

Веб-приложения ныне используются повсеместно, а среди всех транспортных протоколов львиную долю занимает HTTP. Изучая нюансы разработки веб-приложений, большинство уделяет очень мало внимания операционной системе, где эти приложения реально запускаются. Разделение разработки (Dev) и эксплуатации (Ops) лишь ухудшало ситуацию. Но с распространением культуры DevOps разработчики начинают нести ответственность за запуск своих приложений в облаке, поэтому для них очень полезно досконально познакомиться с бэкендом операционной системы. Это особенно полезно, если вы пытаетесь развернуть систему для тысяч или десятков тысяч одновременных подключений.
Ограничения в веб-службах очень похожи на ограничения в других приложениях. Будь то балансировщики нагрузки или серверы БД, у всех этих приложений аналогичные проблемы в высокопроизводительной среде. Понимание этих фундаментальных ограничений и способов их преодоления в целом позволит оценить производительность и масштабируемость ваших веб-приложений.
Я пишу эту серию статей в ответ на вопросы молодых разработчиков, которые хотят стать хорошо информированными системными архитекторами. Невозможно чётко понять методы оптимизации приложений Linux, не погрузившись в основы, как они работают на уровне операционной системы. Хотя есть много типов приложений, в этом цикле я хочу исследовать сетевые приложения, а не десктопные, такие как браузер или текстовый редактор. Этот материал рассчитан на разработчиков и архитекторов, которые хотят понять, как работают программы Linux или Unix и как их структурировать для высокой производительности.
Linux — это серверная операционная система, и чаще всего ваши приложения работают именно на этой ОС. Хотя я говорю «Linux», большую часть времени вы можете с уверенностью предположить, что имеются в виду все Unix-подобные операционные системы в целом. Тем не менее, я не тестировал сопровождающий код на других системах. Итак, если вас интересует FreeBSD или OpenBSD, результат может отличаться. Когда я пробую что-то Linux-специфическое, то указываю на это.
Хотя вы можете использовать полученные знания для создания приложения с нуля, и оно будет великолепно оптимизировано, но лучше так не делать. Если вы напишете новый веб-сервер на C или C++ для бизнес-приложения своей организации, возможно, это будет ваш последний день на работе. Однако знание структуры этих приложений поможет в выборе уже существующих программ. Вы сможете сравнивать системы на основе процессов с системами на основе потоков, а также на основе событий. Вы поймёте и оцените, почему Nginx работает лучше, чем Apache httpd, почему приложение Python на основе Tornado может обслуживать больше пользователей по сравнению с приложением Python на основе Django.
ZeroHTTPd: инструмент обучения
— веб-сервер, который я написал с нуля на C в качестве учебного инструмента. У него нет внешних зависимостей, в том числе доступа к Redis. Мы запускаем собственные процедуры Redis. Подробнее см. ниже.
Хотя мы могли бы долго обсуждать теорию, нет ничего лучше, чем написать код, запустить его и сравнить между собой все серверных архитектуры. Это самый наглядный метод. Поэтому мы будем писать простой веб-сервер ZeroHTTPd, применяя каждую модель: на основе процессов, потоков и событий. Проверим каждый из этих серверов и посмотрим, как они работают по сравнению друг с другом. ZeroHTTPd реализован в одном файле C. В состав сервера на основе событий входит , отличная реализация хэш-таблицы, которая поставляется в одном заголовочном файле. В остальных случаях никаких зависимостей нет, чтобы не усложнять проект.
В коде очень много комментариев, чтобы помочь разобраться. Будучи простым веб-сервером в нескольких строчках кода, ZeroHTTPd также представляет собой минимальный фреймворк для веб-разработки. У него ограниченная функциональность, но он способен выдавать статические файлы и очень простые «динамические» страницы. Должен сказать, что ZeroHTTPd хорошо подходит для обучения, как создавать высокопроизводительные Linux-приложения. По большому счёту, большинство веб-сервисов ждут запросов, проверяют их и обрабатывают. Именно это будет делать ZeroHTTPd. Это инструмент для обучения, а не для продакшна. Он не силён в обработке ошибок и вряд ли похвастается лучшими практиками безопасности (о да, я использовал strcpy) или заумными трюками языка C. Но я надеюсь, он хорошо справится со своей задачей.
Заглавная страница ZeroHTTPd. Он может выдавать разные типы файлов, включая изображения
Приложение гостевой книги
Современные веб-приложения обычно не ограничены статическими файлы. У них сложные взаимодействия с различными БД, кешами и т. д. Поэтому мы создадим простое веб-приложение под названием «Гостевая книга», где посетители оставляют записи под своими именами. В гостевой книге сохраняются записи, оставленные ранее. Есть также счётчик посетителей в нижней части страницы.
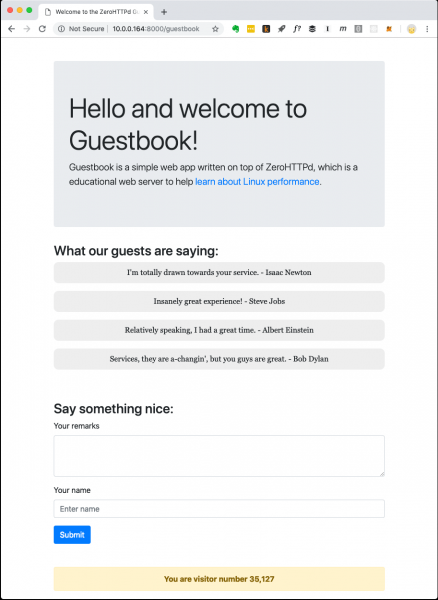
Веб-приложение «Гостевая книга» ZeroHTTPd
Счётчик посетителей и записи гостевой книги хранятся в Redis. Для коммуникаций с Redis реализованы собственные процедуры, они не зависят от внешней библиотеки. Я не большой поклонник выкатывать доморощенный код, когда есть общедоступные и хорошо протестированные решения. Но цель ZeroHTTPd — изучить производительность Linux и доступ к внешним службам, в то время как обслуживание HTTP-запросов серьёзно влияет на производительность. Мы должны полностью контролировать коммуникации с Redis в каждой из наших серверных архитектур. В одной архитектуре мы используем блокирующие вызовы, в других — процедуры на основе событий. Использование внешней клиентской библиотеки Redis не даст такой контроль. Кроме того, наш маленький клиент Redis выполняет только несколько функций (получение, настройка и увеличение ключа; получение и добавление к массиву). К тому же, протокол Redis исключительно элегантный и простой. Его даже учить специально не надо. Сам факт, что всю работу протокол выполняет примерно в ста строчках кода, говорит о том, насколько он хорошо продуман.
На следующем рисунке показаны действия приложения, когда клиент (браузер) запрашивает /guestbookURL.

Механизм работы приложения гостевой книги
Когда нужно выдать страницу гостевой книги, происходит один вызов к файловой системе для чтения шаблона в память и три сетевых вызова к Redis. Файл шаблона содержит большую часть содержимого HTML для страницы на скриншоте вверху. Там есть также специальные заполнители для динамической части контента: записей и счётчика посетителей. Мы получаем их из Redis, вставляем на страницу и выдаём клиенту полностью сформированный контент. Третьего вызова Redis можно избежать, поскольку Redis возвращает новое значение ключа при увеличении. Однако для нашего сервера с асинхронной архитектурой на основе событий множество сетевых вызовов — хорошее испытание в учебных целях. Таким образом, мы отбрасываем возвращаемое значение Redis о количестве посетителей и запрашиваем его отдельным вызовом.
Серверные архитектуры ZeroHTTPd
Мы строим семь версий ZeroHTTPd с одинаковой функциональностью, но разными архитектурами:
- Итеративная
- Форк сервер (один дочерний процесс на запрос)
- Пре-форк сервер (предварительный форкинг процессов)
- Cервер c потоками выполнения (один thread на запрос)
- Сервер с предварительным созданием потоков
- Архитектура на базе
poll() - Архитектура на базе
epoll
Измеряем производительность каждой архитектуры, загрузив сервер HTTP-запросами. Но при сравнении архитектур с высокой степенью параллелизма количество запросов увеличивается. Тестируем три раза и считаем среднее.
Методология тестирования
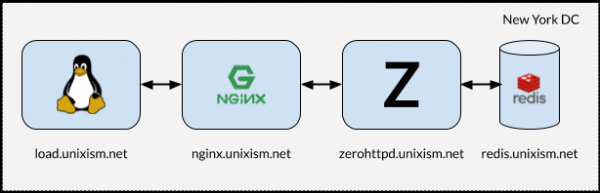
Установка для нагрузочного тестирования ZeroHTTPd
Важно, чтобы при выполнении тестов все компоненты не работали на одной машине. В этом случае ОС несёт дополнительные накладные расходы на планирование, поскольку компоненты соперничают за CPU. Измерение накладных расходов операционной системы с каждой из выбранных серверных архитектур является одной из наиболее важных целей этого упражнения. Добавление большего количества переменных станет пагубным для процесса. Следовательно, настройка на рисунке выше работает лучше всего.
Что делает каждый из этих серверов
- load.unixism.net: здесь мы запускаем
ab, утилиту Apache Benchmark. Она генерирует нагрузку, необходимую для тестирования наших серверных архитектур. - nginx.unixism.net: иногда мы хотим запустить более одного экземпляра серверной программы. Для этого сервер Nginx с соответствующими настройками работает как балансировщик нагрузки, поступающей от ab на наши серверные процессы.
- zerohttpd.unixism.net: здесь мы запускаем наши серверные программы на семи различных архитектурах, по одной за раз.
- redis.unixism.net: на этом сервере работает демон Redis, где хранятся записи в гостевой книге и счётчик посетителей.
Все серверы работают на одном процессорном ядре. Идея в том, чтобы оценить максимальную производительность каждой из архитектур. Так как все серверные программы тестируются на одном оборудовании, это базовый уровень для их сравнения. Моя тестовая установка состоит из виртуальных серверов, арендованных у Digital Ocean.
Что мы измеряем?
Можно измерить разные показатели. Мы оцениваем производительность каждой архитектуры в данной конфигурации, загружая серверы запросами на разных уровнях параллелизма: нагрузка растёт от 20 до 15 000 одновременных пользователей.
Результаты тестов
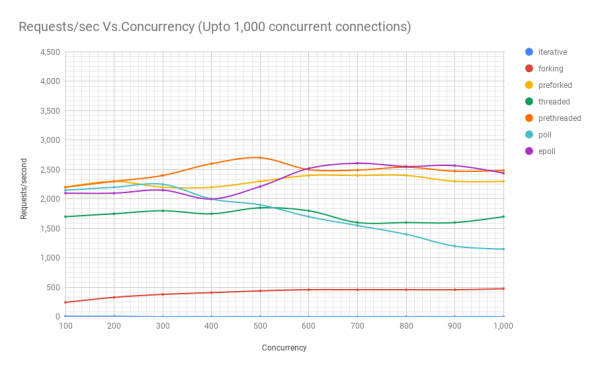
На следующей диаграмме показана производительность серверов на разной архитектуре при различных уровнях параллелизма. По оси y — количество запросов в секунду, по оси x — параллельные соединения.
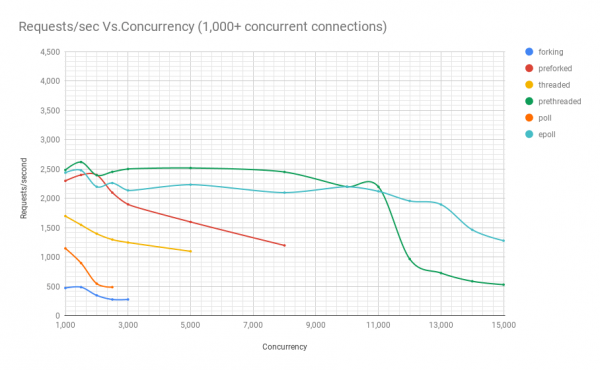
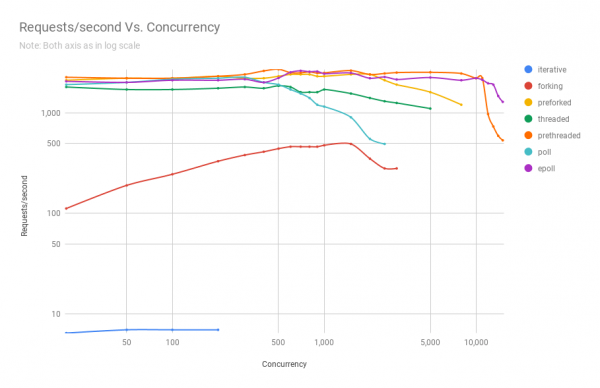
Ниже таблица с результатами.
запросов в секунду
параллелизм
итеративный
форк
пре-форк
потоковый
пре-потоковый
poll
epoll
20
7
112
2100
1800
2250
1900
2050
50
7
190
2200
1700
2200
2000
2000
100
7
245
2200
1700
2200
2150
2100
200
7
330
2300
1750
2300
2200
2100
300
–
380
2200
1800
2400
2250
2150
400
–
410
2200
1750
2600
2000
2000
500
–
440
2300
1850
2700
1900
2212
600
–
460
2400
1800
2500
1700
2519
700
–
460
2400
1600
2490
1550
2607
800
–
460
2400
1600
2540
1400
2553
900
–
460
2300
1600
2472
1200
2567
1000
–
475
2300
1700
2485
1150
2439
1500
–
490
2400
1550
2620
900
2479
2000
–
350
2400
1400
2396
550
2200
2500
–
280
2100
1300
2453
490
2262
3000
–
280
1900
1250
2502
большой разброс
2138
5000
–
большой разброс
1600
1100
2519
–
2235
8000
–
–
1200
большой разброс
2451
–
2100
10 000
–
–
большой разброс
–
2200
–
2200
11 000
–
–
–
–
2200
–
2122
12 000
–
–
–
–
970
–
1958
13 000
–
–
–
–
730
–
1897
14 000
–
–
–
–
590
–
1466
15 000
–
–
–
–
532
–
1281
Из графика и таблицы видно, что выше 8000 одновременных запросов у нас остаётся только две игрока: пре-форк и epoll. С ростом нагрузки сервер на базе poll работает хуже, чем потоковый. Архитектура с предварительным созданием потоков составляет достойную конкуренцию epoll: это свидетельство, насколько хорошо ядро Linux планирует большое количество потоков.
Исходный код ZeroHTTPd
Исходный код ZeroHTTPd . Для каждой архитектуры отдельный каталог.
ZeroHTTPd
│
├── 01_iterative
│ ├── main.c
├── 02_forking
│ ├── main.c
├── 03_preforking
│ ├── main.c
├── 04_threading
│ ├── main.c
├── 05_prethreading
│ ├── main.c
├── 06_poll
│ ├── main.c
├── 07_epoll
│ └── main.c
├── Makefile
├── public
│ ├── index.html
│ └── tux.png
└── templates
└── guestbook
└── index.html
Кроме семи директорий для всех архитектур, в каталоге верхнего уровня есть ещё две: public и templates. В первом лежит файл index.html и изображение с первого скриншота. Туда можно поместить другие файлы и папки, и ZeroHTTPd должен без проблем выдать эти статические файлы. Если path в браузере соответствует пути в папке public, то ZeroHTTPd ищет в этом каталоге файл index.html. Контент для гостевой книги генерируется динамически. У него только главная страница, а её содержимое основано на файле ‘templates/guestbook/index.html’. В ZeroHTTPd легко добавляются динамические страницы для расширения. Идея заключается в том, что пользователи могут добавлять в этом каталог шаблоны и расширять ZeroHTTPd по мере необходимости.
Для сборки всех семи серверов запустите make all из каталога верхнего уровня — и все билды появятся в этом каталоге. Исполняемые файлы ищут каталоги public и templates в том каталоге, откуда они запускаются.
Linux API
Чтобы понять информацию в этом цикле статей, не обязательно хорошо разбираться в Linux API. Однако рекомендую прочитать больше на эту тему, в Сети много справочных ресурсов. Хотя мы коснёмся нескольких категорий Linux API, наше внимание будет сосредоточено в основном на процессах, потоках, событиях и сетевом стеке. Кроме книг и статей про Linux API, рекомендую также почитать маны для системных вызовов и используемых библиотечных функций.
Производительность и масштабируемость
Одно замечание о производительности и масштабируемости. Теоретически между ними нет никакой связи. У вас может быть веб-сервис, который работает очень хорошо, с временем отклика в несколько миллисекунд, но он вообще не масштабируется. Точно так же может быть плохо работающее веб-приложение, которое требует несколько секунд для ответа, но оно масштабируется на десятки для обработки десятков тысяч одновременных пользователей. Тем не менее, сочетание высокой производительности и масштабируемости — очень мощное сочетание. Высокопроизводительные приложения в целом экономно используют ресурсы и, таким образом, эффективно обслуживают больше одновременных пользователей на сервере, снижая затраты.
Задачи CPU и I/O
Наконец, в вычислениях всегда два возможных типа задач: для I/O и CPU. Получение запросов через интернет (сетевой ввод-вывод), обслуживание файлов (сетевой и дисковый ввод-вывод), коммуникации с базой данных (сетевой и дисковый ввод-вывод) — всё это действия I/O. Некоторые запросы к БД могут немного нагружать CPU (сортировка, вычисление среднего значения миллиона результатов и т. д.). Большинство веб-приложений ограничены по максимально возможному I/O, а процессор редко используется на полную мощность. Когда вы видите, что в какой-то задаче ввода-вывода используется много CPU, скорее всего, это признак плохой архитектуры приложения. Это может означать, что ресурсы CPU тратятся на управление процессами и переключение контекста — и это не совсем полезно. Если вы делаете что-то вроде обработки изображений, преобразования аудиофайлов или машинного обучения, тогда приложение требует мощных ресурсов CPU. Но для большинства приложений это не так.
Более подробно о серверных архитектурах
Источник: habr.com
