

Всем привет. Мы разрабатываем продукт для анализа оффлайн-трафика. В проекте есть задача, связанная со статистическим анализом путей движения посетителей по областям.
В рамках этой задачи пользователи могут задавать системе запросы следующего вида:
- сколько посетителей прошло из области "A" в область "Б";
- сколько посетителей прошло из области "A" в область "Б" через область "C", а затем через область "Д";
- сколько времени заняло прохождение посетителя определенного типа из области "А" в область "Б".
и еще ряд подобных аналитических запросов.
Движение посетителя по областям представляет собой направленный граф. Почитав интернеты, я обнаружил, что графовые СУБД используются и для аналитических отчетов. У меня появилось желание посмотреть как будут справляться с подобными запросами графовые СУБД (TL;DR; плохо).
Я выбрал для использования СУБД , как выдающегося представителя графовых open-source СУБД, которая опирается на стек зрелых технологий, которые (по моему мнению) должны были бы обеспечить ей приличные операционные характеристики:
- бэкенд хранилища BerkeleyDB, Apache Cassandra, Scylla;
- сложные индексы можно хранить в Lucene, Elasticsearch, Solr.
Авторы JanusGraph пишут, что она подходит как для OLTP, так и для OLAP.
Я работал с BerkeleyDB, Apache Cassandra, Scylla и ES, кроме того, данные продукты часто используются в наших системах, поэтому я с оптимизмом смотрел на тестирование этой графовой СУБД. Мне показался странным выбор BerkeleyDB, а не RocksDB, но, вероятно, это связано с требованиям к транзакциям. В любом случае, для масштабируемого, продуктового использования предлагается использовать бэкенд на Cassandra или Scylla.
Neo4j я не рассматривал, поскольку для кластеризации требуется коммерческая версия, то есть продукт не является открытым.
Графовые СУБД говорят: "Если что-то выглядит как граф — обрабатывайте это как граф!" — красота!
Сначала я нарисовал граф, который вот прям по канонам графовых СУБД сделан:
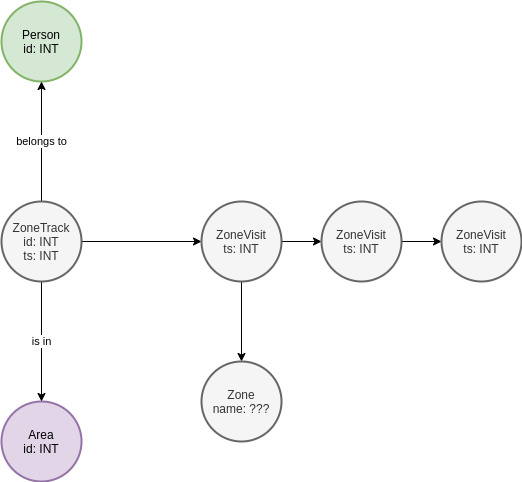
Есть сущность Zone, отвечающая за область. Если ZoneStep принадлежит этой Zone, то он на нее ссылается. На сущности Area, ZoneTrack, Person внимание не обращайте, они принадлежат домену и в рамках теста не рассматриваются. Итого, к такой графовой структуре запрос поиска цепочек выглядел бы как:
g.V().hasLabel('Zone').has('id',0).in_()
.repeat(__.out()).until(__.out().hasLabel('Zone').has('id',19)).count().next()Что на русском примерно так: найди Zone с ID=0, возьми все вершины, от которых к ней идет ребро (ZoneStep), топай без возврата назад пока не найдешь такие ZoneStep, из которых идет ребро в Zone с ID=19, посчитай количество таких цепочек.
Я не претендую на знание все тонкостей поиска на графах, но данный запрос был сгенерирован на основе вот этой книги ().
Я загрузил 50 тысяч треков длиной от 3 до 20 точек в графовую базу JanusGraph, использующую бэкенд BerkeleyDB, создал индексы согласно .
Скрипт для загрузки на Python:
from random import random
from time import time
from init import g, graph
if __name__ == '__main__':
points = []
max_zones = 19
zcache = dict()
for i in range(0, max_zones + 1):
zcache[i] = g.addV('Zone').property('id', i).next()
startZ = zcache[0]
endZ = zcache[max_zones]
for i in range(0, 10000):
if not i % 100:
print(i)
start = g.addV('ZoneStep').property('time', int(time())).next()
g.V(start).addE('belongs').to(startZ).iterate()
while True:
pt = g.addV('ZoneStep').property('time', int(time())).next()
end_chain = random()
if end_chain < 0.3:
g.V(pt).addE('belongs').to(endZ).iterate()
g.V(start).addE('goes').to(pt).iterate()
break
else:
zone_id = int(random() * max_zones)
g.V(pt).addE('belongs').to(zcache[zone_id]).iterate()
g.V(start).addE('goes').to(pt).iterate()
start = pt
count = g.V().count().next()
print(count)Использовалась VM c 4 ядрами и 16 GB RAM на SSD. JanusGraph был развернут с помощью вот такой команды:
docker run --name janusgraph -p8182:8182 janusgraph/janusgraph:latestВ этом случае данные и индексы, которые используются для поиска по точному совпадению хранятся в BerkeleyDB. Выполнив запрос, приведенный ранее, я получил время равное нескольким десяткам секунд.
Запустив 4 вышеприведенных скрипта в параллель, мне удалось превратить СУБД в тыкву с веселым потоком стектрейсов Java (а мы все любим читать стектрейсы Java) в логах Docker.
Поразмышляв, я решил упростить схему графа до следующей:
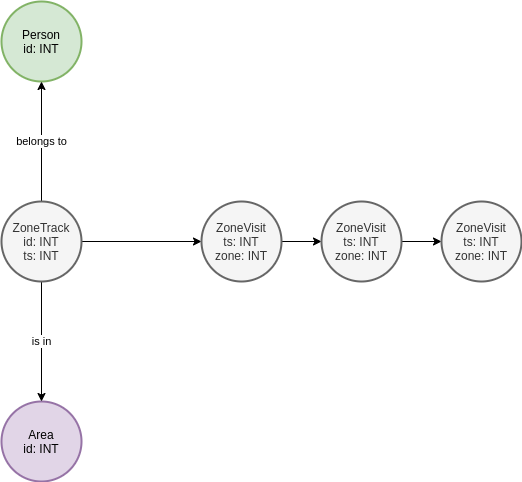
Решив, что поиск по атрибутам сущности будет быстрее, чем поиск по ребрам. В итоге мой запрос превратился в следующий:
g.V().hasLabel('ZoneStep').has('id',0).repeat(__.out().simplePath()).until(__.hasLabel('ZoneStep').has('id',19)).count().next()Что на русском примерно так: найди ZoneStep с ID=0, топай без возврата назад пока не найдешь ZoneStep с ID=19, посчитай количество таких цепочек.
Скрипт загрузки, приведенный выше, я тоже упростил, для того, чтобы не создавать лишних связей, ограничившись атрибутами.
Запрос все еще выполнялся несколько секунд, что было совершенно неприемлемо для нашей задачи, поскольку для целей AdHoc запросов произвольного вида это совсем не подходило.
Я попробовал развернуть JanusGraph с использованием Scylla, как наиболее быстрой реализации Cassandra, но это тоже не привело каким-то существенным изменениям производительности.
Таким образом, несмотря на то, что "это выглядит как граф", мне не удалось заставить графовую СУБД обработать это быстро. Вполне предполагаю, что я чего-то не знаю и можно заставить JanusGraph выполнять этот поиск за доли секунды, однако, мне это не удалось.
Поскольку решить задачу все равно было нужно, я начал думать о JOIN-ах и Pivot-ах таблиц, что не внушало оптимизма с точки зрения изящности, но могло быть вполне рабочим вариантом на практике.
В нашем проекте уже используется Apache ClickHouse, поэтому я решил проверить свои изыскания на этой аналитической СУБД.
Развернул ClickHouse по простому рецепту:
sudo docker run -d --name clickhouse_1
--ulimit nofile=262144:262144
-v /opt/clickhouse/log:/var/log/clickhouse-server
-v /opt/clickhouse/data:/var/lib/clickhouse
yandex/clickhouse-serverСоздал в нем БД и таблицу вида:
CREATE TABLE
db.steps (`area` Int64, `when` DateTime64(1, 'Europe/Moscow') DEFAULT now64(), `zone` Int64, `person` Int64)
ENGINE = MergeTree() ORDER BY (area, zone, person) SETTINGS index_granularity = 8192Заполнил ее данными следующим скриптом:
from time import time
from clickhouse_driver import Client
from random import random
client = Client('vm-12c2c34c-df68-4a98-b1e5-a4d1cef1acff.domain',
database='db',
password='secret')
max = 20
for r in range(0, 100000):
if r % 1000 == 0:
print("CNT: {}, TS: {}".format(r, time()))
data = [{
'area': 0,
'zone': 0,
'person': r
}]
while True:
if random() < 0.3:
break
data.append({
'area': 0,
'zone': int(random() * (max - 2)) + 1,
'person': r
})
data.append({
'area': 0,
'zone': max - 1,
'person': r
})
client.execute(
'INSERT INTO steps (area, zone, person) VALUES',
data
)Поскольку вставки идут батчами, заполнение было гораздо быстрее, чем для JanusGraph.
Сконструировал два запроса с помощью JOIN. Для перехода из точки A в точку Б:
SELECT s1.person AS person,
s1.zone,
s1.when,
s2.zone,
s2.when
FROM
(SELECT *
FROM steps
WHERE (area = 0)
AND (zone = 0)) AS s1 ANY INNER JOIN
(SELECT *
FROM steps AS s2
WHERE (area = 0)
AND (zone = 19)) AS s2 USING person
WHERE s1.when <= s2.whenДля перехода через 3 точки:
SELECT s3.person,
s1z,
s1w,
s2z,
s2w,
s3.zone,
s3.when
FROM
(SELECT s1.person AS person,
s1.zone AS s1z,
s1.when AS s1w,
s2.zone AS s2z,
s2.when AS s2w
FROM
(SELECT *
FROM steps
WHERE (area = 0)
AND (zone = 0)) AS s1 ANY INNER JOIN
(SELECT *
FROM steps AS s2
WHERE (area = 0)
AND (zone = 3)) AS s2 USING person
WHERE s1.when <= s2.when) p ANY INNER JOIN
(SELECT *
FROM steps
WHERE (area = 0)
AND (zone = 19)) AS s3 USING person
WHERE p.s2w <= s3.whenЗапросы, конечно, выглядят довольно страшно, для реального использования требуется делать программную обвязку-генератор. Однако, они работают и работают быстро. И первый и второй запросы выполняются менее чем за 0.1 сек. Вот пример времени исполнения запроса для count(*) прохода по 3м точкам:
SELECT count(*)
FROM
(
SELECT
s1.person AS person,
s1.zone AS s1z,
s1.when AS s1w,
s2.zone AS s2z,
s2.when AS s2w
FROM
(
SELECT *
FROM steps
WHERE (area = 0) AND (zone = 0)
) AS s1
ANY INNER JOIN
(
SELECT *
FROM steps AS s2
WHERE (area = 0) AND (zone = 3)
) AS s2 USING (person)
WHERE s1.when <= s2.when
) AS p
ANY INNER JOIN
(
SELECT *
FROM steps
WHERE (area = 0) AND (zone = 19)
) AS s3 USING (person)
WHERE p.s2w <= s3.when
┌─count()─┐
│ 11592 │
└─────────┘1 rows in set. Elapsed: 0.068 sec. Processed 250.03 thousand rows, 8.00 MB (3.69 million rows/s., 117.98 MB/s.)Замечание про IOPS. При заполнении данных, JanusGraph генерировал довольно высокое количество IOPS (1000-1300 для четырех потоков заполнения данными), а IOWAIT был довольно высоким. В то же время, ClickHouse генерировал минимальную нагрузку на дисковую подсистему.
Заключение
Мы решили использовать ClickHouse для обслуживания запросов этого типа. Мы всегда можем еще больше оптимизировать запросы, используя материализованные представления и параллелизацию, выполняя предварительную обработку потока событий с помощью Apache Flink перед загрузкой их в ClickHouse.
Производительность настолько хороша, что нам, вероятно, даже не придется думать о pivot-ах таблиц программными средствами. Ранее, нам приходилось делать pivot-ы данных, извлекаемых из Vertica через выгрузку в Apache Parquet.
К сожалению, очередная попытка использования графовой СУБД не увенчалась успехом. Я не обнаружил, что у JanusGraph дружелюбная экосистема, которая позволяет быстро освоиться с продуктом. При этом для конфигурирования сервера применяется традиционный Java-way, который людей с Java не знакомых заставит плакать кровавыми слезами:
host: 0.0.0.0
port: 8182
threadPoolWorker: 1
gremlinPool: 8
scriptEvaluationTimeout: 30000
channelizer: org.janusgraph.channelizers.JanusGraphWsAndHttpChannelizer
graphManager: org.janusgraph.graphdb.management.JanusGraphManager
graphs: {
ConfigurationManagementGraph: conf/janusgraph-cql-configurationgraph.properties,
airlines: conf/airlines.properties
}
scriptEngines: {
gremlin-groovy: {
plugins: { org.janusgraph.graphdb.tinkerpop.plugin.JanusGraphGremlinPlugin: {},
org.apache.tinkerpop.gremlin.server.jsr223.GremlinServerGremlinPlugin: {},
org.apache.tinkerpop.gremlin.tinkergraph.jsr223.TinkerGraphGremlinPlugin: {},
org.apache.tinkerpop.gremlin.jsr223.ImportGremlinPlugin: {classImports: [java.lang.Math], methodImports: [java.lang.Math#*]},
org.apache.tinkerpop.gremlin.jsr223.ScriptFileGremlinPlugin: {files: [scripts/airline-sample.groovy]}}}}
serializers:
# GraphBinary is here to replace Gryo and Graphson
- { className: org.apache.tinkerpop.gremlin.driver.ser.GraphBinaryMessageSerializerV1, config: { ioRegistries: [org.janusgraph.graphdb.tinkerpop.JanusGraphIoRegistry] }}
- { className: org.apache.tinkerpop.gremlin.driver.ser.GraphBinaryMessageSerializerV1, config: { serializeResultToString: true }}
# Gryo and Graphson, latest versions
- { className: org.apache.tinkerpop.gremlin.driver.ser.GryoMessageSerializerV3d0, config: { ioRegistries: [org.janusgraph.graphdb.tinkerpop.JanusGraphIoRegistry] }}
- { className: org.apache.tinkerpop.gremlin.driver.ser.GryoMessageSerializerV3d0, config: { serializeResultToString: true }}
- { className: org.apache.tinkerpop.gremlin.driver.ser.GraphSONMessageSerializerV3d0, config: { ioRegistries: [org.janusgraph.graphdb.tinkerpop.JanusGraphIoRegistry] }}
# Older serialization versions for backwards compatibility:
- { className: org.apache.tinkerpop.gremlin.driver.ser.GryoMessageSerializerV1d0, config: { ioRegistries: [org.janusgraph.graphdb.tinkerpop.JanusGraphIoRegistry] }}
- { className: org.apache.tinkerpop.gremlin.driver.ser.GryoMessageSerializerV1d0, config: { serializeResultToString: true }}
- { className: org.apache.tinkerpop.gremlin.driver.ser.GryoLiteMessageSerializerV1d0, config: {ioRegistries: [org.janusgraph.graphdb.tinkerpop.JanusGraphIoRegistry] }}
- { className: org.apache.tinkerpop.gremlin.driver.ser.GraphSONMessageSerializerGremlinV2d0, config: { ioRegistries: [org.janusgraph.graphdb.tinkerpop.JanusGraphIoRegistry] }}
- { className: org.apache.tinkerpop.gremlin.driver.ser.GraphSONMessageSerializerGremlinV1d0, config: { ioRegistries: [org.janusgraph.graphdb.tinkerpop.JanusGraphIoRegistryV1d0] }}
- { className: org.apache.tinkerpop.gremlin.driver.ser.GraphSONMessageSerializerV1d0, config: { ioRegistries: [org.janusgraph.graphdb.tinkerpop.JanusGraphIoRegistryV1d0] }}
processors:
- { className: org.apache.tinkerpop.gremlin.server.op.session.SessionOpProcessor, config: { sessionTimeout: 28800000 }}
- { className: org.apache.tinkerpop.gremlin.server.op.traversal.TraversalOpProcessor, config: { cacheExpirationTime: 600000, cacheMaxSize: 1000 }}
metrics: {
consoleReporter: {enabled: false, interval: 180000},
csvReporter: {enabled: false, interval: 180000, fileName: /tmp/gremlin-server-metrics.csv},
jmxReporter: {enabled: false},
slf4jReporter: {enabled: true, interval: 180000},
gangliaReporter: {enabled: false, interval: 180000, addressingMode: MULTICAST},
graphiteReporter: {enabled: false, interval: 180000}}
threadPoolBoss: 1
maxInitialLineLength: 4096
maxHeaderSize: 8192
maxChunkSize: 8192
maxContentLength: 65536
maxAccumulationBufferComponents: 1024
resultIterationBatchSize: 64
writeBufferHighWaterMark: 32768
writeBufferHighWaterMark: 65536
ssl: {
enabled: false}Мне удалось случайно "положить" BerkeleyDB версию JanusGraph.
Документация довольно кривая в части индексов, поскольку при управлении индексами требуется выполнять довольно странные шаманства на Groovy. Например, создание индекса должно производиться с помощью написания кода в консоли Gremlin (которое, кстати, не работает из коробки). Из официальной документации JanusGraph:
graph.tx().rollback() //Never create new indexes while a transaction is active
mgmt = graph.openManagement()
name = mgmt.getPropertyKey('name')
age = mgmt.getPropertyKey('age')
mgmt.buildIndex('byNameComposite', Vertex.class).addKey(name).buildCompositeIndex()
mgmt.buildIndex('byNameAndAgeComposite', Vertex.class).addKey(name).addKey(age).buildCompositeIndex()
mgmt.commit()
//Wait for the index to become available
ManagementSystem.awaitGraphIndexStatus(graph, 'byNameComposite').call()
ManagementSystem.awaitGraphIndexStatus(graph, 'byNameAndAgeComposite').call()
//Reindex the existing data
mgmt = graph.openManagement()
mgmt.updateIndex(mgmt.getGraphIndex("byNameComposite"), SchemaAction.REINDEX).get()
mgmt.updateIndex(mgmt.getGraphIndex("byNameAndAgeComposite"), SchemaAction.REINDEX).get()
mgmt.commit()Послесловие
В некотором смысле приведенный выше эксперимент — это сравнение теплого с мягким. Если вдуматься, то графовая СУБД выполняет другие операции для получения тех же самых результатов. Однако, в рамках тестов я проводил и эксперимент с запросом вида:
g.V().hasLabel('ZoneStep').has('id',0)
.repeat(__.out().simplePath()).until(__.hasLabel('ZoneStep').has('id',1)).count().next()который отражает шаговую доступность. Однако и на таких данных графовая СУБД показывала результат, который выходил за пределы нескольких секунд… Это, конечно, же связано с тем, что были пути вида 0 -> X -> Y ... -> 1, которые графовый движок тоже проверял.
Даже для запроса вида:
g.V().hasLabel('ZoneStep').has('id',0).out().has('id',1)).count().next()мне не удалось получить производительный ответ с временем обработки меньше секунды.
Мораль басни такова, что красивая идея и парадигматичное моделирование не ведут к желаемому результату, который со значительно более высокой эффективностью демонстрируется на примере ClickHouse. Приведенный в этой статье вариант использования — явный антипаттерн для графовых СУБД, хотя и выглядит как подходящий для моделирования в их парадигме.
Источник: habr.com
