

Hi all. Below is the decryption .
– a system for monitoring various systems and services, with the help of which system administrators can collect information about the current parameters of systems and set up alerts to receive notifications about deviations in the operation of systems.
The report will compare и — projects for long-term storage of Prometheus metrics.



Let me tell you about Prometheus first. This is a monitoring system that collects metrics from given targets and stores them in local storage. Prometheus can write metrics to remote storage, can generate alerts and recording rules.

Prometheus Limitations:
- It does not have a global query view. This is when you have multiple independent prometheus instances. They collect metrics. And you want to query on top of all these metrics collected from different prometheus instances. Prometheus does not allow this.
- With prometheus, performance is limited to only one server. Prometheus cannot automatically scale to multiple servers. You can only manually split your targets between multiple Prometheus.
- The scope of metrics in Prometheus is limited to only one server for the same reason that it can't automatically scale to multiple servers automatically.
- In Prometheus, it is not so easy to organize the safety of data.

Solutions to these problems/tasks?
Solutions are:
All these solutions are for remote storage of data collected by Prometheus. They solve the remote storage problem from the previous slide in different ways. In this presentation, I will only talk about the first two solutions: и .
For the first time information about appeared on . The architecture is described and how it works.

Thanos takes the data that Prometheus saved to the local drive and copies it to S3, or to another object storage.

Thus Thanos provides a global query view. You can query data stored in object storage from multiple Prometheus instances.

Thanos supports PromQL and .

Thanos uses Prometheus code to store data.

Thanos is developed by the same developers as Prometheus.
About . Here where we first talked about .
VictoriaMetrics receives data from several prometheus protocol supported by Prometheus.
VictoriaMetrics provides a global query view, as multiple Prometheus instances can write data to a single VictoriaMetrics. Accordingly, you can make queries on all these data.

VictoriaMetrics also supports, like Thanos, PromQL and Prometheus querying API.

Unlike Thanos, VictoriaMetrics' source code is written from scratch and optimized for speed and resource consumption.

VictoriaMetrics, unlike Thanos, scales both vertically and horizontally. Eat , which scales vertically. You can start with one processor and 1 GB of memory and grow up to hundreds of processors and 1 TB of memory. VictoriaMetrics knows how to use all these resources. Its performance will increase by about 100 times compared to a 1-core system.

The history of Thanos began in November 2017, when the first public commit appeared. Prior to this, Thanos was developed in-house .

In June 2019, there was a landmark release 0.5.0, in which protocol. He was removed from Thanos because he did not perform well. Often the Thanos cluster did not work correctly, nodes connected to it incorrectly due to the gossip protocol. So we decided to remove it from there. I believe this is the right decision.

In the same June 2019, they sent an application number в .

And after a couple of months, Thanos was accepted into , which includes Prometheus, Kubernetes and other popular projects.

In January 2018, the development of VictoriaMetrics began.

In September 2018, I first publicly mentioned VictoriaMetrics.

In December 2018, the Single-node version was published.

In 2019 sources of both Single-node and cluster version.

In June 2019, just like Thanos, we submitted an application to the CNCF foundation under the number . We applied one day before Thanos applied.

But, unfortunately, we still have not been accepted there. Community help needed.

Consider the most important slides showing the architecture of Thanos and VictoriaMetrics.
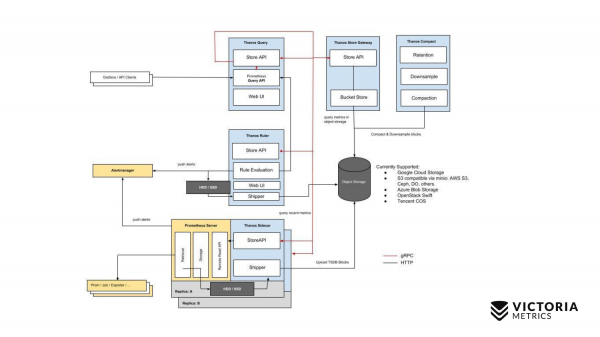
Let's start with Thanos. The yellow components are Prometheus components. Everything else is Thanos components. Let's start with the most important component. Thanos Sidecar is a component that is installed next to every Prometheus. It is responsible for loading Prometheus data from local storage to S3 or other Object Storage.
There is also such a component as Thanos Store Gateway, which can read this data from Object Storage upon incoming requests from Thanos Query. Thanos Query implements PromQL and Prometheus API. That is, from the outside it looks like Prometheus. It accepts PromQL requests, sends them to Thanos Store Gateway, Thanos Store Gateway gets the necessary data from Object Storage, sends it back.
But we have data stored in Object Storage without the last two hours due to the implementation of Thanos Sidecar, which cannot upload the last two hours to Object Storage S3, since Prometheus has not yet created files in local storage for these two hours.
How did you decide to get around this? Thanos Query, in addition to requests to the Thanos Store Gateway, sends parallel requests to each Thanos Sidecar that is next to Prometheus.
And Thanos Sidecar, in turn, proxies requests further to Prometheus, and gets data for the last two hours.
In addition to these components, there is also an optional component, without which Thanos will feel bad. This is Thanos Compact, which merges small files on Object Storage into larger files that have been uploaded here by Thanos Sidecars. Thanos Sidecar uploads data files there for two hours. These files, if they are not merged into larger files, their number can grow very significantly. The more such files, the more memory is needed for Thanos Store Gateway, the more resources are needed to transfer data over the network, metadata. Thanos Store Gateway becomes inefficient. Therefore, it is necessary to run Thanos Compact, which merges small files into larger ones, so that there are fewer such files and to reduce overhead on Thanos Store Gateway.
There is also such a component as Thanos Ruler. It executes Prometheus alerting rules and can compute Prometheus recording rules in order to write data back to Object Storage. But this component is not recommended to be used, because. He .
Here is a simple scheme for Thanos.
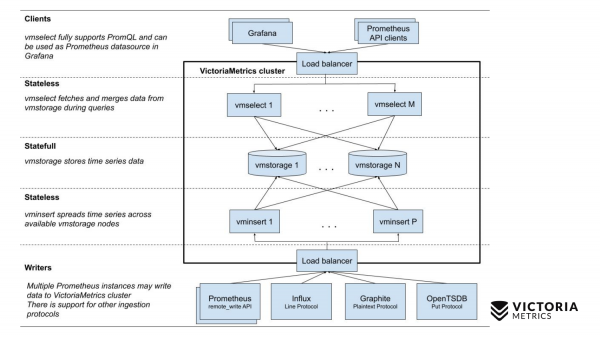
Now let's compare with the VictoriaMetrics scheme.
VictoriaMetrics has 2 versions: Single-node and cluster version. Single-node runs on one computer. Single-node does not have these components, just one binary. This binary on the slide looks like this square. Everything inside the square is the contents of the binary file for the Single-node version. You don't need to know about it. Just run the binary - and everything works for us.
The cluster version is more difficult. Inside it are three different components: vmselect, vminsert and vmstorage. From their name it should be clear what each of them does. The Insert component accepts data in different formats: from the Prometheus remote write API, the Influx line protocol, the Graphite protocol, and the OpenTSDB protocol. The Insert component accepts them, parses them, and distributes them among the existing storage components, where the data is already stored. The Select component, in turn, accepts PromQL requests. It implements , as well as the Prometheus querying API, and can be used as a replacement for Prometheus in Grafana or other Prometheus API clients. Select takes a promql request, parses it, reads the necessary data to execute this request from storage nodes, processes this data and returns a response.

Let's compare the complexity of installing Thanos and VictoriaMetrics.

Let's start with Thanos. Before you start working with Thanos, you need to create a bucket in Object Storage, such as S3 or GCS, so that Thanos Sidecar can write data there.

Then for each Prometheus you need to install Thanos Sidecar. Before that, you need to remember to disable data compaction in Prometheus. Data compaction periodically compresses data in Prometheus local storage in order to reduce resource consumption.
When you install Thanos Sidecar on your Prometheus you must disable this data compaction because Thanos Sidecar does not work properly with data compaction enabled. This means that your Prometheus starts saving data in blocks of two hours and stops merging these blocks into larger ones. Accordingly, if you make requests that exceed the duration of the last two hours, then they will not work as efficiently as they could work if data compaction were enabled.

Therefore, Thanos recommends reducing the data retention time in local storage to 6-8 hours in order to reduce this overhead of a large number of small blocks.
After you have installed Thanos Sidecar, you must install two components for each Object Storage Bucket. These are Thanos Compactor and Thanos Store Gateway.

After that, you need to install Thanos Query and configure it so that it can connect to all Thanos Store Gateways that you have, as well as be able to connect to all Thanos Sidecars.
There might be a little problem here.

You need to set up a reliable and secure connection from Thanos Query to these components. And if you have Prometheus'y located in different data centers, or in different VPCs, then connections to them from the outside are prohibited. But for Thanos Query to work, you need to somehow configure the connection there, and you must come up with a way.
If you have a lot of such data centers, then, accordingly, the reliability of the entire system decreases. Since Thanos Query must constantly keep connections to all Thanos Sidecars located in different data centers. With each incoming request, it will send requests to all Thanos Sidecars. If the connection is interrupted, then you will either receive an incomplete data set, or you will receive a response “the cluster is not working”.

In VictoriaMetrics, things are a little simpler. For the Single-node version, just run one binary and everything works.

In the clustered version, it is enough to run all the above three types of components in any quantity you need, or use to automate the launch of components in Kubernetes. We are also planning to make a Kubernetes operator. Helm chart doesn't cover some cases and allows you to shoot your foot. For example, it allows you to reduce the number of storage nodes, which will lead to data loss.

After you have launched one binary or clustered version, you just need to add to the Prometheus config so that it starts writing data in parallel to local storage and remote storage. As you can see, this configuration should work much more reliably than the Thanos configuration. We do not need to keep a connection from VictoriaMetrics to all Prometheus's, because Prometheus's themselves connect to VictoriaMetrics and transfer data.

Consider support for Thanos and VictoriaMetrics.

Thanos needs to keep an eye on Sidecar so they don't stop uploading data to Object Storage. They may stop this data download due to download errors, for example, your network connection to Object Storage is temporarily lost, or Object Storage is temporarily unavailable. Thanos Sidecar will notice this at this point, report an error, may crash and then stop working. If you do not monitor it, then your data will no longer be transferred to Object Storage. If the retention time passes (6-8 hours is recommended), then you will lose data that did not get into Object Storage.

Thanos compactors may stop working due to . Compactors take data from Object Storage and merge it into larger chunks of data. Since the compactors are not synchronized with the Sidecars, the following can happen: the Sidecar has not had time to add the block yet, the Compactor decides that this block has been completely written. Compactor starts reading it. It reads the block incompletely and stops working. See details .

Store Gateway may return inconsistent data due to races between Compactor and Sidecars. It's the same thing here, because Store Gateway is not synchronized with Compactors and Sidecars in any way. Accordingly, race conditions may occur when the Store Gateway does not see part of the data, or sees extra data.

The Query component in Thanos returns a partial result by default if some Sidecars or Store Gateways are not available at the moment. You will receive some of the data, and will not even know that you did not receive all the data. This is how it works by default. In a similar situation, VictoriaMetrics returns labeled data as partial.

Unlike Thanos, VictoriaMetrics rarely loses data. Even if the connection from Prometheus to VictoriaMetrics is interrupted, then this is not a problem, since Prometheus continues to write incoming new data to the Write Ahead Log, which is 2 hours long. If you restore the connection to VictoriaMetrics within two hours, the data will not be lost. Prometheus .

Unlike Thanos, which writes data to object storage only after two hours, Prometheus automatically replicates data via remote write protocol to remote storage, such as VictoriaMetrics. You are not afraid of losing local storage in Prometheus. If he suddenly lost local storage, then you will lose the last seconds of data that did not have time to write to remote storage in the worst case.

Kubernetes manages the cluster automatically unlike Thanos. It is difficult to place all Thanos components in one Kubernetes cluster, unlike VictoriaMetrics cluster components.

VictoriaMetrics has a very easy upgrade to the new version. Just stop VictoriaMetrics, update the binaries and start. When stopped via a SIGINT signal, all VictoriaMetrics binaries do a gracefull shutdown. They correctly store the necessary data, correctly close incoming connections so as not to lose anything. So you won't lose anything when you upgrade.

It is very easy for VictoriaMetrics to expand the cluster. Just add the necessary components and keep working.

About pitfalls in Thanos and VictoriaMetrics.

Thanos has the following pitfalls. Prometheus should store data for the last two hours. If they get lost, you will completely lose them, since they have not had time to write to Object Storage, such as S3.

The Store Gateway component and compactor component can be memory intensive to deal with large Object Storage if there are many small files stored there. The larger the number and size of files, the more RAM the Store Gateway and compactor require to store meta information. Thanos has a lot of issues about what .

Thanos is advertised as being able to scale indefinitely by the number of Prometheus you have. Actually this is not true. Since all requests go through the Query component, which must poll all Store Gateway components and all Sidecar components in parallel, extract data from there and then preprocess them. It is obvious that the rate of requests is limited by the slowest weak link, the slowest Store Gateway or the slowest Sidecar.
These components may be unevenly loaded. For example, you have Prometheus, which collects millions of metrics per second. And there is Prometheus, which collects thousands of metrics per second. Prometheus, which collects millions of metrics per second, loads the server on which it runs much more. Accordingly, Sidecar is slower there. And in general, everything there is slow. And the Query component will pull data very slowly from there. Accordingly, the performance of your entire cluster will be limited by this slow Sidecar.

By default, Thanos returns partial data if some Sidecars and either Store Gateways are unavailable. For example, if you have Sidecars scattered all over the world in different data centers, then the probability of a disconnection and unavailability of components greatly increases. Accordingly, in most cases, you will receive partial data without even knowing it.
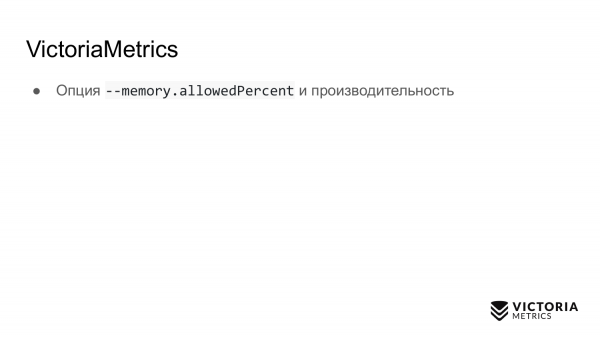
VictoriaMetrics also has pitfalls. The first pitfall is an option that limits the amount of RAM used for the VictoriaMetrics cache. It defaults to 60% RAM on the machine where VictoriaMetrics is running, or 60% RAM on the VictoriaMetrics pod in Kubernetes.
If you change this value incorrectly, you can ruin the performance of VictoriaMetrics. For example, if the value is set too low, then the data may no longer fit into the VictoriaMetrics cache. Because of this, she will have to do extra work and load the processor with the disk. If you make this option too large, it increases, firstly, the likelihood that VictoriaMetrics will crash with an out of memory error, and secondly, it will lead to the fact that the operating system will have very little RAM left. memory for the file cache. And VictoriaMetrics relies on the file cache for performance. If it is not enough, then the load on the disk can greatly increase. Therefore, advice: do not change the parameter unless absolutely necessary.
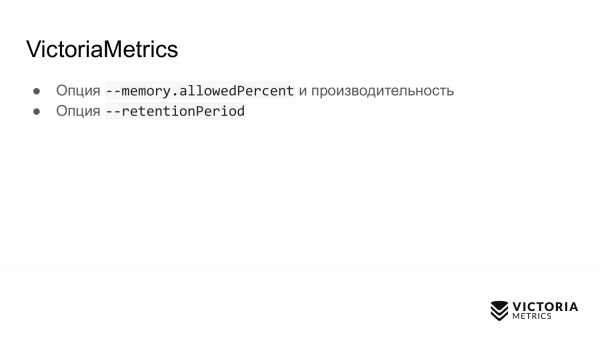
Second option. This retentionPeriod is a period that is set to 1 month by default. This is the time during which VictoriaMetrics keeps the data. After this period, VictoriaMetrics deletes the data.
Many people run VictoriaMetrics without this option and record data for a month. And then they ask: why did the data disappear for the previous month? Because the default retentionPeriod is 1 month. Therefore, you need to know and set the correct retentionPeriod.

Let's go through the unique features.

Thanos has a feature called downsampling: 5-minute and hourly intervals, which are often . If you google and look at their issue on github, there are a lot of issues related to this downsampling, that it sometimes does not work correctly, or does not work as users expect.

Thanos has data deduplication for Prometheus HA pairs. When two Prometheus collect the same metrics from the same targets and Thanos adds them to Object Storage. Thanos can properly dedupe this data, unlike VictoriaMetrics.

Thanos has an alert component that was on the Thanos schematic. But him .

Thanos has the advantage that Thanos and Prometheus share the same code. Thanos and Prometheus are developed by the same developers. With improvements in Thanos or Prometheus, the other side wins.

VictoriaMetrics' main feature is MetricsQL. These are the VictoriaMetrics extensions for PromQL, which I talked about at the previous big monitoring metup.

VictoriaMetrics supports uploading data using many different protocols. VictoriaMetrics can not only receive data from Prometheus, but also via the Influx, OpenTSDB and Graphite protocols.

VictoriaMetrics data takes up much less space than Thanos and Prometheus.
When writing real data, users are talking about a 2-5 fold reduction in data size on disk compared to Prometheus and Thanos.

Another advantage of VictoriaMetrics is that it is optimized for speed.

Let's go over the cost of infrastructure.

One of the advantages of Thanos is that it stores data in object storage, which is relatively cheap.
When storing data in object storage, you must pay for data writing and reading operations ($10 per million operations). When you write data to object storage, you pay for your hosting costs for uploading data to the Internet, if your cluster is not in AWS - it's free there. When you read data, you pay between $10 and $230 for 1TB. This can be significant if you frequently request historical data from the Thanos cluster.

For a Thanos cluster, you need to pay for servers for Compact, Store Gateway, Query components that require a lot of memory, CPU for large amounts of data.

VictoriaMetrics has the following costs. If you store data on GCE HDDs, then $40 for 1TB comes out. For VictoriaMetrics, ordinary HDD drives are enough, no SSDs are needed, which cost five times more. VictoriaMetrics is optimized for HDD.

VictoriaMetrics needs servers for components: either Single-nod or for clustered components, which, unlike Thanos components, require much less CPU, RAM - respectively, it will be cheaper.

Implementation examples.

For Thanos, the implementation example is Gitlab. Gitlab runs entirely on Thanos. But not everything is so smooth there. If you look at them , then you can see that they constantly have some : Not enough memory for Store Gateway or Query components. They constantly have to increase the amount of memory.
Because of this, the costs of solving these problems increase.
The second implementation, which may be more successful, is Improbable, who started the development of Thanos. They released the Thanos source. Improbable is a company that develops game engines.

VictoriaMetrics has public implementation examples that are:
- wix website builder
- Adidas implements VictoriaMetrics and even made a presentation at the last PromCon 2019
- TrafficStars-ad network
- Seznam.cz is a popular Czech search engine.
And then there were no-name companies that I can’t name now. They didn't agree.
- One major game developer. Bigger than im Improbable.
- Large developer of graphics software.
- Large Russian bank.
- European wind turbine manufacturer that has successfully tested VictoriaMetrics. This manufacturer is implementing VictoriaMetrics to monitor wind turbine data at a rate of 50 samples per second per sensor. Each wind turbine has several hundred sensors. They have several hundred wind turbines.
- Russian airlines that want to implement VictoriaMetrics but still can't. We are at the contract stage with them.
 Conclusions.
Conclusions.
VictoriaMetrics and Thanos solve similar problems, but in different ways:
- global query view
- horizontal scaling
- arbitrary retention

Thank you.
We are waiting for you on our .

Only registered users can participate in the survey. , you are welcome.
What do you use as long term storage for Prometheus?
35,3%Thanos6
0,0%Cortex0
0,0%M3DB0
41,2%VictoriaMetrics7
23,5%other4
17 users voted. 16 users abstained.
Source: habr.com
