблема у нас с локальностью данных, потому корреляции нельзя локализовать. Мы не можем сложить часть данных на один сервер, часть на другой и посчитать, у нас должны быть все данные везде.
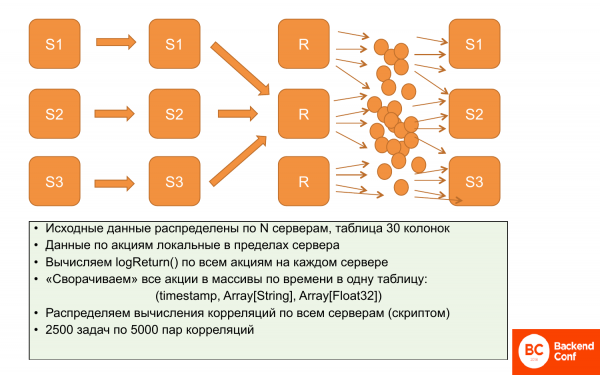
Что они сделали? Изначально данные локализованные. На каждом из серверов хранятся данные по прайсингу определенного набора акций. И они не пересекаются. Поэтому можно параллельно и независимо посчитать logReturn, все это происходит пока параллельно и распределено.
Дальше решили эти данные уменьшить, при этом не потеряв выразительности. Уменьшить с помощью массивов, т. е. для каждого отрезка времени сделать массив акций и массив цен. Таким образом это занимает гораздо меньше места данные. И с ними несколько удобнее работать. Это почти параллельные операции, т. е. мы параллельно частично считаем и потом записываем на сервер.
После этого это можно среплицировать. Буковка «r» означает, что эти данные мы среплицировали. Т. е. у нас на всех трех серверах одинаковые данные – вот эти массивы.
И дальше специальным скриптом из этого набора 12,5 миллионов корреляций, которые надо посчитать, можно сделать пакеты. Т. е. 2 500 задач по 5 000 пар корреляций. И эту задачу вычислять на конкретном ClickHouse-сервере. Все данные у него есть, потому что данные одинаковые и он может их последовательно вычислять.
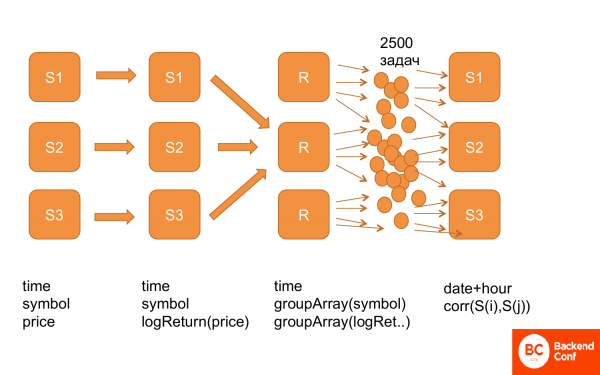
Еще раз, как это выглядит. Сначала у нас все данные есть в такой структуре: время, акции, цена. Потом мы посчитали logReturn, т. е. данные той же структуры, только вместо цены у нас уже logReturn. Потом их переделали, т. е. у нас получились время и groupArray по акциям и по прайсам. Среплицировали. И после этого сгенерировали кучу задач и скормили ClickHouse, чтобы он их считал. И это работает.

На proof of concept задача – это была подзадача, т. е. взяли меньше данных. И всего на трех серверах.
Первые эти два этапа: вычисление Log_return и заворачивание в массивы заняли примерно по часу.
А вычисление корреляции где-то 50 часов. Но 50 часов – это мало, потому что раньше у них это работало неделями. Это был большой успех. И если посчитать, то 70 раз в секунду на этом кластере все считалось.
Но самое главное, что эта система практически без узких мест, т. е. она масштабируется практически линейно. И они это проверили. Успешно ее отмасштабировали.

- Правильная схема – половина успеха. И правильная схема – это использование всех нужных технологий ClickHouse.
- Summing/AggregatingMergeTrees – это технологии, которые позволяют агрегировать или считать снапшот state как частный случай. И это существенно упрощает многие вещи.
- Materialized Views позволяют обойти ограничение в один индекс. Может быть, я это не очень четко проговорил, но когда мы загружали логи, то сырые логи были в таблице с одним индексом, а на attribute логи были в таблице, т. е. те же самые данные, только отфильтрованные, но индекс был совершенно другим. Вроде бы одни и те же данные, но разная сортировка. И Materialized Views позволяет, если вам это нужно, обойти такое ограничение ClickHouse.
- Уменьшайте гранулярность индекса для точечных запросов.
- И распределяйте данные умно, старайтесь максимально локализовать данные внутри сервера. И старайтесь, чтобы запросы использовали тоже локализацию там, где это возможно максимально.
И резюмируя это небольшое выступление, можно сказать, что ClickHouse сейчас твердо занял территорию и коммерческих баз данных, и open source баз данных, т. е. именно для аналитики. Он замечательно вписался в этот ландшафт. И более того, он потихонечку начинает других вытеснять, потому что, когда есть ClickHouse, то вам не нужен InfiniDB. Вертика, может быть, скоро будет не нужна, если они сделают нормальную поддержку SQL. Пользуйтесь!

—Спасибо за доклад! Очень интересно! Были ли какие-то сравнения с Apache Phoenix?
-Нет, я не слышал, чтобы кто-то сравнивал. Мы и Яндекс стараемся отслеживать все сравнения ClickHouse с разными базами данных. Потому что если вдруг что-то оказывается быстрее ClickHouse, то Леша Миловидов не может спать по ночам и начинает быстренько его ускорять. Я не слышал о таком сравнении.
(Алексей Миловидов) Apache Phoenix – это SQL-движок на Hbase. Hbase в основном предназначен для сценария работ типа key-value. Там в каждой строчке может быть произвольное количество столбцов с произвольными именами. Это можно сказать про такие системы как Hbase, Cassandra. И на них именно тяжелые аналитические запросы нормально работать не будут. Или вы можете подумать, что они работают нормально, если у вас не было никакого опыта работы с ClickHouse.
Спасибо
Добрый день! Я уже довольно много интересуюсь этой темой, потому что у меня подсистема аналитическая. Но когда я смотрю на ClickHouse, то у меня возникает ощущение, что ClickHouse очень хорошо подходит для анализа ивентов, mutable. И если мне нужно анализировать много бизнес-данных с кучей больших таблиц, то ClickHouse, насколько я понимаю, мне не очень подходит? Особенно, если они меняются. Правильно ли это или есть примеры, которые могут опровергнуть это?
Это правильно. И это правда про большинство специализированных аналитических баз данных. Они заточены под то, что есть одна или несколько больших таблиц, которые mutable, и под много маленьких, которые медленно изменяются. Т. е. ClickHouse не как Oracle, куда можно положить все и строить какие-то очень сложные запросы. Для того чтобы ClickHouse эффективно использовать, надо схему выстраивать тем образом, который в ClickHouse хорошо работает. Т. е. избегать излишней нормализации, использовать словари, стараться делать меньше длинных связей. И если схему таким образом выстроить, то тогда аналогичные бизнес-задачи на ClickHouse могут быть решены гораздо более эффективно, чем традиционной реляционной базе данных.
Спасибо за доклад! У меня вопрос по последнему финансовому кейсу. У них была аналитика. Надо было сравнить, как идут вверх-вниз. И я так понимаю, что вы систему построили именно под эту аналитику? Если им завтра, допустим, понадобится, какой-то другой отчет по этим данным, нужно заново схему строить и загружать данные? Т. е. делать какую-то предобработку, чтобы получить запрос?
Конечно, это использование ClickHouse для вполне конкретной задачи. Она более традиционно могла бы быть решена в рамках Hadoop. Для Hadoop – это идеальная задача. Но на Hadoop это очень медленно. И моя цель – это продемонстрировать то, что на ClickHouse можно решать задачи, которые обычно решаются совершенно другими средствами, но при этом сделать гораздо эффективнее. Это под конкретную задачу заточено. Понятно, что если есть задача чем-то похожая, то можно ее похожим образом решать.
Понятно. Вы сказали, что 50 часов обрабатывалось. Это начиная с самого начала, когда загрузили данные или получили результаты?
Да-да.
Хорошо, спасибо большое.
Это на 3-х серверном кластере.
Приветствую! Спасибо за доклад! Все очень интересно. Я немножко не про функционал спрошу, а про использование ClickHouse с точки зрения стабильности. Т. е. случались ли у вас какие-то, приходилось ли восстанавливать? Как при этом себя ведет ClickHouse? И случалось ли так, что у вас вылетала и реплика в том числе? Мы, допустим, у ClickHouse сталкивались с проблемой, когда он вылезает все-таки за свой лимит и падает.
Конечно, идеальных систем нет. И у ClickHouse тоже есть свои проблемы. Но вы слышали о том, чтобы Яндекс.Метрика долго не работала? Наверное, нет. Она работает надежно где-то с 2012-2013-го года на ClickHouse. Про мой опыт я тоже могу сказать. У нас никогда не бывало полных отказов. Какие-то частичные вещи могли случаться, но они никогда не были критичными настолько, чтобы серьезно повлиять на бизнес. Никогда такого не было. ClickHouse – достаточно надежен и не падает случайным образом. Можно об этом не беспокоиться. Это не сырая вещь. Это доказано многими компаниями.
Здравствуйте! Вы сказали, что нужно сразу хорошо продумать схему данных. А если это случилось? У меня данные льются-льются. Проходит полгода, и я понимаю, что так жить нельзя, мне надо перезаливать данные и что-то с ними делать.
Это зависит, конечно, от вашей системы. Есть несколько способов сделать это практически без остановки. Например, вы можете создать Materialized View, в котором сделать другую структуру данных, если ее можно однозначно смапировать. Т. е. если она допускает мапирование средствами ClickHouse, т. е. extract каких-то вещей, поменять primary key, поменять партиционирование, то можно сделать Materialized View. Туда ваши старые данные переписать, новые будут писаться автоматически. А потом просто переключиться на использование Materialized View, потом переключить запись и старую таблицу убить. Это вообще без остановки способ.
Спасибо.
Источник: habr.com
