

Bringing a new project release to production requires a careful balance between deployment speed and solution reliability. Slack values fast iteration, short feedback cycles, and quick response to user requests. In addition, the company has hundreds of programmers who strive to be as productive as possible.
The authors of the material, the translation of which we are publishing today, say that a company that strives to adhere to such values \uXNUMXb\uXNUMXband grows at the same time must constantly improve its system for deploying projects. The company needs to invest in transparency and reliability of work processes, doing so in order to ensure that these processes are consistent with the scope of the project. Here we will talk about the workflows that have developed in Slack, and about some of the decisions that led the company to use the current system for deploying projects in it.
How Project Deployment Processes Work Today
Each PR (pull request) in Slack must be subjected to a code review and must pass all tests successfully. Only after these conditions are met, the programmer can merge his code into the master branch of the project. However, this code is deployed only during North American business hours. As a result, we, due to the fact that our employees are in the workplace, are fully prepared to solve any unexpected problems.
Every day we perform about 12 planned deployments. During each deployment, the programmer designated as the Deployment Lead is responsible for bringing the new build to production. This is a multi-step process that brings the assembly into production smoothly. With this approach, we can detect bugs before they affect all of our users. If there are too many errors, the deployment of the assembly can be rolled back. If a particular problem is discovered after the release, it is easy to release a fix for it.
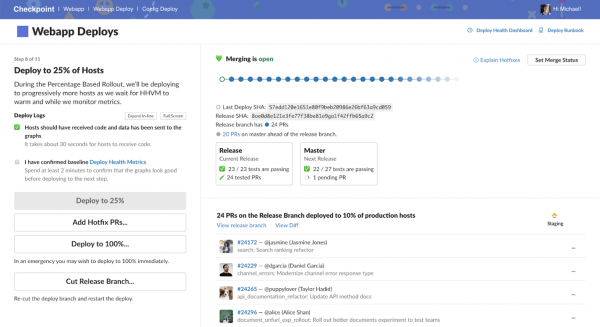
The interface of the Checkpoint system used by Slack to deploy projects
The process of deploying a new release to production can be thought of as consisting of four steps.
▍1. Create a release branch
Each release starts with a new release branch, from a point in our Git history. This allows you to assign tags to the release and provides a place to make hot fixes for bugs found while preparing the release for release to production.
▍2. Deployment in a staging environment
The next step of the work is to deploy the assembly on intermediate (staging) servers and run an automatic test for the overall health of the project (smoke test). The staging environment is a production environment that does not receive external traffic. In this environment, we do additional manual testing. This gives us additional confidence that the modified project works correctly. Automated tests alone are not enough to provide such confidence.
▍3. Deployment to dogfood and canary environments
A production deployment starts with a dogfood environment, which is a set of hosts that serve our internal Slack workspaces. Since we are very active Slack users, taking this approach helped us catch a lot of bugs in the early stages of deployment. After we have made sure that the basic functionality of the system is not violated, the assembly is deployed in the canary environment. It represents the systems that receive approximately 2% of production traffic.
▍4. Gradual release to production
If the monitoring indicators of the new release turn out to be stable, and if after the deployment of the project in the canary environment we did not receive any complaints, we continue to gradually transfer the production servers to the new release. The deployment process is divided into the following stages: 10%, 25%, 50%, 75% and 100%. As a result, we can slowly transfer production traffic to a new release of the system. At the same time, we have time to study the situation in case of detection of some anomalies.
▍What if something went wrong during the deployment?
Making modifications to the code is always a risk. But we manage this by having well-trained "deployment leaders" who manage the process of bringing a new release to production, overseeing monitoring metrics, and coordinating the work of programmers releasing code.
In the event that something really went wrong, we try to detect the problem as early as possible. We investigate the problem, find the PR that causes errors, roll it back, carefully analyze it and create a new build. True, sometimes the problem goes unnoticed until the project is released into production. In such a situation, the most important thing is to restore the service. Therefore, before we start investigating the problem, we immediately roll back to the previous working build.
Building blocks of a deployment system
Let's take a look at the technologies behind our project deployment system.
▍Quick Deployments
The above workflow may seem, in retrospect, something quite obvious. But our deployment system did not become so immediately.
When the company was much smaller, our entire application could run on 10 Amazon EC2 instances. Deploying the project in such a situation meant using rsync to quickly synchronize all servers. Previously, the new code from production was separated by only one step, represented by the staging environment. Builds were created and tested in such an environment, and then went straight to production. It was very easy to understand such a system, it allowed any programmer to deploy the code he had written at any time.
But as the number of our clients grew, so did the scale of the infrastructure needed to keep the project running. Soon, given the constant growth of the system, our deployment model, based on pushing new code to the servers, ceased to cope with its task. Namely, the addition of each new server meant an increase in the time required to complete the deployment. Even strategies based on parallel use of rsync have certain limitations.
In the end, we solved this problem by moving to a fully parallel deployment system, arranged differently from the old system. Namely, now we did not send the code to the servers using the synchronization script. Now each server downloaded a new build on its own, knowing that it needed to be done thanks to observing the change in the Consul key. The servers loaded the code in parallel. This allowed us to maintain a high speed of deployment even in an environment of constant system growth.

1. Production servers watch the Consul key. 2. The key is changed, this tells the servers to start downloading the new code. 3. Servers download application code tarballs
▍Atomic Deployments
Another solution that helped us get to the tiered deployment system was atomic deployment.
Prior to using atomic deployments, each deployment could result in a large number of error messages. The fact is that the process of copying new files to production servers was not atomic. This led to the existence of a short time period when the code in which new functions were called was available before the functions themselves were available. When such code was called, it caused internal errors to be returned. This manifested itself in failed API requests and "broken" web pages.
The team that dealt with this problem solved it by introducing the concept of "hot" (hot) and "cold" (cold) directories. The code in the hot directory is responsible for processing production traffic. And in the "cold" directories, the code, during the operation of the system, is only being prepared for use. During deployment, new code is copied to an unused "cold" directory. Then, when there are no active processes on the server, an instant directory switch is performed.
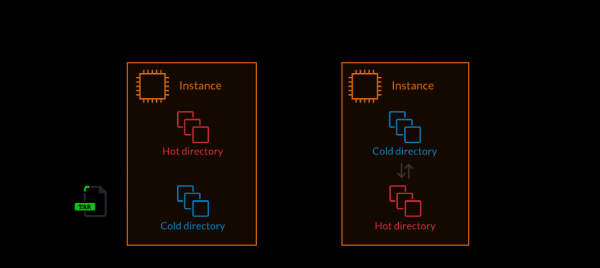
1. Unpacking the application code into a "cold" directory. 2. Switching the system to a "cold" directory, which becomes "hot" (atomic operation)
Results: a shift in emphasis on reliability
In 2018, the project has grown to such a scale that a very rapid deployment began to harm the stability of the product. We had a very advanced deployment system that we put a lot of time and effort into. We just needed to rebuild and improve the deployment organization processes. We have turned into a fairly large company, the developments of which were used all over the world to organize uninterrupted communications and solve important problems. Therefore, reliability is at the center of our attention.
We needed to make the process of deploying new Slack releases more secure. This need led us to improve our deployment system. As a matter of fact, above we discussed this improved system. In the bowels of the system, we continue to use technologies for rapid and atomic deployment. The way deployment is performed has changed. Our new system is designed to gradually deploy new code at different levels, in different environments. Now we use more advanced than before, auxiliary tools and tools for monitoring the system. This gives us the ability to catch and fix bugs long before they have a chance to reach the end user.
But we are not going to stop there. We are constantly improving this system, using more advanced auxiliary tools and automation tools.
Dear Readers, How is the process of deploying new project releases where you work?
Source: habr.com
