


Казалось бы, разработчики Terraform предлагают достаточно удобные best practices для работы с AWS-инфраструктурой. Только есть нюанс. Со временем количество окружений увеличивается, в каждом появляются особенности. Появляется почти копия стека приложений в соседнем регионе. И Terraform-код нужно аккуратно скопировать и отредактировать согласно новым требованиям или сделать снежинку.
Мой доклад про паттерны в Terraform для борьбы с хаосом и ручной рутиной на крупных и долгих проектах.
Видео:

Мне 40, я 20 лет в IT. 12 лет работаю в компании Ixtens. Мы занимаемся ecommerce-driven-development. И 5 лет практикую DevOps-практики.

Мой рассказ будет про опыт в проекте в компании, название которой я не буду говорить, прикрываясь соглашением о неразглашении.
Цифры на слайде указаны для того, чтобы понимать масштаб проекта. И все, что я буду дальше говорить, связано с Amazon.

Я присоединился к этому проекту 4 года назад. И в самом разгаре проходил рефакторинг инфраструктуры, потому что проект вырос. И те паттерны, которые использовались, они уже не подходили. И учитывая весь планируемый рост проекта, нужно было что-то придумать новое.
Спасибо Матвею, который вчера рассказал, что у них происходило в Додо Пицца. Это то, что происходило у нас 4 года назад.
Пришли разработчики и стали делать инфраструктурный код.
Самые очевидные моменты, почему это требовалось, нужно было time to market. Нужно было сделать так, чтобы DevOps-команда не была узким местом при выкатке. И кроме всего прочего на самом первом уровне использовались Terraform и Puppet.
Terraform – это open source проект компании HashiCorp. И для тех, кто вообще не в курсе, что это, следующие несколько слайдов.

Инфраструктура как код – это значит, что мы можем описать нашу инфраструктуру и попросить каких-то роботов сделать так, чтобы мы получили те ресурсы, которые мы описали.
Например, нам нужна виртуальная машина. Мы опишем, добавим несколько обязательных параметров.

После этого в консоли настроим доступ к Amazon. И попросим Terraform plan. Terraform plan скажет: «Ок, для вашего ресурса мы можем сделать вот такие штуки». И, как минимум, один ресурс будет добавлен. И никаких изменений не предвидится.
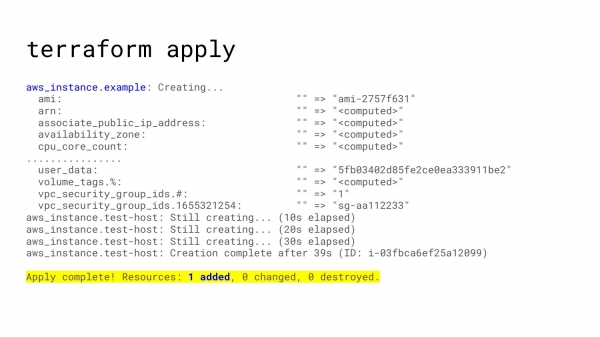
После того, как вас все устроило, вы можете попросить Terraform apply и Terraform создаст вам instance, и вы получите виртуальную машину в вашем облаке.

Далее наш проект развивается. Мы добавляем туда какие-то изменения. Мы просим больше instances, мы добавляем 53 запись.
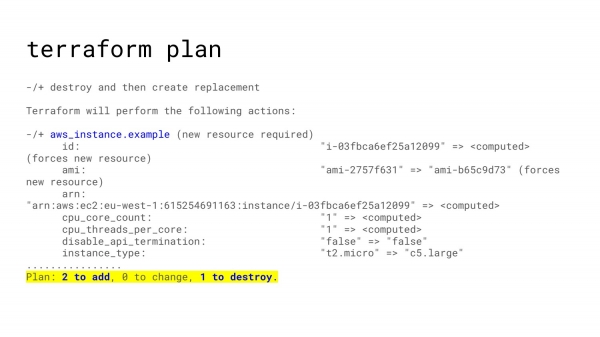
И повторяем. Просим plan. Видим, какие изменения планируются. Применяем. И таким образом наша инфраструктура растет.
Terraform использует такую штуку как state-файлы. Т. е. все изменения, которые уходят на Amazon, он сохраняет в файлике, где для каждого ресурса, который вы описали, есть соответствующие ресурсы, которые были созданы в Amazon. Таким образом при изменении описания какого-то ресурса, Terraform точно знает, что именно нужно поменять в Amazon.

Эти state-файлы первоначально были просто файлами. И мы их хранили в Git, что было крайне неудобно. Постоянно кто-то забывал прокоммитить изменения, и возникало много конфликтов.
Сейчас есть возможность использовать бэкенд, т. е. Terraform указывается в какой bucket, по какому ключу нужно сохранить state-файл. И Terraform сам позаботится о том, чтобы достать этот state-файл, сделать всю магию и положить обратно финальный результат.

Наша инфраструктура растет. Вот наш код. И мы теперь не хотим просто создавать виртуальную машину, мы хотим иметь тестовое окружение.

Terraform позволяет сделать такую штуку как модуль, т. е. тоже самое описать в какой-то папке.

И, например, в тестинге вызвать этот модуль и получить тоже самое как будто мы выполняли Terraform apply в самом модуле. Для тестинга будет вот такой код.

Для production мы можем послать туда какие-то изменения, потому что в тестинге нам не нужны большие instances, в production большие instances как раз пригодятся.

И дальше я вернусь обратно в проект. Была сложная задача, инфраструктура планировалась очень большой. И нужно было как-то разместить весь код, чтобы это было удобно для всех: и для тех, кто производит maintenance над этим кодом, и для тех, кто вносит изменения. А планировалось, что любой разработчик может пойти и поправить инфраструктуру так, как нужно для его части платформы.
Это дерево каталогов, которое рекомендуется самим HashiCorp, если у вас большой проект и есть смысл разделить всю инфраструктуру на какие-то маленькие кусочку, и каждые кусочки описывать в отдельной папочке.
Имея обширную библиотеку ресурсов можно в тестинге и в production вызывать примерно одно и то же.

В нашем случае это не совсем подходило, потому что тестовый стек для разработчиков или для тестирования нужно было получать как-то попроще. А ходить по папочкам и применять в нужной последовательности, и беспокоиться о том, что база поднимется, а потом поднимется instance, который использует эту базу, не хотелось. Поэтому весь тестинг запускался из одной папки. Там вызывались те же самые модули, но проходило все за один прогон.
Terraform беспокоится обо всех зависимостях. И всегда создает ресурсы в той последовательности, чтобы можно было получить IP-адрес, например, от свежесозданного instance, и получить этот IP-адрес в route53 запись.
Кроме этого, платформа очень большая. И запуск тестового стека, даже если на час, даже если на 8 часов – это достаточно дорогое дело.
И мы автоматизировали это дело. И Jenkins job позволял запускать стек. В нем нужно было запускать pull request с изменениями, которые хочет разработчик протестировать, указать все нужные опции, компоненты, а также размеры. Если он хочет performance тестирование, то он может побольше instances взять. Если ему нужно просто проверить, что какая-то формочка открывается, то мог стартануть на минималках. А также указать нужен кластер или не нужен и т. д.
И потом Jenkins толкал shell-скрипт, который немножко модифицировал код в папке Terraform. Убирал ненужные файлы, добавлял нужные файлы. И потом одним прогоном Terraform apply стек поднимался.
А дальше уже шли другие шаги, в которые я не хочу углубляться.

Из-за того, что для тестинга нам требовалось немножко больше опций, чем в production, нам приходилось делать копии модулей, чтобы в этих копиях можно было добавить те фичи, которые нужны только в тестинге.
И так получилось, что в тестинге вроде как хочется протестировать те изменения, которые в итоге пойдут на production. Но на самом деле тестировалось одно, а в production применялось немножко другое. И был небольшой разрыв шаблона, что в production все изменения применялись operation командой. И иногда получалось так, что те изменения, которые должны были из тестинга перейти в production, они оставались в другой версии.
Кроме этого была такая проблема, что добавлялся новый сервис, который немножко отличался от какого-то уже существующего. И вместо того, чтобы модифицировать существующий модуль, приходилось делать его копию и добавлять необходимые изменения.
По сути, Terraform – это не настоящий язык. Это декларация. Если нам нужно что-то задекларировать, то мы это декларируем. И все это работает.
В какой-то момент, когда обсуждался один из моих pull request, один из коллег сказал, что не нужно плодить снежинки. Я заинтересовался, что он имеет в виду. Есть такой научный факт, что в мире не существует двух одинаковых снежинок, все они чуть-чуть, да отличаются. И как только я это услышал, я сразу ощутил всю тяжесть Terraform-кода. Потому что когда требовалось перейти с версии на версию, то Terraform требовал breaking chain изменения, т. е. код больше не был совместим со следующей версией. И приходилось делать pull request, который покрывал почти половину файлов в инфраструктуре, чтобы привести инфраструктуру к следующей версии Terraform.
И после того, как появилась такая снежинка, весь Terraform-код, который у нас имелся, превращался в большую-большую кучу снега.
Для внешнего разработчика, который вне operation, для него это не имеет большого значения, потому что он сделал pull request, его ресурс запустился. И все, дальше не его забота. А команде DevOps, которые следят за тем, чтобы все было Ок, требуется делается делать все эти изменения. И стоимость этих изменений очень-очень сильно возрастала с каждой дополнительной снежинкой.

Есть такая история про то, как студент на семинаре рисует мелом на доске два идеальных круга. И преподаватель удивляется, как ему удалось так ровно без циркуля нарисовать. Студент отвечает: «Очень просто, я два года в армии крутил мясорубку».
И из тех четырех лет, в которых я участвую в этом проекте, где-то около двух лет я занимаюсь Terraform. И, конечно, у меня есть некие фишки, некие советы, как можно упростить Terraform-код, работать с ним, как с языком программирования и уменьшить нагрузку на разработчиков, которые должны поддерживать этот код в актуальном состоянии.

Первое, с чего я хотел бы начать, это Symlinks. Terraform имеет много повторяющегося кода. Например, вызов провайдера практически в каждой точке, где мы создает кусочек инфраструктуры, один и тот же. И логично вынести его в отдельную папочку. И везде, где требуется провайдер делать Symlinks на этот файлик.

Например, у вас в production используется assume role, который позволяет вам получить права доступа на какой-то внешний Amazon-аккаунт. И поменяв один файлик, все оставшиеся, которые в дереве ресурсов, будут иметь требуемые права, чтобы Terraform знал к какому Amazon-сегменту обращаться.

Где Symlinks не работают? Как и говорил, в Terraform есть state-файлы. И они очень-очень классные. Но дело в том, что Terraform инициализирует бэкенд в самом первом. И он не может использовать в этих параметрах какие-либо переменные, их всегда нужно писать текстом.
И как результат, когда кто-то делает новый ресурс, он копирует часть кода из других папочек. И он может ошибиться с ключом или с bucket. Например, он из sandbox делает sandbox-штуку, а потом делает в production. И так может оказаться, что bucket в production будет использоваться из sandbox. Конечно, это быстро найдут. Можно будет это как-то исправить, но тем не менее это потеря времени и в какой-то степени ресурсов.

Что мы можем сделать далее? Перед тем, как работать с Terraform надо его проинициализировать. В момент инициализации Terraform выкачивает все плагины. Они в какой-то момент из монолита разбились на более микросервисную архитектуру. И всегда нужно делать Terraform init, чтобы он подтянул все модули, все плагины.
И можно использовать shell-скрипт, который, во-первых, сможет достать все переменные. Shell-скрипт ничем не ограничен. А, во-вторых, пути. Если мы всегда используем тот путь, который в репозитории как ключ к state-файлу, то, соответственно, ошибка здесь будет исключена.

Откуда достать данные? JSON-файл. Terraform позволяет записывать инфраструктуру не только в hcl (HashiCorp Configuration Language), но и в JSON.
JSON легко читается из shell-скрипта. Соответственно, можно в какое-то место положить конфигурационный файл с bucket. И использовать этот bucket и в Terraform-коде, и в shell-скрипте для инициализации.

Почему важно иметь bucket для Terraform? Потому что есть такая штука как remote state-файлы. Т. е. когда я поднимаю какой-то ресурс, мне для того, чтобы сказать Amazon: «Подними, пожалуйста, instance», нужно указать очень много обязательных параметров.
И эти идентификаторы хранятся в какой-то другой папочке. И я могу взять и сказать: «Terraform, сбегай, пожалуйста, в state-файл того самого ресурса и достань мне эти идентификаторы». И таким образом появляется некая унификакция между различными регионами или environments.
Не всегда можно использовать удаленный state-файл. Например, вы руками создали VPC. И тот Terraform-код, который создает VPC, создает настолько непохожий VPC, что очень долго и нужно вам придется подстраивать одно под другое, поэтому можно использовать следующую фишку.
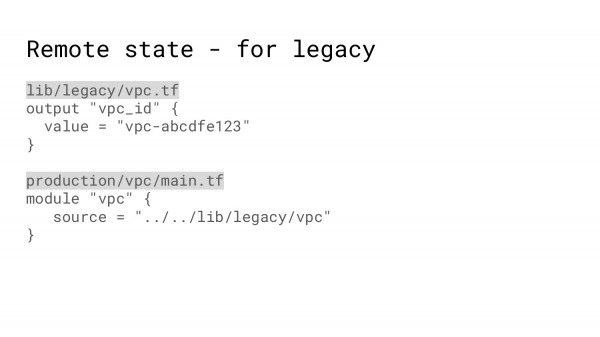
Т. е. сделать модуль, который как бы делает VPC и как бы выдает вам идентификаторы, а на самом деле просто есть файлик с захардкоженными значениями, который можно использовать для создания того же instance.

Не всегда требуется сохранять state-файл в облаке. Например, когда тестируются модули, можно использовать инициализацию бэкенда, когда файл будет сохраняться просто на диске на момент тестирования.
Сейчас немножко про тестирование. Что в Terraform можно тестировать? Наверное, многое можно, но я буду говорить про вот эти 4 штучки.
У HashiCorp есть понимание, как нужно форматировать Terraform-код. И Terraform fmt позволяет вам отформатировать код, который вы редактируете в соответствие с этой верой. Соответственно, тесты должны обязательно проверить, а соответствует ли форматирование тому, что завещал HashiCorp, чтобы не приходилось менять расположение скобочек и т. д.

Следующий – это Terraform validate. Он делает немножко большее, чем проверку синтаксиса – аля, все ли скобки парные. Что здесь важно? У нас инфраструктура очень развесистая. В ней очень много различных папочек. И в каждой нужно запустить Terraform validate.
Соответственно, чтобы ускорить тестирование, мы запускаем несколько процессов параллельно, используя параллель.
Параллель – это очень классная штука, пользуйтесь.
Но каждый раз, когда происходит инициализация Terraform, он идет на HashiCorp и спрашивает: «Какие последние версии плагинов? А тот плагин, который у меня кэше – он тот или не тот?». И это на каждом шаге давало свое замедление.

Если Terraform подсказать, где лежат плагины, то Terraform скажет: «Ок, наверное, это самое свежее, что есть. Я не буду никуда ходить, я сразу начну валидировать ваш Terraform-код».

Для того чтобы наполнить папочку нужными плагинами, у нас есть очень простой Terraform-код, который нужно просто проинициализировать. Здесь, конечно, нужно указать всех провайдеров, которые как-либо участвуют в вашем коде, иначе Terraform скажет: «Я не знаю какого-то провайдера, потому что его нет в кэше».

Следующее – это Terraform plan. Как и говорил, разработка – циклична. Мы делаем код с изменениями. И потом нужно узнать, какие изменения планируются на инфраструктуру.
И когда инфраструктура очень-очень большая, можно поменять один модуль, починить какое-то тестовое окружение или какой-нибудь конкретный регион и сломать какой-нибудь соседний. Поэтому Terraform plan должен делаться на всю инфраструктуру и показывать, какие изменения планируются.
Делать это можно по умному. Мы, например, написали скрипт на Python, который разрезолвивает зависимости. И в зависимости оттого, что было изменено: Terraform-модуль или просто какой-то конкретный компонент, он делает планы на все зависимые папочки.
Terraform plan должны делать по запросу. По крайней мере, это то, что делаем мы.
Тесты, конечно, хорошо делать на каждое изменение, на каждый коммит, но планы – это достаточно дорогая штука. И мы в pull request говорим: «Пожалуйста, дай мне планы». Запускается робот. И присылает в комменты или в attach все планы, которые предполагаются от ваших изменений.
План – вещь достаточно дорогая. Она занимает время, потому что Terraform идет в Amazon и спрашивает: «А этот instance еще существует? А у этого autoscale точно такие параметры?». И для того чтобы это ускорить, можно использовать такой параметр, как refresh=false. Это значит, что Terraform выкачает из S3 state. И будет верить, что state будет точно соответствовать тому, что находится в Amazon.
Такой Terraform plan проходит гораздо быстрее, но state должен соответствовать вашей инфраструктуре, т. е. где-то, когда-то должен запуститься Terraform refresh. Terraform refresh делает именно то, чтобы state соответствовал тому, что находится в реальной инфраструктуре.
И нужно сказать о безопасности. С этого и надо было начинать. Там, где вы запускаете Terraform, и Terraform работает с вашей инфраструктурой, есть уязвимость. Т. е. вы, по сути, выполняете код. И если pull request содержит какой-то вредоносный код, то он может исполниться на инфраструктуре, которая имеет слишком много доступа. Поэтому будьте внимательны, где вы запускаете Terraform plan.

Следующее, о чем я хотел бы рассказать, это тестирование user-data.
Что такое user-data? В Amazon, когда мы создаем instance, мы можем с instance отправить некое письмо – мета-данные. Когда instance запускается, обычно cloud init всегда присутствует на этих instances. Cloud init считывает это письмо и говорит: «Ок, сегодня я – load balancer». И в соответствие с этими заветами производит какие-то действия.

Но, к сожалению, когда мы делаем Terraform plan и Terraform apply, user-data выглядит, как вот такая кашица из цифр. Т. е. он просто присылает вам хэш. И все, что вы можете посмотреть в плане, это будут ли какие-то изменения или хэш останется тем же самым.
И если на это не обращать внимание, то на Amazon, на реальную инфраструктуру может уйти какой-то побитый текстовый файлик.

Как вариант, можно при выполнении указать не всю инфраструктуру, а только template. И в коде сказать: «Пожалуйста, выведи мне на экран этот template». И в итоге можно получить распечатку, как будет выглядеть ваши данные на Amazon.

Другой вариант – это использовать модуль для генерации user-data. Вы примените этот модуль. Получаете файл на диске. Сравниваете его с референсным. И таким образом, если какой-то джун решит поправить немножко user-data, то ваши тесты скажут: «Ок, вот здесь и здесь какие-то изменения – это нормально».

Следующее, о чем я хотел бы рассказать, это Automate Terraform apply.
Конечно, достаточно страшно делать Terraform apply в автоматическом режиме, потому что, кто знает, какие там пришли изменения и насколько они могут быть губительны для живой инфраструктуры.
Для тестового окружения – это все нормально. Т. е. job, который создает тестовое окружение, это то, что нужно всем разработчикам. И такое выражение, как «у меня все работало» — это не смешной мем, а доказательство того, что человек заморочился, поднял стек, запустил на этот стек какие-то тесты. И убедился, что там все нормально и сказал: «Ок, тот код, который я выпускаю, был протестирован».
В production, sandbox и других окружениях, которые более важны для бизнеса, можно применять частично некоторые ресурсы достаточно безопасно, потому что это не приводит к тому, что кто-то умирает. Это: autoscale-группы, security-группы, roles, route53 и там список может быть достаточно большой. Но следите за тем, что происходит, читайте отчеты об автоматических применениях.
Там, где применять опасно или боязно, например, если это какие-то ресурсы с persistent, с базы данных, то получайте отчеты о том, что в каком-то кусочке инфраструктуры есть не примененные изменения. И инженер уже под надзором запускает jobs, чтобы применить или делает это со своей консоли.
В Amazon есть такая штука как Terminate protection. И она может защитить в некоторых случаях от нетребуемых для вас изменений. Т. е. Terraform пошел на Amazon и говорит: «Мне нужно убить этот instance, чтобы сделать другой». А Amazon говорит: «Sorry, не сегодня. У нас стоит Terminate protection».

И вишенка на торте – это оптимизация кода. Когда мы работаем с Terraform-кодом, мы должны передать в модуль очень большое количество параметров. Это те параметры, которые необходимы для того, чтобы создать какой-то ресурс. И код превращается в большие списки параметров, которые нужно передать из модуля в модуль, из модуля в модуль, особенно, если модули вложенные.
И это очень сложно читаемо. На это очень сложно делать review. И очень часто получается так, что какие-то параметры проходят review и они не совсем те, которые нужны. А это стоит времени и денег, чтобы потом исправить.
Поэтому я вам предлагаю использовать такую штуку как сложный параметр, который включает в себя некое дерево значений. Т. е. нужна какая-то папка, где у вас указаны все значения, которые вы хотели бы иметь на каком-то environment.

И вызывая этот модуль, можно получить дерево, которое генерируется в одном общем модуле, т. е. в общем модуле, который одинаково работает для всей инфраструктуры.
В этом модуле можно сделать некие вычисления, используя такую свежую фичу в Terraform, как locals. И потом одним output’ом выдать какой-то сложный параметр, который может включать в себе хэши массивы и т. д.

На этом все самые лучшие находки, которые у меня есть закончились. И хотел бы рассказать байку про Колумба. Когда он искал деньги на свою экспедицию, чтобы открыть Индию (как тогда он думал), ему никто не верил и считали, что это невозможно. Тогда он сказал: «Сделайте так, чтобы яйцо не упало». Все банкиры, очень богатые и, наверное, умные люди, пытались каким-то образом поставить яйцо, и оно все время падало. Тогда Колумб взял яйцо, немножко на него надавил. Скорлупа смялось, и яйцо осталось неподвижным. Они сказали: «О, это слишком просто!». И Колумб ответил: «Да, это слишком просто. И когда я открою Индию, все будут использовать этот торговый путь».
И то, что сейчас я вам рассказал, это, наверное, достаточно простые и тривиальные вещи. И когда ты о них узнаешь и начинаешь использовать, это в порядке вещей. Так что пользуйтесь. И если для вас это вполне себе нормальные вещи, то, по крайней мере, вы знаете, как поставить яйцо, чтобы оно не упало.

Подведем итоги:
- Постарайтесь избегать снежинок. И чем меньше снежинок, тем меньше ресурсов вам потребуется, чтобы делать какие-то изменения на всей вашей большой инфраструктуре.
- Постоянные изменения. Т. е. когда в коде произошли какие-то изменения, нужно как можно быстрее привести вашу инфраструктуру в соответствие с этими изменениями. Не должно быть ситуации, когда кто-то через два-три месяца приходит, чтобы посмотреть Elasticsearch, делает Terraform plan, а там куча изменений, которых он не ожидал. И тратится очень много времени для того, чтобы привести обратно все в порядок.
- Тесты и автоматизация. Чем больше у вас код покрыт тестами и фишками, то тем больше у вас уверенность в том, что вы все делаете правильно. А автоматическая доставка увеличит вашу уверенность многократно.
- Код для тестового и production-окружения должен быть практически одинаковым. Практически, потому что все-таки production немножко другой и там все равно будут какие-то нюансы, которые будут выходить за рамки тестового окружения. Но тем не менее плюс-минус можно это обеспечить.
- И если у вас очень много Terraform-кода и на поддержку этого кода в актуальном состоянии требуется очень много времени, то никогда не поздно сделать refactoring и привести его в хорошую форму.

- Immutable infrastructure. Доставка AMI по расписанию.
- Структура для route53, когда у вас записей очень много и вам хочется, чтобы они были в согласованном порядке.
- Борьба с API rate limits. Это когда Amazon говорит: «Все-все, больше я не могу принимать запросов, пожалуйста, подождите». И половина конторы ждет, пока она сможет запустить свою инфраструктуру.
- Spot instances. Amazon – недешевое мероприятия и spots позволяют достаточно много экономить. И там можно рассказать целый доклад об этом.
- Безопасность и IAM roles.
- Поиск потерянных ресурсов, когда у вас в Amazone есть instances непонятного происхождения, они кушают деньги. Даже если instances стоит 100-150 долларов в месяц – за год это 1 000 с лишним. Поиск таких ресурсов – это прибыльное дело.
- И зарезервированные instances.

На этом у меня все. Terraform – это очень круто, пользуетесь. Спасибо!
Вопросы
Спасибо за доклад! У вас state-файл лежит в S3, а как вы решаете проблему, что несколько человек могут взять этот state-файл и попытаться развернуться?
Во-первых, мы не торопимся. Во-вторых, есть flags, в котором мы сообщаем о том, что мы работаем над каким-то участком кода. Т. е. несмотря на то, что инфраструктура очень большая, это не значит, что постоянно кто-то что-то применяет. И когда была активная фаза – это было проблемой, у нас state-файлы в Git хранились. Это было важно, иначе кто-то сделает state-файл, и нам приходилось вручную их собирать в кучу, чтобы все дальше продолжалось. Сейчас такой проблемы нет. А вообще, Terraform решил эту задачу. И если постоянно что-то меняется, то можно использовать locks, которые предотвращают то, что вы сказали.
Вы используете открытую версию или enterprise?
Никакого enterprise, т. е. все, что можно пойти и скачать бесплатно.
Меня зовут Станислав. Я хотел сделать маленькое дополнение. Вы рассказали про фичу Amazon, которая позволяет сделать instance неубиваемым. Это есть и в самом Terraform, в блоке Life Second можно прописать запрет на изменение, либо запрет на уничтожение.
Во времени был ограничен. Хорошее замечание.
Еще хотел спросить две вещи. Во-первых, вы рассказали про тестирование. Пользовались ли вы какими-то инструментами для тестирования? Я слышал про плагин Test Kitchen. Возможно, есть что-то еще. И хотел бы еще спросить про Local Values. Чем они в принципе отличаются от Input Variables? И почему я не могу параметризировать что-то только через Local Values? Я пытался разобраться с этой темой, но как-то не разобрался сам.
Мы можем поподробней поговорить за этим залом. Инструменты для тестирования – это у нас полный самопал. Там ничего такого нет, чтобы протестировать. А вообще, есть варианты, когда автоматические тесты поднимают инфраструктуру где-то, проверяют, что она Ок, а потом все уничтожают с отчетом, что ваша инфраструктура все еще в хорошей форме. У нас этого нет, потому что тестовые стеки запускаются каждый день. И этого достаточно. И если что-то начало ломаться, то оно начнет ломаться без того, что мы еще где-то это проверим.
По поводу Local Values давайте продолжим разговор за залом.
Привет! Спасибо за доклад! Очень познавательно. Ты говорил, что у вас очень много однотипного кода для описания инфраструктуры. Не рассматривали ли вы вариант генерации этого кода?
Отличный вопрос, спасибо! Дело в том, что, когда мы используем инфраструктуру как код, мы предполагаем, что мы смотрим на код и понимаем, какая инфраструктура за этим кодом лежит. Если код генерируется, то нам нужно представить, какой код сгенерируется, чтобы понять, какая инфраструктура там будет. Либо мы генерируем код, коммитим его и, по сути, получается то же самое. Поэтому мы пошли по тому пути, как мы написали, мы это получили. Плюс генераторы появлялись несколько позже, когда мы начали делать. И уже поздно было менять.
Про jsonnet слышал что-нибудь?
Нет.
Посмотри, это очень классная штука. Я вижу конкретный кейс, где можно применить его и генерировать структуру данных.
Генераторы – это хорошо, когда у вас, как в анекдоте про машину для бритья. Т. е. первый раз лицо разное, но потом у всех лицо одинаковое. Генераторы очень классно заходят. Но у нас, к сожалению, лица немного разные. Это проблема.
Просто посмотри. Спасибо!
Меня зовут Максим, я из Сбербанка. Вы немного рассказали, что пытались привести Terraform к аналогу языка программирования. Не проще пользоваться Ansible?
Это очень разные вещи. Можно и Ansible создавать ресурсы, и Puppet можно создавать ресурсы в Amazon. Но Terraform прямо заточен.
У вас только Amazon?
Дело не в том, что у нас только Amazon. У нас почти только Amazon. Но ключевая фича в том, что Terraform помнит. В Ansible, если сказать: «Подними мне 5 instances», то он поднимет, а потом ты говоришь: «А теперь мне нужно 3». И Terraform скажет: «Ок, 2 убью», а Ansible скажет: «Ок, вот тебе 3». Итого 8.
Здравствуйте! Спасибо за ваш доклад! Очень интересно было послушать про Terraform. Сразу хочу дать маленький комментарий по поводу того, что Terraform все-таки не имеет стабильного релиза, поэтому с большой осторожностью относитесь к Terraform .
Хороша ложка к обеду. Т. е. если вам нужно решение, то вы иногда откладываете то, что нестабильно и т. д., но оно работает и нам помогло.
Вопрос такой. Вы используете Remote backend, вы используете S 3. Почему официальный бэкенд не используете?
Официальный?
Terraform Cloud .
Когда он появился?
Месяца 4 назад.
Если бы он появился 4 года назад, то, наверное, я бы ответил на ваш вопрос.
Там есть уже встроенная функция и locks, и можно хранить state -файл. Попробуйте. Но я тоже не тестировал.
Мы едем в большом поезде, который движется с большой скоростью. И нельзя просто взять и выкинуть несколько вагонов.
Вы говорили про снежинки, а почему вы не использовали branch? Почему не получилось так сделать?
У нас такой подход, что вся инфраструктура в одном репозитории. Terraform, Puppet, все скрипты, которые хоть как-то к этому относятся, они все в одном репозитории. Таким образом, можем гарантировать, что инкрементальные изменения протестированы один за другим. Если бы это было куча branches, то такой проект практически невозможно обслуживать. Проходят полгода, и они настолько расходятся, что это просто наказание какое-то. Это то, от чего захотелось убежать до рефакторинга.
Т. е. это не работает?
Это вообще не работает.
В branch я вырезал слайд папки. Т. е. если сделать на каждый тестовый стек, например, у команды А– у нее своя папочка, у команды Б своя папочка, то это тоже не работает. Мы сделали унифицированный код тестового окружения, который был достаточно гибкий, чтобы подходить всем. Т. е. мы один код обслуживали.
Привет! Меня зовут Юра! Спасибо за доклад! Вопрос о модулях. Вы говорите, что вы используете модули. Как решаете вопрос, если в одном модуле внесли изменения, которые не совместимы с изменением другого человека? Как-то версионируете модули или пытаетесь привести вундервафлю, чтобы соответствовать двум требованиям?
Это проблема большой снежной кучи. Это то, отчего мы страдаем, когда какое-то безобидное изменение может сломать какую-то часть инфраструктуры. И это будет заметно только через какое-то длительное время.
Т. е. пока никак не решается?
Делаете универсальные модули. Избегайте снежинок. И все получится. Вторая половина доклада про то, как это избежать.
Здравствуйте! Спасибо за доклад! Хотел бы уточнить. За кадром осталась большая куча, ради которой я пришел. Каким образом интегрированы Puppet и раздача ролей?
User-data.
Т. е. просто выплевываете файлик и по нему как-то выполняете?
User-data – это записка, т. е. когда мы делаем клон образа, то там поднимается Daemon и пытаясь разобраться, кто он, читает записку, что он load balancer.
Т. е. это какой-то отдельный процесс, который отдается?
Не мы его изобрели. Мы им пользуемся.
Здравствуйте! У меня как раз вопрос про User — data. Вы сказали, что там есть проблемы, что кто-то может что-то не туда передать. Есть какой-то способ хранения user — data в том же самом Git, чтобы всегда было понятно, на что ссылается User-data?
Мы User-data генерируем из template. Т. е. туда прибегает какое-то количество переменных. И Terraform генерирует финальный результат. Поэтому нельзя просто так посмотреть на template и сказать, что получится, потому что все проблемы связаны с тем, что разработчик думает, что он в этой переменной передает строчку, а там прибегает массив. И у него – бац и я –тот-то, тот-то, следующая строчка, и все сломалось. Если это новый ресурс и человек поднимает его, видит, что что-то не работает, то это быстро решается. А если это autoscale-группа обновилась, то в какой-то момент instances в autoscale-группе начинают подменяться. И хлоп, что-то не работает. Это обидно.
Получается, что единственное решение – это тестировать?
Да, вы видите проблему, вы туда добавляете тестовые шаги. Т. е. output’ом тоже можно тестировать. Может быть, не так удобно, но тоже можно какие-то метки поставить – проверяйте, что User-data тут гвоздями прибита.
Меня зовут Тимур. Очень классно, что есть доклады про то, как правильно организовывать Terraform .
Я даже не начинал.
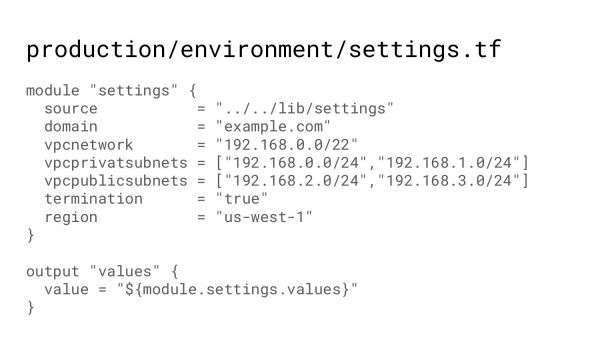
Я думаю, что в следующей конференции, может быть, будет. У меня есть простой вопрос. Почему вы хардкодите значение в отдельном модуле, а не используете tfvars, т. е. чем лучше модуль со значениями, чем tfvars ?
Т. е. мне здесь (слайд: Production/environment/settings.tf) написать: domain = переменная, domain vpcnetwork, переменная vpcnetwork и stvars – достать тоже самое?
Мы же точно так делаем. Ссылаемся на модуль setting source, например.
По сути, это такой tfvars. Tfvars очень удобен в testing-окружении. У меня есть tfvars для больших instances, для маленьких. И я один файлик кинул в папку. И получил то, что я хотел. Когда мы инфраструктуру пилим, мы хотим, чтобы можно было посмотреть и сразу все понять. А так получается, что надо глянуть сюда, потом глянуть в tfvars.
Получается, чтобы все было в одном месте?
Да, tfvars – это когда у вас один код. И он используется в нескольких разных местах с разными нюансами. Тогда вы бы tfvars кинули и получили ваши нюансы. А мы – это инфраструктура как код в чистом виде. Посмотрел и понял.
Здравствуйте! Сталкивались с такими ситуациями, когда облачный провайдер вмешивается в то, что вы сделали Terraform ’ом? Допустим, мы мета-данную правим. Там ssh -ключи. А Google постоянно туда подсовывает свои мета-данные, свои ключи. И Terraform всегда пишет, что у него есть изменения. После каждого прогона, даже если ничего не меняется, он всегда говорит, что он сейчас это поле будет обновлять.
С ключами, но – да, часть инфраструктуры поражена такой штукой, т. е. Terraform поменять ничего не может. Мы руками тоже поменять ничего не можем. Пока живем с этим.
Т. е. вы с таким сталкивались, но ничего не придумали, он как делает и делает сам?
К сожалению, да.
Здравствуйте! Меня зовут Старков Станислав. Mail. ru Group. Как решаете проблему с генерацией тега на …, как вы его передаете внутрь? Я так понимаю, через User — data, чтобы указать host name, Puppet натравить? И вторая часть вопроса. Как вы решаете этот вопрос в SG, т. е. когда вы генерируете SG, сотня однотипных instances, как их правильно наименовать?
Те instances, которые нам очень важны, мы их наименуем красиво. Те, которые не нужны, там приписка, что это autoscale-группа. И по идее это можно прибить, и получить новый.
Насчет проблемы с тегом, то нет такой проблемы, а есть такая задача. И теги у нас очень-очень сильно используются, потому что инфраструктура большая и дорогая. И нам нужно смотреть, на что уходят деньги, поэтому теги позволяют рассиропить, что и куда ушло. И, соответственно, поиск того, что что-то здесь много денег тратится.
Про что еще вопрос был?
Когда SG создает сотню instances, их нужно как-то различать?
Нет, не надо. На каждом instance есть агент, который сообщает, что у меня проблема. Если агент сообщает, то про него агент знает и, как минимум, его IP-адрес существует. Уже можно сбегать. Во-вторых, у нас используется Consul для Discovery, там, где не Kubernetes. И Consul тоже показывает IP-адрес instance.
Т. е. вы ориентируетесь именно на IP, а не на host name ?
Невозможно ориентироваться по host name, т. е. их очень много. Есть идентификаторы instance – AE и т. д. Его можно где-нибудь найти, можно его в поиск кинуть.
Привет! Я понял, что Terraform – это хорошая штука, заточенная под облака.
Не только.
Именно этот вопрос мне и интересен. Если вы решите переезжать, допустим, на Bare Metal массово со всеми своими instances? Не будет никаких проблем? Либо все-таки придется использовать другие продукты, например, тот же Ansible, который был здесь упомянут?
Ansible немножко про другое. Т. е. Ansible работает уже тогда, когда instance запустился. А Terraform работает до того, как instance запустился. Переход на Bare Metal – нет.
Сейчас нет, а придет бизнес и скажет: «Давай».
Переход на другое облако – да, но тут немножко другая фишка. Нужно писать так Terraform-код, чтобы с меньшей кровью можно было перейти на какое-то другое облако.
Изначально ставилась такая задача, что у нас вся инфраструктура – агностик, т. е. любое облако должно подойти, но в какой-то момент бизнес сдался и сказал: «Ок, в ближайшие N лет мы никуда не уйдем, можно использовать сервисы от Amazon».
Terraform позволяет создавать в Front-End jobs, конфигурировать PagerDuty, data doc и т. д. У него очень много хвостов. Он практически может контролировать весь мир.
Спасибо за доклад! Я уже тоже 4 года кручу Terraform. На этапе плавного перехода к Terraform, к инфраструктуре, к декларативному описанию, мы сталкивались с ситуацией, когда кто-то что-то делал руками, а ты пытался сделать plan. И получал там какую-то ошибку. Как вы такие проблемы разбираете? Как находите потерянные ресурсы, которые были указаны?
В основном руками и глазами, если мы видим в отчете что-то странное, то мы анализируем, что там происходит, либо просто убиваем. А вообще, pull requests – это обычное дело.
Если есть ошибка, делаете ли вы rollback? Пробовали такое делать?
Нет, это решение человека в моменте, когда он видит проблему.
Источник: habr.com
