

The translation of the article was prepared specifically for the students of the course .

Over the past few weeks, we added to binary stream format, supplementing the already existing random access/IPC file format. We have Java and C++ implementations and Python bindings. In this article, I'll explain how the format works and show how you can achieve very high data throughput for a pandas DataFrame.
Streaming column data
A common question I get from Arrow users is the high cost of migrating large tabular datasets from a row- or record-oriented format to a column format. For multi-gigabyte datasets, transposing in memory or on disk can be overwhelming.
For streaming data, whether the source data is row or column, one option is to send small batches of rows, each containing a column layout internally.
In Apache Arrow, a collection of in-memory columnar arrays representing a table chunk is called a record batch. To represent a single data structure of a logical table, you can collect several sets of records.
In the existing "random access" file format, we write metadata containing the table schema and block layout at the end of the file, which allows you to select any batch of records or any column from the dataset very cheaply. In a streaming format, we send a series of messages: a schema, and then one or more batches of records.
The different formats look something like this picture:
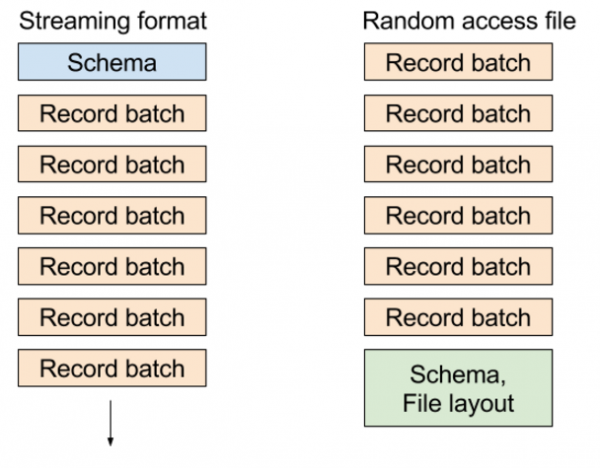
Streaming data in PyArrow: application
To show you how it works, I'll create an example dataset representing a single stream chunk:
import time
import numpy as np
import pandas as pd
import pyarrow as pa
def generate_data(total_size, ncols):
nrows = int(total_size / ncols / np.dtype('float64').itemsize)
return pd.DataFrame({
'c' + str(i): np.random.randn(nrows)
for i in range(ncols)
}) Now, suppose we want to write 1 GB of data, consisting of 1 MB chunks each, for a total of 1024 chunks. First, let's create the first 1MB data frame with 16 columns:
KILOBYTE = 1 << 10
MEGABYTE = KILOBYTE * KILOBYTE
DATA_SIZE = 1024 * MEGABYTE
NCOLS = 16
df = generate_data(MEGABYTE, NCOLS) Then I convert them to pyarrow.RecordBatch:
batch = pa.RecordBatch.from_pandas(df) Now I will create an output stream that will write to RAM and create StreamWriter:
sink = pa.InMemoryOutputStream()
stream_writer = pa.StreamWriter(sink, batch.schema)Then we will write 1024 chunks, which will eventually make up a 1GB dataset:
for i in range(DATA_SIZE // MEGABYTE):
stream_writer.write_batch(batch)Since we wrote in RAM, we can get the entire stream in one buffer:
In [13]: source = sink.get_result()
In [14]: source
Out[14]: <pyarrow.io.Buffer at 0x7f2df7118f80>
In [15]: source.size
Out[15]: 1074750744 Because this data is in memory, reading batches of Arrow records is obtained by a zero-copy operation. I open StreamReader, read data into pyarrow.Tableand then convert them to DataFrame pandas:
In [16]: reader = pa.StreamReader(source)
In [17]: table = reader.read_all()
In [18]: table
Out[18]: <pyarrow.table.Table at 0x7fae8281f6f0>
In [19]: df = table.to_pandas()
In [20]: df.memory_usage().sum()
Out[20]: 1073741904All this, of course, is good, but you may have questions. How fast does it happen? How does chunk size affect pandas DataFrame retrieval performance?
Streaming performance
As the streaming chunk size decreases, the cost of reconstructing a contiguous columnar DataFrame in pandas increases due to inefficient cache access schemes. There is also some overhead from working with C++ data structures and arrays and their memory buffers.
For 1 MB as above, on my laptop (Quad-core Xeon E3-1505M) it turns out:
In [20]: %timeit pa.StreamReader(source).read_all().to_pandas()
10 loops, best of 3: 129 ms per loopIt turns out that the effective throughput is 7.75 Gb / s for restoring a 1 GB DataFrame from 1024 1 MB chunks. What happens if we use larger or smaller chunks? Here are the results you get:
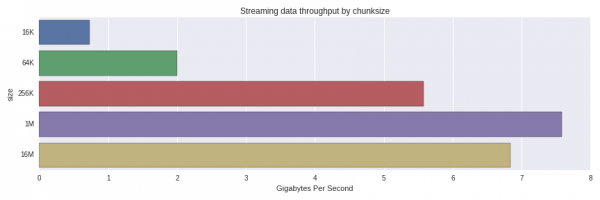
Performance drops significantly from 256K to 64K chunks. I was surprised that 1MB chunks were processed faster than 16MB chunks. It is worth doing a more thorough study and understand whether this is a normal distribution or something else is involved.
In the current implementation of the format, the data is not compressed in principle, so the size in memory and "on the wire" is approximately the same. Compression may become an option in the future.
Сonclusion
Streaming column data can be an efficient way to transfer large datasets to column analytics tools like pandas in small chunks. Data services that use row-oriented storage can transfer and transpose small chunks of data that are more convenient for your processor's L2 and L3 cache.
Full code
import time
import numpy as np
import pandas as pd
import pyarrow as pa
def generate_data(total_size, ncols):
nrows = total_size / ncols / np.dtype('float64').itemsize
return pd.DataFrame({
'c' + str(i): np.random.randn(nrows)
for i in range(ncols)
})
KILOBYTE = 1 << 10
MEGABYTE = KILOBYTE * KILOBYTE
DATA_SIZE = 1024 * MEGABYTE
NCOLS = 16
def get_timing(f, niter):
start = time.clock_gettime(time.CLOCK_REALTIME)
for i in range(niter):
f()
return (time.clock_gettime(time.CLOCK_REALTIME) - start) / NITER
def read_as_dataframe(klass, source):
reader = klass(source)
table = reader.read_all()
return table.to_pandas()
NITER = 5
results = []
CHUNKSIZES = [16 * KILOBYTE, 64 * KILOBYTE, 256 * KILOBYTE, MEGABYTE, 16 * MEGABYTE]
for chunksize in CHUNKSIZES:
nchunks = DATA_SIZE // chunksize
batch = pa.RecordBatch.from_pandas(generate_data(chunksize, NCOLS))
sink = pa.InMemoryOutputStream()
stream_writer = pa.StreamWriter(sink, batch.schema)
for i in range(nchunks):
stream_writer.write_batch(batch)
source = sink.get_result()
elapsed = get_timing(lambda: read_as_dataframe(pa.StreamReader, source), NITER)
result = (chunksize, elapsed)
print(result)
results.append(result)Source: habr.com
